 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-EEGNet: an Energy-Efficient 8-bit Quantized Parallel EEGNet Implementation for Edge Motor-Imagery Brain--Machine Interfaces
Apr 24, 2020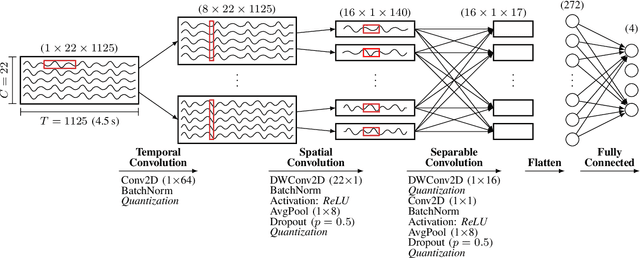
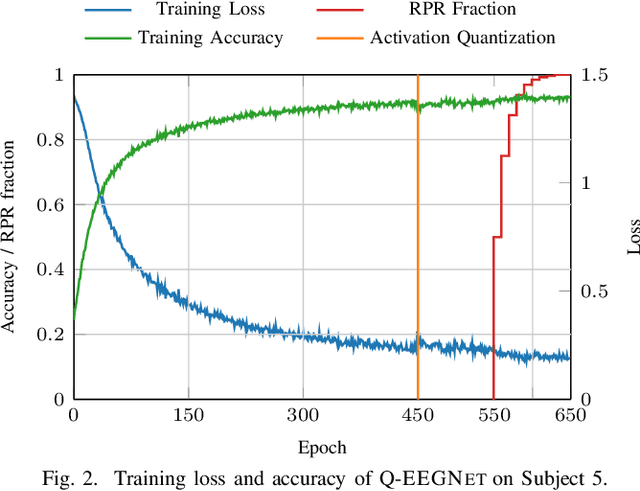
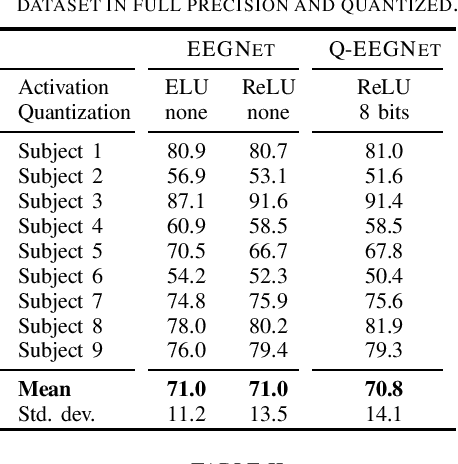
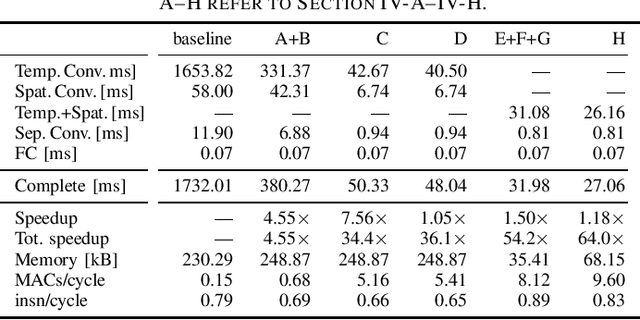
Motor-Imagery Brain-Machine Interfaces (MI-BMIs) promise direct and accessible communication between human brains and machines by analyzing brain activities recorded with Electroencephalography (EEG). Latency, reliability, and privacy constraints make it unsuitable to offload the computation to the cloud. Practical use cases demand a wearable, battery-operated device with a low average power consumption for long-term use. Recently, sophisticated algorithms, in particular deep learning models, have emerged for classifying EEG signals. While reaching outstanding accuracy, these models often exceed the limitations of edge devices due to their memory and computational requirements. In this paper, we demonstrate algorithmic and implementation optimizations for EEGNET, a compact Convolutional Neural Network (CNN) suitable for many BMI paradigms. We quantize weights and activations to 8-bit fixed-point with a negligible accuracy loss of 0.2% on 4-class MI, and present an energy-efficient hardware-aware implementation on the Mr.Wolf parallel ultra-low power (PULP) System-on-Chip (SoC) by utilizing its custom RISC-V ISA extensions and 8-core compute cluster. With our proposed optimization steps, we can obtain an overall speedup of 64x and a reduction of up to 85% in memory footprint with respect to a single-core layer-wise baseline implementation. Our implementation takes only 5.82 ms and consumes 0.627 mJ per inference. With 20.692GMAC/s/W, it is 252x more energy-efficient than an EEGNET implementation on an ARM Cortex-M7 (0.082GMAC/s/W).
RPR: Random Partition Relaxation for Training; Binary and Ternary Weight Neural Networks
Jan 04, 2020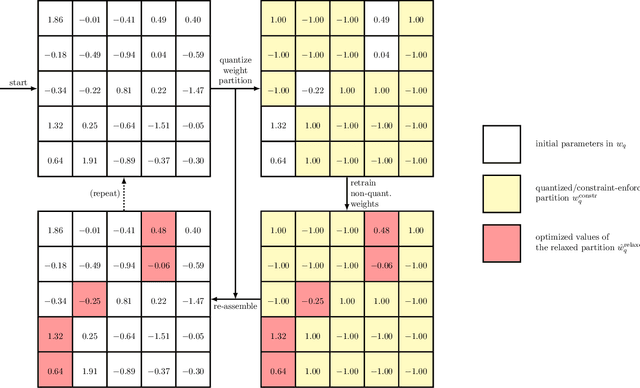
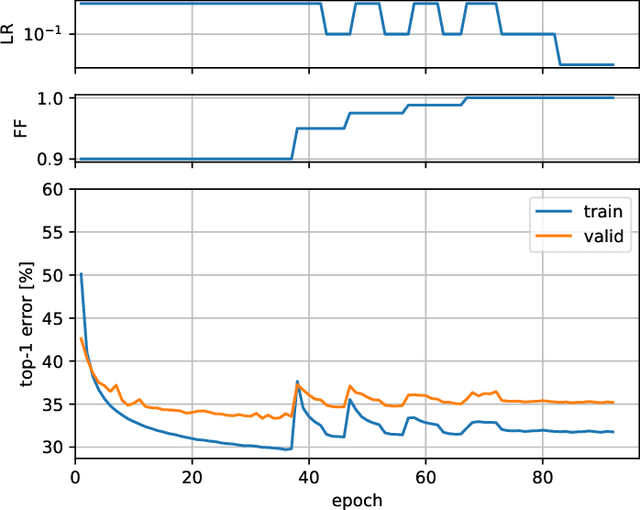
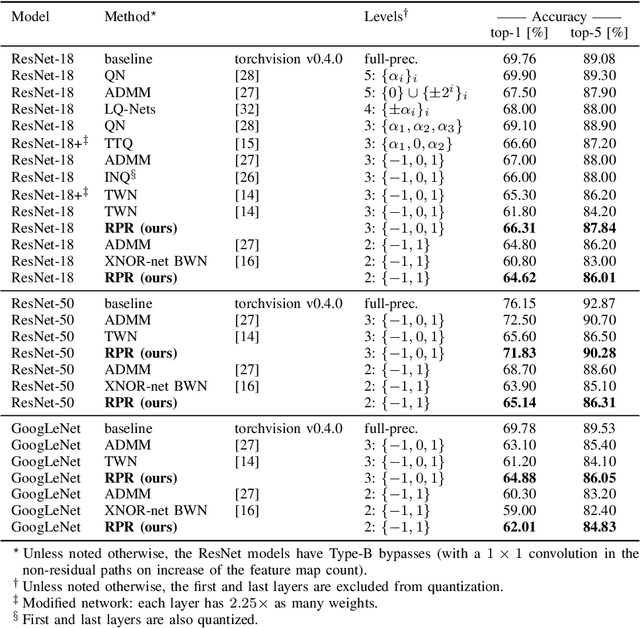
We present Random Partition Relaxation (RPR), a method for strong quantization of neural networks weight to binary (+1/-1) and ternary (+1/0/-1) values. Starting from a pre-trained model, we quantize the weights and then relax random partitions of them to their continuous values for retraining before re-quantizing them and switching to another weight partition for further adaptation. We demonstrate binary and ternary-weight networks with accuracies beyond the state-of-the-art for GoogLeNet and competitive performance for ResNet-18 and ResNet-50 using an SGD-based training method that can easily be integrated into existing frameworks.
HR-SAR-Net: A Deep Neural Network for Urban Scene Segmentation from High-Resolution SAR Data
Dec 10, 2019
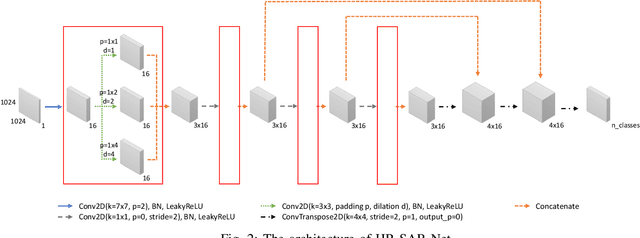

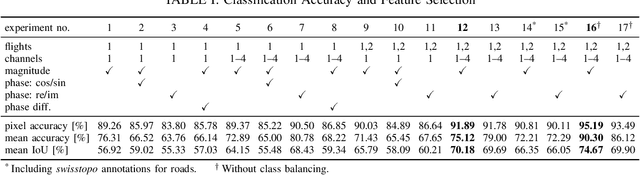
Synthetic aperture radar (SAR) data is becoming increasingly available to a wide range of users through commercial service providers with resolutions reaching 0.5m/px. Segmenting SAR data still requires skilled personnel, limiting the potential for large-scale use. We show that it is possible to automatically and reliably perform urban scene segmentation from next-gen resolution SAR data (0.15m/px) using deep neural networks (DNNs), achieving a pixel accuracy of 95.19% and a mean IoU of 74.67% with data collected over a region of merely 2.2km${}^2$. The presented DNN is not only effective, but is very small with only 63k parameters and computationally simple enough to achieve a throughput of around 500Mpx/s using a single GPU. We further identify that additional SAR receive antennas and data from multiple flights massively improve the segmentation accuracy. We describe a procedure for generating a high-quality segmentation ground truth from multiple inaccurate building and road annotations, which has been crucial to achieving these segmentation results.
FANN-on-MCU: An Open-Source Toolkit for Energy-Efficient Neural Network Inference at the Edge of the Internet of Things
Nov 08, 2019
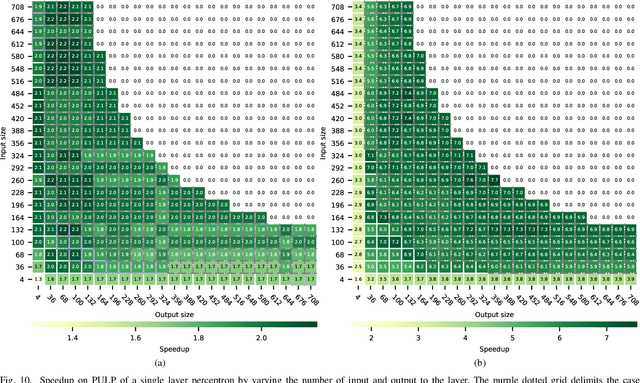
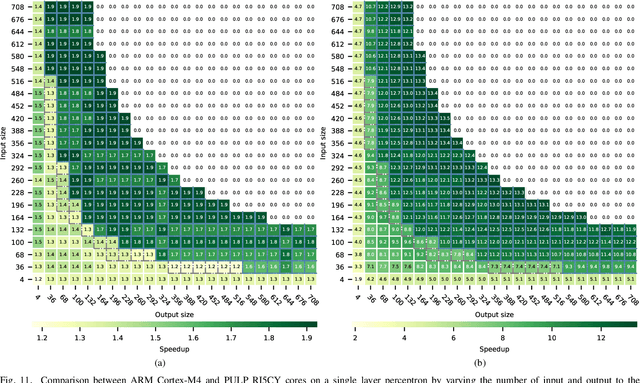
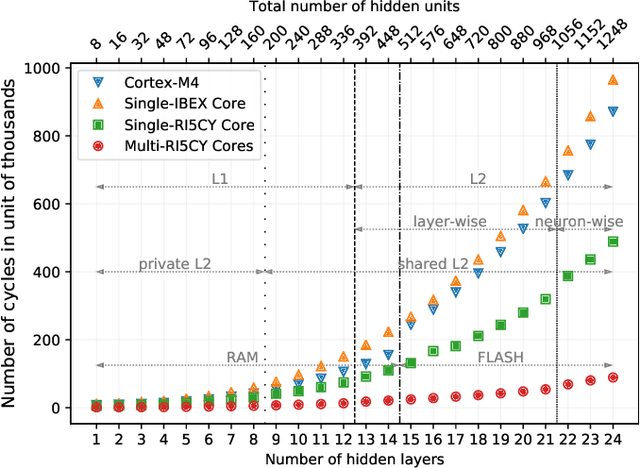
The growing number of low-power smart devices in the Internet of Things is coupled with the concept of "Edge Computing", that is moving some of the intelligence, especially machine learning, towards the edge of the network. Enabling machine learning algorithms to run on resource-constrained hardware, typically on low-power smart devices, is challenging in terms of hardware (optimized and energy-efficient integrated circuits), algorithmic and firmware implementations. This paper presents FANN-on-MCU, an open-source toolkit built upon the Fast Artificial Neural Network (FANN) library to run lightweight and energy-efficient neural networks on microcontrollers based on both the ARM Cortex-M series and the novel RISC-V-based Parallel Ultra-Low-Power (PULP) platform. The toolkit takes multi-layer perceptrons trained with FANN and generates code targeted at execution on low-power microcontrollers either with a floating-point unit (i.e., ARM Cortex-M4F and M7F) or without (i.e., ARM Cortex M0-M3 or PULP-based processors). This paper also provides an architectural performance evaluation of neural networks on the most popular ARM Cortex-M family and the parallel RISC-V processor called Mr. Wolf. The evaluation includes experimental results for three different applications using a self-sustainable wearable multi-sensor bracelet. Experimental results show a measured latency in the order of only a few microseconds and a power consumption of few milliwatts while keeping the memory requirements below the limitations of the targeted microcontrollers. In particular, the parallel implementation on the octa-core RISC-V platform reaches a speedup of 22x and a 69% reduction in energy consumption with respect to a single-core implementation on Cortex-M4 for continuous real-time classification.
EBPC: Extended Bit-Plane Compression for Deep Neural Network Inference and Training Accelerators
Aug 30, 2019
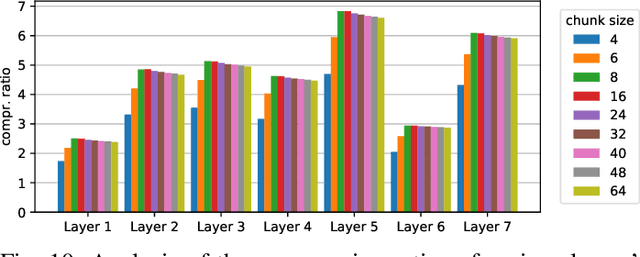
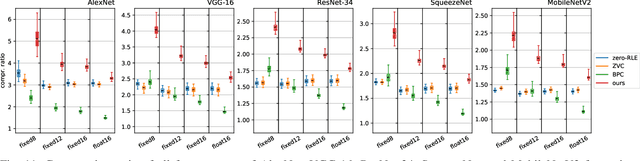
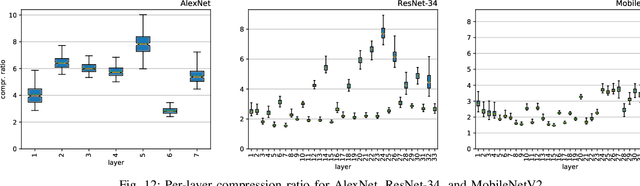
In the wake of the success of convolutional neural networks in image classification, object recognition, speech recognition, etc., the demand for deploying these compute-intensive ML models on embedded and mobile systems with tight power and energy constraints at low cost, as well as for boosting throughput in data centers, is growing rapidly. This has sparked a surge of research into specialized hardware accelerators. Their performance is typically limited by I/O bandwidth, power consumption is dominated by I/O transfers to off-chip memory, and on-chip memories occupy a large part of the silicon area. We introduce and evaluate a novel, hardware-friendly and lossless compression scheme for the feature maps present within convolutional neural networks. Its hardware implementation fits into 2.8 kGE and 1.7 kGE of silicon area for the compressor and decompressor, respectively. We show that an average compression ratio of 5.1x for AlexNet, 4x for VGG-16, 2.4x for ResNet-34 and 2.2x for MobileNetV2 can be achieved---a gain of 45--70% over existing methods. Our approach also works effectively for various number formats, has a low frame-to-frame variance on the compression ratio, and achieves compression factors for gradient map compression during training that are even better than for inference.
Additive Noise Annealing and Approximation Properties of Quantized Neural Networks
May 24, 2019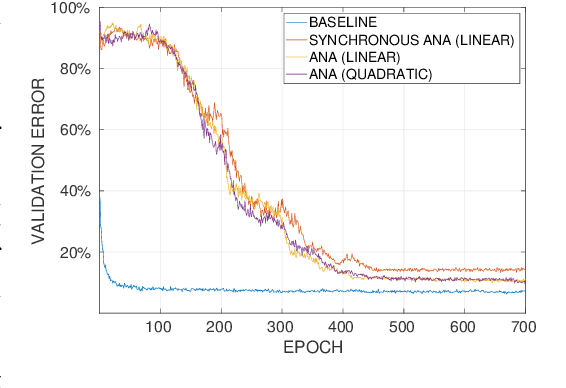


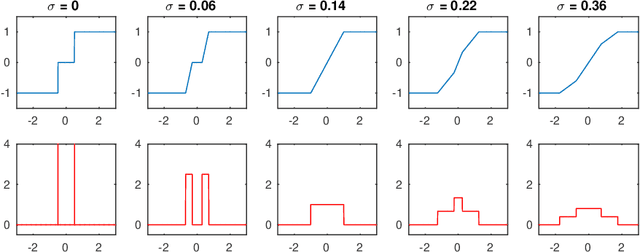
We present a theoretical and experimental investigation of the quantization problem for artificial neural networks. We provide a mathematical definition of quantized neural networks and analyze their approximation capabilities, showing in particular that any Lipschitz-continuous map defined on a hypercube can be uniformly approximated by a quantized neural network. We then focus on the regularization effect of additive noise on the arguments of multi-step functions inherent to the quantization of continuous variables. In particular, when the expectation operator is applied to a non-differentiable multi-step random function, and if the underlying probability density is differentiable (in either classical or weak sense), then a differentiable function is retrieved, with explicit bounds on its Lipschitz constant. Based on these results, we propose a novel gradient-based training algorithm for quantized neural networks that generalizes the straight-through estimator, acting on noise applied to the network's parameters. We evaluate our algorithm on the CIFAR-10 and ImageNet image classification benchmarks, showing state-of-the-art performance on AlexNet and MobileNetV2 for ternary networks.
Extended Bit-Plane Compression for Convolutional Neural Network Accelerators
Oct 01, 2018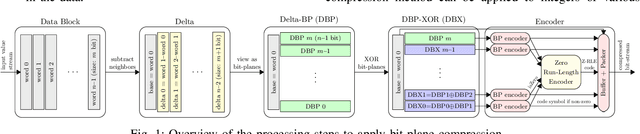
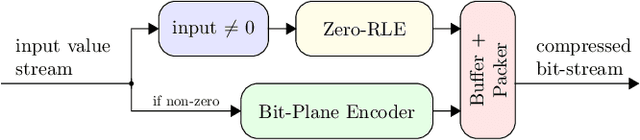
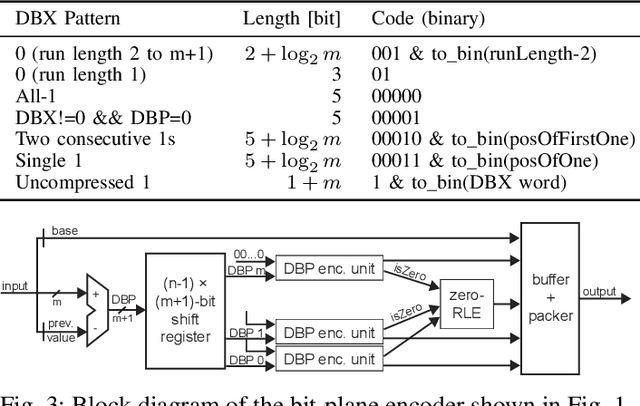
After the tremendous success of convolutional neural networks in image classification, object detection, speech recognition, etc., there is now rising demand for deployment of these compute-intensive ML models on tightly power constrained embedded and mobile systems at low cost as well as for pushing the throughput in data centers. This has triggered a wave of research towards specialized hardware accelerators. Their performance is often constrained by I/O bandwidth and the energy consumption is dominated by I/O transfers to off-chip memory. We introduce and evaluate a novel, hardware-friendly compression scheme for the feature maps present within convolutional neural networks. We show that an average compression ratio of 4.4x relative to uncompressed data and a gain of 60% over existing method can be achieved for ResNet-34 with a compression block requiring <300 bit of sequential cells and minimal combinational logic.
CBinfer: Exploiting Frame-to-Frame Locality for Faster Convolutional Network Inference on Video Streams
Aug 15, 2018
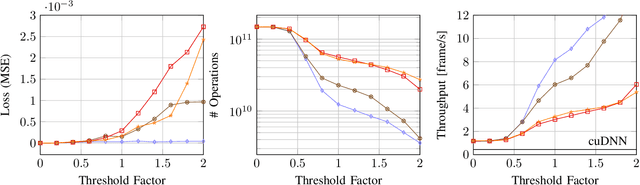
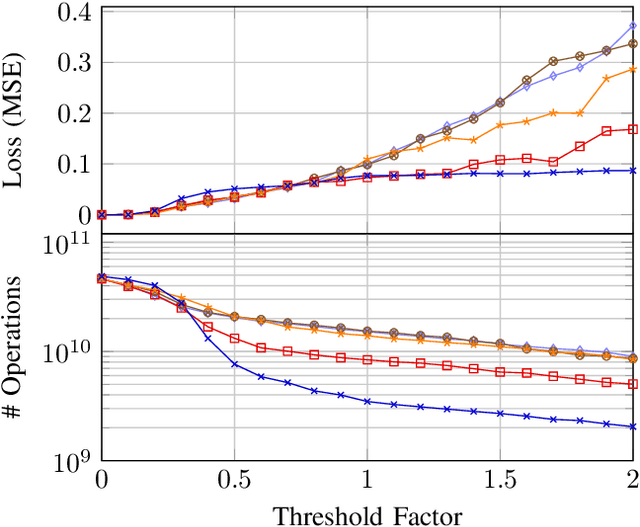
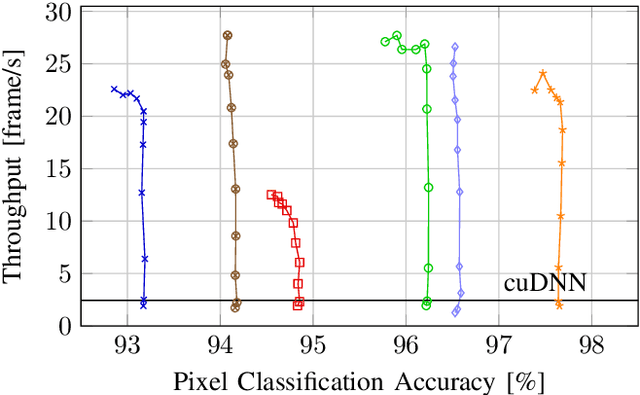
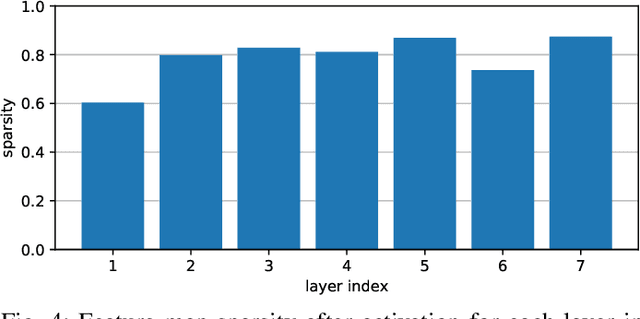
The last few years have brought advances in computer vision at an amazing pace, grounded on new findings in deep neural network construction and training as well as the availability of large labeled datasets. Applying these networks to images demands a high computational effort and pushes the use of state-of-the-art networks on real-time video data out of reach of embedded platforms. Many recent works focus on reducing network complexity for real-time inference on embedded computing platforms. We adopt an orthogonal viewpoint and propose a novel algorithm exploiting the spatio-temporal sparsity of pixel changes. This optimized inference procedure resulted in an average speed-up of 9.1x over cuDNN on the Tegra X2 platform at a negligible accuracy loss of <0.1% and no retraining of the network for a semantic segmentation application. Similarly, an average speed-up of 7.0x has been achieved for a pose detection DNN on static camera video surveillance data. These throughput gains combined with a lower power consumption result in an energy efficiency of 511 GOp/s/W compared to 70 GOp/s/W for the baseline.
Hyperdrive: A Systolically Scalable Binary-Weight CNN Inference Engine for mW IoT End-Nodes
Jun 13, 2018
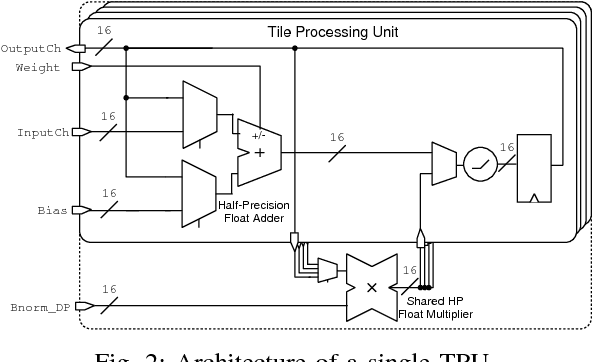
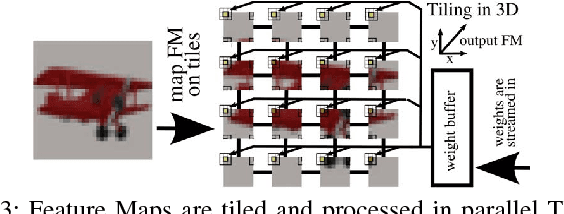
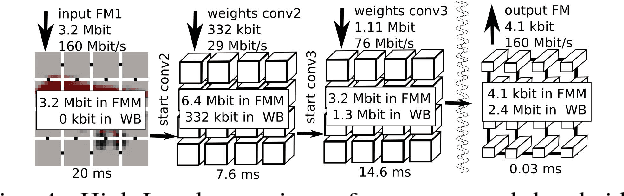
Deep neural networks have achieved impressive results in computer vision and machine learning. Unfortunately, state-of-the-art networks are extremely compute- and memory-intensive which makes them unsuitable for mW-devices such as IoT end-nodes. Aggressive quantization of these networks dramatically reduces the computation and memory footprint. Binary-weight neural networks (BWNs) follow this trend, pushing weight quantization to the limit. Hardware accelerators for BWNs presented up to now have focused on core efficiency, disregarding I/O bandwidth and system-level efficiency that are crucial for deployment of accelerators in ultra-low power devices. We present Hyperdrive: a BWN accelerator dramatically reducing the I/O bandwidth exploiting a novel binary-weight streaming approach, and capable of handling high-resolution images by virtue of its systolic-scalable architecture. We achieve a 5.9 TOp/s/W system-level efficiency (i.e. including I/Os)---2.2x higher than state-of-the-art BNN accelerators, even if our core uses resource-intensive FP16 arithmetic for increased robustness.
XNORBIN: A 95 TOp/s/W Hardware Accelerator for Binary Convolutional Neural Networks
Mar 05, 2018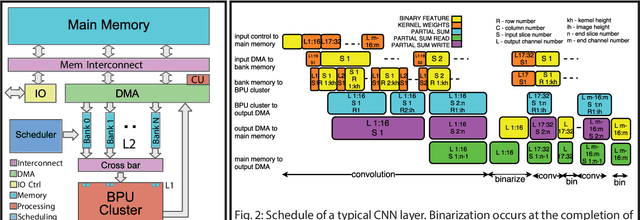
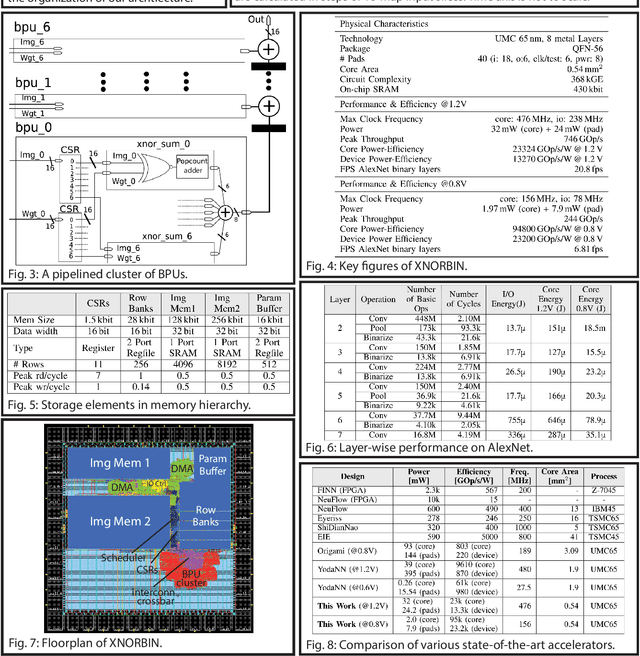
Deploying state-of-the-art CNNs requires power-hungry processors and off-chip memory. This precludes the implementation of CNNs in low-power embedded systems. Recent research shows CNNs sustain extreme quantization, binarizing their weights and intermediate feature maps, thereby saving 8-32\x memory and collapsing energy-intensive sum-of-products into XNOR-and-popcount operations. We present XNORBIN, an accelerator for binary CNNs with computation tightly coupled to memory for aggressive data reuse. Implemented in UMC 65nm technology XNORBIN achieves an energy efficiency of 95 TOp/s/W and an area efficiency of 2.0 TOp/s/MGE at 0.8 V.