 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn Your Scales: Towards Scale-Consistent Generative Novel View Synthesis
Mar 19, 2025Conventional depth-free multi-view datasets are captured using a moving monocular camera without metric calibration. The scales of camera positions in this monocular setting are ambiguous. Previous methods have acknowledged scale ambiguity in multi-view data via various ad-hoc normalization pre-processing steps, but have not directly analyzed the effect of incorrect scene scales on their application. In this paper, we seek to understand and address the effect of scale ambiguity when used to train generative novel view synthesis methods (GNVS). In GNVS, new views of a scene or object can be minimally synthesized given a single image and are, thus, unconstrained, necessitating the use of generative methods. The generative nature of these models captures all aspects of uncertainty, including any uncertainty of scene scales, which act as nuisance variables for the task. We study the effect of scene scale ambiguity in GNVS when sampled from a single image by isolating its effect on the resulting models and, based on these intuitions, define new metrics that measure the scale inconsistency of generated views. We then propose a framework to estimate scene scales jointly with the GNVS model in an end-to-end fashion. Empirically, we show that our method reduces the scale inconsistency of generated views without the complexity or downsides of previous scale normalization methods. Further, we show that removing this ambiguity improves generated image quality of the resulting GNVS model.
PolyOculus: Simultaneous Multi-view Image-based Novel View Synthesis
Feb 28, 2024



This paper considers the problem of generative novel view synthesis (GNVS), generating novel, plausible views of a scene given a limited number of known views. Here, we propose a set-based generative model that can simultaneously generate multiple, self-consistent new views, conditioned on any number of known views. Our approach is not limited to generating a single image at a time and can condition on zero, one, or more views. As a result, when generating a large number of views, our method is not restricted to a low-order autoregressive generation approach and is better able to maintain generated image quality over large sets of images. We evaluate the proposed model on standard NVS datasets and show that it outperforms the state-of-the-art image-based GNVS baselines. Further, we show that the model is capable of generating sets of camera views that have no natural sequential ordering, like loops and binocular trajectories, and significantly outperforms other methods on such tasks.
Long-Term Photometric Consistent Novel View Synthesis with Diffusion Models
Apr 21, 2023



Novel view synthesis from a single input image is a challenging task, where the goal is to generate a new view of a scene from a desired camera pose that may be separated by a large motion. The highly uncertain nature of this synthesis task due to unobserved elements within the scene (i.e., occlusion) and outside the field-of-view makes the use of generative models appealing to capture the variety of possible outputs. In this paper, we propose a novel generative model which is capable of producing a sequence of photorealistic images consistent with a specified camera trajectory, and a single starting image. Our approach is centred on an autoregressive conditional diffusion-based model capable of interpolating visible scene elements, and extrapolating unobserved regions in a view, in a geometrically consistent manner. Conditioning is limited to an image capturing a single camera view and the (relative) pose of the new camera view. To measure the consistency over a sequence of generated views, we introduce a new metric, the thresholded symmetric epipolar distance (TSED), to measure the number of consistent frame pairs in a sequence. While previous methods have been shown to produce high quality images and consistent semantics across pairs of views, we show empirically with our metric that they are often inconsistent with the desired camera poses. In contrast, we demonstrate that our method produces both photorealistic and view-consistent imagery.
Wavelet Flow: Fast Training of High Resolution Normalizing Flows
Oct 26, 2020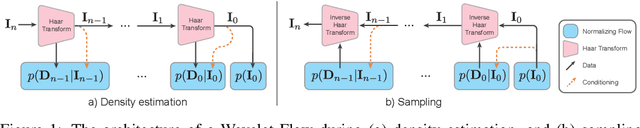


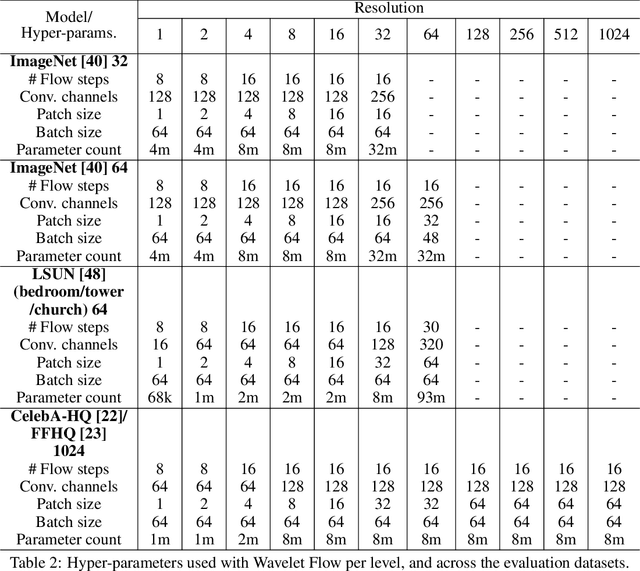
Normalizing flows are a class of probabilistic generative models which allow for both fast density computation and efficient sampling and are effective at modelling complex distributions like images. A drawback among current methods is their significant training cost, sometimes requiring months of GPU training time to achieve state-of-the-art results. This paper introduces Wavelet Flow, a multi-scale, normalizing flow architecture based on wavelets. A Wavelet Flow has an explicit representation of signal scale that inherently includes models of lower resolution signals and conditional generation of higher resolution signals, i.e., super resolution. A major advantage of Wavelet Flow is the ability to construct generative models for high resolution data (e.g., 1024 x 1024 images) that are impractical with previous models. Furthermore, Wavelet Flow is competitive with previous normalizing flows in terms of bits per dimension on standard (low resolution) benchmarks while being up to 15x faster to train.
Back to Basics: Unsupervised Learning of Optical Flow via Brightness Constancy and Motion Smoothness
Aug 20, 2016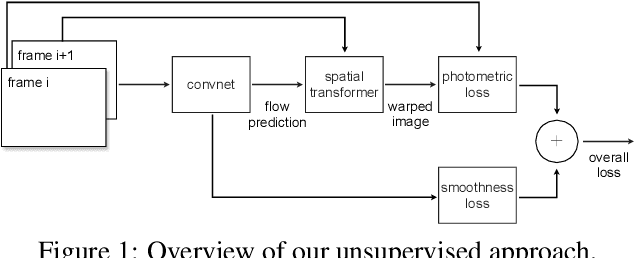
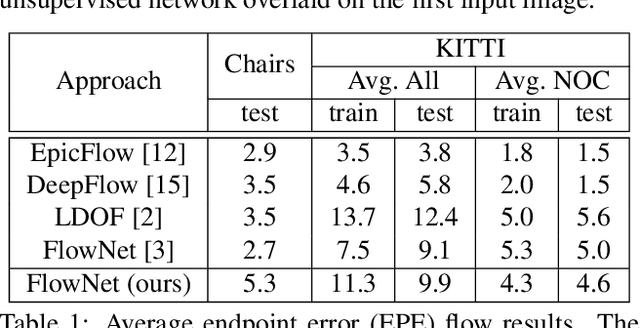
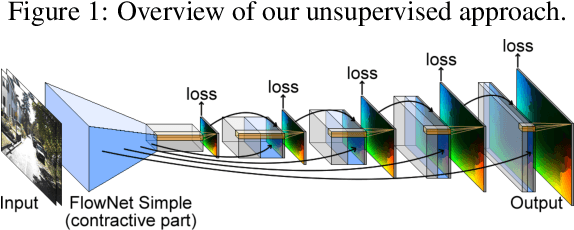

Recently, convolutional networks (convnets) have proven useful for predicting optical flow. Much of this success is predicated on the availability of large datasets that require expensive and involved data acquisition and laborious la- beling. To bypass these challenges, we propose an unsuper- vised approach (i.e., without leveraging groundtruth flow) to train a convnet end-to-end for predicting optical flow be- tween two images. We use a loss function that combines a data term that measures photometric constancy over time with a spatial term that models the expected variation of flow across the image. Together these losses form a proxy measure for losses based on the groundtruth flow. Empiri- cally, we show that a strong convnet baseline trained with the proposed unsupervised approach outperforms the same network trained with supervision on the KITTI dataset.