 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-based Policy Adaptation without Policy Updates
Jun 04, 2026Leveraging prior knowledge from pretrained policies, foundation models, or human operators offers an efficient alternative to learning robot skills from scratch. However, these agents often provide actions that are suboptimal, noisy, or misaligned with task-specific expert behavior. We propose GLOVES, a family of flow-based adaptation methods that correct non-expert actions by transporting them toward an expert action distribution. Rather than replacing agentic control with full autonomy, GLOVES performs selective action-level adaptation, improving task success while preserving agent intent. The learned flow also provides a natural in-distribution scoring mechanism through reverse flow evaluation. We use this signal as an intervention gate: actions that appear consistent with the expert distribution are passed through unchanged, while anomalous or out-of-distribution (OOD) actions are corrected. In this way, assistance is only provided when necessary. GLOVES requires only limited expert supervision, using a small number of demonstrations or reusable successful skill segments. By learning local expert action patterns and stitching them during execution, GLOVES provides a lightweight shared-control module for robust action adaptation across tasks and environments. Code and demos are available at ripl.github.io/GLOVES_web.
What Are We Actually Benchmarking in Robot Manipulation?
Jun 02, 2026A robotics benchmark score measures success under one fixed evaluation setup, yet is routinely treated as evidence of general manipulation capability. We identify four failure modes, each of which weakens or invalidates a benchmark's role as a valid proxy for that capability: shortcut solvability, lack of statistical significance, creeping overfitting, and data-source dependence. We propose one diagnostic per failure mode. We audit LIBERO, CALVIN, SimplerEnv, RoboCasa, and RoboTwin 2.0 under these diagnostics. LIBERO and CALVIN fail multiple diagnostics. RoboCasa and RoboTwin 2.0 fail fewer, despite appearing far less often in recent progress claims. On LIBERO, a 0.09B probe with no language encoder scores at or near reported SOTA, and most reported gains are not provably statistically significant. On CALVIN, randomizing block poses within the training range drops performance for every tested policy. We release the four diagnostics with reference implementations for authors and reviewers to apply before treating a benchmark score as evidence of progress. Code and artifacts are available at https://ripl.github.io/manipulation_benchmark_audit/.
Seeing without Looking: Do Vision-Language Benchmarks Really Test Vision?
May 21, 2026Benchmark accuracy is often implicitly assumed to reflect grounded visual understanding in vision-language models (VLMs), yet it remains unclear to what extent such scores truly reflect reliance on visual evidence. Motivated by a surprising observation that removing a substantial fraction of image tokens only degrades model performance very slightly on a widely used hallucination benchmark, we systematically investigate this mismatch in a set of open-source VLMs. Our analysis spans multiple levels of granularity, spanning global visual degradation, localized occlusion, question reformulation, answer-space expansion, and decision-level analyses beyond standard accuracy. We further complement these behavioral results with a layer-wise analysis of vision-token geometry. Throughout the experiments, we find that although VLMs do incorporate visual input, their predictions are less sensitive to the loss of fine-grained visual evidence that standard accuracy should have suggested. Even when the final prediction remains unchanged, the model's internal support for the correct answer may already be weakened. We further complement a representation-level analysis, which shows increasing similarity among visual tokens in deeper layers, providing a possible explanation for our findings. Together, these results suggest that current benchmarks are not sufficient to reliably evaluate fine-grained visual grounding in VLMs.
HALP: Detecting Hallucinations in Vision-Language Models without Generating a Single Token
Mar 05, 2026Hallucinations remain a persistent challenge for vision-language models (VLMs), which often describe nonexistent objects or fabricate facts. Existing detection methods typically operate after text generation, making intervention both costly and untimely. We investigate whether hallucination risk can instead be predicted before any token is generated by probing a model's internal representations in a single forward pass. Across a diverse set of vision-language tasks and eight modern VLMs, including Llama-3.2-Vision, Gemma-3, Phi-4-VL, and Qwen2.5-VL, we examine three families of internal representations: (i) visual-only features without multimodal fusion, (ii) vision-token representations within the text decoder, and (iii) query-token representations that integrate visual and textual information before generation. Probes trained on these representations achieve strong hallucination-detection performance without decoding, reaching up to 0.93 AUROC on Gemma-3-12B, Phi-4-VL 5.6B, and Molmo 7B. Late query-token states are the most predictive for most models, while visual or mid-layer features dominate in a few architectures (e.g., ~0.79 AUROC for Qwen2.5-VL-7B using visual-only features). These results demonstrate that (1) hallucination risk is detectable pre-generation, (2) the most informative layer and modality vary across architectures, and (3) lightweight probes have the potential to enable early abstention, selective routing, and adaptive decoding to improve both safety and efficiency.
FlashBack: Consistency Model-Accelerated Shared Autonomy
May 22, 2025Shared autonomy is an enabling technology that provides users with control authority over robots that would otherwise be difficult if not impossible to directly control. Yet, standard methods make assumptions that limit their adoption in practice-for example, prior knowledge of the user's goals or the objective (i.e., reward) function that they wish to optimize, knowledge of the user's policy, or query-level access to the user during training. Diffusion-based approaches to shared autonomy do not make such assumptions and instead only require access to demonstrations of desired behaviors, while allowing the user to maintain control authority. However, these advantages have come at the expense of high computational complexity, which has made real-time shared autonomy all but impossible. To overcome this limitation, we propose Consistency Shared Autonomy (CSA), a shared autonomy framework that employs a consistency model-based formulation of diffusion. Key to CSA is that it employs the distilled probability flow of ordinary differential equations (PF ODE) to generate high-fidelity samples in a single step. This results in inference speeds significantly than what is possible with previous diffusion-based approaches to shared autonomy, enabling real-time assistance in complex domains with only a single function evaluation. Further, by intervening on flawed actions at intermediate states of the PF ODE, CSA enables varying levels of assistance. We evaluate CSA on a variety of challenging simulated and real-world robot control problems, demonstrating significant improvements over state-of-the-art methods both in terms of task performance and computational efficiency.
StackGen: Generating Stable Structures from Silhouettes via Diffusion
Sep 26, 2024



Humans naturally obtain intuition about the interactions between and the stability of rigid objects by observing and interacting with the world. It is this intuition that governs the way in which we regularly configure objects in our environment, allowing us to build complex structures from simple, everyday objects. Robotic agents, on the other hand, traditionally require an explicit model of the world that includes the detailed geometry of each object and an analytical model of the environment dynamics, which are difficult to scale and preclude generalization. Instead, robots would benefit from an awareness of intuitive physics that enables them to similarly reason over the stable interaction of objects in their environment. Towards that goal, we propose StackGen, a diffusion model that generates diverse stable configurations of building blocks matching a target silhouette. To demonstrate the capability of the method, we evaluate it in a simulated environment and deploy it in the real setting using a robotic arm to assemble structures generated by the model.
To the Noise and Back: Diffusion for Shared Autonomy
Feb 24, 2023



Shared autonomy is an operational concept in which a user and an autonomous agent collaboratively control a robotic system. It provides a number of advantages over the extremes of full-teleoperation and full-autonomy in many settings. Traditional approaches to shared autonomy rely on knowledge of the environment dynamics, a discrete space of user goals that is known a priori, or knowledge of the user's policy -- assumptions that are unrealistic in many domains. Recent works relax some of these assumptions by formulating shared autonomy with model-free deep reinforcement learning (RL). In particular, they no longer need knowledge of the goal space (e.g., that the goals are discrete or constrained) or environment dynamics. However, they need knowledge of a task-specific reward function to train the policy. Unfortunately, such reward specification can be a difficult and brittle process. On top of that, the formulations inherently rely on human-in-the-loop training, and that necessitates them to prepare a policy that mimics users' behavior. In this paper, we present a new approach to shared autonomy that employs a modulation of the forward and reverse diffusion process of diffusion models. Our approach does not assume known environment dynamics or the space of user goals, and in contrast to previous work, it does not require any reward feedback, nor does it require access to the user's policy during training. Instead, our framework learns a distribution over a space of desired behaviors. It then employs a diffusion model to translate the user's actions to a sample from this distribution. Crucially, we show that it is possible to carry out this process in a manner that preserves the user's control authority. We evaluate our framework on a series of challenging continuous control tasks, and analyze its ability to effectively correct user actions while maintaining their autonomy.
Decompositional Quantum Graph Neural Network
Jan 13, 2022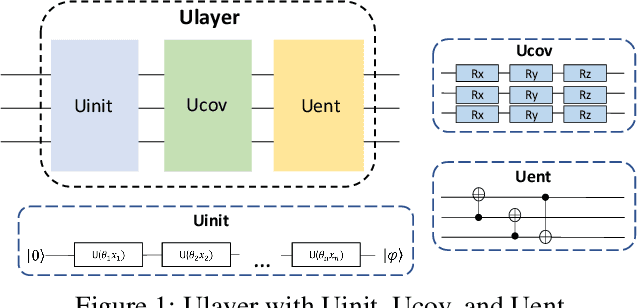
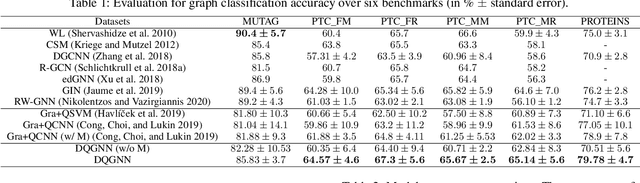
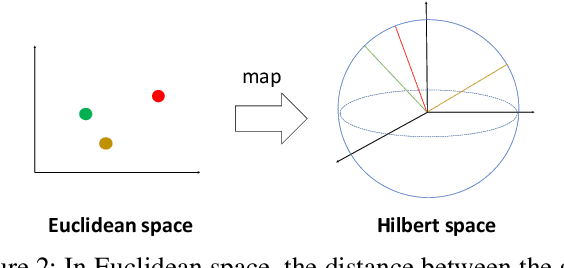
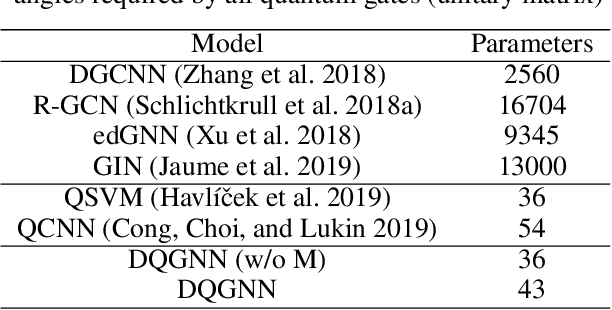
Quantum machine learning is a fast emerging field that aims to tackle machine learning using quantum algorithms and quantum computing. Due to the lack of physical qubits and an effective means to map real-world data from Euclidean space to Hilbert space, most of these methods focus on quantum analogies or process simulations rather than devising concrete architectures based on qubits. In this paper, we propose a novel hybrid quantum-classical algorithm for graph-structured data, which we refer to as the Decompositional Quantum Graph Neural Network (DQGNN). DQGNN implements the GNN theoretical framework using the tensor product and unity matrices representation, which greatly reduces the number of model parameters required. When controlled by a classical computer, DQGNN can accommodate arbitrarily sized graphs by processing substructures from the input graph using a modestly-sized quantum device. The architecture is based on a novel mapping from real-world data to Hilbert space. This mapping maintains the distance relations present in the data and reduces information loss. Experimental results show that the proposed method outperforms competitive state-of-the-art models with only 1.68\% parameters compared to those models.