 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Uncertainty in Neural Machine Translation
Aug 13, 2018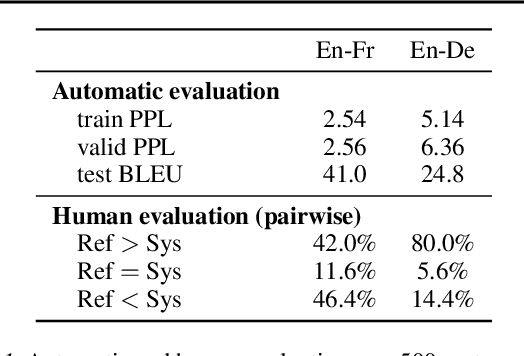
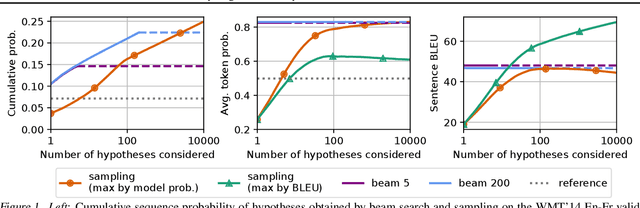
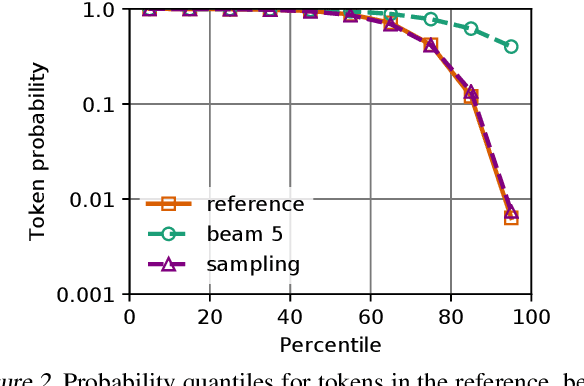
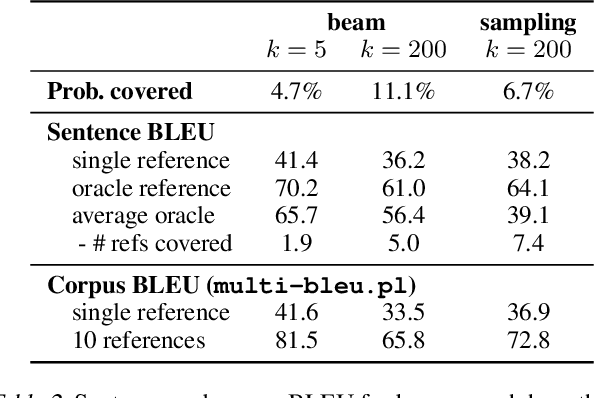
Machine translation is a popular test bed for research in neural sequence-to-sequence models but despite much recent research, there is still a lack of understanding of these models. Practitioners report performance degradation with large beams, the under-estimation of rare words and a lack of diversity in the final translations. Our study relates some of these issues to the inherent uncertainty of the task, due to the existence of multiple valid translations for a single source sentence, and to the extrinsic uncertainty caused by noisy training data. We propose tools and metrics to assess how uncertainty in the data is captured by the model distribution and how it affects search strategies that generate translations. Our results show that search works remarkably well but that models tend to spread too much probability mass over the hypothesis space. Next, we propose tools to assess model calibration and show how to easily fix some shortcomings of current models. As part of this study, we release multiple human reference translations for two popular benchmarks.
Unsupervised Machine Translation Using Monolingual Corpora Only
Apr 13, 2018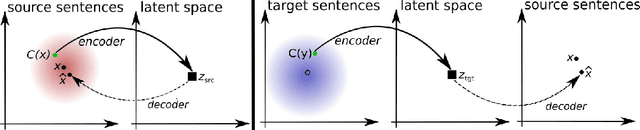


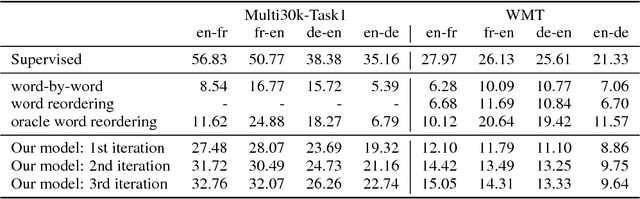
Machine translation has recently achieved impressive performance thanks to recent advances in deep learning and the availability of large-scale parallel corpora. There have been numerous attempts to extend these successes to low-resource language pairs, yet requiring tens of thousands of parallel sentences. In this work, we take this research direction to the extreme and investigate whether it is possible to learn to translate even without any parallel data. We propose a model that takes sentences from monolingual corpora in two different languages and maps them into the same latent space. By learning to reconstruct in both languages from this shared feature space, the model effectively learns to translate without using any labeled data. We demonstrate our model on two widely used datasets and two language pairs, reporting BLEU scores of 32.8 and 15.1 on the Multi30k and WMT English-French datasets, without using even a single parallel sentence at training time.
Word Translation Without Parallel Data
Jan 30, 2018
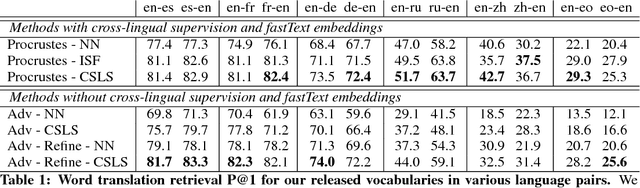
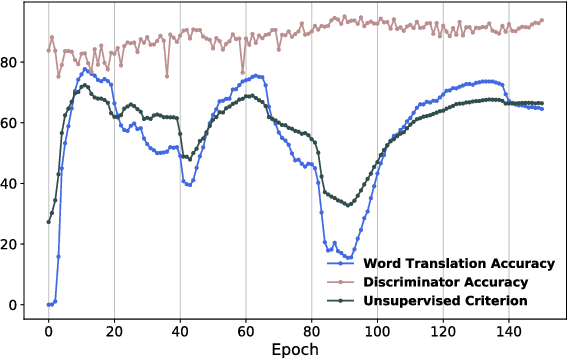
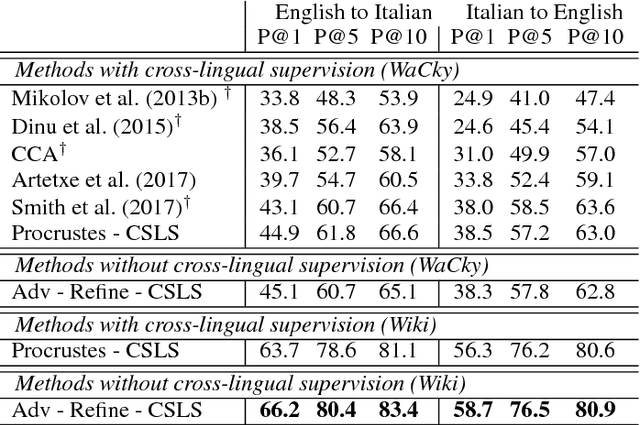
State-of-the-art methods for learning cross-lingual word embeddings have relied on bilingual dictionaries or parallel corpora. Recent studies showed that the need for parallel data supervision can be alleviated with character-level information. While these methods showed encouraging results, they are not on par with their supervised counterparts and are limited to pairs of languages sharing a common alphabet. In this work, we show that we can build a bilingual dictionary between two languages without using any parallel corpora, by aligning monolingual word embedding spaces in an unsupervised way. Without using any character information, our model even outperforms existing supervised methods on cross-lingual tasks for some language pairs. Our experiments demonstrate that our method works very well also for distant language pairs, like English-Russian or English-Chinese. We finally describe experiments on the English-Esperanto low-resource language pair, on which there only exists a limited amount of parallel data, to show the potential impact of our method in fully unsupervised machine translation. Our code, embeddings and dictionaries are publicly available.
Fader Networks: Manipulating Images by Sliding Attributes
Jan 28, 2018
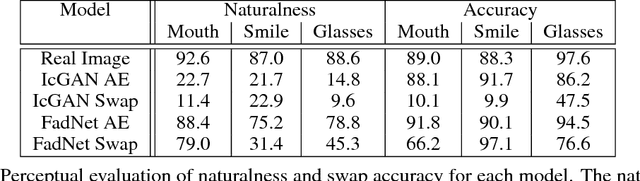
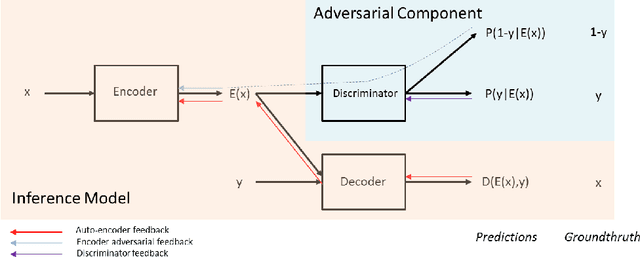

This paper introduces a new encoder-decoder architecture that is trained to reconstruct images by disentangling the salient information of the image and the values of attributes directly in the latent space. As a result, after training, our model can generate different realistic versions of an input image by varying the attribute values. By using continuous attribute values, we can choose how much a specific attribute is perceivable in the generated image. This property could allow for applications where users can modify an image using sliding knobs, like faders on a mixing console, to change the facial expression of a portrait, or to update the color of some objects. Compared to the state-of-the-art which mostly relies on training adversarial networks in pixel space by altering attribute values at train time, our approach results in much simpler training schemes and nicely scales to multiple attributes. We present evidence that our model can significantly change the perceived value of the attributes while preserving the naturalness of images.
Gradient Episodic Memory for Continual Learning
Nov 04, 2017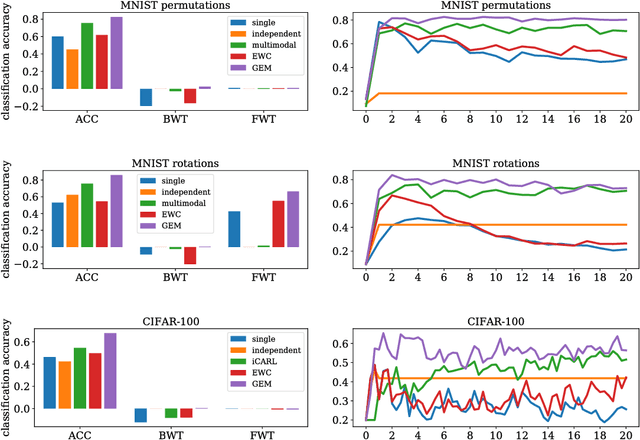

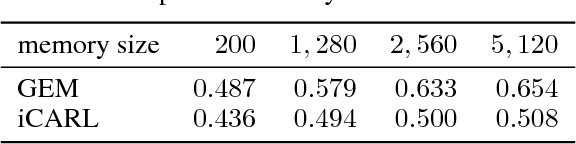
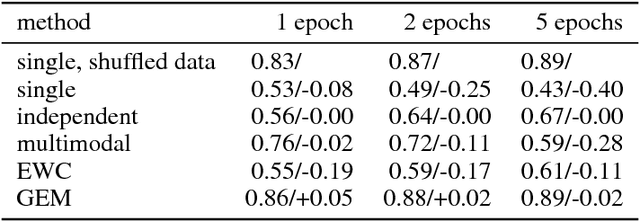
One major obstacle towards AI is the poor ability of models to solve new problems quicker, and without forgetting previously acquired knowledge. To better understand this issue, we study the problem of continual learning, where the model observes, once and one by one, examples concerning a sequence of tasks. First, we propose a set of metrics to evaluate models learning over a continuum of data. These metrics characterize models not only by their test accuracy, but also in terms of their ability to transfer knowledge across tasks. Second, we propose a model for continual learning, called Gradient Episodic Memory (GEM) that alleviates forgetting, while allowing beneficial transfer of knowledge to previous tasks. Our experiments on variants of the MNIST and CIFAR-100 datasets demonstrate the strong performance of GEM when compared to the state-of-the-art.
Transformation-Based Models of Video Sequences
Apr 24, 2017

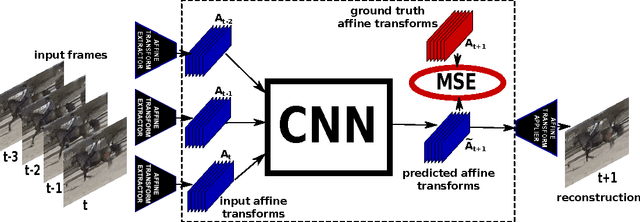
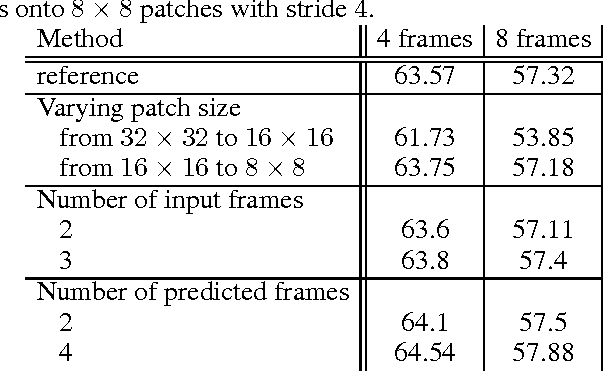
In this work we propose a simple unsupervised approach for next frame prediction in video. Instead of directly predicting the pixels in a frame given past frames, we predict the transformations needed for generating the next frame in a sequence, given the transformations of the past frames. This leads to sharper results, while using a smaller prediction model. In order to enable a fair comparison between different video frame prediction models, we also propose a new evaluation protocol. We use generated frames as input to a classifier trained with ground truth sequences. This criterion guarantees that models scoring high are those producing sequences which preserve discrim- inative features, as opposed to merely penalizing any deviation, plausible or not, from the ground truth. Our proposed approach compares favourably against more sophisticated ones on the UCF-101 data set, while also being more efficient in terms of the number of parameters and computational cost.
Hard Mixtures of Experts for Large Scale Weakly Supervised Vision
Apr 20, 2017
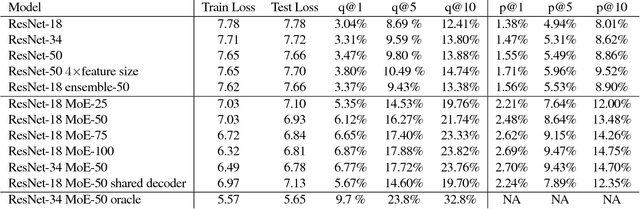

Training convolutional networks (CNN's) that fit on a single GPU with minibatch stochastic gradient descent has become effective in practice. However, there is still no effective method for training large CNN's that do not fit in the memory of a few GPU cards, or for parallelizing CNN training. In this work we show that a simple hard mixture of experts model can be efficiently trained to good effect on large scale hashtag (multilabel) prediction tasks. Mixture of experts models are not new (Jacobs et. al. 1991, Collobert et. al. 2003), but in the past, researchers have had to devise sophisticated methods to deal with data fragmentation. We show empirically that modern weakly supervised data sets are large enough to support naive partitioning schemes where each data point is assigned to a single expert. Because the experts are independent, training them in parallel is easy, and evaluation is cheap for the size of the model. Furthermore, we show that we can use a single decoding layer for all the experts, allowing a unified feature embedding space. We demonstrate that it is feasible (and in fact relatively painless) to train far larger models than could be practically trained with standard CNN architectures, and that the extra capacity can be well used on current datasets.
Training Language Models Using Target-Propagation
Feb 15, 2017



While Truncated Back-Propagation through Time (BPTT) is the most popular approach to training Recurrent Neural Networks (RNNs), it suffers from being inherently sequential (making parallelization difficult) and from truncating gradient flow between distant time-steps. We investigate whether Target Propagation (TPROP) style approaches can address these shortcomings. Unfortunately, extensive experiments suggest that TPROP generally underperforms BPTT, and we end with an analysis of this phenomenon, and suggestions for future work.
Learning through Dialogue Interactions by Asking Questions
Feb 13, 2017
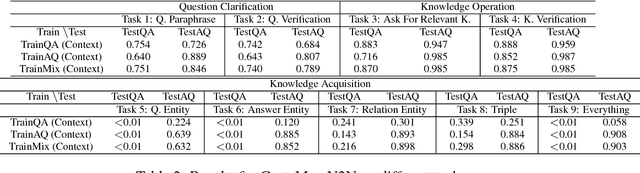

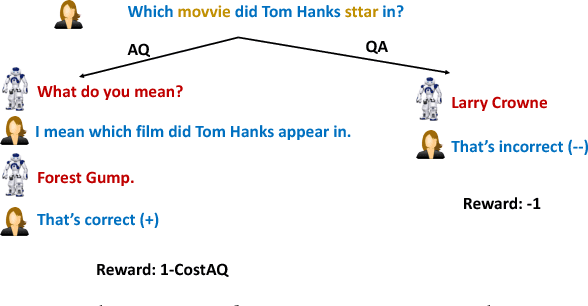
A good dialogue agent should have the ability to interact with users by both responding to questions and by asking questions, and importantly to learn from both types of interaction. In this work, we explore this direction by designing a simulator and a set of synthetic tasks in the movie domain that allow such interactions between a learner and a teacher. We investigate how a learner can benefit from asking questions in both offline and online reinforcement learning settings, and demonstrate that the learner improves when asking questions. Finally, real experiments with Mechanical Turk validate the approach. Our work represents a first step in developing such end-to-end learned interactive dialogue agents.
Dialogue Learning With Human-In-The-Loop
Jan 13, 2017
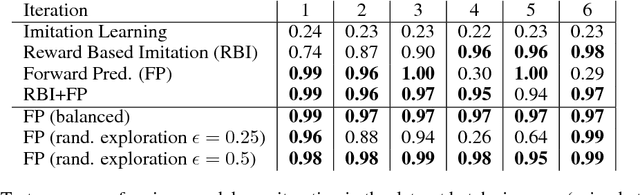
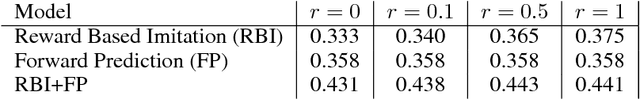
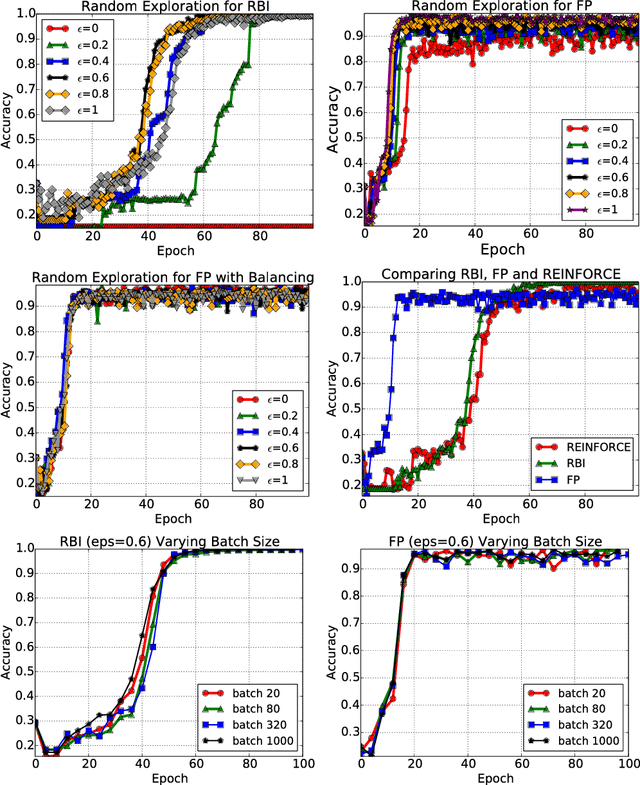
An important aspect of developing conversational agents is to give a bot the ability to improve through communicating with humans and to learn from the mistakes that it makes. Most research has focused on learning from fixed training sets of labeled data rather than interacting with a dialogue partner in an online fashion. In this paper we explore this direction in a reinforcement learning setting where the bot improves its question-answering ability from feedback a teacher gives following its generated responses. We build a simulator that tests various aspects of such learning in a synthetic environment, and introduce models that work in this regime. Finally, real experiments with Mechanical Turk validate the approach.