 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL-SeqSleepNet: Whole-cycle Long Sequence Modelling for Automatic Sleep Staging
Jan 25, 2023



Human sleep is cyclical with a period of approximately 90 minutes, implying long temporal dependency in the sleep data. Yet, exploring this long-term dependency when developing sleep staging models has remained untouched. In this work, we show that while encoding the logic of a whole sleep cycle is crucial to improve sleep staging performance, the sequential modelling approach in existing state-of-the-art deep learning models are inefficient for that purpose. We thus introduce a method for efficient long sequence modelling and propose a new deep learning model, L-SeqSleepNet, which takes into account whole-cycle sleep information for sleep staging. Evaluating L-SeqSleepNet on four distinct databases of various sizes, we demonstrate state-of-the-art performance obtained by the model over three different EEG setups, including scalp EEG in conventional Polysomnography (PSG), in-ear EEG, and around-the-ear EEG (cEEGrid), even with a single EEG channel input. Our analyses also show that L-SeqSleepNet is able to alleviate the predominance of N2 sleep (the major class in terms of classification) to bring down errors in other sleep stages. Moreover the network becomes much more robust, meaning that for all subjects where the baseline method had exceptionally poor performance, their performance are improved significantly. Finally, the computation time only grows at a sub-linear rate when the sequence length increases.
EventNet: Detecting Events in EEG
Sep 22, 2022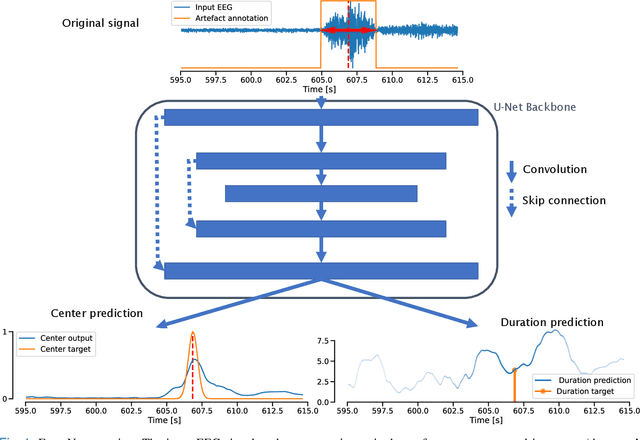
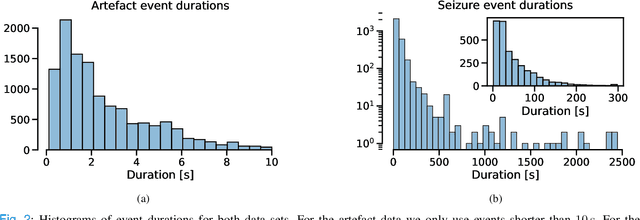
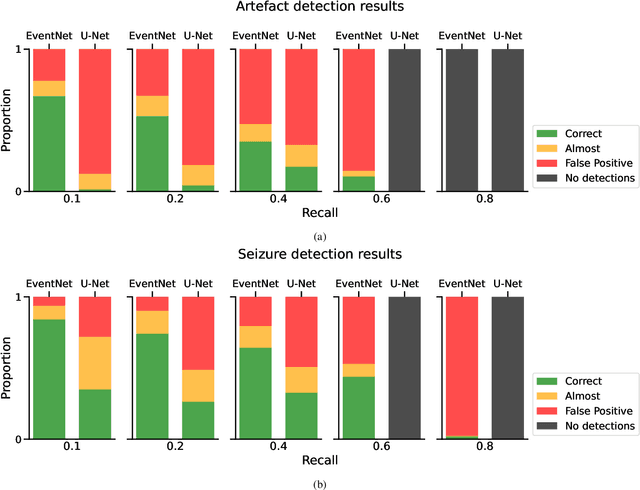
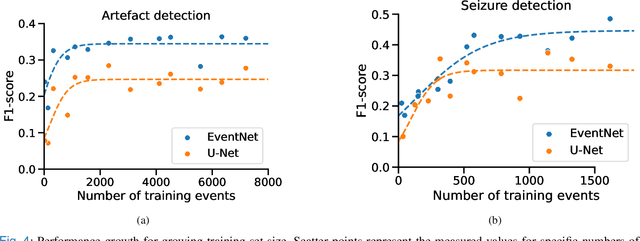
Neurologists are often looking for various "events of interest" when analyzing EEG. To support them in this task various machine-learning-based algorithms have been developed. Most of these algorithms treat the problem as classification, thereby independently processing signal segments and ignoring temporal dependencies inherent to events of varying duration. At inference time, the predicted labels for each segment then have to be post processed to detect the actual events. We propose an end-to-end event detection approach (EventNet), based on deep learning, that directly works with events as learning targets, stepping away from ad-hoc postprocessing schemes to turn model outputs into events. We compare EventNet with a state-of-the-art approach for artefact and and epileptic seizure detection, two event types with highly variable durations. EventNet shows improved performance in detecting both event types. These results show the power of treating events as direct learning targets, instead of using ad-hoc postprocessing to obtain them. Our event detection framework can easily be extended to other event detection problems in signal processing, since the deep learning backbone does not depend on any task-specific features.
Feature matching as improved transfer learning technique for wearable EEG
Dec 29, 2021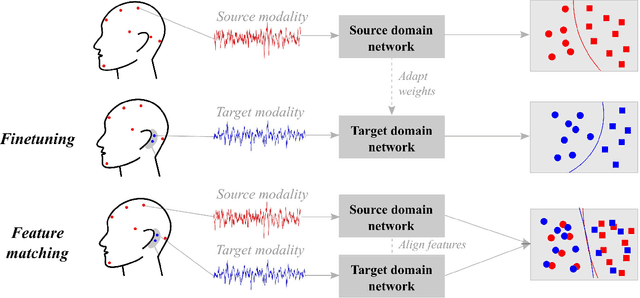
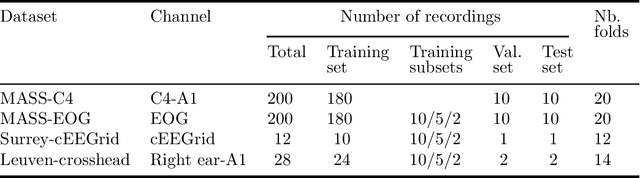
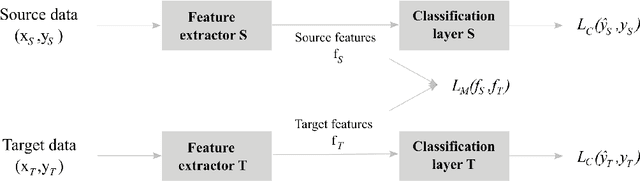
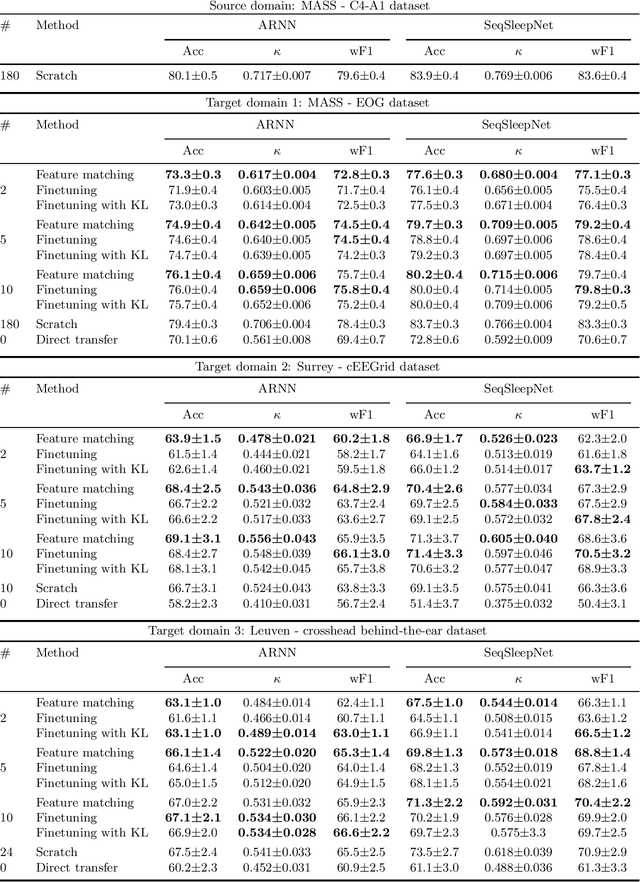
Objective: With the rapid rise of wearable sleep monitoring devices with non-conventional electrode configurations, there is a need for automated algorithms that can perform sleep staging on configurations with small amounts of labeled data. Transfer learning has the ability to adapt neural network weights from a source modality (e.g. standard electrode configuration) to a new target modality (e.g. non-conventional electrode configuration). Methods: We propose feature matching, a new transfer learning strategy as an alternative to the commonly used finetuning approach. This method consists of training a model with larger amounts of data from the source modality and few paired samples of source and target modality. For those paired samples, the model extracts features of the target modality, matching these to the features from the corresponding samples of the source modality. Results: We compare feature matching to finetuning for three different target domains, with two different neural network architectures, and with varying amounts of training data. Particularly on small cohorts (i.e. 2 - 5 labeled recordings in the non-conventional recording setting), feature matching systematically outperforms finetuning with mean relative differences in accuracy ranging from 0.4% to 4.7% for the different scenarios and datasets. Conclusion: Our findings suggest that feature matching outperforms finetuning as a transfer learning approach, especially in very low data regimes. Significance: As such, we conclude that feature matching is a promising new method for wearable sleep staging with novel devices.
SleepTransformer: Automatic Sleep Staging with Interpretability and Uncertainty Quantification
May 23, 2021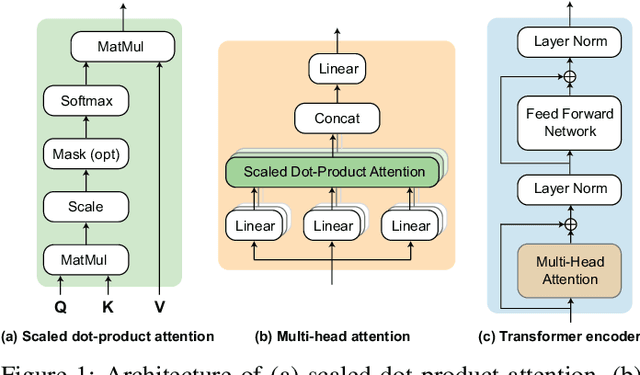
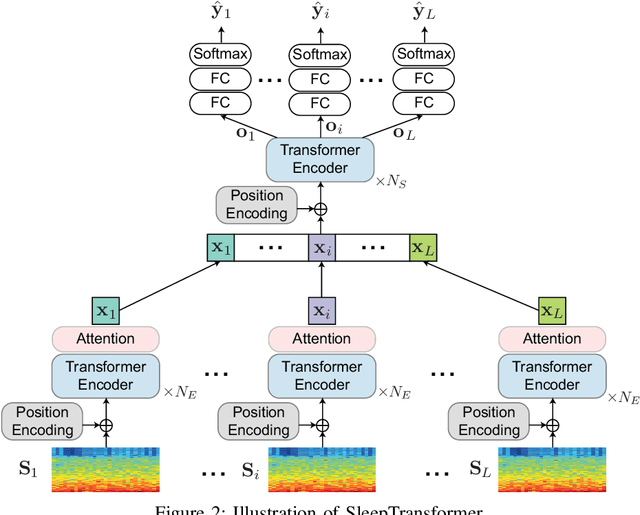
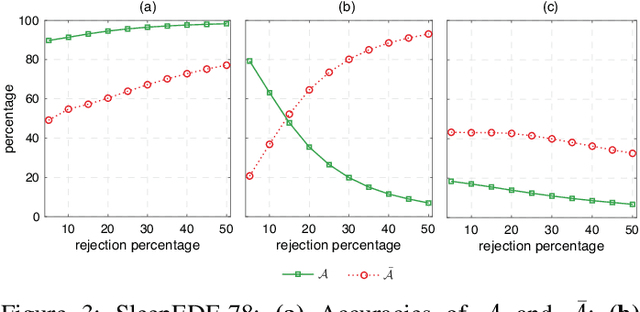
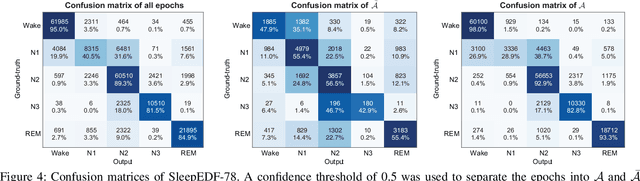
Black-box skepticism is one of the main hindrances impeding deep-learning-based automatic sleep scoring from being used in clinical environments. Towards interpretability, this work proposes a sequence-to-sequence sleep-staging model, namely SleepTransformer. It is based on the transformer backbone whose self-attention scores offer interpretability of the model's decisions at both the epoch and sequence level. At the epoch level, the attention scores can be encoded as a heat map to highlight sleep-relevant features captured from the input EEG signal. At the sequence level, the attention scores are visualized as the influence of different neighboring epochs in an input sequence (i.e. the context) to recognition of a target epoch, mimicking the way manual scoring is done by human experts. We further propose a simple yet efficient method to quantify uncertainty in the model's decisions. The method, which is based on entropy, can serve as a metric for deferring low-confidence epochs to a human expert for further inspection. Additionally, we demonstrate that the proposed SleepTransformer outperforms existing methods at a lower computational cost and achieves state-of-the-art performance on two experimental databases of different sizes.
Interpretable Deep Learning for the Remote Characterisation of Ambulation in Multiple Sclerosis using Smartphones
Mar 16, 2021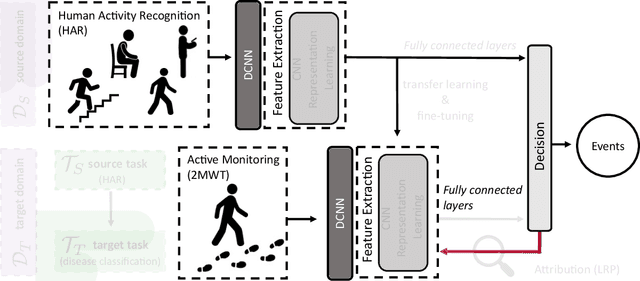
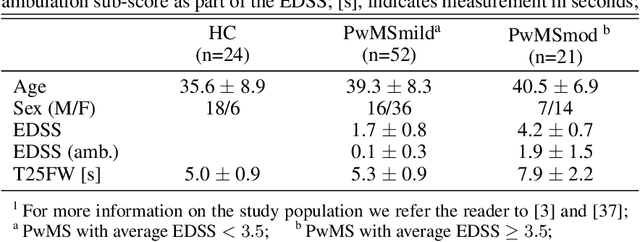
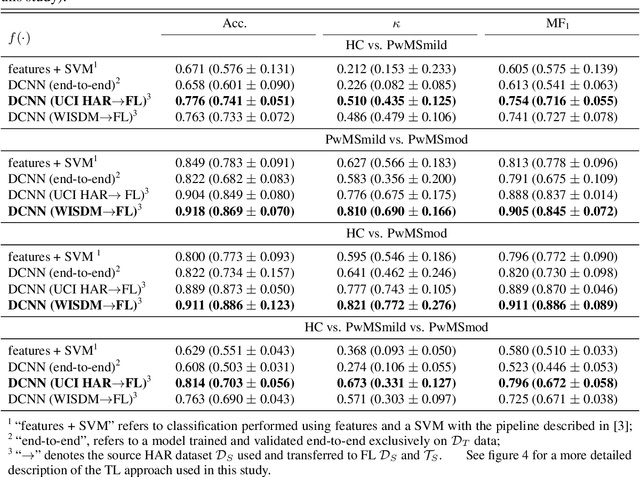
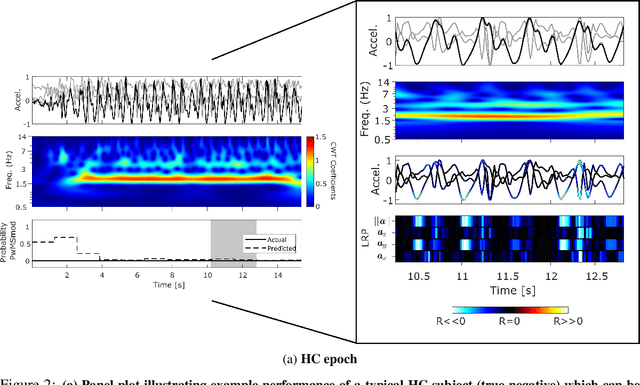
The emergence of digital technologies such as smartphones in healthcare applications have demonstrated the possibility of developing rich, continuous, and objective measures of multiple sclerosis (MS) disability that can be administered remotely and out-of-clinic. In this work, deep convolutional neural networks (DCNN) applied to smartphone inertial sensor data were shown to better distinguish healthy from MS participant ambulation, compared to standard Support Vector Machine (SVM) feature-based methodologies. To overcome the typical limitations associated with remotely generated health data, such as low subject numbers, sparsity, and heterogeneous data, a transfer learning (TL) model from similar large open-source datasets was proposed. Our TL framework utilised the ambulatory information learned on Human Activity Recognition (HAR) tasks collected from similar smartphone-based sensor data. A lack of transparency of "black-box" deep networks remains one of the largest stumbling blocks to the wider acceptance of deep learning for clinical applications. Ensuing work therefore aimed to visualise DCNN decisions attributed by relevance heatmaps using Layer-Wise Relevance Propagation (LRP). Through the LRP framework, the patterns captured from smartphone-based inertial sensor data that were reflective of those who are healthy versus persons with MS (PwMS) could begin to be established and understood. Interpretations suggested that cadence-based measures, gait speed, and ambulation-related signal perturbations were distinct characteristics that distinguished MS disability from healthy participants. Robust and interpretable outcomes, generated from high-frequency out-of-clinic assessments, could greatly augment the current in-clinic assessment picture for PwMS, to inform better disease management techniques, and enable the development of better therapeutic interventions.
Estimation of Continuous Blood Pressure from PPG via a Federated Learning Approach
Feb 24, 2021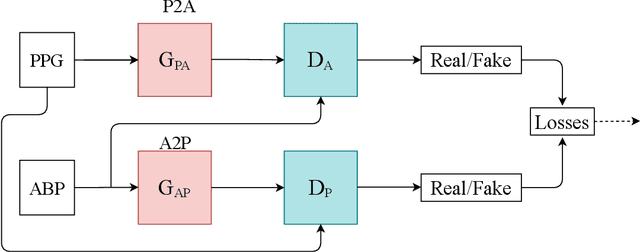

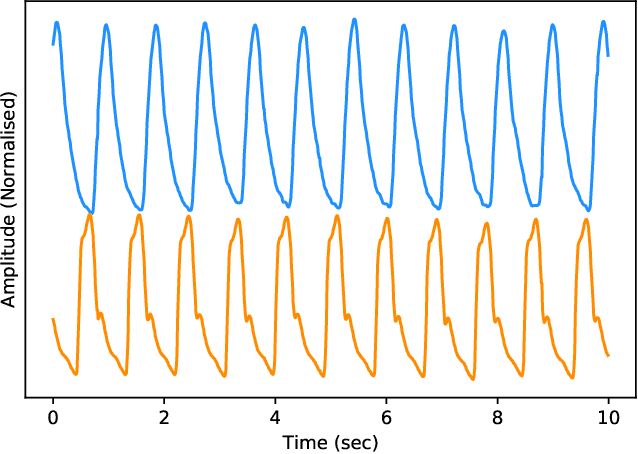
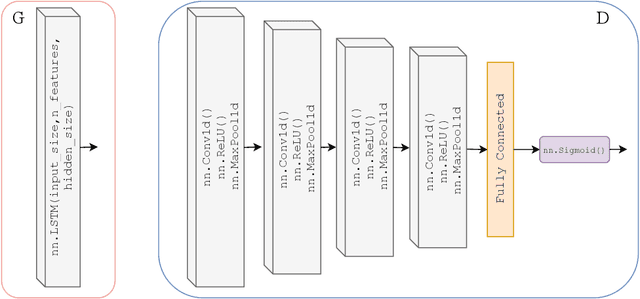
Ischemic heart disease is the highest cause of mortality globally each year. This not only puts a massive strain on the lives of those affected but also on the public healthcare systems. To understand the dynamics of the healthy and unhealthy heart doctors commonly use electrocardiogram (ECG) and blood pressure (BP) readings. These methods are often quite invasive, in particular when continuous arterial blood pressure (ABP) readings are taken and not to mention very costly. Using machine learning methods we seek to develop a framework that is capable of inferring ABP from a single optical photoplethysmogram (PPG) sensor alone. We train our framework across distributed models and data sources to mimic a large-scale distributed collaborative learning experiment that could be implemented across low-cost wearables. Our time series-to-time series generative adversarial network (T2TGAN) is capable of high-quality continuous ABP generation from a PPG signal with a mean error of 2.54 mmHg and a standard deviation of 23.7 mmHg when estimating mean arterial pressure on a previously unseen, noisy, independent dataset. To our knowledge, this framework is the first example of a GAN capable of continuous ABP generation from an input PPG signal that also uses a federated learning methodology.
Change Point Detection in Time Series Data using Autoencoders with a Time-Invariant Representation
Aug 21, 2020
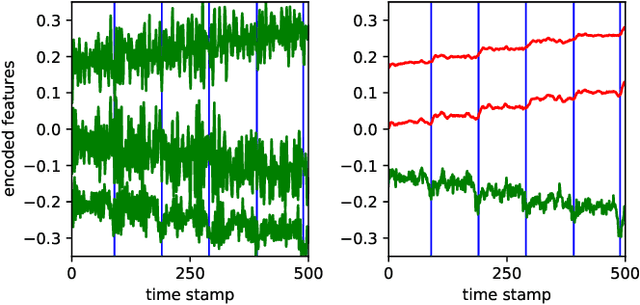
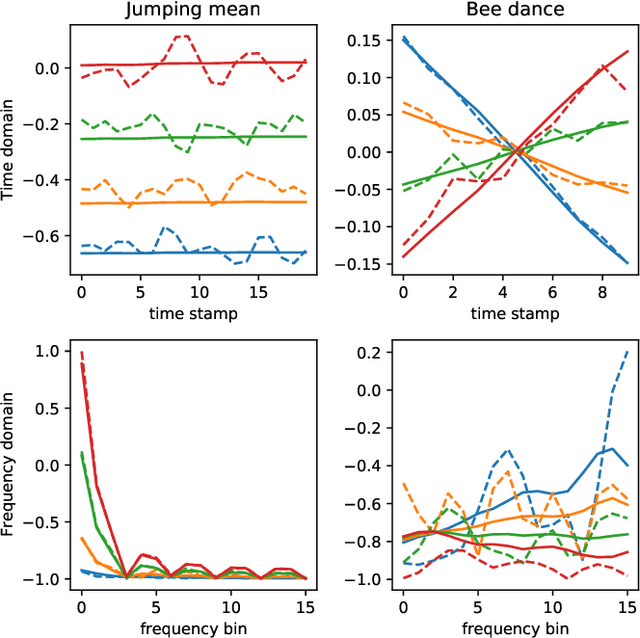
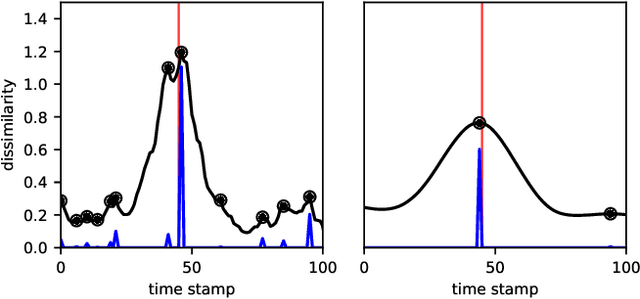
Change point detection (CPD) aims to locate abrupt property changes in time series data. Recent CPD methods demonstrated the potential of using deep learning techniques, but often lack the ability to identify more subtle changes in the autocorrelation statistics of the signal and suffer from a high false alarm rate. To address these issues, we employ an autoencoder-based methodology with a novel loss function, through which the used autoencoders learn a partially time-invariant representation that is tailored for CPD. The result is a flexible method that allows the user to indicate whether change points should be sought in the time domain, frequency domain or both. Detectable change points include abrupt changes in the slope, mean, variance, autocorrelation function and frequency spectrum. We demonstrate that our proposed method is consistently highly competitive or superior to baseline methods on diverse simulated and real-life benchmark data sets. Finally, we mitigate the issue of false detection alarms through the use of a postprocessing procedure that combines a matched filter and a newly proposed change point score. We show that this combination drastically improves the performance of our method as well as all baseline methods.
XSleepNet: Multi-View Sequential Model for Automatic Sleep Staging
Jul 17, 2020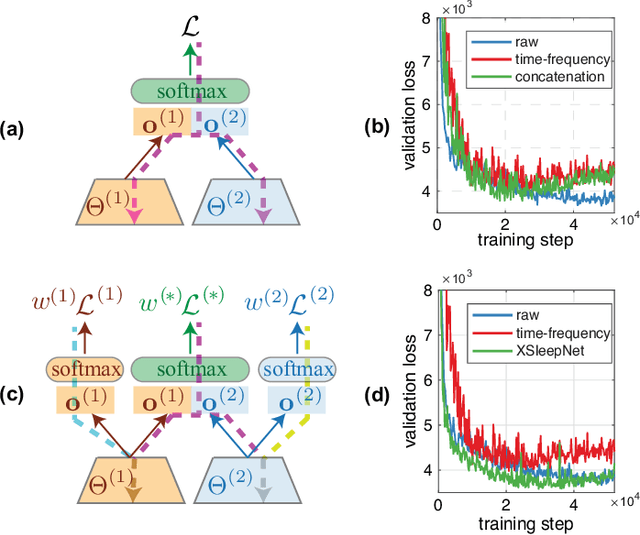

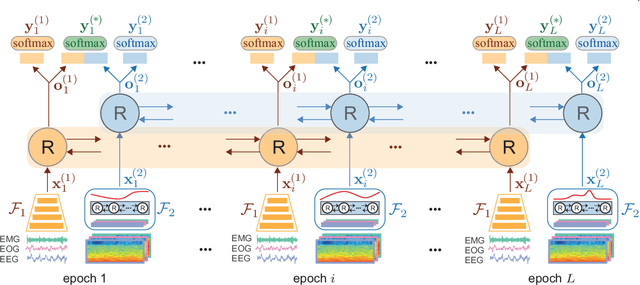
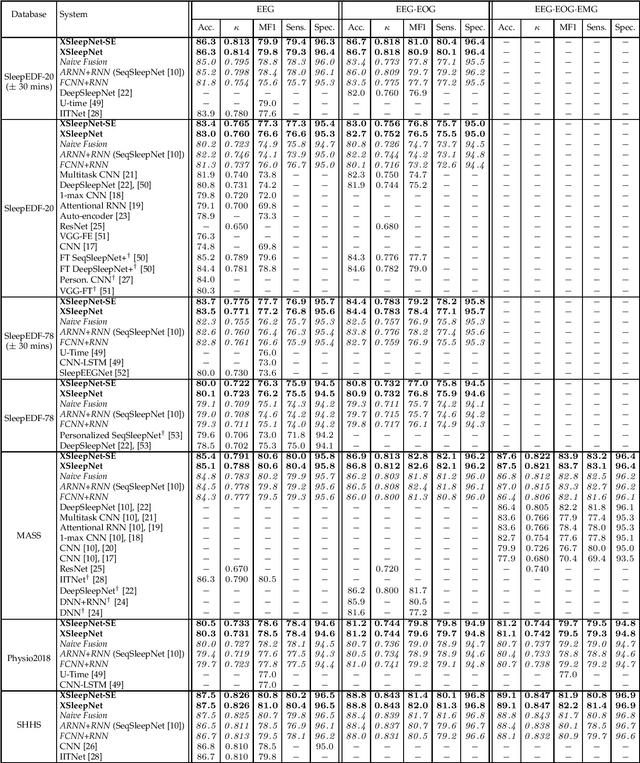
Automating sleep staging is vital to scale up sleep assessment and diagnosis to millions of people experiencing sleep deprivation and disorders and to enable longitudinal sleep monitoring in home environments. Learning from raw polysomnography signals and their derived time-frequency images has been prevalent. However, learning from multi-view inputs (e.g. both the raw signals and the time-frequency images) for sleep staging is difficult and not well understood. This work proposes a sequence-to-sequence sleep staging model, XSleepNet, that is capable of learning a joint representation from both raw signals and time-frequency images effectively. Since different views often generalize (and overfit) at different rates, the proposed network is trained in such a way that the learning pace on each view is adapted based on their generalization/overfitting behavior. In simple terms, the learning on a particular view is speeded up when it is generalizing well and slowed down when it is overfitting. View-specific generalization/overfitting measures are computed on-the-fly during the training course and used to derive weights to blend the gradients from different views. As a result, the network is able to retain representation power of different views in the joint features which represent the underlying distribution better than those learned by each individual view alone. Furthermore, the XSleepNet architecture is principally designed to gain robustness to the amount of training data and to increase the complementarity between the input views. Experimental results on five databases of different size show that XSleepNet consistently results in better performance than the single-view baselines as well as the multi-view baseline with a simple fusion strategy. Finally, XSleepNet outperforms all prior sleep staging methods and sets new state-of-the-art results on the experimental databases.
Personalized Automatic Sleep Staging with Single-Night Data: a Pilot Study with KL-Divergence Regularization
May 11, 2020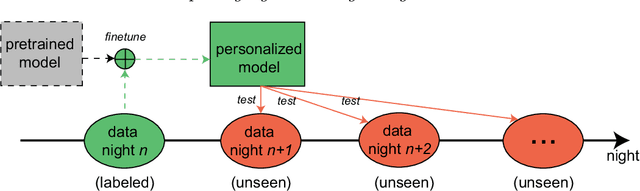
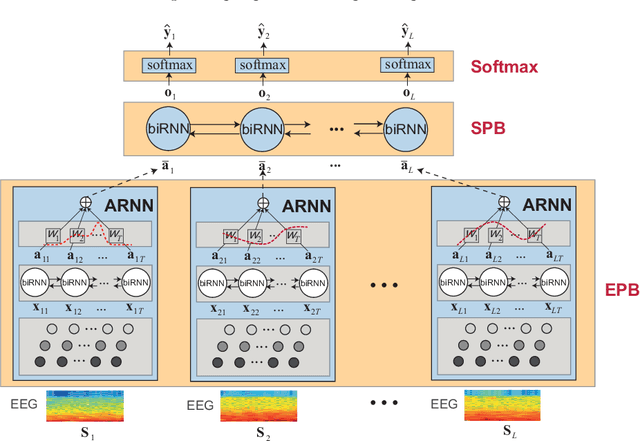
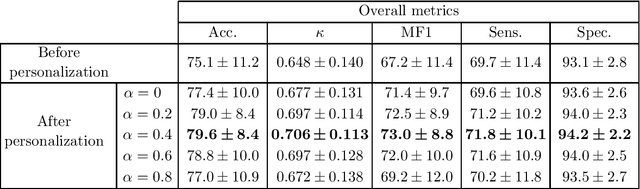
Brain waves vary between people. An obvious way to improve automatic sleep staging for longitudinal sleep monitoring is personalization of algorithms based on individual characteristics extracted from the first night of data. As a single night is a very small amount of data to train a sleep staging model, we propose a Kullback-Leibler (KL) divergence regularized transfer learning approach to address this problem. We employ the pretrained SeqSleepNet (i.e. the subject independent model) as a starting point and finetune it with the single-night personalization data to derive the personalized model. This is done by adding the KL divergence between the output of the subject independent model and the output of the personalized model to the loss function during finetuning. In effect, KL-divergence regularization prevents the personalized model from overfitting to the single-night data and straying too far away from the subject independent model. Experimental results on the Sleep-EDF Expanded database with 75 subjects show that sleep staging personalization with a single-night data is possible with help of the proposed KL-divergence regularization. On average, we achieve a personalized sleep staging accuracy of 79.6%, a Cohen's kappa of 0.706, a macro F1-score of 73.0%, a sensitivity of 71.8%, and a specificity of 94.2%. We find both that the approach is robust against overfitting and that it improves the accuracy by 4.5 percentage points compared to non-personalization and 2.2 percentage points compared to personalization without regularization.
Improving GANs for Speech Enhancement
Jan 15, 2020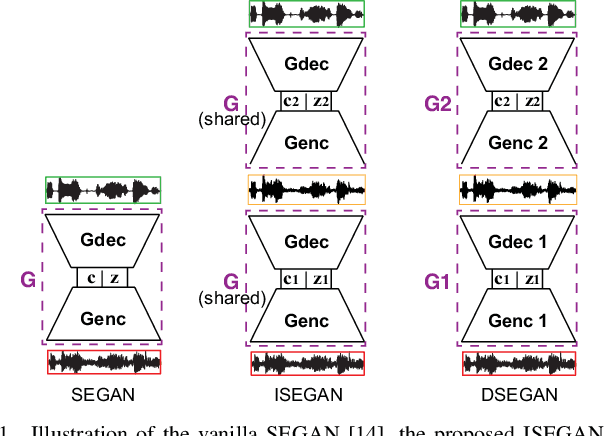
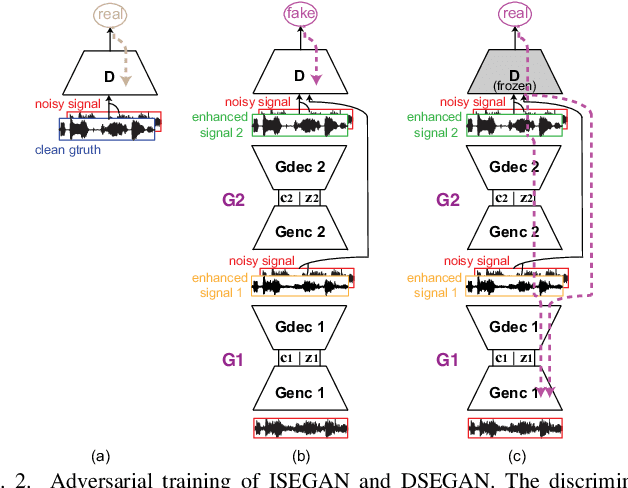
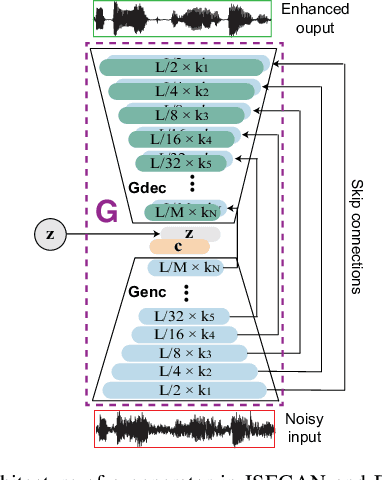
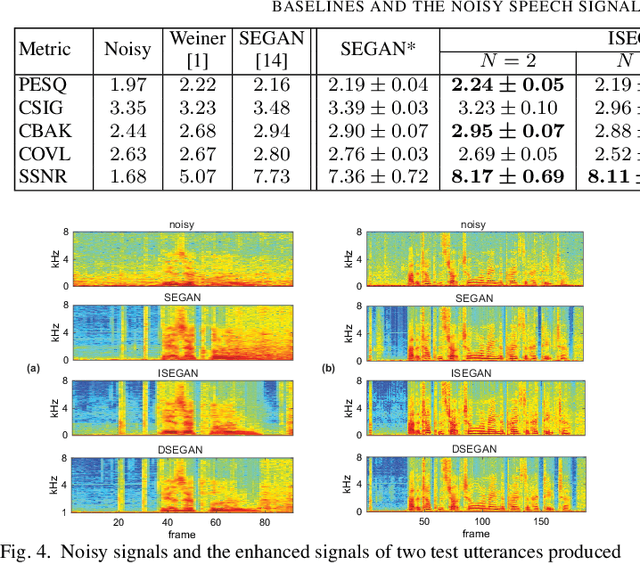
Generative adversarial networks (GAN) have recently been shown to be efficient for speech enhancement. Most, if not all, existing speech enhancement GANs (SEGANs) make use of a single generator to perform one-stage enhancement mapping. In this work, we propose two novel SEGAN frameworks, iterated SEGAN (ISEGAN) and deep SEGAN (DSEGAN). In the two proposed frameworks, the GAN architectures are composed of multiple generators that are chained to accomplish multiple-stage enhancement mapping which gradually refines the noisy input signals in stage-wise fashion. On the one hand, ISEGAN's generators share their parameters to learn an iterative enhancement mapping. On the other hand, DSEGAN's generators share a common architecture but their parameters are independent; as a result, different enhancement mappings are learned at different stages of the network. We empirically demonstrate favorable results obtained by the proposed ISEGAN and DSEGAN frameworks over the vanilla SEGAN. The source code is available at http://github.com/pquochuy/idsegan.