 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasque and Spanish Counter Narrative Generation: Data Creation and Evaluation
Mar 14, 2024



Counter Narratives (CNs) are non-negative textual responses to Hate Speech (HS) aiming at defusing online hatred and mitigating its spreading across media. Despite the recent increase in HS content posted online, research on automatic CN generation has been relatively scarce and predominantly focused on English. In this paper, we present CONAN-EUS, a new Basque and Spanish dataset for CN generation developed by means of Machine Translation (MT) and professional post-edition. Being a parallel corpus, also with respect to the original English CONAN, it allows to perform novel research on multilingual and crosslingual automatic generation of CNs. Our experiments on CN generation with mT5, a multilingual encoder-decoder model, show that generation greatly benefits from training on post-edited data, as opposed to relying on silver MT data only. These results are confirmed by their correlation with a qualitative manual evaluation, demonstrating that manually revised training data remains crucial for the quality of the generated CNs. Furthermore, multilingual data augmentation improves results over monolingual settings for structurally similar languages such as English and Spanish, while being detrimental for Basque, a language isolate. Similar findings occur in zero-shot crosslingual evaluations, where model transfer (fine-tuning in English and generating in a different target language) outperforms fine-tuning mT5 on machine translated data for Spanish but not for Basque. This provides an interesting insight into the asymmetry in the multilinguality of generative models, a challenging topic which is still open to research.
Putting Context in Context: the Impact of Discussion Structure on Text Classification
Feb 05, 2024



Current text classification approaches usually focus on the content to be classified. Contextual aspects (both linguistic and extra-linguistic) are usually neglected, even in tasks based on online discussions. Still in many cases the multi-party and multi-turn nature of the context from which these elements are selected can be fruitfully exploited. In this work, we propose a series of experiments on a large dataset for stance detection in English, in which we evaluate the contribution of different types of contextual information, i.e. linguistic, structural and temporal, by feeding them as natural language input into a transformer-based model. We also experiment with different amounts of training data and analyse the topology of local discussion networks in a privacy-compliant way. Results show that structural information can be highly beneficial to text classification but only under certain circumstances (e.g. depending on the amount of training data and on discussion chain complexity). Indeed, we show that contextual information on smaller datasets from other classification tasks does not yield significant improvements. Our framework, based on local discussion networks, allows the integration of structural information, while minimising user profiling, thus preserving their privacy.
Countering Misinformation via Emotional Response Generation
Nov 17, 2023



The proliferation of misinformation on social media platforms (SMPs) poses a significant danger to public health, social cohesion and ultimately democracy. Previous research has shown how social correction can be an effective way to curb misinformation, by engaging directly in a constructive dialogue with users who spread -- often in good faith -- misleading messages. Although professional fact-checkers are crucial to debunking viral claims, they usually do not engage in conversations on social media. Thereby, significant effort has been made to automate the use of fact-checker material in social correction; however, no previous work has tried to integrate it with the style and pragmatics that are commonly employed in social media communication. To fill this gap, we present VerMouth, the first large-scale dataset comprising roughly 12 thousand claim-response pairs (linked to debunking articles), accounting for both SMP-style and basic emotions, two factors which have a significant role in misinformation credibility and spreading. To collect this dataset we used a technique based on an author-reviewer pipeline, which efficiently combines LLMs and human annotators to obtain high-quality data. We also provide comprehensive experiments showing how models trained on our proposed dataset have significant improvements in terms of output quality and generalization capabilities.
PRODIGy: a PROfile-based DIalogue Generation dataset
Nov 09, 2023



Providing dialogue agents with a profile representation can improve their consistency and coherence, leading to better conversations. However, current profile-based dialogue datasets for training such agents contain either explicit profile representations that are simple and dialogue-specific, or implicit representations that are difficult to collect. In this work, we propose a unified framework in which we bring together both standard and more sophisticated profile representations by creating a new resource where each dialogue is aligned with all possible speaker representations such as communication style, biographies, and personality. This framework allows to test several baselines built using generative language models with several profile configurations. The automatic evaluation shows that profile-based models have better generalisation capabilities than models trained on dialogues only, both in-domain and cross-domain settings. These results are consistent for fine-tuned models and instruction-based LLMs. Additionally, human evaluation demonstrates a clear preference for generations consistent with both profile and context. Finally, to account for possible privacy concerns, all experiments are done under two configurations: inter-character and intra-character. In the former, the LM stores the information about the character in its internal representation, while in the latter, the LM does not retain any personal information but uses it only at inference time.
Weigh Your Own Words: Improving Hate Speech Counter Narrative Generation via Attention Regularization
Sep 05, 2023Recent computational approaches for combating online hate speech involve the automatic generation of counter narratives by adapting Pretrained Transformer-based Language Models (PLMs) with human-curated data. This process, however, can produce in-domain overfitting, resulting in models generating acceptable narratives only for hatred similar to training data, with little portability to other targets or to real-world toxic language. This paper introduces novel attention regularization methodologies to improve the generalization capabilities of PLMs for counter narratives generation. Overfitting to training-specific terms is then discouraged, resulting in more diverse and richer narratives. We experiment with two attention-based regularization techniques on a benchmark English dataset. Regularized models produce better counter narratives than state-of-the-art approaches in most cases, both in terms of automatic metrics and human evaluation, especially when hateful targets are not present in the training data. This work paves the way for better and more flexible counter-speech generation models, a task for which datasets are highly challenging to produce.
Benchmarking the Generation of Fact Checking Explanations
Aug 29, 2023Fighting misinformation is a challenging, yet crucial, task. Despite the growing number of experts being involved in manual fact-checking, this activity is time-consuming and cannot keep up with the ever-increasing amount of Fake News produced daily. Hence, automating this process is necessary to help curb misinformation. Thus far, researchers have mainly focused on claim veracity classification. In this paper, instead, we address the generation of justifications (textual explanation of why a claim is classified as either true or false) and benchmark it with novel datasets and advanced baselines. In particular, we focus on summarization approaches over unstructured knowledge (i.e. news articles) and we experiment with several extractive and abstractive strategies. We employed two datasets with different styles and structures, in order to assess the generalizability of our findings. Results show that in justification production summarization benefits from the claim information, and, in particular, that a claim-driven extractive step improves abstractive summarization performances. Finally, we show that although cross-dataset experiments suffer from performance degradation, a unique model trained on a combination of the two datasets is able to retain style information in an efficient manner.
Human-Machine Collaboration Approaches to Build a Dialogue Dataset for Hate Speech Countering
Nov 07, 2022



Fighting online hate speech is a challenge that is usually addressed using Natural Language Processing via automatic detection and removal of hate content. Besides this approach, counter narratives have emerged as an effective tool employed by NGOs to respond to online hate on social media platforms. For this reason, Natural Language Generation is currently being studied as a way to automatize counter narrative writing. However, the existing resources necessary to train NLG models are limited to 2-turn interactions (a hate speech and a counter narrative as response), while in real life, interactions can consist of multiple turns. In this paper, we present a hybrid approach for dialogical data collection, which combines the intervention of human expert annotators over machine generated dialogues obtained using 19 different configurations. The result of this work is DIALOCONAN, the first dataset comprising over 3000 fictitious multi-turn dialogues between a hater and an NGO operator, covering 6 targets of hate.
Using Pre-Trained Language Models for Producing Counter Narratives Against Hate Speech: a Comparative Study
Apr 04, 2022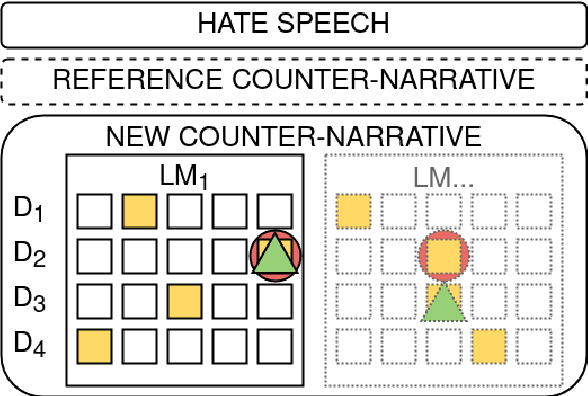


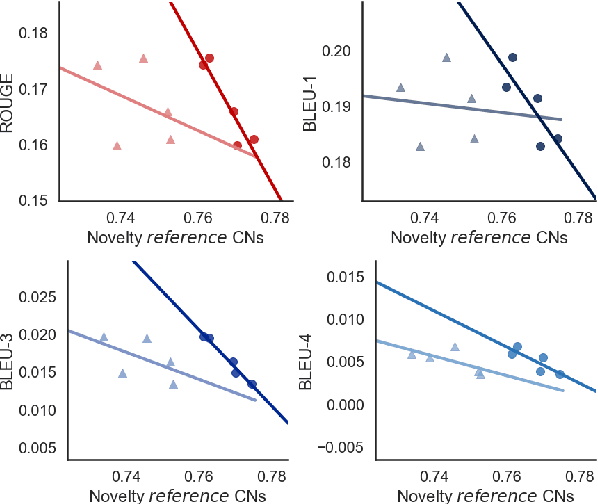
In this work, we present an extensive study on the use of pre-trained language models for the task of automatic Counter Narrative (CN) generation to fight online hate speech in English. We first present a comparative study to determine whether there is a particular Language Model (or class of LMs) and a particular decoding mechanism that are the most appropriate to generate CNs. Findings show that autoregressive models combined with stochastic decodings are the most promising. We then investigate how an LM performs in generating a CN with regard to an unseen target of hate. We find out that a key element for successful `out of target' experiments is not an overall similarity with the training data but the presence of a specific subset of training data, i.e. a target that shares some commonalities with the test target that can be defined a-priori. We finally introduce the idea of a pipeline based on the addition of an automatic post-editing step to refine generated CNs.
Multilingual Counter Narrative Type Classification
Sep 28, 2021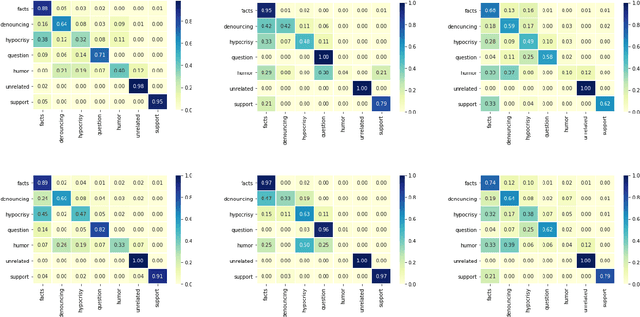
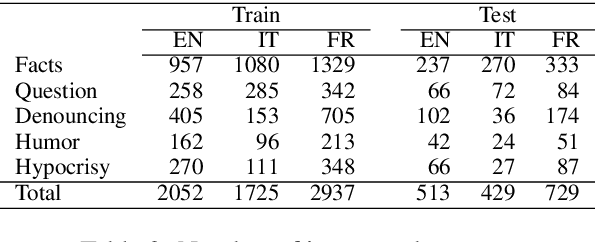


The growing interest in employing counter narratives for hatred intervention brings with it a focus on dataset creation and automation strategies. In this scenario, learning to recognize counter narrative types from natural text is expected to be useful for applications such as hate speech countering, where operators from non-governmental organizations are supposed to answer to hate with several and diverse arguments that can be mined from online sources. This paper presents the first multilingual work on counter narrative type classification, evaluating SoTA pre-trained language models in monolingual, multilingual and cross-lingual settings. When considering a fine-grained annotation of counter narrative classes, we report strong baseline classification results for the majority of the counter narrative types, especially if we translate every language to English before cross-lingual prediction. This suggests that knowledge about counter narratives can be successfully transferred across languages.
Agreeing to Disagree: Annotating Offensive Language Datasets with Annotators' Disagreement
Sep 28, 2021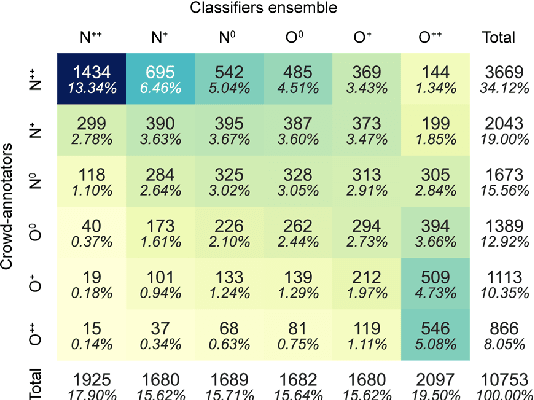

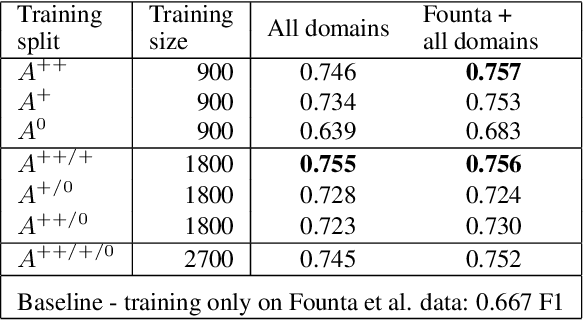
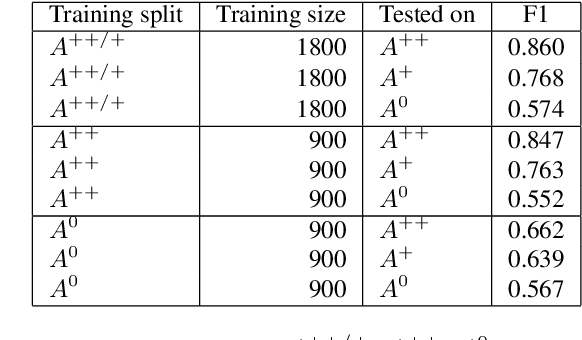
Since state-of-the-art approaches to offensive language detection rely on supervised learning, it is crucial to quickly adapt them to the continuously evolving scenario of social media. While several approaches have been proposed to tackle the problem from an algorithmic perspective, so to reduce the need for annotated data, less attention has been paid to the quality of these data. Following a trend that has emerged recently, we focus on the level of agreement among annotators while selecting data to create offensive language datasets, a task involving a high level of subjectivity. Our study comprises the creation of three novel datasets of English tweets covering different topics and having five crowd-sourced judgments each. We also present an extensive set of experiments showing that selecting training and test data according to different levels of annotators' agreement has a strong effect on classifiers performance and robustness. Our findings are further validated in cross-domain experiments and studied using a popular benchmark dataset. We show that such hard cases, where low agreement is present, are not necessarily due to poor-quality annotation and we advocate for a higher presence of ambiguous cases in future datasets, particularly in test sets, to better account for the different points of view expressed online.