 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikidated 1.0: An Evolving Knowledge Graph Dataset of Wikidata's Revision History
Dec 09, 2021
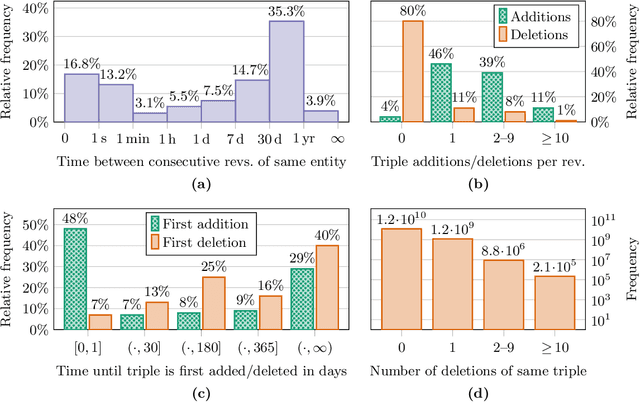
Wikidata is the largest general-interest knowledge base that is openly available. It is collaboratively edited by thousands of volunteer editors and has thus evolved considerably since its inception in 2012. In this paper, we present Wikidated 1.0, a dataset of Wikidata's full revision history, which encodes changes between Wikidata revisions as sets of deletions and additions of RDF triples. To the best of our knowledge, it constitutes the first large dataset of an evolving knowledge graph, a recently emerging research subject in the Semantic Web community. We introduce the methodology for generating Wikidated 1.0 from dumps of Wikidata, discuss its implementation and limitations, and present statistical characteristics of the dataset.
* 15 pages, 4 figures. Published at Wikidata@ISWC 2021
Knowledge Graphs
Mar 28, 2020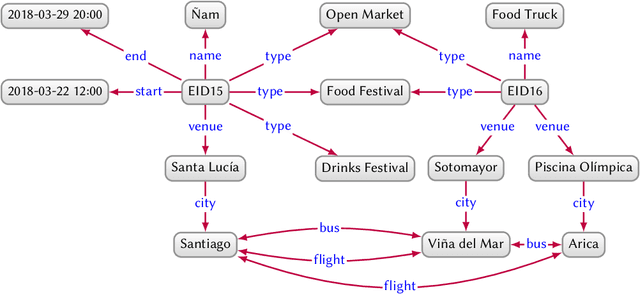
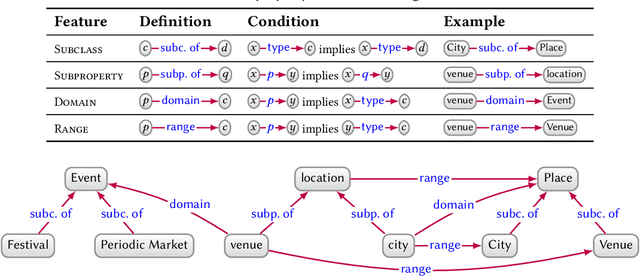
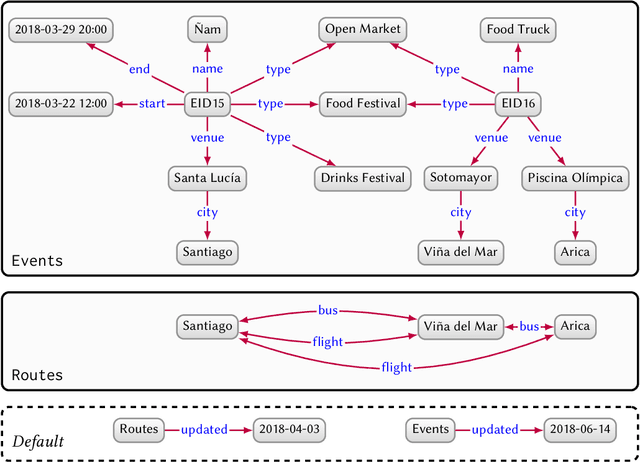
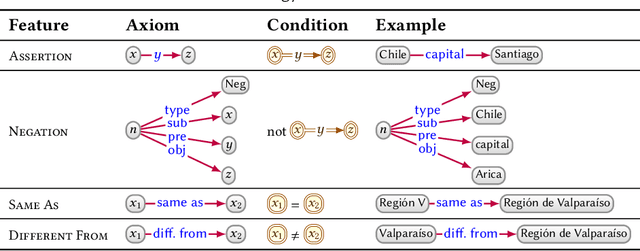
In this paper we provide a comprehensive introduction to knowledge graphs, which have recently garnered significant attention from both industry and academia in scenarios that require exploiting diverse, dynamic, large-scale collections of data. After a general introduction, we motivate and contrast various graph-based data models and query languages that are used for knowledge graphs. We discuss the roles of schema, identity, and context in knowledge graphs. We explain how knowledge can be represented and extracted using a combination of deductive and inductive techniques. We summarise methods for the creation, enrichment, quality assessment, refinement, and publication of knowledge graphs. We provide an overview of prominent open knowledge graphs and enterprise knowledge graphs, their applications, and how they use the aforementioned techniques. We conclude with high-level future research directions for knowledge graphs.
CLEARumor at SemEval-2019 Task 7: ConvoLving ELMo Against Rumors
Apr 05, 2019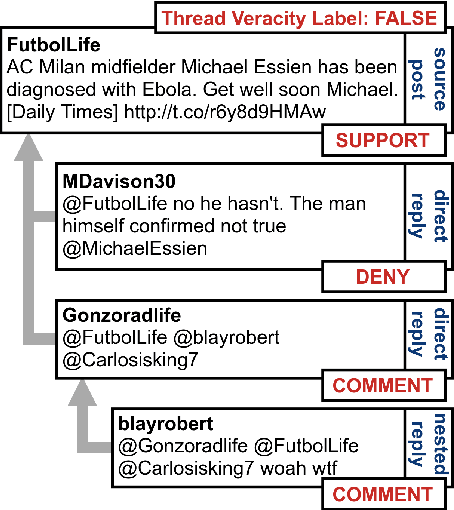
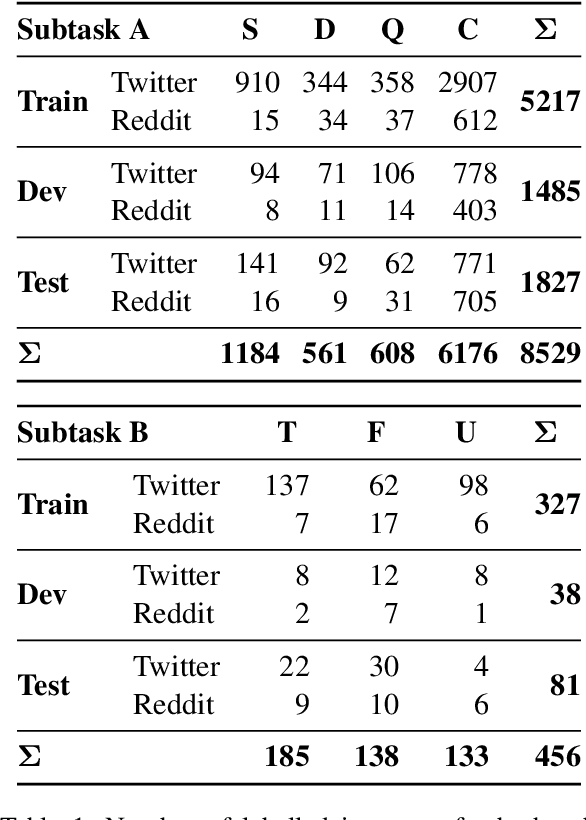
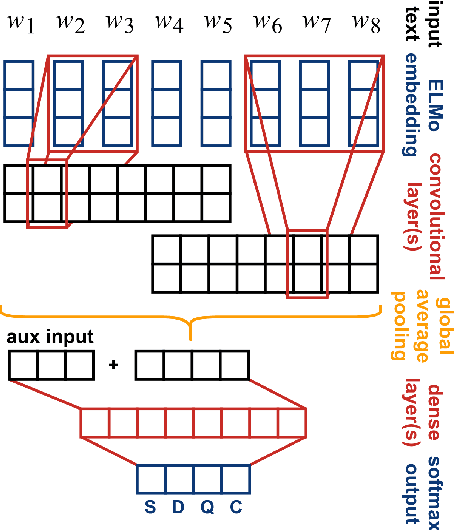

This paper describes our submission to SemEval-2019 Task 7: RumourEval: Determining Rumor Veracity and Support for Rumors. We participated in both subtasks. The goal of subtask A is to classify the type of interaction between a rumorous social media post and a reply post as support, query, deny, or comment. The goal of subtask B is to predict the veracity of a given rumor. For subtask A, we implement a CNN-based neural architecture using ELMo embeddings of post text combined with auxiliary features and achieve a F1-score of 44.6%. For subtask B, we employ a MLP neural network leveraging our estimates for subtask A and achieve a F1-score of 30.1% (second place in the competition). We provide results and analysis of our system performance and present ablation experiments.
Learning Taxonomies of Concepts and not Words using Contextualized Word Representations: A Position Paper
Jan 31, 2019
Taxonomies are semantic hierarchies of concepts. One limitation of current taxonomy learning systems is that they define concepts as single words. This position paper argues that contextualized word representations, which recently achieved state-of-the-art results on many competitive NLP tasks, are a promising method to address this limitation. We outline a novel approach for taxonomy learning that (1) defines concepts as synsets, (2) learns density-based approximations of contextualized word representations, and (3) can measure similarity and hypernymy among them.