 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Minimization In Emergent Languages
May 31, 2019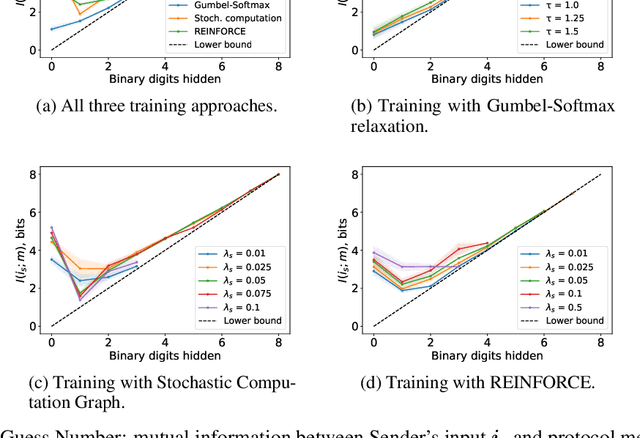
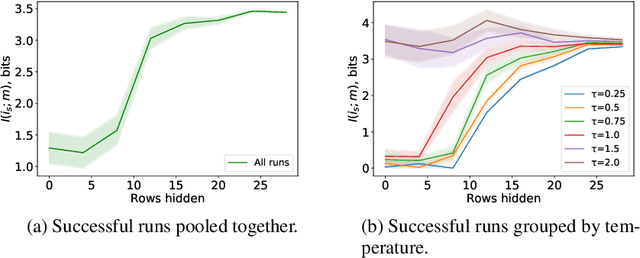
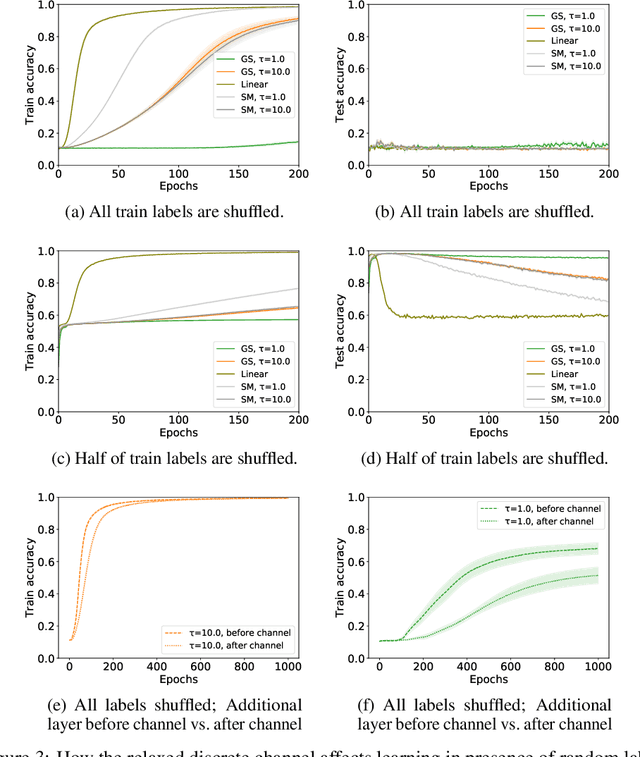
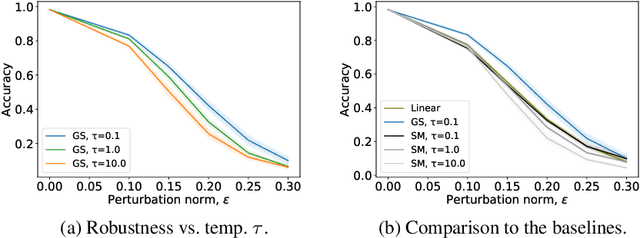
There is a growing interest in studying the languages emerging when neural agents are jointly trained to solve tasks that require communication through discrete messages. We investigate here the information-theoretic complexity of such languages, focusing on the most basic two-agent, one-symbol, one-exchange setup. We find that, under common training procedures, the emergent languages are subject to an information minimization pressure: The mutual information between the communicating agent's inputs and the messages is close to the minimum that still allows the task to be solved. After verifying this information minimization property, we perform experiments showing that a stronger discrete-channel-driven information minimization pressure leads to increased robustness to overfitting and to adversarial attacks. We conclude by discussing the implications of our findings for the studies of artificial and natural language emergence, and for representation learning.
Miss Tools and Mr Fruit: Emergent communication in agents learning about object affordances
May 28, 2019
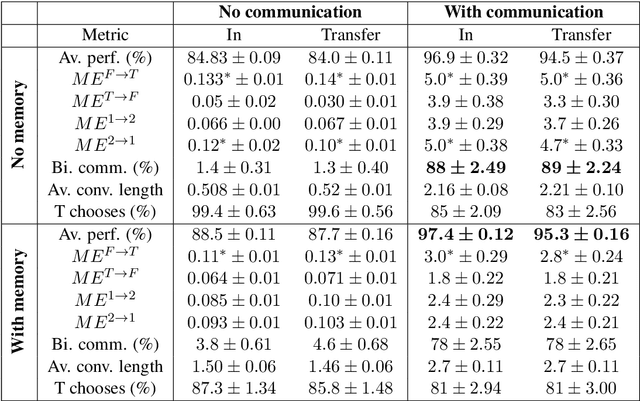
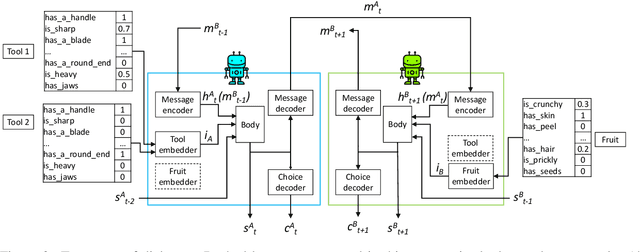
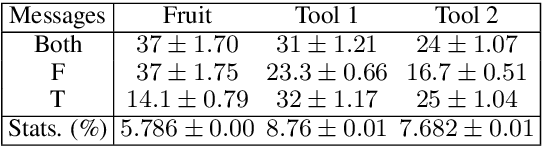
Recent research studies communication emergence in communities of deep network agents assigned a joint task, hoping to gain insights on human language evolution. We propose here a new task capturing crucial aspects of the human environment, such as natural object affordances, and of human conversation, such as full symmetry among the participants. By conducting a thorough pragmatic and semantic analysis of the emergent protocol, we show that the agents solve the shared task through genuine bilateral, referential communication. However, the agents develop multiple idiolects, which makes us conclude that full symmetry is not a sufficient condition for a common language to emerge.
CNNs found to jump around more skillfully than RNNs: Compositional generalization in seq2seq convolutional networks
May 21, 2019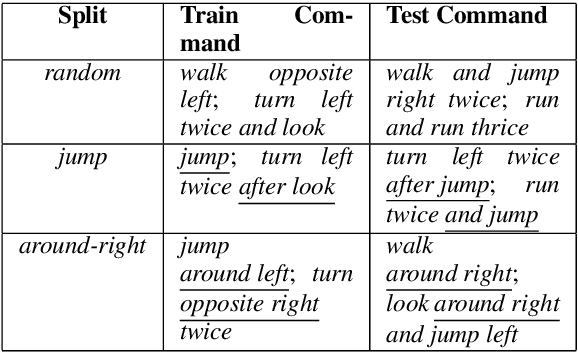
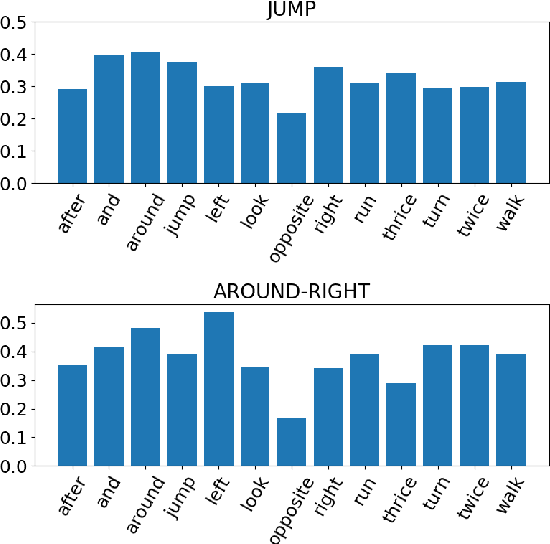
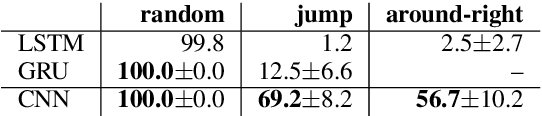
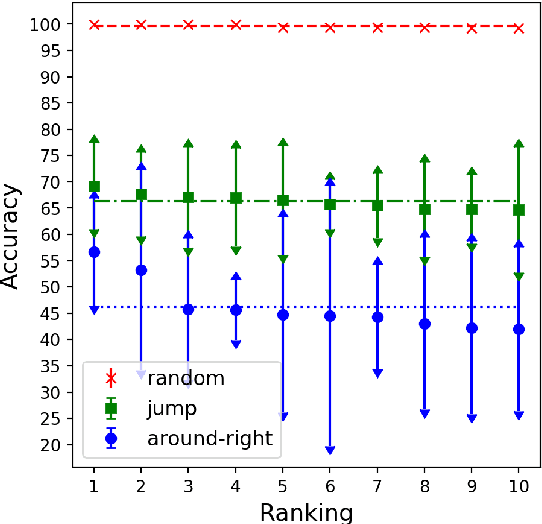
Lake and Baroni (2018) introduced the SCAN dataset probing the ability of seq2seq models to capture compositional generalizations, such as inferring the meaning of "jump around" 0-shot from the component words. Recurrent networks (RNNs) were found to completely fail the most challenging generalization cases. We test here a convolutional network (CNN) on these tasks, reporting hugely improved performance with respect to RNNs. Despite the big improvement, the CNN has however not induced systematic rules, suggesting that the difference between compositional and non-compositional behaviour is not clear-cut.
The emergence of number and syntax units in LSTM language models
Apr 02, 2019
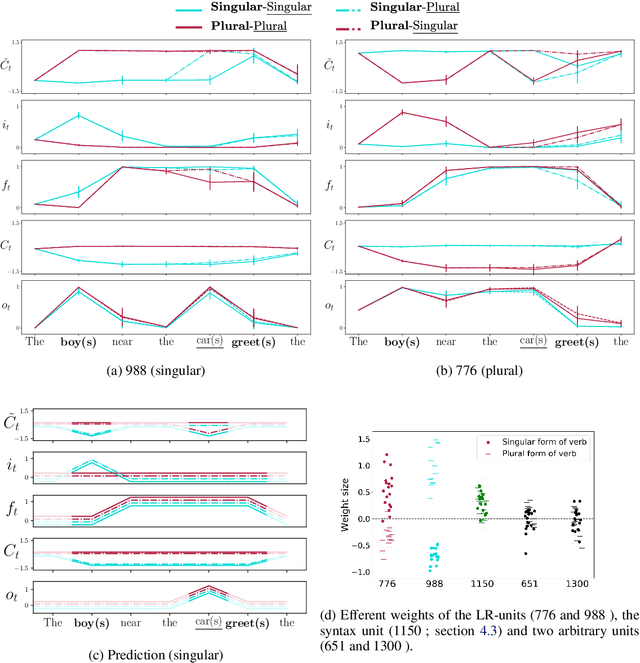
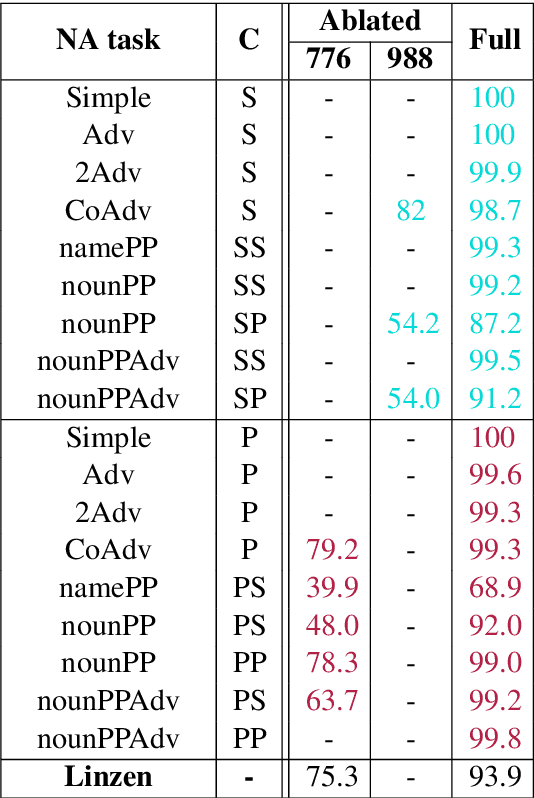
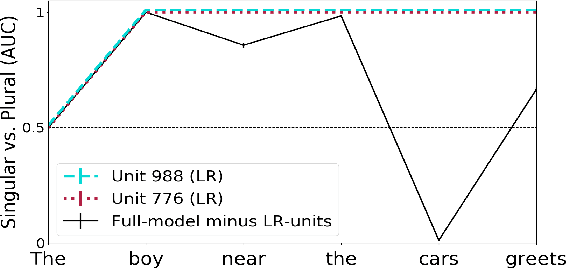
Recent work has shown that LSTMs trained on a generic language modeling objective capture syntax-sensitive generalizations such as long-distance number agreement. We have however no mechanistic understanding of how they accomplish this remarkable feat. Some have conjectured it depends on heuristics that do not truly take hierarchical structure into account. We present here a detailed study of the inner mechanics of number tracking in LSTMs at the single neuron level. We discover that long-distance number information is largely managed by two `number units'. Importantly, the behaviour of these units is partially controlled by other units independently shown to track syntactic structure. We conclude that LSTMs are, to some extent, implementing genuinely syntactic processing mechanisms, paving the way to a more general understanding of grammatical encoding in LSTMs.
Linguistic generalization and compositionality in modern artificial neural networks
Mar 30, 2019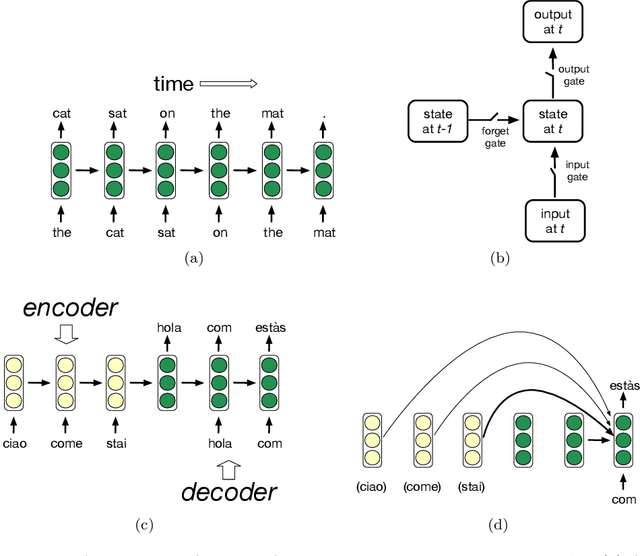
In the last decade, deep artificial neural networks have achieved astounding performance in many natural language processing tasks. Given the high productivity of language, these models must possess effective generalization abilities. It is widely assumed that humans handle linguistic productivity by means of algebraic compositional rules: Are deep networks similarly compositional? After reviewing the main innovations characterizing current deep language processing networks, I discuss a set of studies suggesting that deep networks are capable of subtle grammar-dependent generalizations, but also that they do not rely on systematic compositional rules. I argue that the intriguing behaviour of these devices (still awaiting a full understanding) should be of interest to linguists and cognitive scientists, as it offers a new perspective on possible computational strategies to deal with linguistic productivity beyond rule-based compositionality, and it might lead to new insights into the less systematic generalization patterns that also appear in natural language.
Human few-shot learning of compositional instructions
Jan 14, 2019

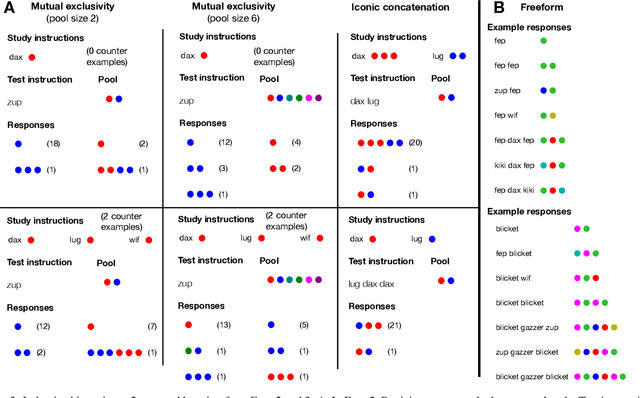
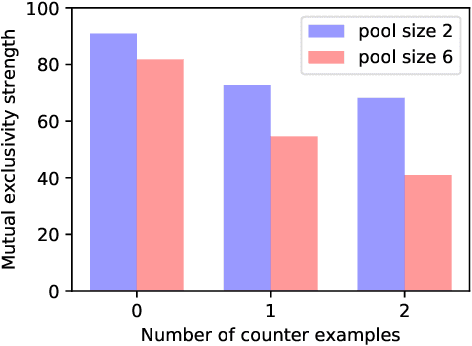
People learn in fast and flexible ways that have not been emulated by machines. Once a person learns a new verb "dax," he or she can effortlessly understand how to "dax twice," "walk and dax," or "dax vigorously." There have been striking recent improvements in machine learning for natural language processing, yet the best algorithms require vast amounts of experience and struggle to generalize new concepts in compositional ways. To better understand these distinctively human abilities, we study the compositional skills of people through language-like instruction learning tasks. Our results show that people can learn and use novel functional concepts from very few examples (few-shot learning), successfully applying familiar functions to novel inputs. People can also compose concepts in complex ways that go beyond the provided demonstrations. Two additional experiments examined the assumptions and inductive biases that people make when solving these tasks, revealing three biases: mutual exclusivity, one-to-one mappings, and iconic concatenation. We discuss the implications for cognitive modeling and the potential for building machines with more human-like language learning capabilities.
How agents see things: On visual representations in an emergent language game
Sep 13, 2018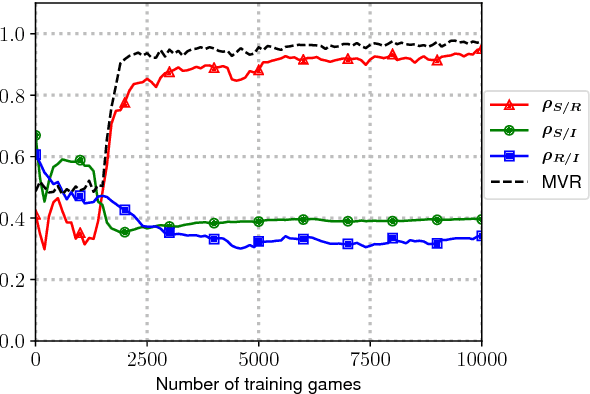

There is growing interest in the language developed by agents interacting in emergent-communication settings. Earlier studies have focused on the agents' symbol usage, rather than on their representation of visual input. In this paper, we consider the referential games of Lazaridou et al. (2017) and investigate the representations the agents develop during their evolving interaction. We find that the agents establish successful communication by inducing visual representations that almost perfectly align with each other, but, surprisingly, do not capture the conceptual properties of the objects depicted in the input images. We conclude that, if we are interested in developing language-like communication systems, we must pay more attention to the visual semantics agents associate to the symbols they use.
Jump to better conclusions: SCAN both left and right
Sep 12, 2018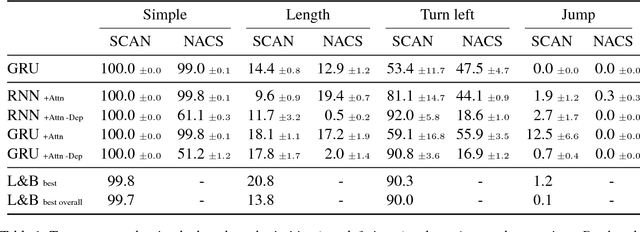
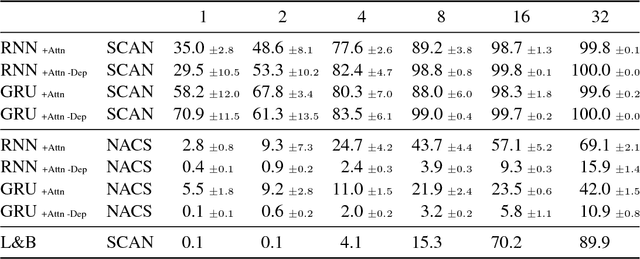

Lake and Baroni (2018) recently introduced the SCAN data set, which consists of simple commands paired with action sequences and is intended to test the strong generalization abilities of recurrent sequence-to-sequence models. Their initial experiments suggested that such models may fail because they lack the ability to extract systematic rules. Here, we take a closer look at SCAN and show that it does not always capture the kind of generalization that it was designed for. To mitigate this we propose a complementary dataset, which requires mapping actions back to the original commands, called NACS. We show that models that do well on SCAN do not necessarily do well on NACS, and that NACS exhibits properties more closely aligned with realistic use-cases for sequence-to-sequence models.
Memorize or generalize? Searching for a compositional RNN in a haystack
Jul 25, 2018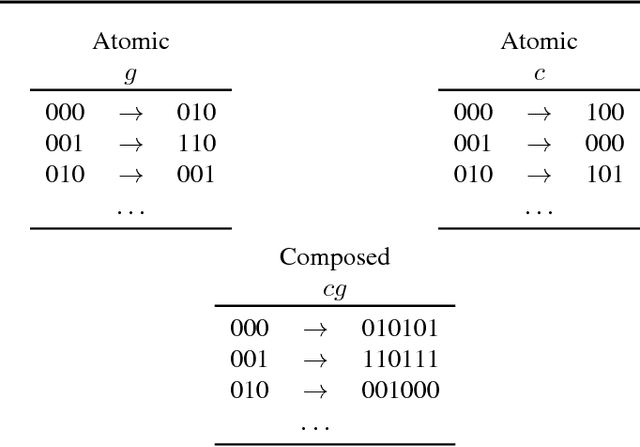
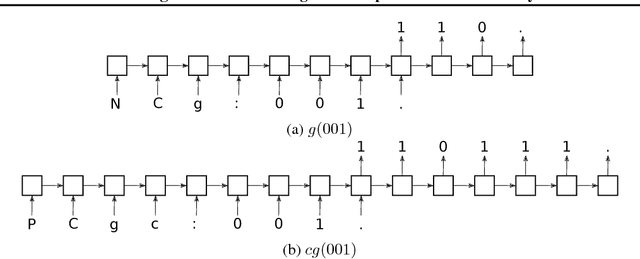
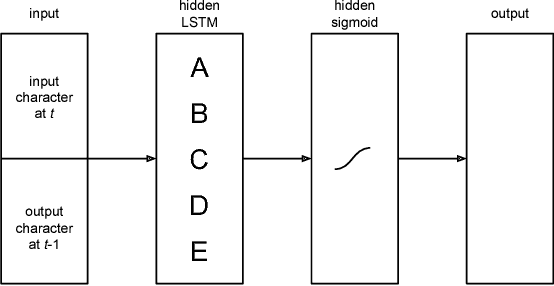

Neural networks are very powerful learning systems, but they do not readily generalize from one task to the other. This is partly due to the fact that they do not learn in a compositional way, that is, by discovering skills that are shared by different tasks, and recombining them to solve new problems. In this paper, we explore the compositional generalization capabilities of recurrent neural networks (RNNs). We first propose the lookup table composition domain as a simple setup to test compositional behaviour and show that it is theoretically possible for a standard RNN to learn to behave compositionally in this domain when trained with standard gradient descent and provided with additional supervision. We then remove this additional supervision and perform a search over a large number of model initializations to investigate the proportion of RNNs that can still converge to a compositional solution. We discover that a small but non-negligible proportion of RNNs do reach partial compositional solutions even without special architectural constraints. This suggests that a combination of gradient descent and evolutionary strategies directly favouring the minority models that developed more compositional approaches might suffice to lead standard RNNs towards compositional solutions.
Rearranging the Familiar: Testing Compositional Generalization in Recurrent Networks
Jul 19, 2018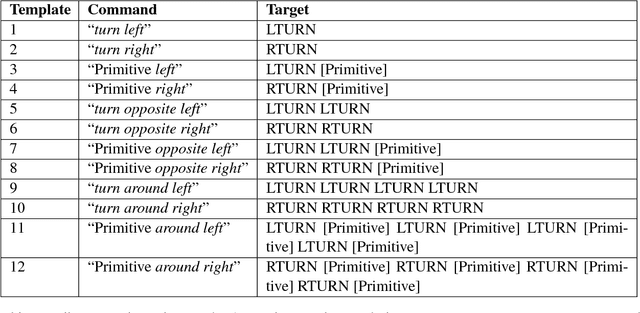
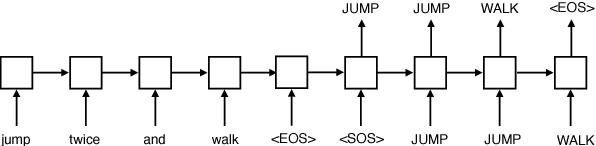

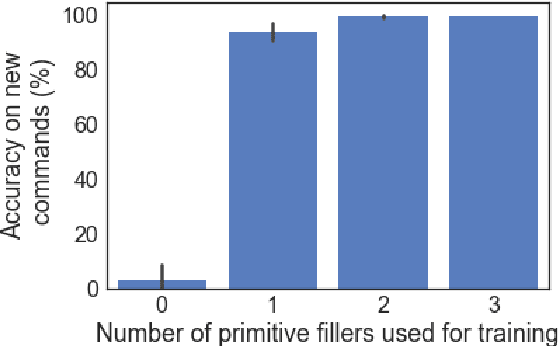
Systematic compositionality is the ability to recombine meaningful units with regular and predictable outcomes, and it's seen as key to humans' capacity for generalization in language. Recent work has studied systematic compositionality in modern seq2seq models using generalization to novel navigation instructions in a grounded environment as a probing tool, requiring models to quickly bootstrap the meaning of new words. We extend this framework here to settings where the model needs only to recombine well-trained functional words (such as "around" and "right") in novel contexts. Our findings confirm and strengthen the earlier ones: seq2seq models can be impressively good at generalizing to novel combinations of previously-seen input, but only when they receive extensive training on the specific pattern to be generalized (e.g., generalizing from many examples of "X around right" to "jump around right"), while failing when generalization requires novel application of compositional rules (e.g., inferring the meaning of "around right" from those of "right" and "around").