 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVEC 2019 Workshop and Challenge: State-of-Mind, Detecting Depression with AI, and Cross-Cultural Affect Recognition
Jul 10, 2019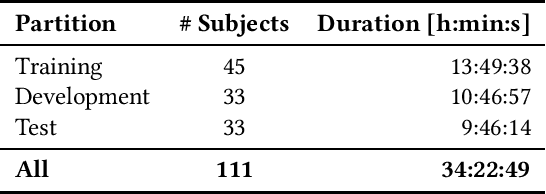
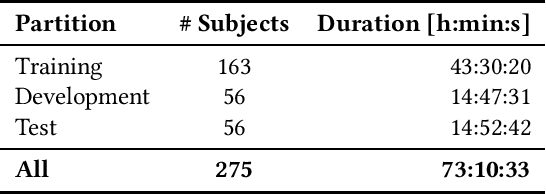
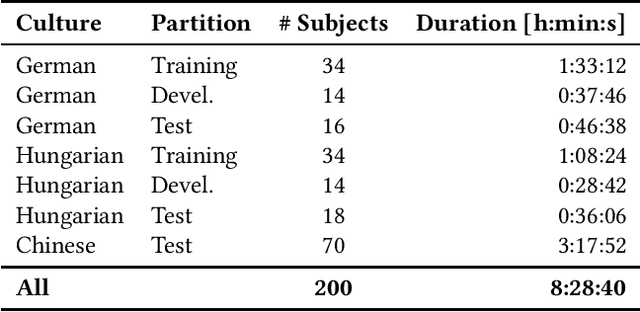
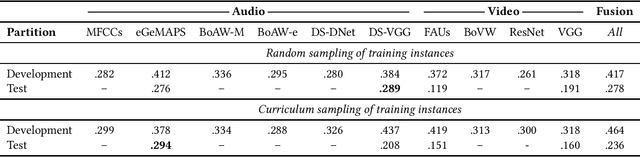
The Audio/Visual Emotion Challenge and Workshop (AVEC 2019) "State-of-Mind, Detecting Depression with AI, and Cross-cultural Affect Recognition" is the ninth competition event aimed at the comparison of multimedia processing and machine learning methods for automatic audiovisual health and emotion analysis, with all participants competing strictly under the same conditions. The goal of the Challenge is to provide a common benchmark test set for multimodal information processing and to bring together the health and emotion recognition communities, as well as the audiovisual processing communities, to compare the relative merits of various approaches to health and emotion recognition from real-life data. This paper presents the major novelties introduced this year, the challenge guidelines, the data used, and the performance of the baseline systems on the three proposed tasks: state-of-mind recognition, depression assessment with AI, and cross-cultural affect sensing, respectively.
Investigating the Lombard Effect Influence on End-to-End Audio-Visual Speech Recognition
Jul 09, 2019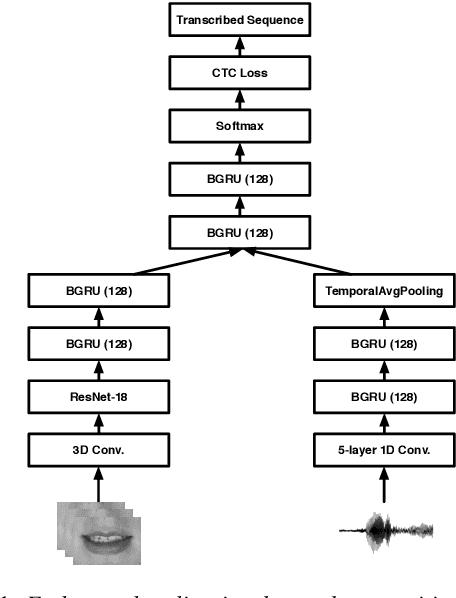

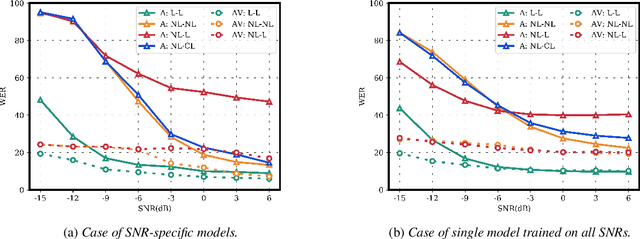
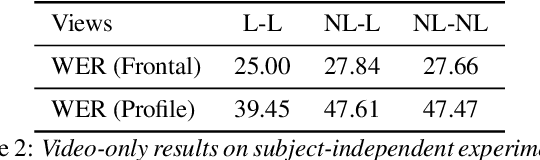
Several audio-visual speech recognition models have been recently proposed which aim to improve the robustness over audio-only models in the presence of noise. However, almost all of them ignore the impact of the Lombard effect, i.e., the change in speaking style in noisy environments which aims to make speech more intelligible and affects both the acoustic characteristics of speech and the lip movements. In this paper, we investigate the impact of the Lombard effect in audio-visual speech recognition. To the best of our knowledge, this is the first work which does so using end-to-end deep architectures and presents results on unseen speakers. Our results show that properly modelling Lombard speech is always beneficial. Even if a relatively small amount of Lombard speech is added to the training set then the performance in a real scenario, where noisy Lombard speech is present, can be significantly improved. We also show that the standard approach followed in the literature, where a model is trained and tested on noisy plain speech, provides a correct estimate of the video-only performance and slightly underestimates the audio-visual performance. In case of audio-only approaches, performance is overestimated for SNRs higher than -3dB and underestimated for lower SNRs.
Dynamic Face Video Segmentation via Reinforcement Learning
Jul 02, 2019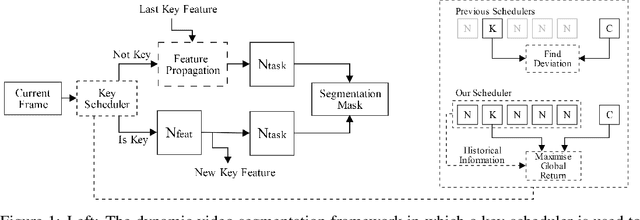
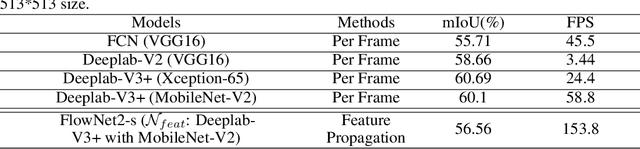
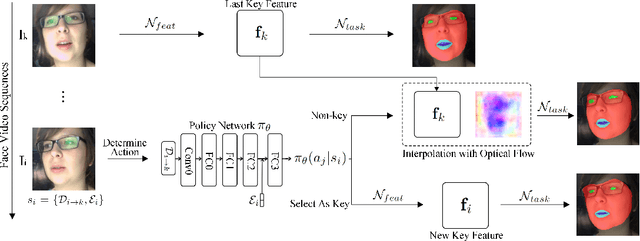
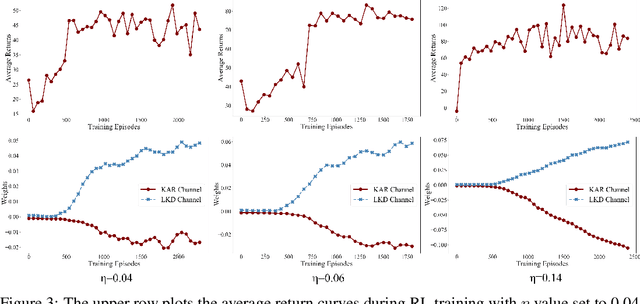
For real-time semantic video segmentation, most recent works utilise a dynamic framework with a key scheduler to make online key/non-key decisions. Some works used a fixed key scheduling policy, while others proposed adaptive key scheduling methods based on heuristic strategies, both of which may lead to suboptimal global performance. To overcome this limitation, we propose to model the online key decision process in dynamic video segmentation as a deep reinforcement learning problem, and to learn an efficient and effective scheduling policy from expert information about decision history and from the process of maximising global return. Moreover, we study the application of dynamic video segmentation on face videos, a field that has not been investigated before. By evaluating on the 300VW dataset, we show that the performance of our reinforcement key scheduler outperforms that of various baseline approaches, and our method could also achieve real-time processing speed. To the best of our knowledge, this is the first work to use reinforcement learning for online key-frame decision in dynamic video segmentation, and also the first work on its application on face videos.
Video-Driven Speech Reconstruction using Generative Adversarial Networks
Jun 14, 2019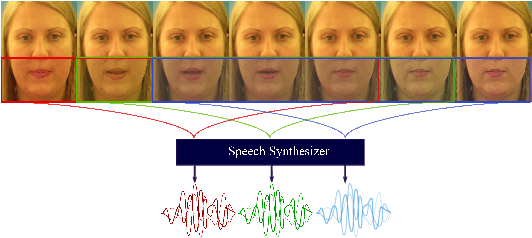

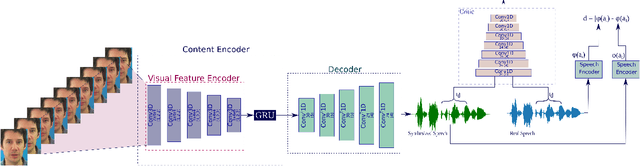
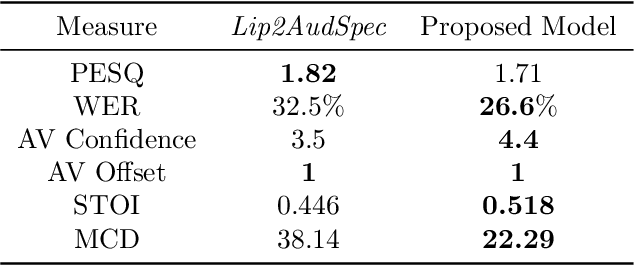
Speech is a means of communication which relies on both audio and visual information. The absence of one modality can often lead to confusion or misinterpretation of information. In this paper we present an end-to-end temporal model capable of directly synthesising audio from silent video, without needing to transform to-and-from intermediate features. Our proposed approach, based on GANs is capable of producing natural sounding, intelligible speech which is synchronised with the video. The performance of our model is evaluated on the GRID dataset for both speaker dependent and speaker independent scenarios. To the best of our knowledge this is the first method that maps video directly to raw audio and the first to produce intelligible speech when tested on previously unseen speakers. We evaluate the synthesised audio not only based on the sound quality but also on the accuracy of the spoken words.
Realistic Speech-Driven Facial Animation with GANs
Jun 14, 2019
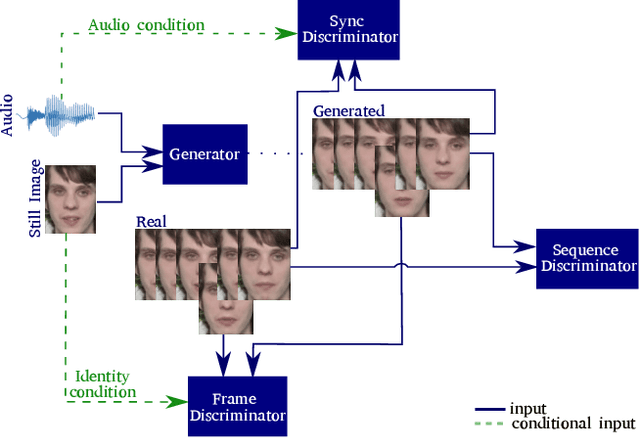
Speech-driven facial animation is the process that automatically synthesizes talking characters based on speech signals. The majority of work in this domain creates a mapping from audio features to visual features. This approach often requires post-processing using computer graphics techniques to produce realistic albeit subject dependent results. We present an end-to-end system that generates videos of a talking head, using only a still image of a person and an audio clip containing speech, without relying on handcrafted intermediate features. Our method generates videos which have (a) lip movements that are in sync with the audio and (b) natural facial expressions such as blinks and eyebrow movements. Our temporal GAN uses 3 discriminators focused on achieving detailed frames, audio-visual synchronization, and realistic expressions. We quantify the contribution of each component in our model using an ablation study and we provide insights into the latent representation of the model. The generated videos are evaluated based on sharpness, reconstruction quality, lip-reading accuracy, synchronization as well as their ability to generate natural blinks.
Efficient N-Dimensional Convolutions via Higher-Order Factorization
Jun 14, 2019

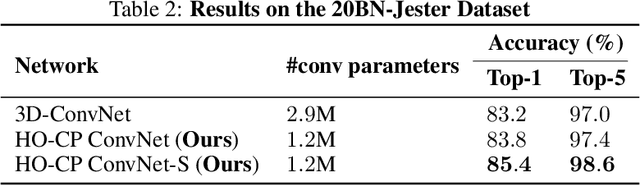
With the unprecedented success of deep convolutional neural networks came the quest for training always deeper networks. However, while deeper neural networks give better performance when trained appropriately, that depth also translates in memory and computation heavy models, typically with tens of millions of parameters. Several methods have been proposed to leverage redundancies in the network to alleviate this complexity. Either a pretrained network is compressed, e.g. using a low-rank tensor decomposition, or the architecture of the network is directly modified to be more effective. In this paper, we study both approaches in a unified framework, under the lens of tensor decompositions. We show how tensor decomposition applied to the convolutional kernel relates to efficient architectures such as MobileNet. Moreover, we propose a tensor-based method for efficient higher order convolutions, which can be used as a plugin replacement for N-dimensional convolutions. We demonstrate their advantageous properties both theoretically and empirically for image classification, for both 2D and 3D convolutional networks.
Matrix and tensor decompositions for training binary neural networks
Apr 16, 2019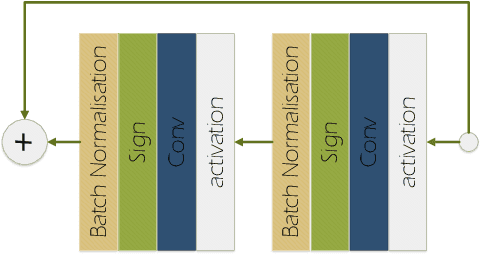
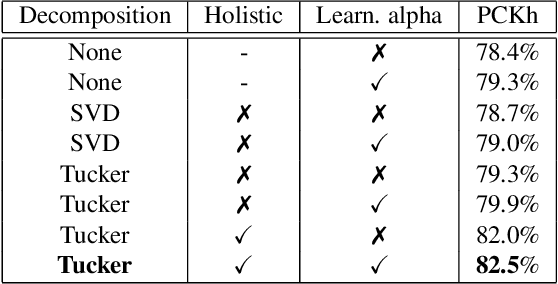
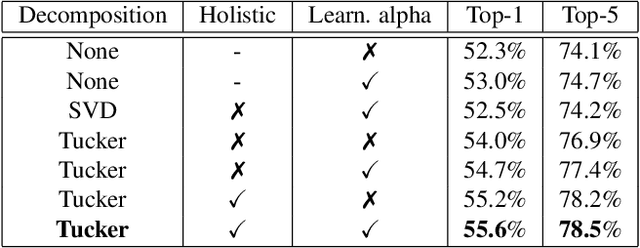
This paper is on improving the training of binary neural networks in which both activations and weights are binary. While prior methods for neural network binarization binarize each filter independently, we propose to instead parametrize the weight tensor of each layer using matrix or tensor decomposition. The binarization process is then performed using this latent parametrization, via a quantization function (e.g. sign function) applied to the reconstructed weights. A key feature of our method is that while the reconstruction is binarized, the computation in the latent factorized space is done in the real domain. This has several advantages: (i) the latent factorization enforces a coupling of the filters before binarization, which significantly improves the accuracy of the trained models. (ii) while at training time, the binary weights of each convolutional layer are parametrized using real-valued matrix or tensor decomposition, during inference we simply use the reconstructed (binary) weights. As a result, our method does not sacrifice any advantage of binary networks in terms of model compression and speeding-up inference. As a further contribution, instead of computing the binary weight scaling factors analytically, as in prior work, we propose to learn them discriminatively via back-propagation. Finally, we show that our approach significantly outperforms existing methods when tested on the challenging tasks of (a) human pose estimation (more than 4% improvements) and (b) ImageNet classification (up to 5% performance gains).
Incremental multi-domain learning with network latent tensor factorization
Apr 12, 2019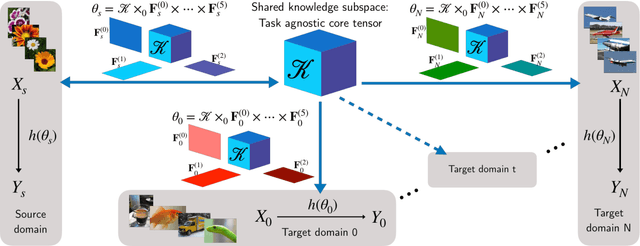
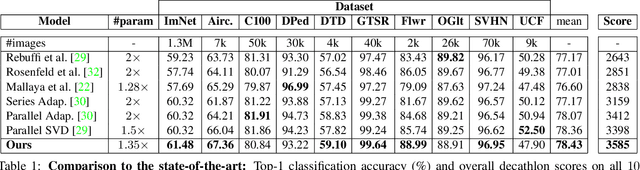

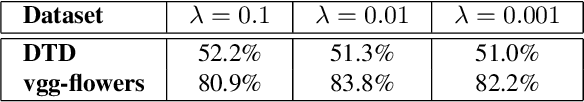
The prominence of deep learning, large amount of annotated data and increasingly powerful hardware made it possible to reach remarkable performance for supervised classification tasks, in many cases saturating the training sets. However, adapting the learned classification to new domains remains a hard problem due to at least three reasons: (1) the domains and the tasks might be drastically different; (2) there might be very limited amount of annotated data on the new domain and (3) full training of a new model for each new task is prohibitive in terms of memory, due to the shear number of parameter of deep networks. Instead, new tasks should be learned incrementally, building on prior knowledge from already learned tasks, and without catastrophic forgetting, i.e. without hurting performance on prior tasks. To our knowledge this paper presents the first method for multi-domain/task learning without catastrophic forgetting using a fully tensorized architecture. Our main contribution is a method for multi-domain learning which models groups of identically structured blocks within a CNN as a high-order tensor. We show that this joint modelling naturally leverages correlations across different layers and results in more compact representations for each new task/domain over previous methods which have focused on adapting each layer separately. We apply the proposed method to 10 datasets of the Visual Decathlon Challenge and show that our method offers on average about 7.5x reduction in number of parameters and superior performance in terms of both classification accuracy and Decathlon score. In particular, our method outperforms all prior work on the Visual Decathlon Challenge.
Improved training of binary networks for human pose estimation and image recognition
Apr 11, 2019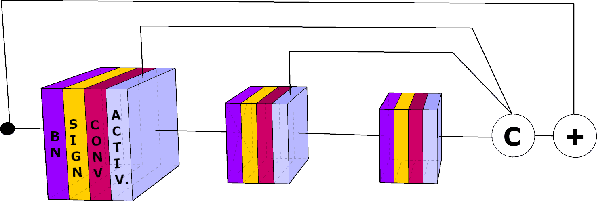
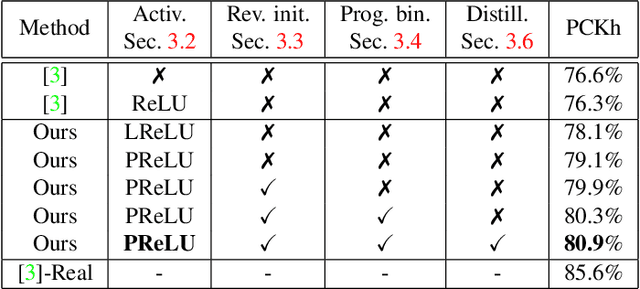

Big neural networks trained on large datasets have advanced the state-of-the-art for a large variety of challenging problems, improving performance by a large margin. However, under low memory and limited computational power constraints, the accuracy on the same problems drops considerable. In this paper, we propose a series of techniques that significantly improve the accuracy of binarized neural networks (i.e networks where both the features and the weights are binary). We evaluate the proposed improvements on two diverse tasks: fine-grained recognition (human pose estimation) and large-scale image recognition (ImageNet classification). Specifically, we introduce a series of novel methodological changes including: (a) more appropriate activation functions, (b) reverse-order initialization, (c) progressive quantization, and (d) network stacking and show that these additions improve existing state-of-the-art network binarization techniques, significantly. Additionally, for the first time, we also investigate the extent to which network binarization and knowledge distillation can be combined. When tested on the challenging MPII dataset, our method shows a performance improvement of more than 4% in absolute terms. Finally, we further validate our findings by applying the proposed techniques for large-scale object recognition on the Imagenet dataset, on which we report a reduction of error rate by 4%.
T-Net: Parametrizing Fully Convolutional Nets with a Single High-Order Tensor
Apr 04, 2019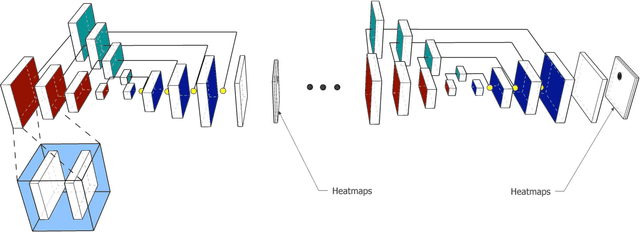
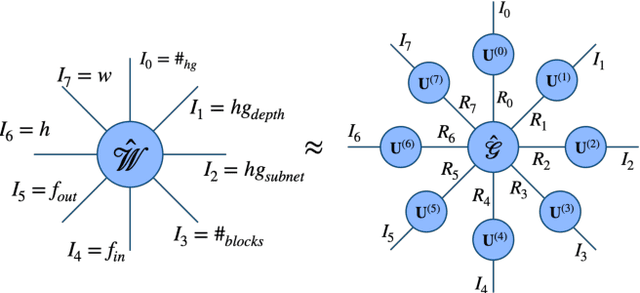
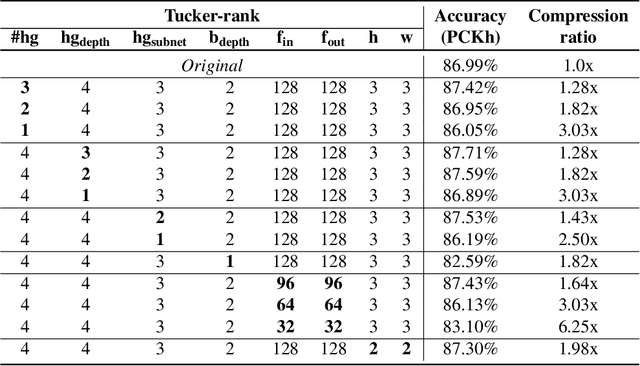
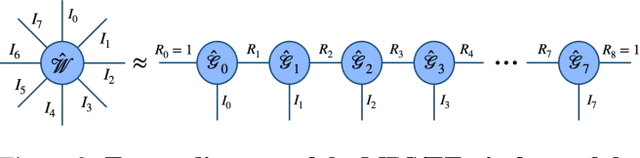
Recent findings indicate that over-parametrization, while crucial for successfully training deep neural networks, also introduces large amounts of redundancy. Tensor methods have the potential to efficiently parametrize over-complete representations by leveraging this redundancy. In this paper, we propose to fully parametrize Convolutional Neural Networks (CNNs) with a single high-order, low-rank tensor. Previous works on network tensorization have focused on parametrizing individual layers (convolutional or fully connected) only, and perform the tensorization layer-by-layer separately. In contrast, we propose to jointly capture the full structure of a neural network by parametrizing it with a single high-order tensor, the modes of which represent each of the architectural design parameters of the network (e.g. number of convolutional blocks, depth, number of stacks, input features, etc). This parametrization allows to regularize the whole network and drastically reduce the number of parameters. Our model is end-to-end trainable and the low-rank structure imposed on the weight tensor acts as an implicit regularization. We study the case of networks with rich structure, namely Fully Convolutional Networks (FCNs), which we propose to parametrize with a single 8th-order tensor. We show that our approach can achieve superior performance with small compression rates, and attain high compression rates with negligible drop in accuracy for the challenging task of human pose estimation.