 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPCCN: Densely-Connected Pyramid Complex Convolutional Network for Robust Speech Separation And Extraction
Dec 27, 2021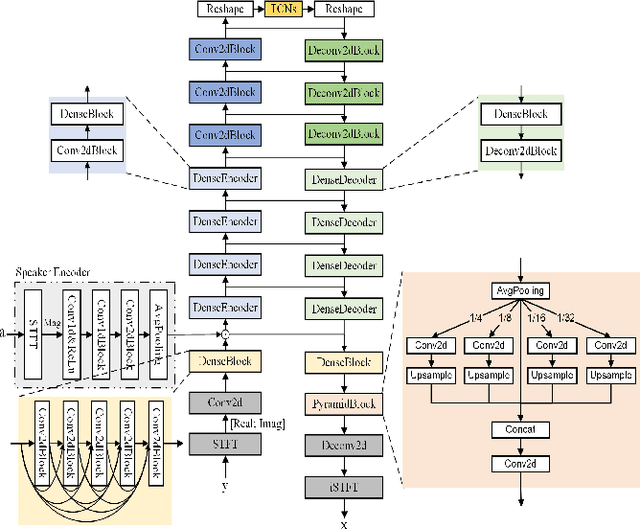
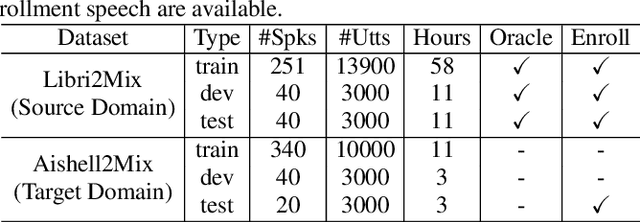
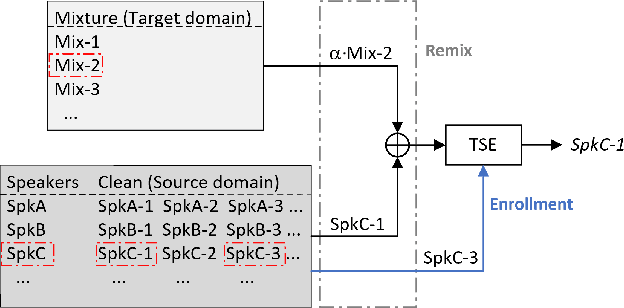

In recent years, a number of time-domain speech separation methods have been proposed. However, most of them are very sensitive to the environments and wide domain coverage tasks. In this paper, from the time-frequency domain perspective, we propose a densely-connected pyramid complex convolutional network, termed DPCCN, to improve the robustness of speech separation under complicated conditions. Furthermore, we generalize the DPCCN to target speech extraction (TSE) by integrating a new specially designed speaker encoder. Moreover, we also investigate the robustness of DPCCN to unsupervised cross-domain TSE tasks. A Mixture-Remix approach is proposed to adapt the target domain acoustic characteristics for fine-tuning the source model. We evaluate the proposed methods not only under noisy and reverberant in-domain condition, but also in clean but cross-domain conditions. Results show that for both speech separation and extraction, the DPCCN-based systems achieve significantly better performance and robustness than the currently dominating time-domain methods, especially for the cross-domain tasks. Particularly, we find that the Mixture-Remix fine-tuning with DPCCN significantly outperforms the TD-SpeakerBeam for unsupervised cross-domain TSE, with around 3.5 dB performance improvement on target domain test set, without any source domain performance degradation.
Speaker embeddings by modeling channel-wise correlations
Apr 06, 2021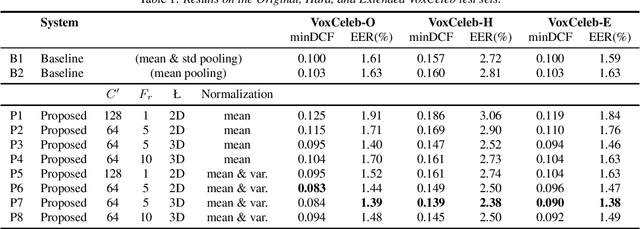
Speaker embeddings extracted with deep 2D convolutional neural networks are typically modeled as projections of first and second order statistics of channel-frequency pairs onto a linear layer, using either average or attentive pooling along the time axis. In this paper we examine an alternative pooling method, where pairwise correlations between channels for given frequencies are used as statistics. The method is inspired by style-transfer methods in computer vision, where the style of an image, modeled by the matrix of channel-wise correlations, is transferred to another image, in order to produce a new image having the style of the first and the content of the second. By drawing analogies between image style and speaker characteristics, and between image content and phonetic sequence, we explore the use of such channel-wise correlations features to train a ResNet architecture in an end-to-end fashion. Our experiments on VoxCeleb demonstrate the effectiveness of the proposed pooling method in speaker recognition.
A Hierarchical Subspace Model for Language-Attuned Acoustic Unit Discovery
Nov 09, 2020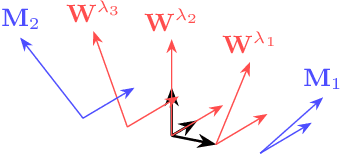
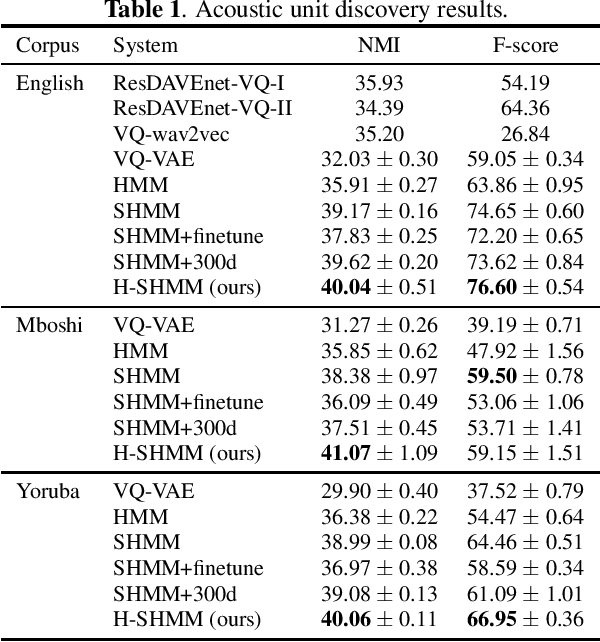
In this work, we propose a hierarchical subspace model for acoustic unit discovery. In this approach, we frame the task as one of learning embeddings on a low-dimensional phonetic subspace, and simultaneously specify the subspace itself as an embedding on a hyper-subspace. We train the hyper-subspace on a set of transcribed languages and transfer it to the target language. In the target language, we infer both the language and unit embeddings in an unsupervised manner, and in so doing, we simultaneously learn a subspace of units specific to that language and the units that dwell on it. We conduct our experiments on TIMIT and two low-resource languages: Mboshi and Yoruba. Results show that our model outperforms major acoustic unit discovery techniques, both in terms of clustering quality and segmentation accuracy.
A Technical Report: BUT Speech Translation Systems
Oct 22, 2020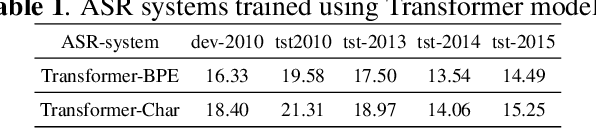
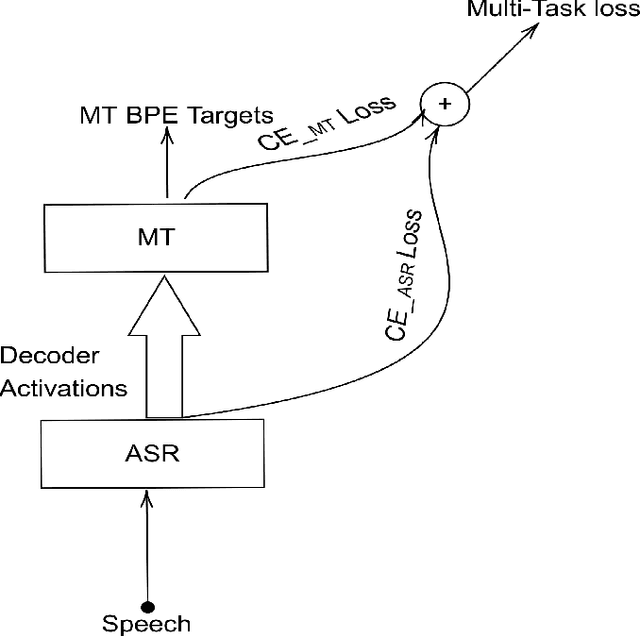
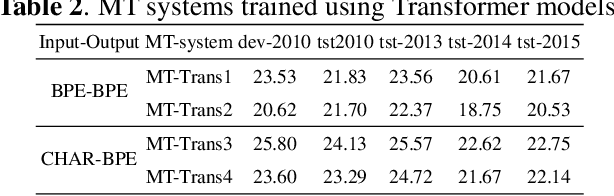
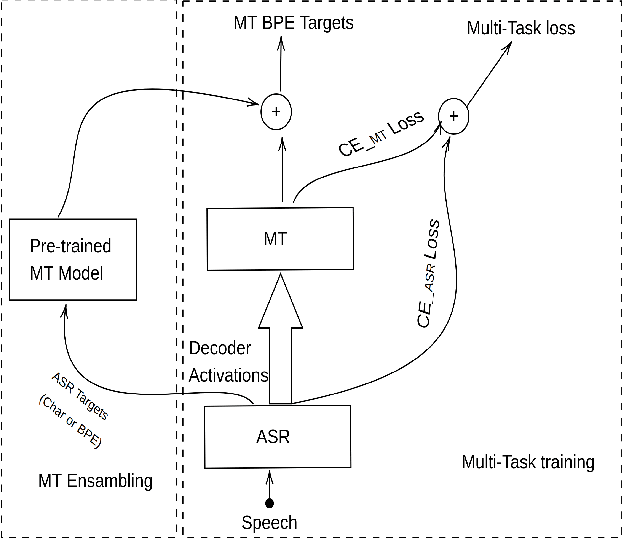
The paper describes the BUT's speech translation systems. The systems are English$\longrightarrow$German offline speech translation systems. The systems are based on our previous works \cite{Jointly_trained_transformers}. Though End-to-End and cascade~(ASR-MT) spoken language translation~(SLT) systems are reaching comparable performances, a large degradation is observed when translating ASR hypothesis compared to the oracle input text. To reduce this performance degradation, we have jointly-trained ASR and MT modules with ASR objective as an auxiliary loss. Both the networks are connected through the neural hidden representations. This model has an End-to-End differentiable path with respect to the final objective function and also utilizes the ASR objective for better optimization. During the inference both the modules(i.e., ASR and MT) are connected through the hidden representations corresponding to the n-best hypotheses. Ensembling with independently trained ASR and MT models have further improved the performance of the system.
Short-duration Speaker Verification (SdSV) Challenge 2020: the Challenge Evaluation Plan
Jan 10, 2020
This document describes the Short-duration Speaker Verification (SdSV) Challenge 2020. The main goal of the challenge is to evaluate new technologies for text-dependent (TD) and text-independent (TI) speaker verification (SV) in a short duration scenario. The proposed challenge evaluates SdSV with varying degree of phonetic overlap between the enrollment and test utterances (cross-lingual). It is the first challenge with a broad focus on systematic benchmark and analysis on varying degrees of phonetic variability on short-duration speaker recognition. We expect that modern methods (deep neural networks in particular) will play a key role.
Self-supervised speaker embeddings
Apr 23, 2019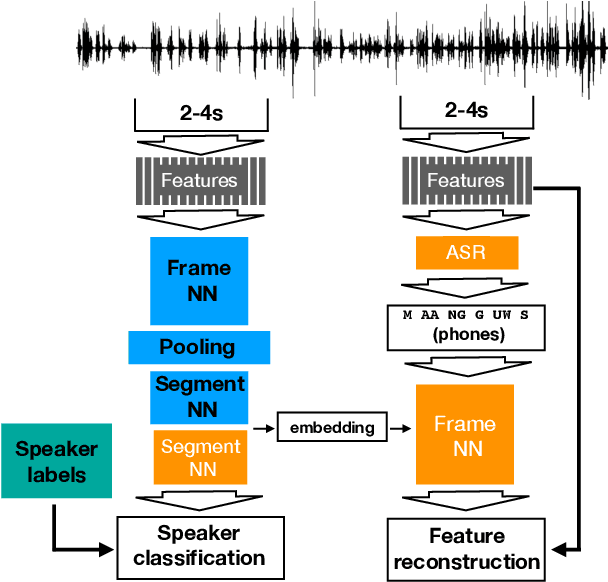
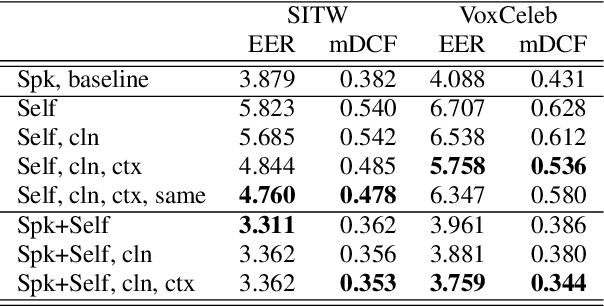
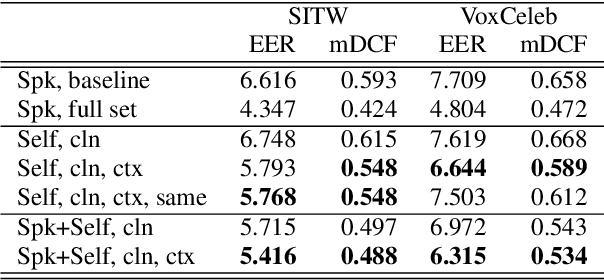
Contrary to i-vectors, speaker embeddings such as x-vectors are incapable of leveraging unlabelled utterances, due to the classification loss over training speakers. In this paper, we explore an alternative training strategy to enable the use of unlabelled utterances in training. We propose to train speaker embedding extractors via reconstructing the frames of a target speech segment, given the inferred embedding of another speech segment of the same utterance. We do this by attaching to the standard speaker embedding extractor a decoder network, which we feed not merely with the speaker embedding, but also with the estimated phone sequence of the target frame sequence. The reconstruction loss can be used either as a single objective, or be combined with the standard speaker classification loss. In the latter case, it acts as a regularizer, encouraging generalizability to speakers unseen during training. In all cases, the proposed architectures are trained from scratch and in an end-to-end fashion. We demonstrate the benefits from the proposed approach on VoxCeleb and Speakers in the wild, and we report notable improvements over the baseline.
How to Improve Your Speaker Embeddings Extractor in Generic Toolkits
Nov 05, 2018
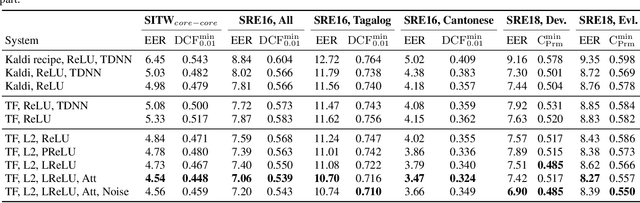
Recently, speaker embeddings extracted with deep neural networks became the state-of-the-art method for speaker verification. In this paper we aim to facilitate its implementation on a more generic toolkit than Kaldi, which we anticipate to enable further improvements on the method. We examine several tricks in training, such as the effects of normalizing input features and pooled statistics, different methods for preventing overfitting as well as alternative non-linearities that can be used instead of Rectifier Linear Units. In addition, we investigate the difference in performance between TDNN and CNN, and between two types of attention mechanism. Experimental results on Speaker in the Wild, SRE 2016 and SRE 2018 datasets demonstrate the effectiveness of the proposed implementation.
Spoken Pass-Phrase Verification in the i-vector Space
Sep 28, 2018

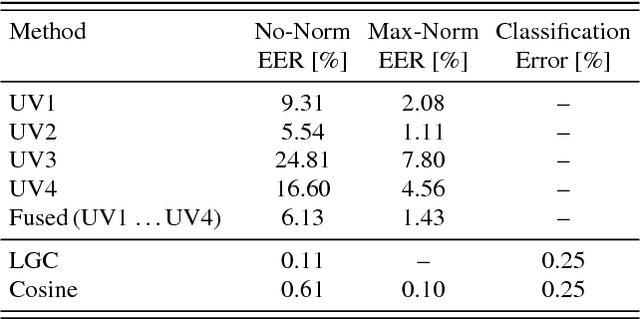
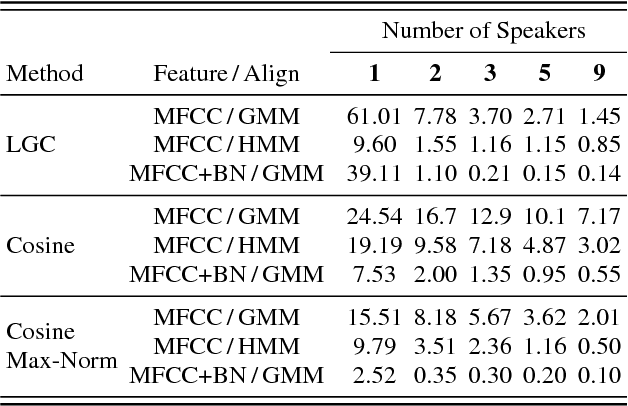
The task of spoken pass-phrase verification is to decide whether a test utterance contains the same phrase as given enrollment utterances. Beside other applications, pass-phrase verification can complement an independent speaker verification subsystem in text-dependent speaker verification. It can also be used for liveness detection by verifying that the user is able to correctly respond to a randomly prompted phrase. In this paper, we build on our previous work on i-vector based text-dependent speaker verification, where we have shown that i-vectors extracted using phrase specific Hidden Markov Models (HMMs) or using Deep Neural Network (DNN) based bottle-neck (BN) features help to reject utterances with wrong pass-phrases. We apply the same i-vector extraction techniques to the stand-alone task of speaker-independent spoken pass-phrase classification and verification. The experiments on RSR2015 and RedDots databases show that very simple scoring techniques (e.g. cosine distance scoring) applied to such i-vectors can provide results superior to those previously published on the same data.
Residual Memory Networks: Feed-forward approach to learn long temporal dependencies
Aug 06, 2018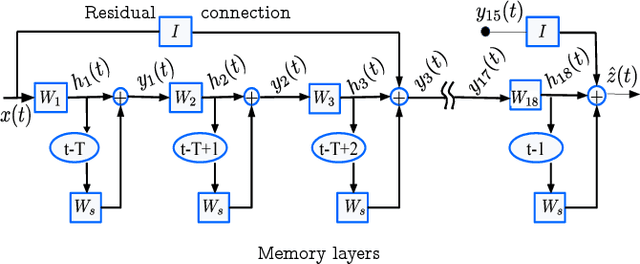
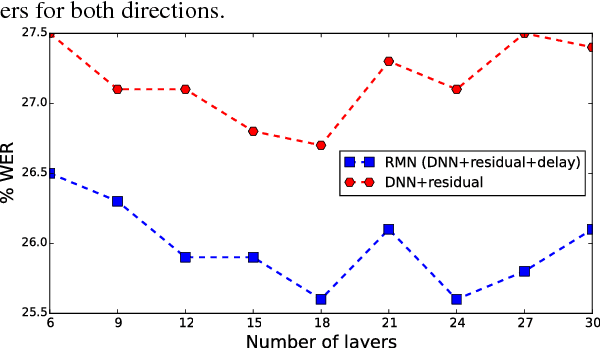
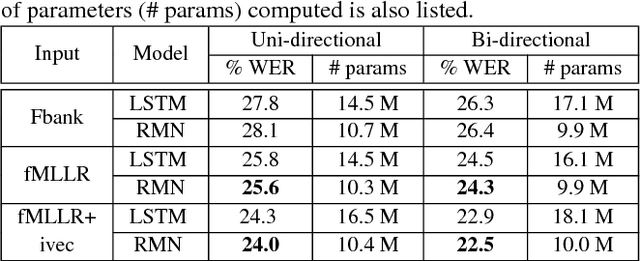
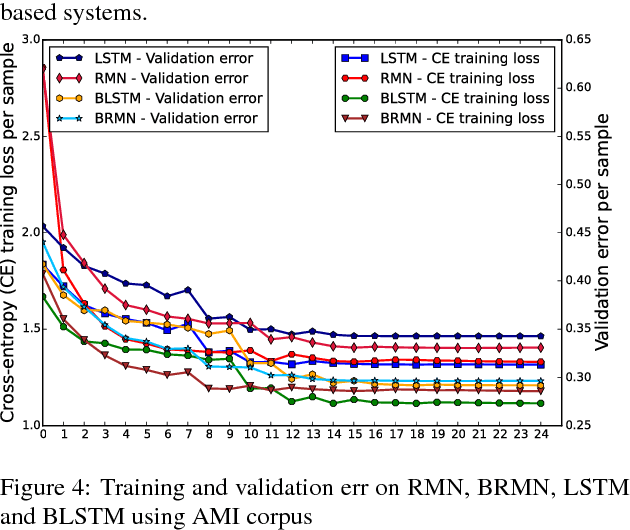
Training deep recurrent neural network (RNN) architectures is complicated due to the increased network complexity. This disrupts the learning of higher order abstracts using deep RNN. In case of feed-forward networks training deep structures is simple and faster while learning long-term temporal information is not possible. In this paper we propose a residual memory neural network (RMN) architecture to model short-time dependencies using deep feed-forward layers having residual and time delayed connections. The residual connection paves way to construct deeper networks by enabling unhindered flow of gradients and the time delay units capture temporal information with shared weights. The number of layers in RMN signifies both the hierarchical processing depth and temporal depth. The computational complexity in training RMN is significantly less when compared to deep recurrent networks. RMN is further extended as bi-directional RMN (BRMN) to capture both past and future information. Experimental analysis is done on AMI corpus to substantiate the capability of RMN in learning long-term information and hierarchical information. Recognition performance of RMN trained with 300 hours of Switchboard corpus is compared with various state-of-the-art LVCSR systems. The results indicate that RMN and BRMN gains 6 % and 3.8 % relative improvement over LSTM and BLSTM networks.
Fast variational Bayes for heavy-tailed PLDA applied to i-vectors and x-vectors
Mar 24, 2018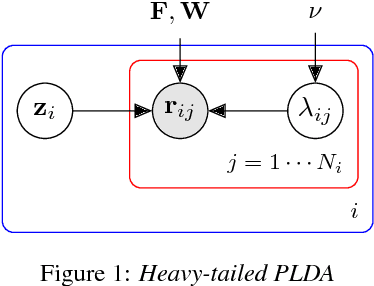
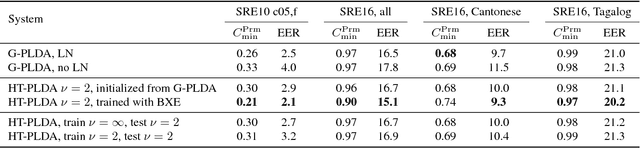
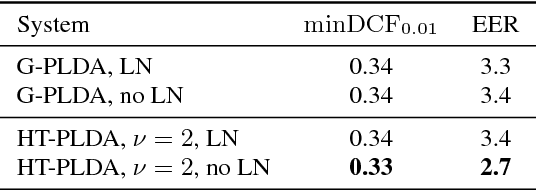
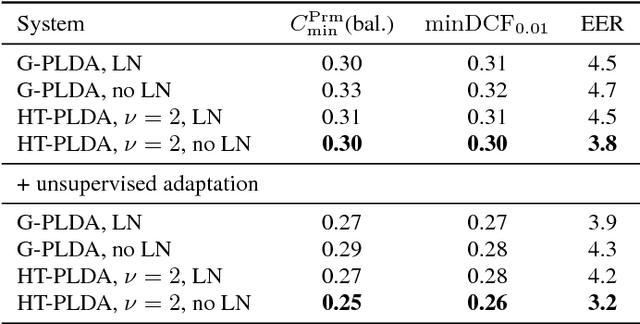
The standard state-of-the-art backend for text-independent speaker recognizers that use i-vectors or x-vectors, is Gaussian PLDA (G-PLDA), assisted by a Gaussianization step involving length normalization. G-PLDA can be trained with both generative or discriminative methods. It has long been known that heavy-tailed PLDA (HT-PLDA), applied without length normalization, gives similar accuracy, but at considerable extra computational cost. We have recently introduced a fast scoring algorithm for a discriminatively trained HT-PLDA backend. This paper extends that work by introducing a fast, variational Bayes, generative training algorithm. We compare old and new backends, with and without length-normalization, with i-vectors and x-vectors, on SRE'10, SRE'16 and SITW.