 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Video-centralised Transformer for Video Face Clustering
Mar 24, 2022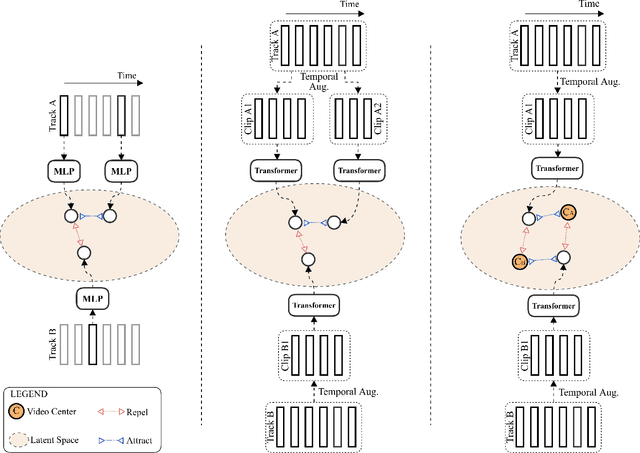

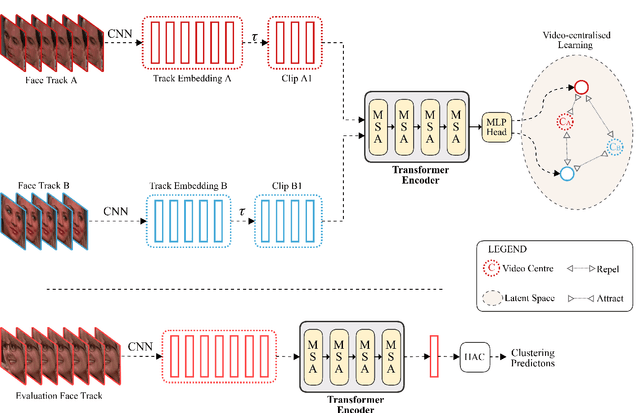
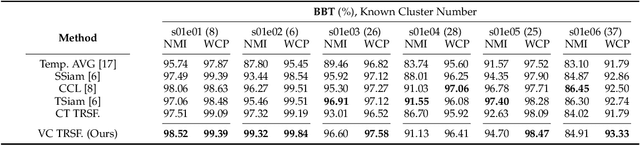
This paper presents a novel method for face clustering in videos using a video-centralised transformer. Previous works often employed contrastive learning to learn frame-level representation and used average pooling to aggregate the features along the temporal dimension. This approach may not fully capture the complicated video dynamics. In addition, despite the recent progress in video-based contrastive learning, few have attempted to learn a self-supervised clustering-friendly face representation that benefits the video face clustering task. To overcome these limitations, our method employs a transformer to directly learn video-level representations that can better reflect the temporally-varying property of faces in videos, while we also propose a video-centralised self-supervised framework to train the transformer model. We also investigate face clustering in egocentric videos, a fast-emerging field that has not been studied yet in works related to face clustering. To this end, we present and release the first large-scale egocentric video face clustering dataset named EasyCom-Clustering. We evaluate our proposed method on both the widely used Big Bang Theory (BBT) dataset and the new EasyCom-Clustering dataset. Results show the performance of our video-centralised transformer has surpassed all previous state-of-the-art methods on both benchmarks, exhibiting a self-attentive understanding of face videos.
Visual Speech Recognition for Multiple Languages in the Wild
Feb 26, 2022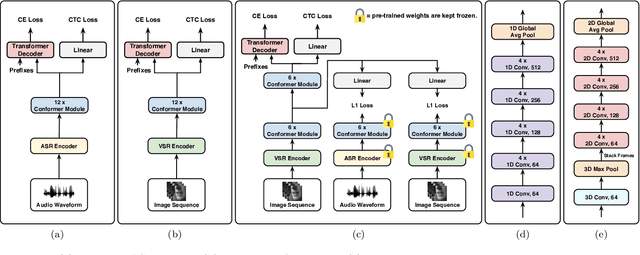
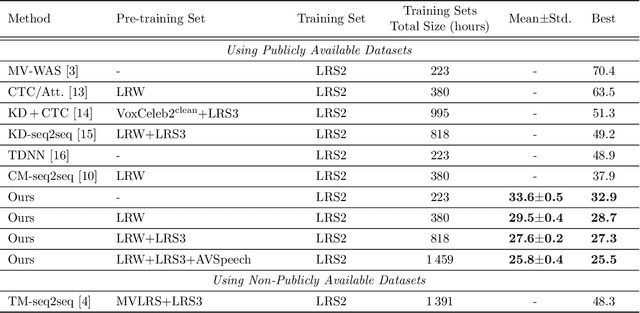
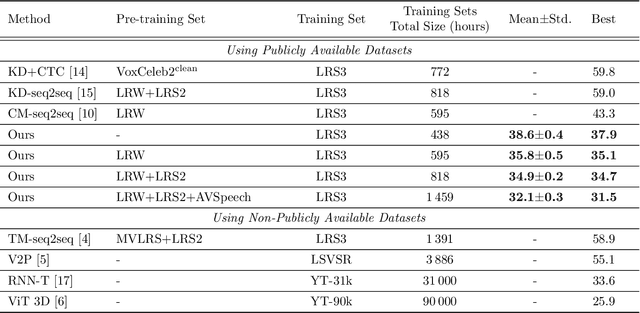
Visual speech recognition (VSR) aims to recognise the content of speech based on the lip movements without relying on the audio stream. Advances in deep learning and the availability of large audio-visual datasets have led to the development of much more accurate and robust VSR models than ever before. However, these advances are usually due to larger training sets rather than the model design. In this work, we demonstrate that designing better models is equally important to using larger training sets. We propose the addition of prediction-based auxiliary tasks to a VSR model and highlight the importance of hyper-parameter optimisation and appropriate data augmentations. We show that such model works for different languages and outperforms all previous methods trained on publicly available datasets by a large margin. It even outperforms models that were trained on non-publicly available datasets containing up to to 21 times more data. We show furthermore that using additional training data, even in other languages or with automatically generated transcriptions, results in further improvement.
Leveraging Real Talking Faces via Self-Supervision for Robust Forgery Detection
Jan 18, 2022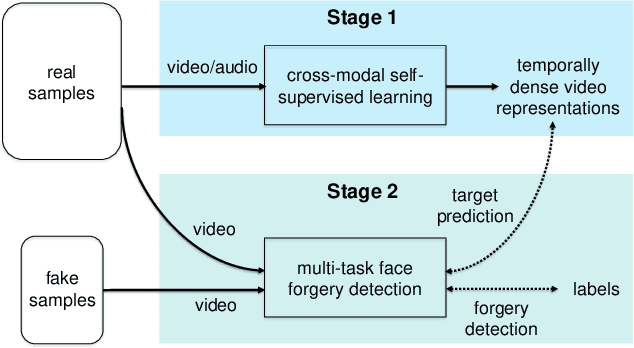
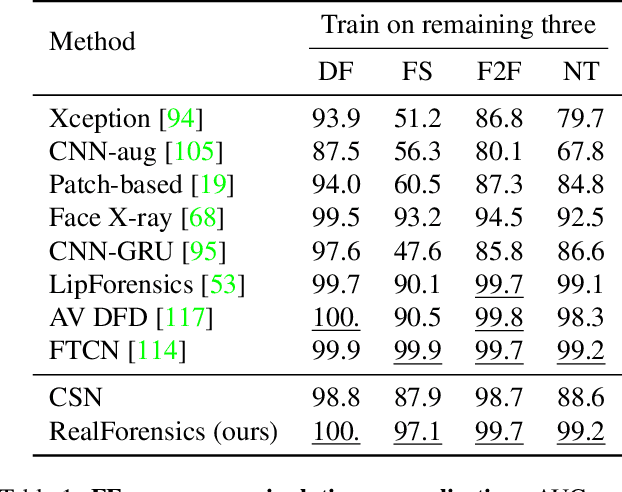

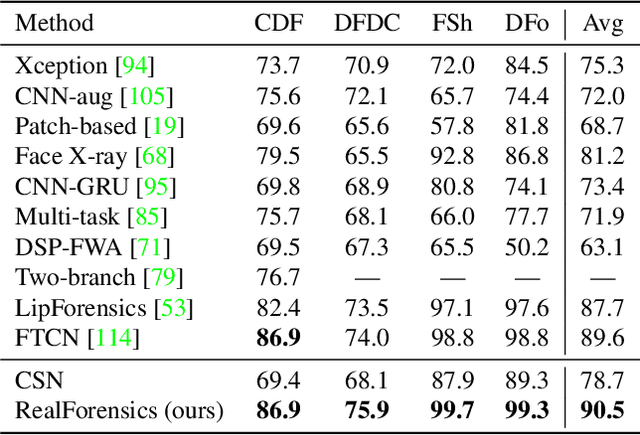
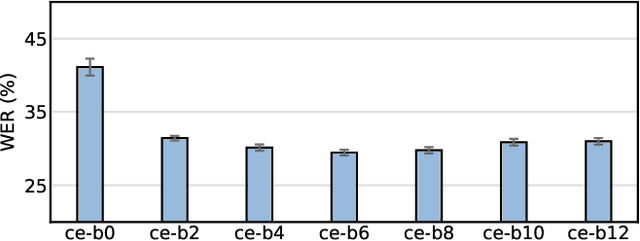
One of the most pressing challenges for the detection of face-manipulated videos is generalising to forgery methods not seen during training while remaining effective under common corruptions such as compression. In this paper, we question whether we can tackle this issue by harnessing videos of real talking faces, which contain rich information on natural facial appearance and behaviour and are readily available in large quantities online. Our method, termed RealForensics, consists of two stages. First, we exploit the natural correspondence between the visual and auditory modalities in real videos to learn, in a self-supervised cross-modal manner, temporally dense video representations that capture factors such as facial movements, expression, and identity. Second, we use these learned representations as targets to be predicted by our forgery detector along with the usual binary forgery classification task; this encourages it to base its real/fake decision on said factors. We show that our method achieves state-of-the-art performance on cross-manipulation generalisation and robustness experiments, and examine the factors that contribute to its performance. Our results suggest that leveraging natural and unlabelled videos is a promising direction for the development of more robust face forgery detectors.
Defensive Tensorization
Oct 26, 2021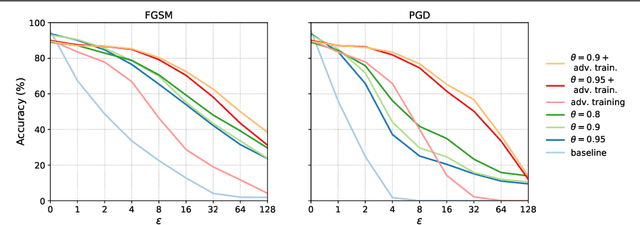
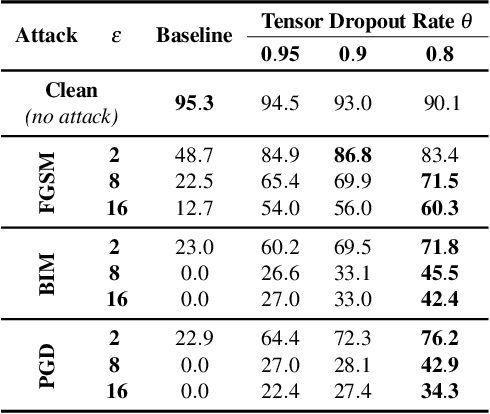
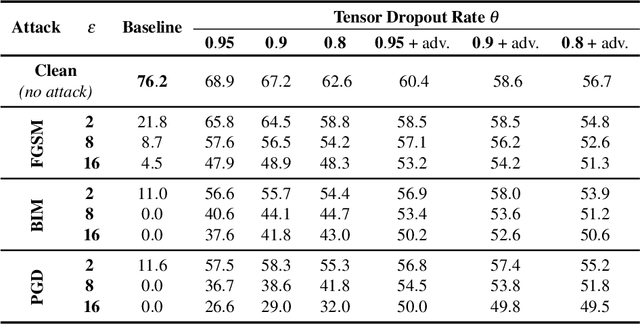
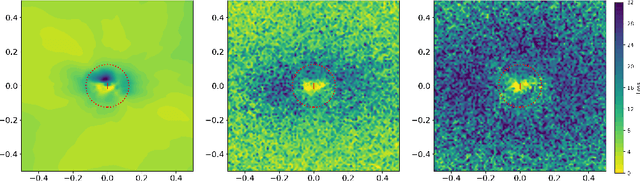
We propose defensive tensorization, an adversarial defence technique that leverages a latent high-order factorization of the network. The layers of a network are first expressed as factorized tensor layers. Tensor dropout is then applied in the latent subspace, therefore resulting in dense reconstructed weights, without the sparsity or perturbations typically induced by the randomization.Our approach can be readily integrated with any arbitrary neural architecture and combined with techniques like adversarial training. We empirically demonstrate the effectiveness of our approach on standard image classification benchmarks. We validate the versatility of our approach across domains and low-precision architectures by considering an audio classification task and binary networks. In all cases, we demonstrate improved performance compared to prior works.
Domain Generalisation for Apparent Emotional Facial Expression Recognition across Age-Groups
Oct 18, 2021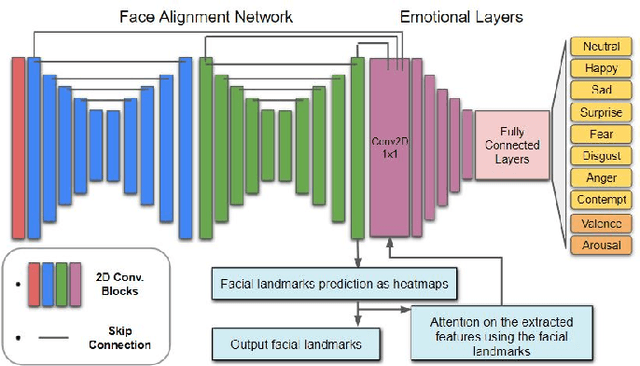
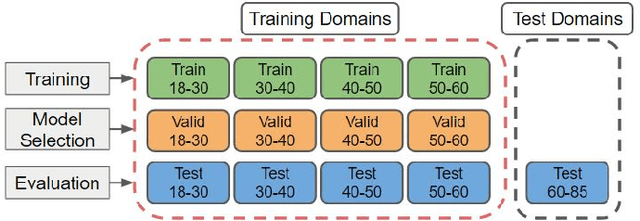
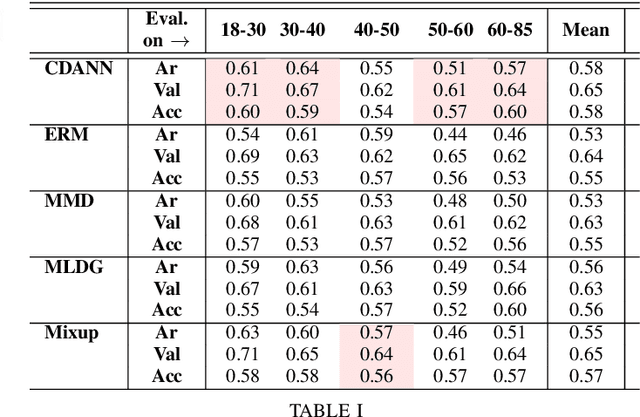
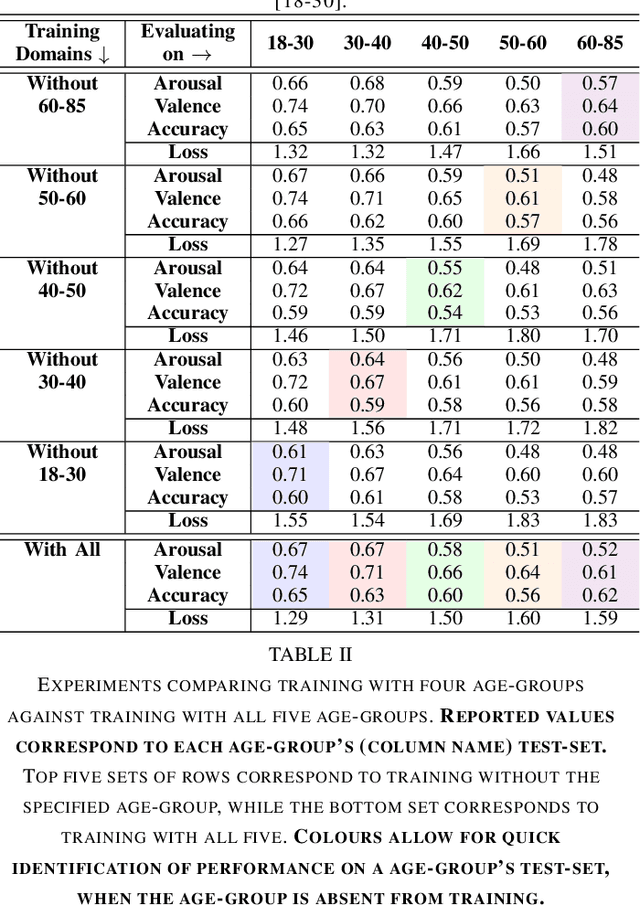
Apparent emotional facial expression recognition has attracted a lot of research attention recently. However, the majority of approaches ignore age differences and train a generic model for all ages. In this work, we study the effect of using different age-groups for training apparent emotional facial expression recognition models. To this end, we study Domain Generalisation in the context of apparent emotional facial expression recognition from facial imagery across different age groups. We first compare several domain generalisation algorithms on the basis of out-of-domain-generalisation, and observe that the Class-Conditional Domain-Adversarial Neural Networks (CDANN) algorithm has the best performance. We then study the effect of variety and number of age-groups used during training on generalisation to unseen age-groups and observe that an increase in the number of training age-groups tends to increase the apparent emotional facial expression recognition performance on unseen age-groups. We also show that exclusion of an age-group during training tends to affect more the performance of the neighbouring age groups.
EasyCom: An Augmented Reality Dataset to Support Algorithms for Easy Communication in Noisy Environments
Jul 09, 2021

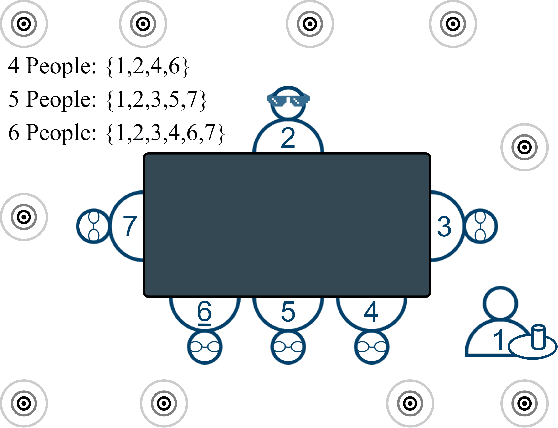
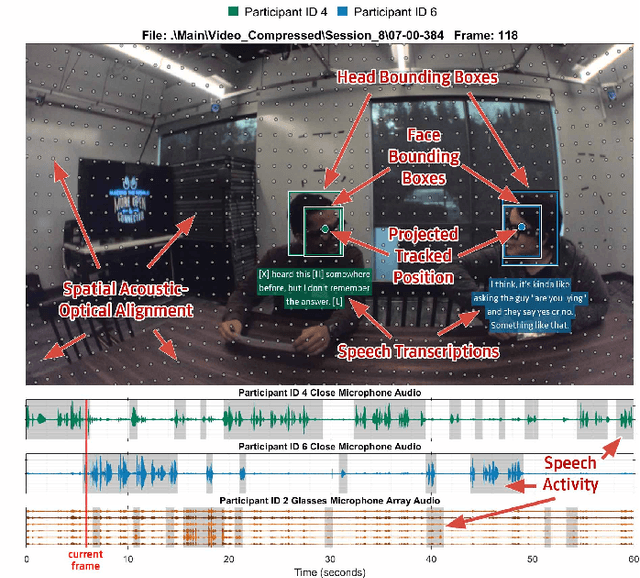
Augmented Reality (AR) as a platform has the potential to facilitate the reduction of the cocktail party effect. Future AR headsets could potentially leverage information from an array of sensors spanning many different modalities. Training and testing signal processing and machine learning algorithms on tasks such as beam-forming and speech enhancement require high quality representative data. To the best of the author's knowledge, as of publication there are no available datasets that contain synchronized egocentric multi-channel audio and video with dynamic movement and conversations in a noisy environment. In this work, we describe, evaluate and release a dataset that contains over 5 hours of multi-modal data useful for training and testing algorithms for the application of improving conversations for an AR glasses wearer. We provide speech intelligibility, quality and signal-to-noise ratio improvement results for a baseline method and show improvements across all tested metrics. The dataset we are releasing contains AR glasses egocentric multi-channel microphone array audio, wide field-of-view RGB video, speech source pose, headset microphone audio, annotated voice activity, speech transcriptions, head bounding boxes, target of speech and source identification labels. We have created and are releasing this dataset to facilitate research in multi-modal AR solutions to the cocktail party problem.
FP-Age: Leveraging Face Parsing Attention for Facial Age Estimation in the Wild
Jun 21, 2021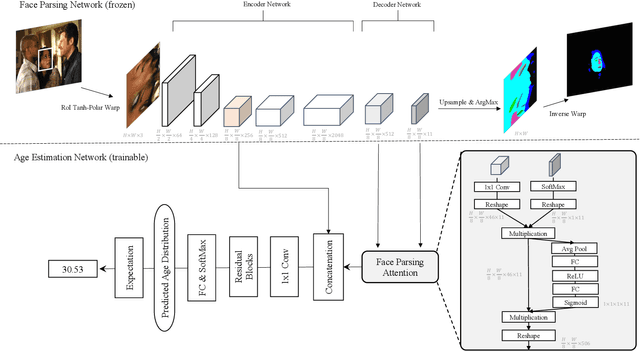
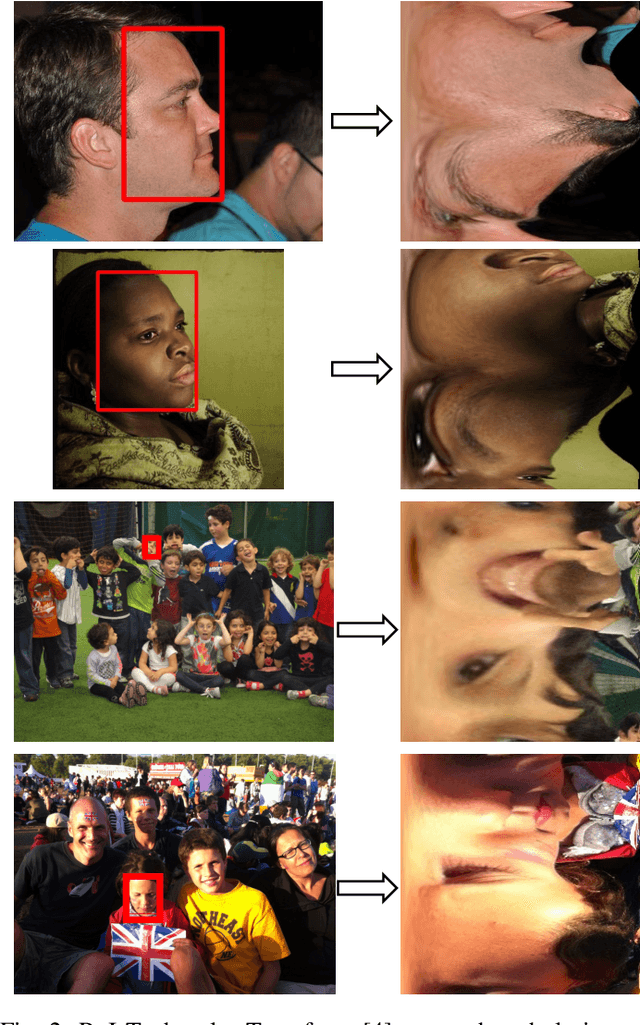

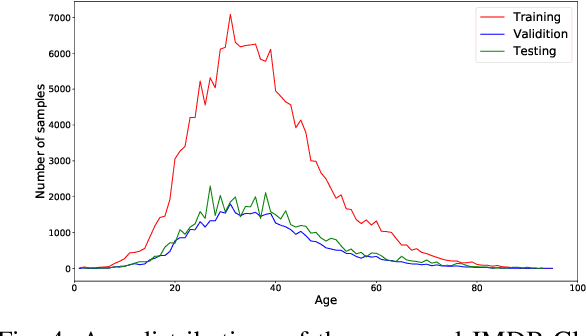
Image-based age estimation aims to predict a person's age from facial images. It is used in a variety of real-world applications. Although end-to-end deep models have achieved impressive results for age estimation on benchmark datasets, their performance in-the-wild still leaves much room for improvement due to the challenges caused by large variations in head pose, facial expressions, and occlusions. To address this issue, we propose a simple yet effective method to explicitly incorporate facial semantics into age estimation, so that the model would learn to correctly focus on the most informative facial components from unaligned facial images regardless of head pose and non-rigid deformation. To this end, we design a face parsing-based network to learn semantic information at different scales and a novel face parsing attention module to leverage these semantic features for age estimation. To evaluate our method on in-the-wild data, we also introduce a new challenging large-scale benchmark called IMDB-Clean. This dataset is created by semi-automatically cleaning the noisy IMDB-WIKI dataset using a constrained clustering method. Through comprehensive experiment on IMDB-Clean and other benchmark datasets, under both intra-dataset and cross-dataset evaluation protocols, we show that our method consistently outperforms all existing age estimation methods and achieves a new state-of-the-art performance. To the best of our knowledge, our work presents the first attempt of leveraging face parsing attention to achieve semantic-aware age estimation, which may be inspiring to other high level facial analysis tasks.
LiRA: Learning Visual Speech Representations from Audio through Self-supervision
Jun 16, 2021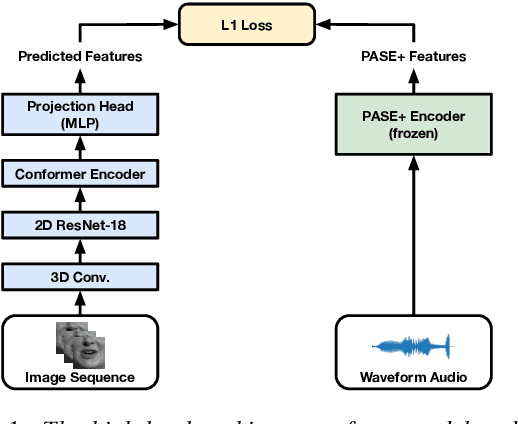
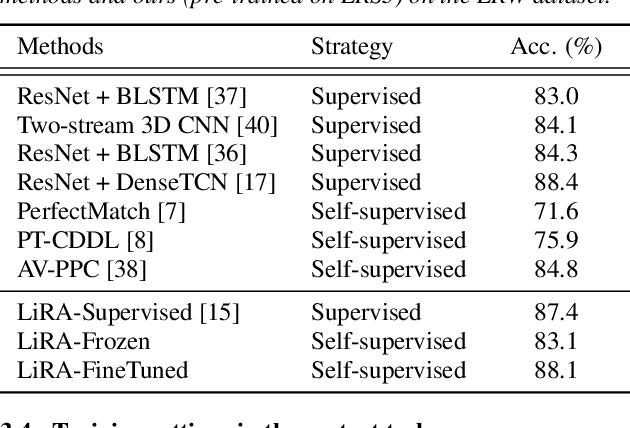
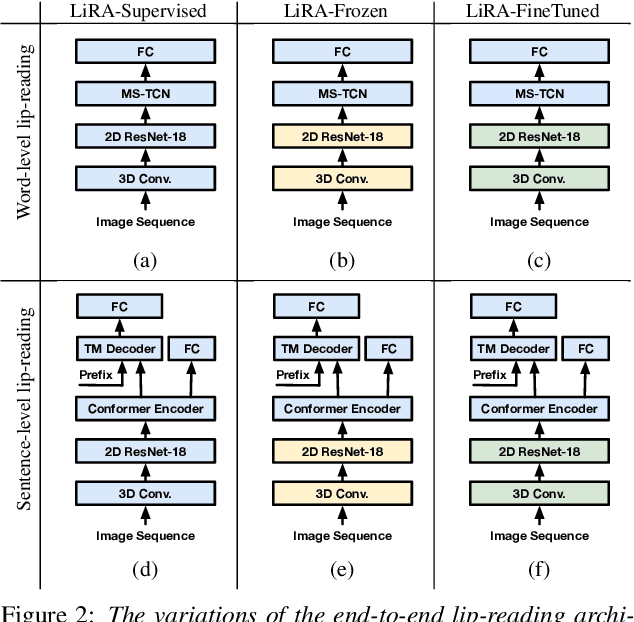
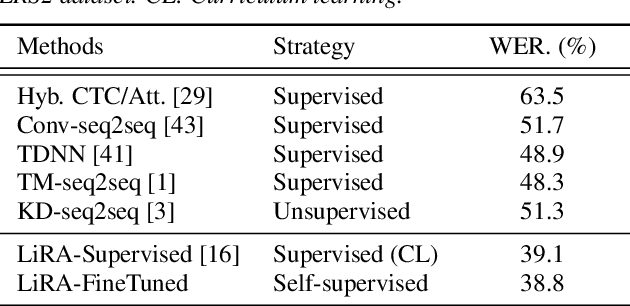
The large amount of audiovisual content being shared online today has drawn substantial attention to the prospect of audiovisual self-supervised learning. Recent works have focused on each of these modalities separately, while others have attempted to model both simultaneously in a cross-modal fashion. However, comparatively little attention has been given to leveraging one modality as a training objective to learn from the other. In this work, we propose Learning visual speech Representations from Audio via self-supervision (LiRA). Specifically, we train a ResNet+Conformer model to predict acoustic features from unlabelled visual speech. We find that this pre-trained model can be leveraged towards word-level and sentence-level lip-reading through feature extraction and fine-tuning experiments. We show that our approach significantly outperforms other self-supervised methods on the Lip Reading in the Wild (LRW) dataset and achieves state-of-the-art performance on Lip Reading Sentences 2 (LRS2) using only a fraction of the total labelled data.
End-to-End Video-To-Speech Synthesis using Generative Adversarial Networks
Apr 30, 2021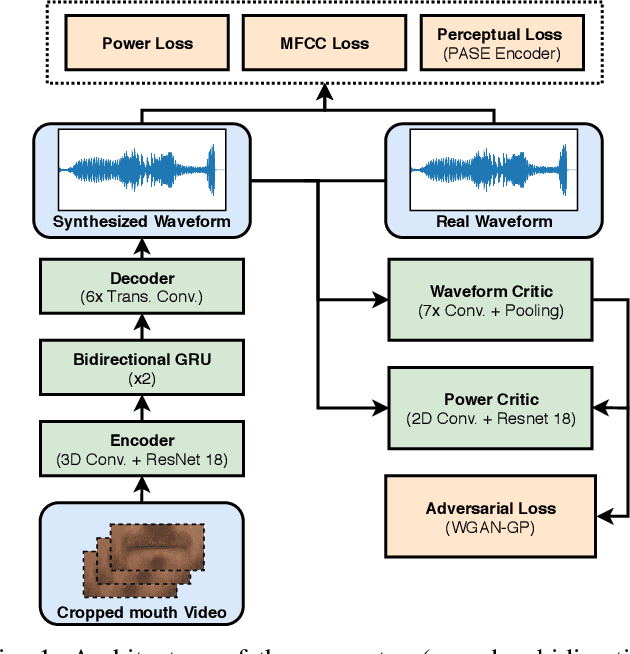
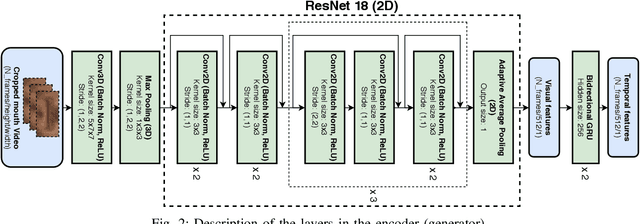
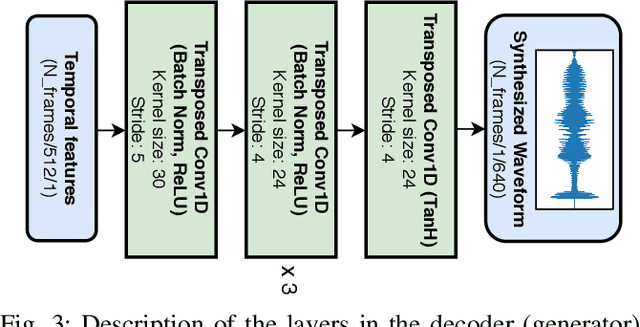
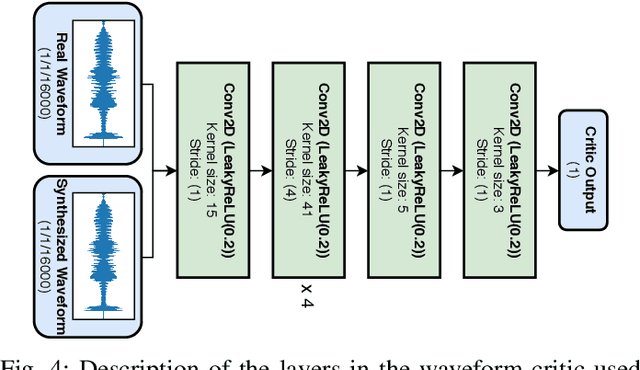
Video-to-speech is the process of reconstructing the audio speech from a video of a spoken utterance. Previous approaches to this task have relied on a two-step process where an intermediate representation is inferred from the video, and is then decoded into waveform audio using a vocoder or a waveform reconstruction algorithm. In this work, we propose a new end-to-end video-to-speech model based on Generative Adversarial Networks (GANs) which translates spoken video to waveform end-to-end without using any intermediate representation or separate waveform synthesis algorithm. Our model consists of an encoder-decoder architecture that receives raw video as input and generates speech, which is then fed to a waveform critic and a power critic. The use of an adversarial loss based on these two critics enables the direct synthesis of raw audio waveform and ensures its realism. In addition, the use of our three comparative losses helps establish direct correspondence between the generated audio and the input video. We show that this model is able to reconstruct speech with remarkable realism for constrained datasets such as GRID, and that it is the first end-to-end model to produce intelligible speech for LRW (Lip Reading in the Wild), featuring hundreds of speakers recorded entirely `in the wild'. We evaluate the generated samples in two different scenarios -- seen and unseen speakers -- using four objective metrics which measure the quality and intelligibility of artificial speech. We demonstrate that the proposed approach outperforms all previous works in most metrics on GRID and LRW.
DINO: A Conditional Energy-Based GAN for Domain Translation
Feb 18, 2021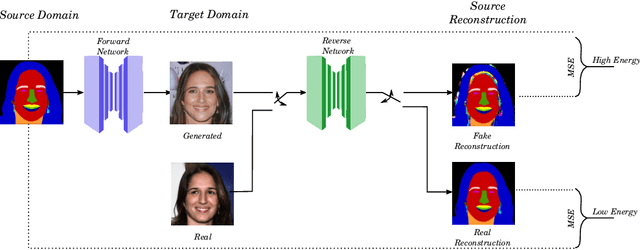

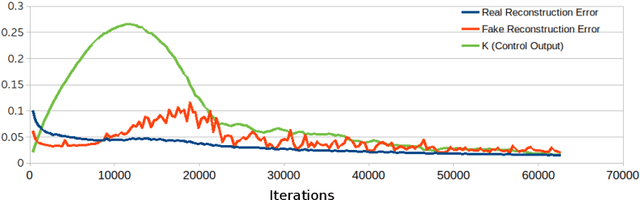
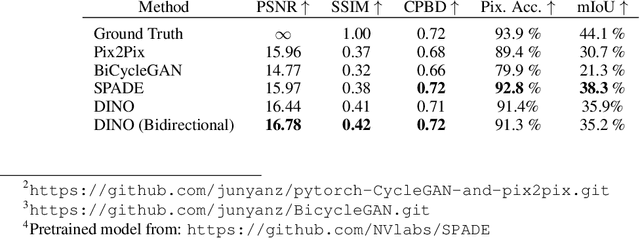
Domain translation is the process of transforming data from one domain to another while preserving the common semantics. Some of the most popular domain translation systems are based on conditional generative adversarial networks, which use source domain data to drive the generator and as an input to the discriminator. However, this approach does not enforce the preservation of shared semantics since the conditional input can often be ignored by the discriminator. We propose an alternative method for conditioning and present a new framework, where two networks are simultaneously trained, in a supervised manner, to perform domain translation in opposite directions. Our method is not only better at capturing the shared information between two domains but is more generic and can be applied to a broader range of problems. The proposed framework performs well even in challenging cross-modal translations, such as video-driven speech reconstruction, for which other systems struggle to maintain correspondence.