 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch Your Steps: Local Image and Scene Editing by Text Instructions
Aug 17, 2023Denoising diffusion models have enabled high-quality image generation and editing. We present a method to localize the desired edit region implicit in a text instruction. We leverage InstructPix2Pix (IP2P) and identify the discrepancy between IP2P predictions with and without the instruction. This discrepancy is referred to as the relevance map. The relevance map conveys the importance of changing each pixel to achieve the edits, and is used to to guide the modifications. This guidance ensures that the irrelevant pixels remain unchanged. Relevance maps are further used to enhance the quality of text-guided editing of 3D scenes in the form of neural radiance fields. A field is trained on relevance maps of training views, denoted as the relevance field, defining the 3D region within which modifications should be made. We perform iterative updates on the training views guided by rendered relevance maps from the relevance field. Our method achieves state-of-the-art performance on both image and NeRF editing tasks. Project page: https://ashmrz.github.io/WatchYourSteps/
Long-Term Photometric Consistent Novel View Synthesis with Diffusion Models
Apr 21, 2023



Novel view synthesis from a single input image is a challenging task, where the goal is to generate a new view of a scene from a desired camera pose that may be separated by a large motion. The highly uncertain nature of this synthesis task due to unobserved elements within the scene (i.e., occlusion) and outside the field-of-view makes the use of generative models appealing to capture the variety of possible outputs. In this paper, we propose a novel generative model which is capable of producing a sequence of photorealistic images consistent with a specified camera trajectory, and a single starting image. Our approach is centred on an autoregressive conditional diffusion-based model capable of interpolating visible scene elements, and extrapolating unobserved regions in a view, in a geometrically consistent manner. Conditioning is limited to an image capturing a single camera view and the (relative) pose of the new camera view. To measure the consistency over a sequence of generated views, we introduce a new metric, the thresholded symmetric epipolar distance (TSED), to measure the number of consistent frame pairs in a sequence. While previous methods have been shown to produce high quality images and consistent semantics across pairs of views, we show empirically with our metric that they are often inconsistent with the desired camera poses. In contrast, we demonstrate that our method produces both photorealistic and view-consistent imagery.
Reference-guided Controllable Inpainting of Neural Radiance Fields
Apr 20, 2023



The popularity of Neural Radiance Fields (NeRFs) for view synthesis has led to a desire for NeRF editing tools. Here, we focus on inpainting regions in a view-consistent and controllable manner. In addition to the typical NeRF inputs and masks delineating the unwanted region in each view, we require only a single inpainted view of the scene, i.e., a reference view. We use monocular depth estimators to back-project the inpainted view to the correct 3D positions. Then, via a novel rendering technique, a bilateral solver can construct view-dependent effects in non-reference views, making the inpainted region appear consistent from any view. For non-reference disoccluded regions, which cannot be supervised by the single reference view, we devise a method based on image inpainters to guide both the geometry and appearance. Our approach shows superior performance to NeRF inpainting baselines, with the additional advantage that a user can control the generated scene via a single inpainted image. Project page: https://ashmrz.github.io/reference-guided-3d
SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields
Nov 22, 2022Neural Radiance Fields (NeRFs) have emerged as a popular approach for novel view synthesis. While NeRFs are quickly being adapted for a wider set of applications, intuitively editing NeRF scenes is still an open challenge. One important editing task is the removal of unwanted objects from a 3D scene, such that the replaced region is visually plausible and consistent with its context. We refer to this task as 3D inpainting. In 3D, solutions must be both consistent across multiple views and geometrically valid. In this paper, we propose a novel 3D inpainting method that addresses these challenges. Given a small set of posed images and sparse annotations in a single input image, our framework first rapidly obtains a 3D segmentation mask for a target object. Using the mask, a perceptual optimizationbased approach is then introduced that leverages learned 2D image inpainters, distilling their information into 3D space, while ensuring view consistency. We also address the lack of a diverse benchmark for evaluating 3D scene inpainting methods by introducing a dataset comprised of challenging real-world scenes. In particular, our dataset contains views of the same scene with and without a target object, enabling more principled benchmarking of the 3D inpainting task. We first demonstrate the superiority of our approach on multiview segmentation, comparing to NeRFbased methods and 2D segmentation approaches. We then evaluate on the task of 3D inpainting, establishing state-ofthe-art performance against other NeRF manipulation algorithms, as well as a strong 2D image inpainter baseline
Learning sRGB-to-Raw-RGB De-rendering with Content-Aware Metadata
Jun 03, 2022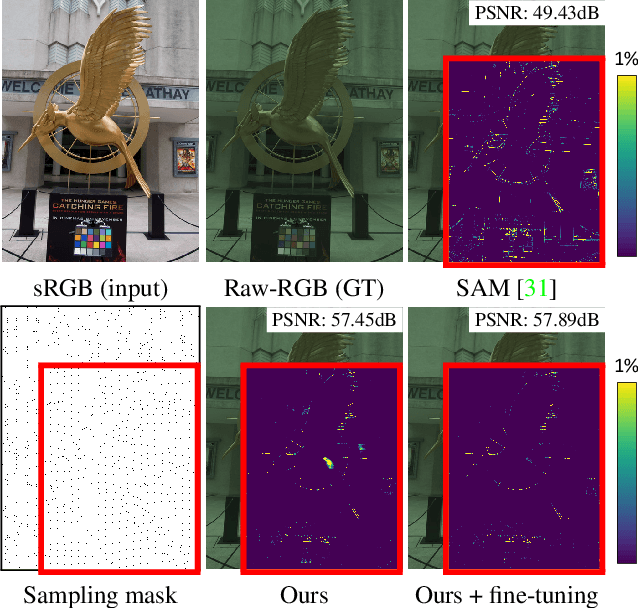

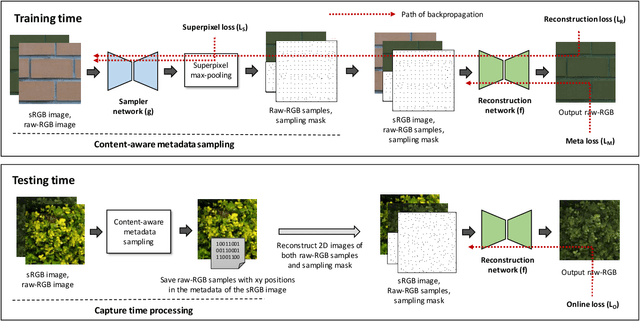
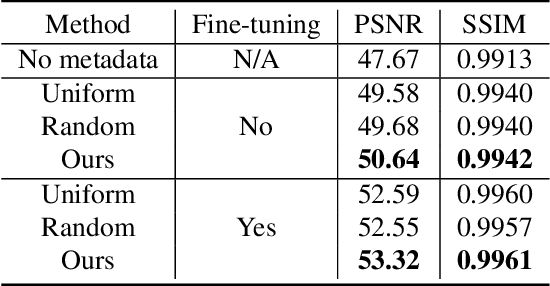
Most camera images are rendered and saved in the standard RGB (sRGB) format by the camera's hardware. Due to the in-camera photo-finishing routines, nonlinear sRGB images are undesirable for computer vision tasks that assume a direct relationship between pixel values and scene radiance. For such applications, linear raw-RGB sensor images are preferred. Saving images in their raw-RGB format is still uncommon due to the large storage requirement and lack of support by many imaging applications. Several "raw reconstruction" methods have been proposed that utilize specialized metadata sampled from the raw-RGB image at capture time and embedded in the sRGB image. This metadata is used to parameterize a mapping function to de-render the sRGB image back to its original raw-RGB format when needed. Existing raw reconstruction methods rely on simple sampling strategies and global mapping to perform the de-rendering. This paper shows how to improve the de-rendering results by jointly learning sampling and reconstruction. Our experiments show that our learned sampling can adapt to the image content to produce better raw reconstructions than existing methods. We also describe an online fine-tuning strategy for the reconstruction network to improve results further.
Noise2NoiseFlow: Realistic Camera Noise Modeling without Clean Images
Jun 02, 2022
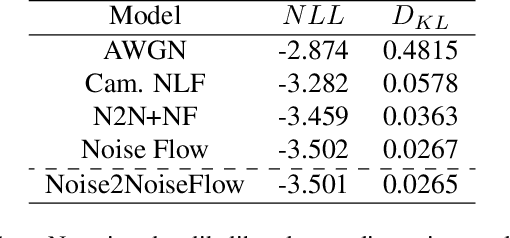
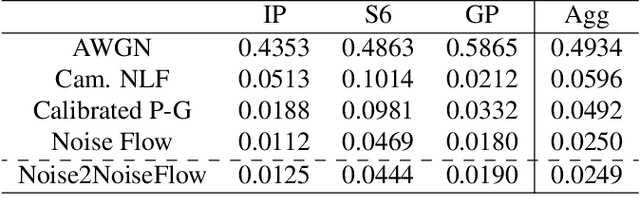
Image noise modeling is a long-standing problem with many applications in computer vision. Early attempts that propose simple models, such as signal-independent additive white Gaussian noise or the heteroscedastic Gaussian noise model (a.k.a., camera noise level function) are not sufficient to learn the complex behavior of the camera sensor noise. Recently, more complex learning-based models have been proposed that yield better results in noise synthesis and downstream tasks, such as denoising. However, their dependence on supervised data (i.e., paired clean images) is a limiting factor given the challenges in producing ground-truth images. This paper proposes a framework for training a noise model and a denoiser simultaneously while relying only on pairs of noisy images rather than noisy/clean paired image data. We apply this framework to the training of the Noise Flow architecture. The noise synthesis and density estimation results show that our framework outperforms previous signal-processing-based noise models and is on par with its supervised counterpart. The trained denoiser is also shown to significantly improve upon both supervised and weakly supervised baseline denoising approaches. The results indicate that the joint training of a denoiser and a noise model yields significant improvements in the denoiser.
Modeling sRGB Camera Noise with Normalizing Flows
Jun 02, 2022
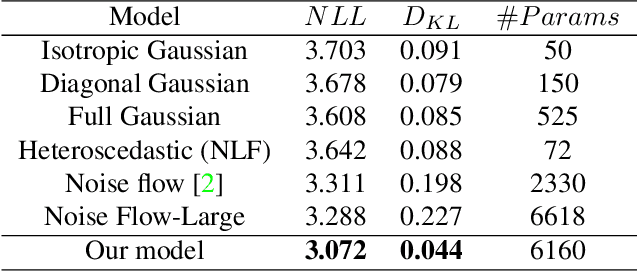
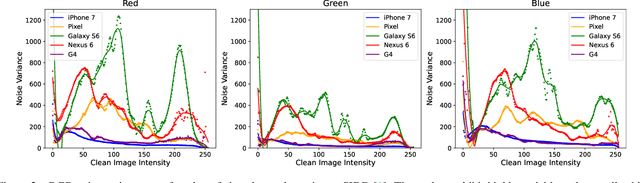
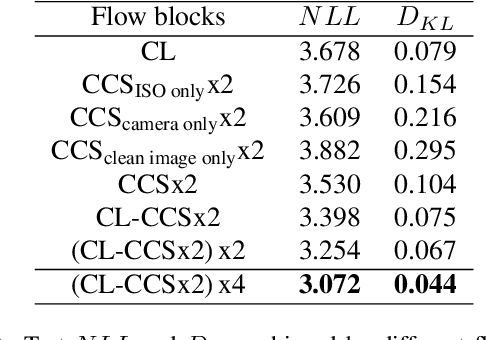
Noise modeling and reduction are fundamental tasks in low-level computer vision. They are particularly important for smartphone cameras relying on small sensors that exhibit visually noticeable noise. There has recently been renewed interest in using data-driven approaches to improve camera noise models via neural networks. These data-driven approaches target noise present in the raw-sensor image before it has been processed by the camera's image signal processor (ISP). Modeling noise in the RAW-rgb domain is useful for improving and testing the in-camera denoising algorithm; however, there are situations where the camera's ISP does not apply denoising or additional denoising is desired when the RAW-rgb domain image is no longer available. In such cases, the sensor noise propagates through the ISP to the final rendered image encoded in standard RGB (sRGB). The nonlinear steps on the ISP culminate in a significantly more complex noise distribution in the sRGB domain and existing raw-domain noise models are unable to capture the sRGB noise distribution. We propose a new sRGB-domain noise model based on normalizing flows that is capable of learning the complex noise distribution found in sRGB images under various ISO levels. Our normalizing flows-based approach outperforms other models by a large margin in noise modeling and synthesis tasks. We also show that image denoisers trained on noisy images synthesized with our noise model outperforms those trained with noise from baselines models.
Residual Multiplicative Filter Networks for Multiscale Reconstruction
Jun 01, 2022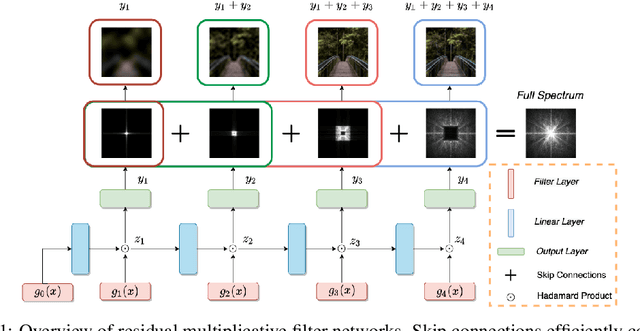
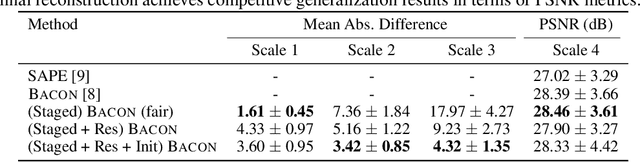
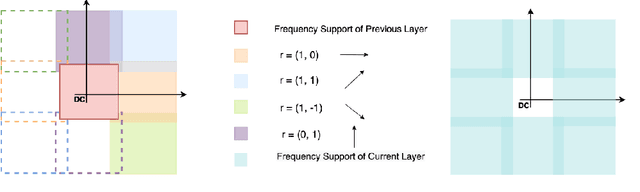
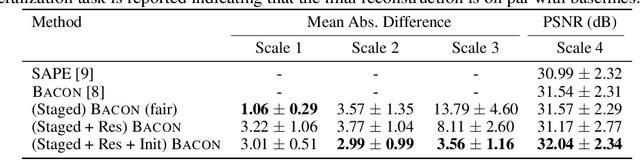
Coordinate networks like Multiplicative Filter Networks (MFNs) and BACON offer some control over the frequency spectrum used to represent continuous signals such as images or 3D volumes. Yet, they are not readily applicable to problems for which coarse-to-fine estimation is required, including various inverse problems in which coarse-to-fine optimization plays a key role in avoiding poor local minima. We introduce a new coordinate network architecture and training scheme that enables coarse-to-fine optimization with fine-grained control over the frequency support of learned reconstructions. This is achieved with two key innovations. First, we incorporate skip connections so that structure at one scale is preserved when fitting finer-scale structure. Second, we propose a novel initialization scheme to provide control over the model frequency spectrum at each stage of optimization. We demonstrate how these modifications enable multiscale optimization for coarse-to-fine fitting to natural images. We then evaluate our model on synthetically generated datasets for the the problem of single-particle cryo-EM reconstruction. We learn high resolution multiscale structures, on par with the state-of-the art.
Auto White-Balance Correction for Mixed-Illuminant Scenes
Oct 08, 2021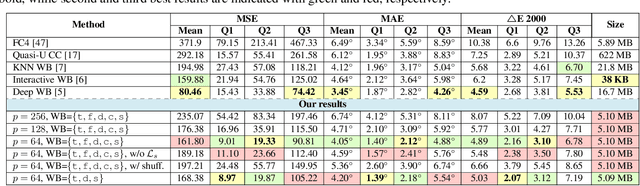

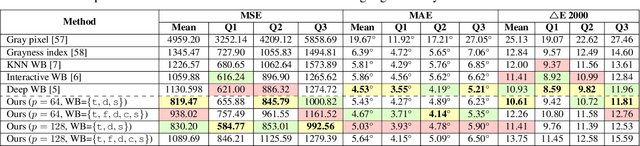

Auto white balance (AWB) is applied by camera hardware at capture time to remove the color cast caused by the scene illumination. The vast majority of white-balance algorithms assume a single light source illuminates the scene; however, real scenes often have mixed lighting conditions. This paper presents an effective AWB method to deal with such mixed-illuminant scenes. A unique departure from conventional AWB, our method does not require illuminant estimation, as is the case in traditional camera AWB modules. Instead, our method proposes to render the captured scene with a small set of predefined white-balance settings. Given this set of rendered images, our method learns to estimate weighting maps that are used to blend the rendered images to generate the final corrected image. Through extensive experiments, we show this proposed method produces promising results compared to other alternatives for single- and mixed-illuminant scene color correction. Our source code and trained models are available at https://github.com/mahmoudnafifi/mixedillWB.
Neural Image Representations for Multi-Image Fusion and Layer Separation
Aug 24, 2021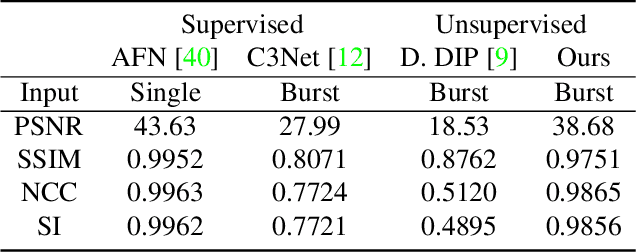
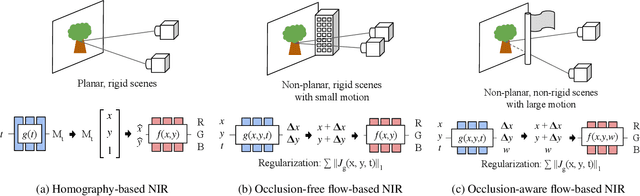
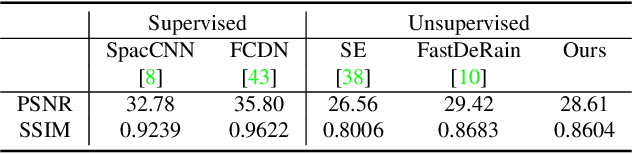
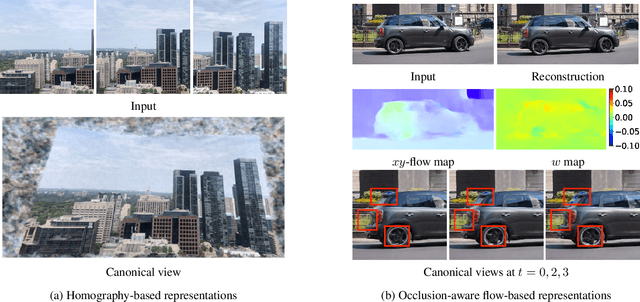
We propose a framework for aligning and fusing multiple images into a single coordinate-based neural representations. Our framework targets burst images that have misalignment due to camera ego motion and small changes in the scene. We describe different strategies for alignment depending on the assumption of the scene motion, namely, perspective planar (i.e., homography), optical flow with minimal scene change, and optical flow with notable occlusion and disocclusion. Our framework effectively combines the multiple inputs into a single neural implicit function without the need for selecting one of the images as a reference frame. We demonstrate how to use this multi-frame fusion framework for various layer separation tasks.