 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-temporal, multi-field deep learning of shock propagation in meso-structured media
Sep 19, 2025



The ability to predict how shock waves traverse porous and architected materials is a decisive factor in planetary defense, national security, and the race to achieve inertial fusion energy. Yet capturing pore collapse, anomalous Hugoniot responses, and localized heating -- phenomena that can determine the success of asteroid deflection or fusion ignition -- has remained a major challenge despite recent advances in single-field and reduced representations. We introduce a multi-field spatio-temporal deep learning model (MSTM) that unifies seven coupled fields -- pressure, density, temperature, energy, material distribution, and two velocity components -- into a single autoregressive surrogate. Trained on high-fidelity hydrocode data, MSTM runs about a thousand times faster than direct simulation, achieving errors below 4\% in porous materials and below 10\% in lattice structures. Unlike prior single-field or operator-based surrogates, MSTM resolves sharp shock fronts while preserving integrated quantities such as mass-averaged pressure and temperature to within 5\%. This advance transforms problems once considered intractable into tractable design studies, establishing a practical framework for optimizing meso-structured materials in planetary impact mitigation, inertial fusion energy, and national security.
A Staged Deep Learning Approach to Spatial Refinement in 3D Temporal Atmospheric Transport
Dec 14, 2024High-resolution spatiotemporal simulations effectively capture the complexities of atmospheric plume dispersion in complex terrain. However, their high computational cost makes them impractical for applications requiring rapid responses or iterative processes, such as optimization, uncertainty quantification, or inverse modeling. To address this challenge, this work introduces the Dual-Stage Temporal Three-dimensional UNet Super-resolution (DST3D-UNet-SR) model, a highly efficient deep learning model for plume dispersion prediction. DST3D-UNet-SR is composed of two sequential modules: the temporal module (TM), which predicts the transient evolution of a plume in complex terrain from low-resolution temporal data, and the spatial refinement module (SRM), which subsequently enhances the spatial resolution of the TM predictions. We train DST3DUNet- SR using a comprehensive dataset derived from high-resolution large eddy simulations (LES) of plume transport. We propose the DST3D-UNet-SR model to significantly accelerate LES simulations of three-dimensional plume dispersion by three orders of magnitude. Additionally, the model demonstrates the ability to dynamically adapt to evolving conditions through the incorporation of new observational data, substantially improving prediction accuracy in high-concentration regions near the source. Keywords: Atmospheric sciences, Geosciences, Plume transport,3D temporal sequences, Artificial intelligence, CNN, LSTM, Autoencoder, Autoregressive model, U-Net, Super-resolution, Spatial Refinement.
Spatiotemporal Predictions of Toxic Urban Plumes Using Deep Learning
May 30, 2024



Industrial accidents, chemical spills, and structural fires can release large amounts of harmful materials that disperse into urban atmospheres and impact populated areas. Computer models are typically used to predict the transport of toxic plumes by solving fluid dynamical equations. However, these models can be computationally expensive due to the need for many grid cells to simulate turbulent flow and resolve individual buildings and streets. In emergency response situations, alternative methods are needed that can run quickly and adequately capture important spatiotemporal features. Here, we present a novel deep learning model called ST-GasNet that was inspired by the mathematical equations that govern the behavior of plumes as they disperse through the atmosphere. ST-GasNet learns the spatiotemporal dependencies from a limited set of temporal sequences of ground-level toxic urban plumes generated by a high-resolution large eddy simulation model. On independent sequences, ST-GasNet accurately predicts the late-time spatiotemporal evolution, given the early-time behavior as an input, even for cases when a building splits a large plume into smaller plumes. By incorporating large-scale wind boundary condition information, ST-GasNet achieves a prediction accuracy of at least 90% on test data for the entire prediction period.
Learning Physics through Images: An Application to Wind-Driven Spatial Patterns
Feb 03, 2022
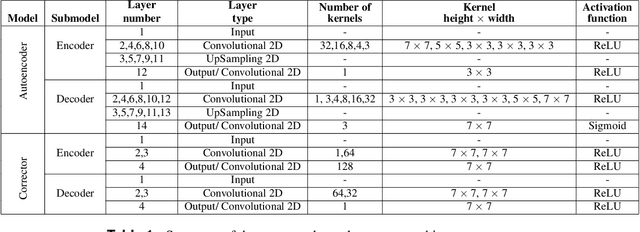
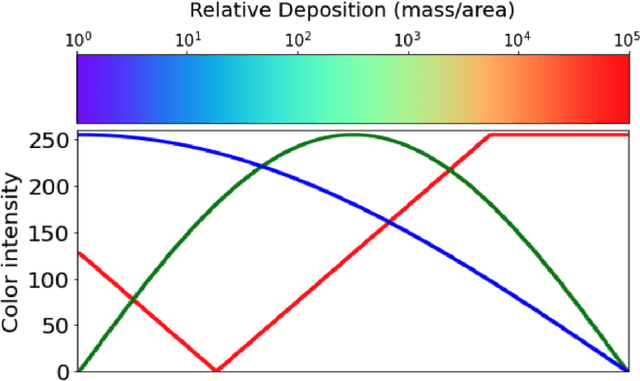
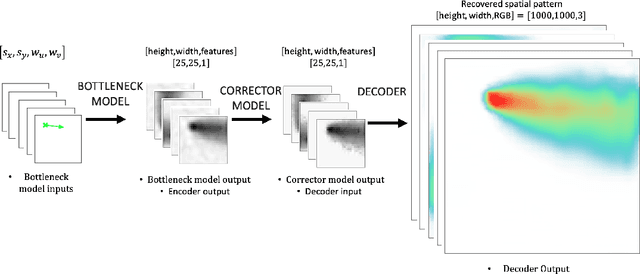
For centuries, scientists have observed nature to understand the laws that govern the physical world. The traditional process of turning observations into physical understanding is slow. Imperfect models are constructed and tested to explain relationships in data. Powerful new algorithms are available that can enable computers to learn physics by observing images and videos. Inspired by this idea, instead of training machine learning models using physical quantities, we trained them using images, that is, pixel information. For this work, and as a proof of concept, the physics of interest are wind-driven spatial patterns. Examples of these phenomena include features in Aeolian dunes and the deposition of volcanic ash, wildfire smoke, and air pollution plumes. We assume that the spatial patterns were collected by an imaging device that records the magnitude of the logarithm of deposition as a red, green, blue (RGB) color image with channels containing values ranging from 0 to 255. In this paper, we explore deep convolutional neural network-based autoencoders to exploit relationships in wind-driven spatial patterns, which commonly occur in geosciences, and reduce their dimensionality. Reducing the data dimension size with an encoder allows us to train regression models linking geographic and meteorological scalar input quantities to the encoded space. Once this is achieved, full predictive spatial patterns are reconstructed using the decoder. We demonstrate this approach on images of spatial deposition from a pollution source, where the encoder compresses the dimensionality to 0.02% of the original size and the full predictive model performance on test data achieves an accuracy of 92%.
Deep Convolutional Autoencoders as Generic Feature Extractors in Seismological Applications
Oct 22, 2021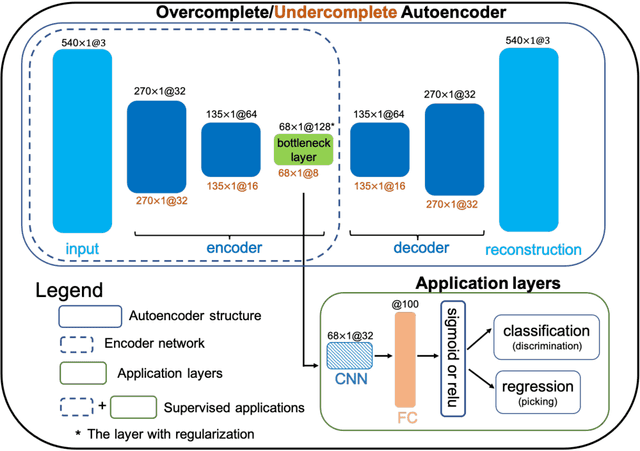
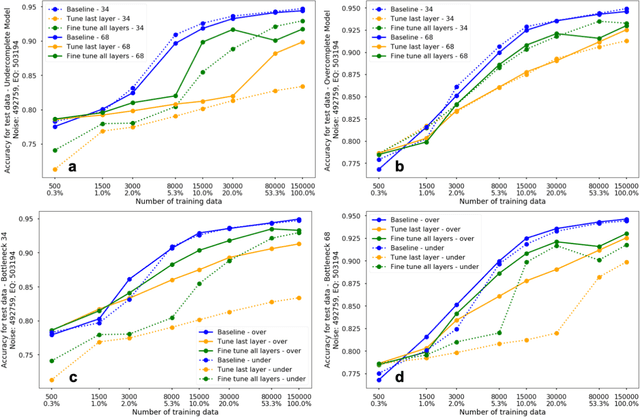
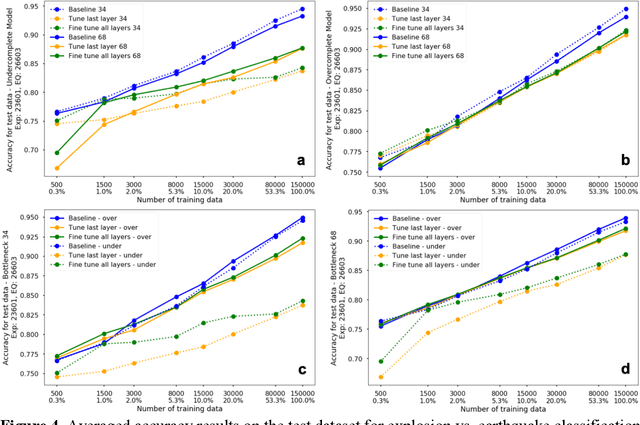
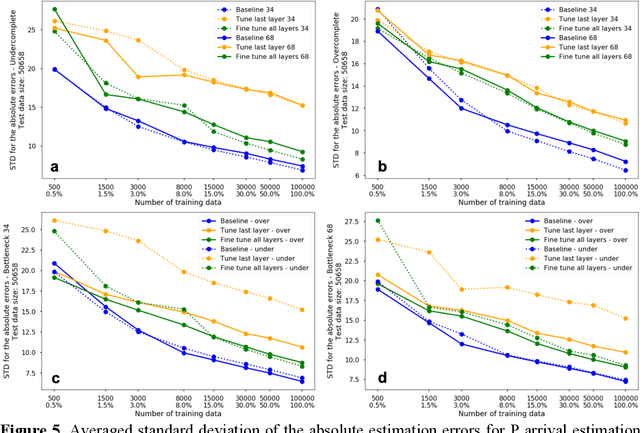
The idea of using a deep autoencoder to encode seismic waveform features and then use them in different seismological applications is appealing. In this paper, we designed tests to evaluate this idea of using autoencoders as feature extractors for different seismological applications, such as event discrimination (i.e., earthquake vs. noise waveforms, earthquake vs. explosion waveforms, and phase picking). These tests involve training an autoencoder, either undercomplete or overcomplete, on a large amount of earthquake waveforms, and then using the trained encoder as a feature extractor with subsequent application layers (either a fully connected layer, or a convolutional layer plus a fully connected layer) to make the decision. By comparing the performance of these newly designed models against the baseline models trained from scratch, we conclude that the autoencoder feature extractor approach may only perform well under certain conditions such as when the target problems require features to be similar to the autoencoder encoded features, when a relatively small amount of training data is available, and when certain model structures and training strategies are utilized. The model structure that works best in all these tests is an overcomplete autoencoder with a convolutional layer and a fully connected layer to make the estimation.
Uncertainty Bounds for Multivariate Machine Learning Predictions on High-Strain Brittle Fracture
Dec 23, 2020
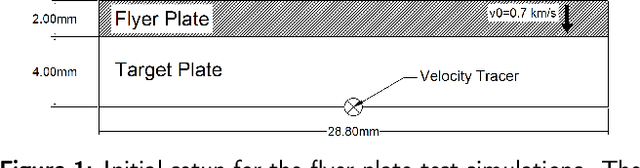


Simulation of the crack network evolution on high strain rate impact experiments performed in brittle materials is very compute-intensive. The cost increases even more if multiple simulations are needed to account for the randomness in crack length, location, and orientation, which is inherently found in real-world materials. Constructing a machine learning emulator can make the process faster by orders of magnitude. There has been little work, however, on assessing the error associated with their predictions. Estimating these errors is imperative for meaningful overall uncertainty quantification. In this work, we extend the heteroscedastic uncertainty estimates to bound a multiple output machine learning emulator. We find that the response prediction is robust with a somewhat conservative estimate of uncertainty.
StressNet: Deep Learning to Predict Stress With Fracture Propagation in Brittle Materials
Nov 20, 2020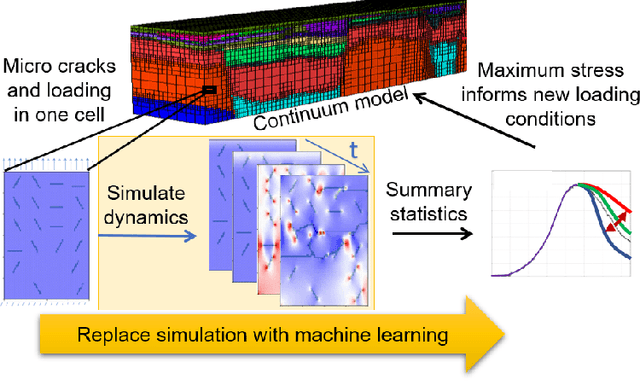

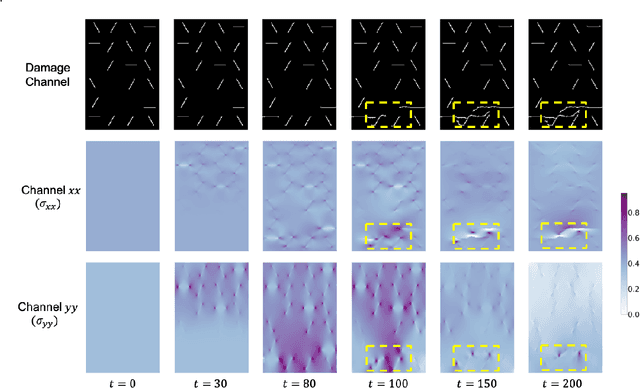

Catastrophic failure in brittle materials is often due to the rapid growth and coalescence of cracks aided by high internal stresses. Hence, accurate prediction of maximum internal stress is critical to predicting time to failure and improving the fracture resistance and reliability of materials. Existing high-fidelity methods, such as the Finite-Discrete Element Model (FDEM), are limited by their high computational cost. Therefore, to reduce computational cost while preserving accuracy, a novel deep learning model, "StressNet," is proposed to predict the entire sequence of maximum internal stress based on fracture propagation and the initial stress data. More specifically, the Temporal Independent Convolutional Neural Network (TI-CNN) is designed to capture the spatial features of fractures like fracture path and spall regions, and the Bidirectional Long Short-term Memory (Bi-LSTM) Network is adapted to capture the temporal features. By fusing these features, the evolution in time of the maximum internal stress can be accurately predicted. Moreover, an adaptive loss function is designed by dynamically integrating the Mean Squared Error (MSE) and the Mean Absolute Percentage Error (MAPE), to reflect the fluctuations in maximum internal stress. After training, the proposed model is able to compute accurate multi-step predictions of maximum internal stress in approximately 20 seconds, as compared to the FDEM run time of 4 hours, with an average MAPE of 2% relative to test data.
Identifying Entangled Physics Relationships through Sparse Matrix Decomposition to Inform Plasma Fusion Design
Oct 28, 2020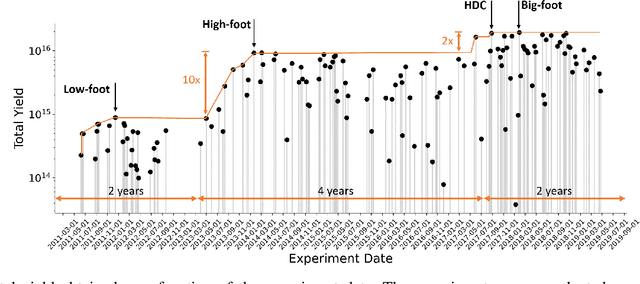
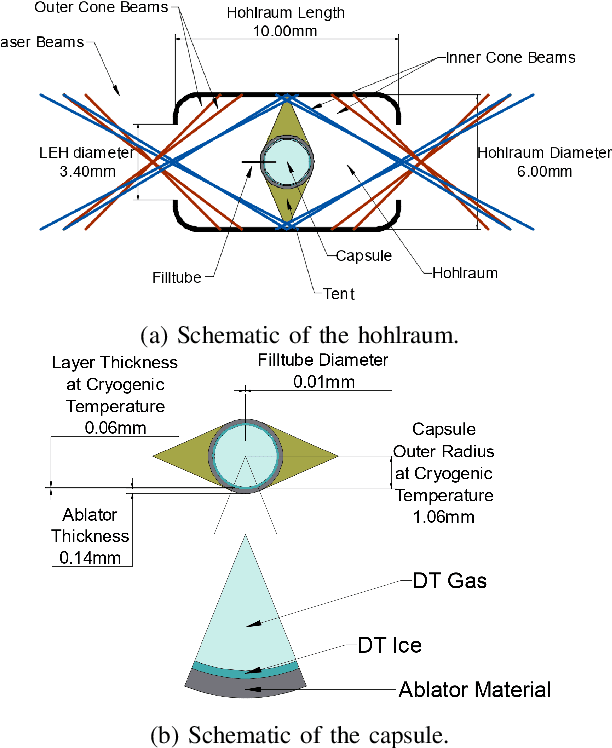
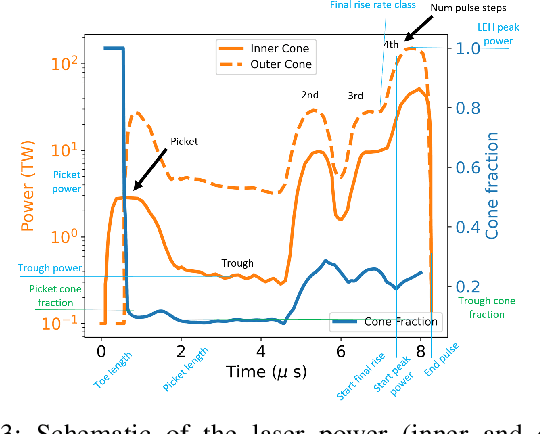
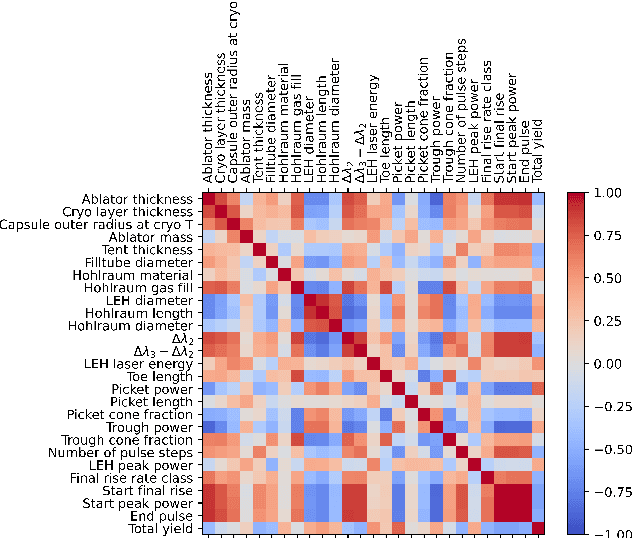
A sustainable burn platform through inertial confinement fusion (ICF) has been an ongoing challenge for over 50 years. Mitigating engineering limitations and improving the current design involves an understanding of the complex coupling of physical processes. While sophisticated simulations codes are used to model ICF implosions, these tools contain necessary numerical approximation but miss physical processes that limit predictive capability. Identification of relationships between controllable design inputs to ICF experiments and measurable outcomes (e.g. yield, shape) from performed experiments can help guide the future design of experiments and development of simulation codes, to potentially improve the accuracy of the computational models used to simulate ICF experiments. We use sparse matrix decomposition methods to identify clusters of a few related design variables. Sparse principal component analysis (SPCA) identifies groupings that are related to the physical origin of the variables (laser, hohlraum, and capsule). A variable importance analysis finds that in addition to variables highly correlated with neutron yield such as picket power and laser energy, variables that represent a dramatic change of the ICF design such as number of pulse steps are also very important. The obtained sparse components are then used to train a random forest (RF) surrogate for predicting total yield. The RF performance on the training and testing data compares with the performance of the RF surrogate trained using all design variables considered. This work is intended to inform design changes in future ICF experiments by augmenting the expert intuition and simulations results.
Exploring Sensitivity of ICF Outputs to Design Parameters in Experiments Using Machine Learning
Oct 08, 2020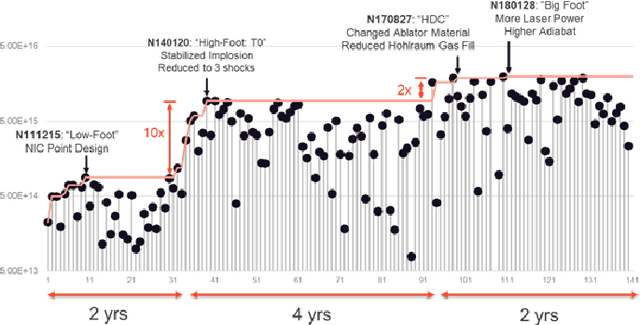
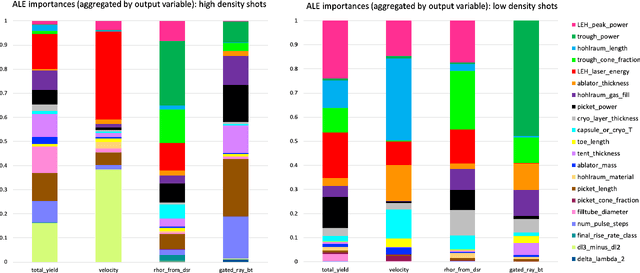
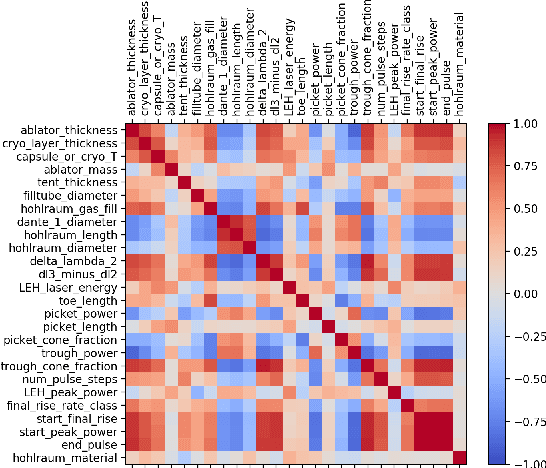

Building a sustainable burn platform in inertial confinement fusion (ICF) requires an understanding of the complex coupling of physical processes and the effects that key experimental design changes have on implosion performance. While simulation codes are used to model ICF implosions, incomplete physics and the need for approximations deteriorate their predictive capability. Identification of relationships between controllable design inputs and measurable outcomes can help guide the future design of experiments and development of simulation codes, which can potentially improve the accuracy of the computational models used to simulate ICF implosions. In this paper, we leverage developments in machine learning (ML) and methods for ML feature importance/sensitivity analysis to identify complex relationships in ways that are difficult to process using expert judgment alone. We present work using random forest (RF) regression for prediction of yield, velocity, and other experimental outcomes given a suite of design parameters, along with an assessment of important relationships and uncertainties in the prediction model. We show that RF models are capable of learning and predicting on ICF experimental data with high accuracy, and we extract feature importance metrics that provide insight into the physical significance of different controllable design inputs for various ICF design configurations. These results can be used to augment expert intuition and simulation results for optimal design of future ICF experiments.