 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlimmable Compressive Autoencoders for Practical Neural Image Compression
Mar 29, 2021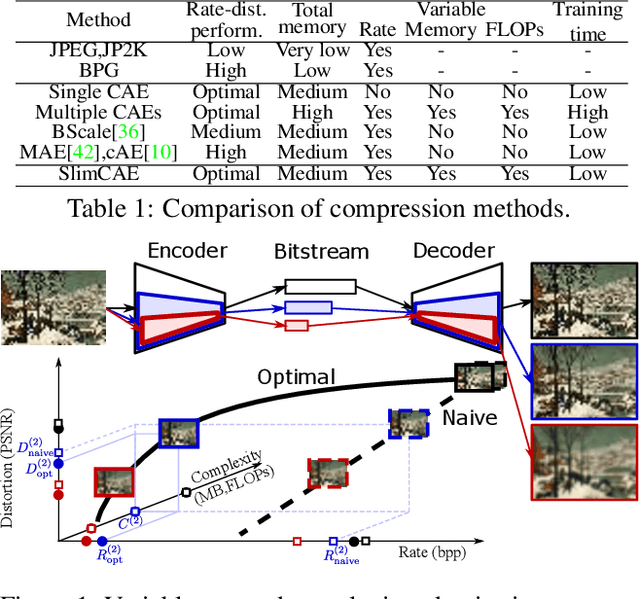
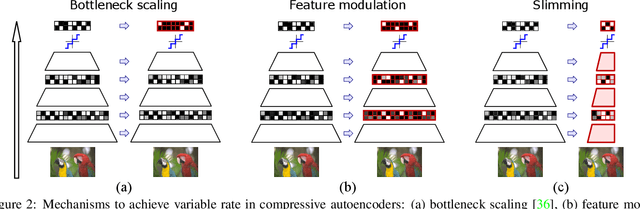
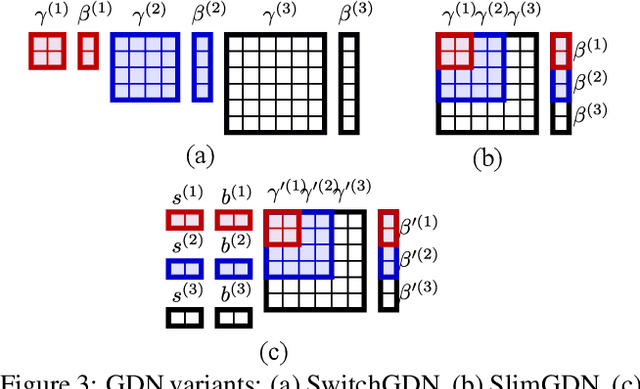
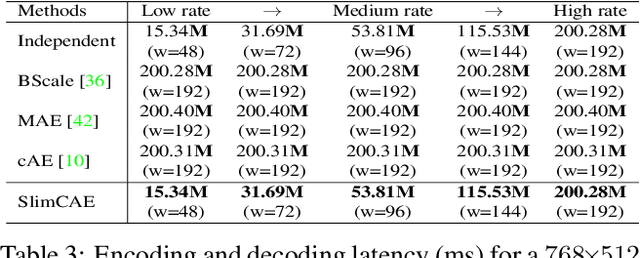
Neural image compression leverages deep neural networks to outperform traditional image codecs in rate-distortion performance. However, the resulting models are also heavy, computationally demanding and generally optimized for a single rate, limiting their practical use. Focusing on practical image compression, we propose slimmable compressive autoencoders (SlimCAEs), where rate (R) and distortion (D) are jointly optimized for different capacities. Once trained, encoders and decoders can be executed at different capacities, leading to different rates and complexities. We show that a successful implementation of SlimCAEs requires suitable capacity-specific RD tradeoffs. Our experiments show that SlimCAEs are highly flexible models that provide excellent rate-distortion performance, variable rate, and dynamic adjustment of memory, computational cost and latency, thus addressing the main requirements of practical image compression.
On Implicit Attribute Localization for Generalized Zero-Shot Learning
Mar 08, 2021
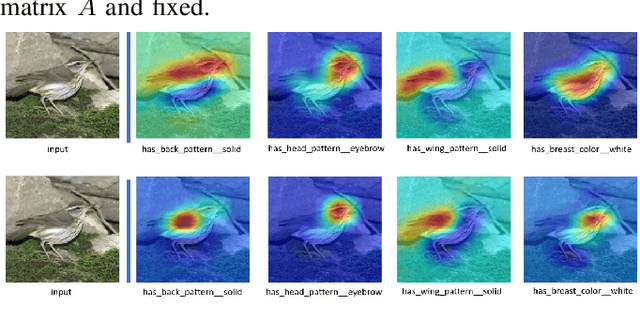

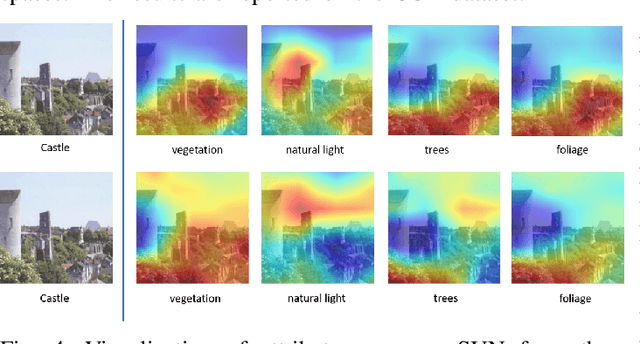
Zero-shot learning (ZSL) aims to discriminate images from unseen classes by exploiting relations to seen classes via their attribute-based descriptions. Since attributes are often related to specific parts of objects, many recent works focus on discovering discriminative regions. However, these methods usually require additional complex part detection modules or attention mechanisms. In this paper, 1) we show that common ZSL backbones (without explicit attention nor part detection) can implicitly localize attributes, yet this property is not exploited. 2) Exploiting it, we then propose SELAR, a simple method that further encourages attribute localization, surprisingly achieving very competitive generalized ZSL (GZSL) performance when compared with more complex state-of-the-art methods. Our findings provide useful insight for designing future GZSL methods, and SELAR provides an easy to implement yet strong baseline.
Unsupervised Domain Adaptation without Source Data by Casting a BAIT
Oct 28, 2020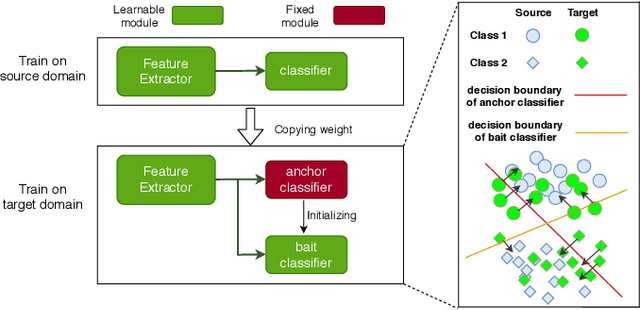
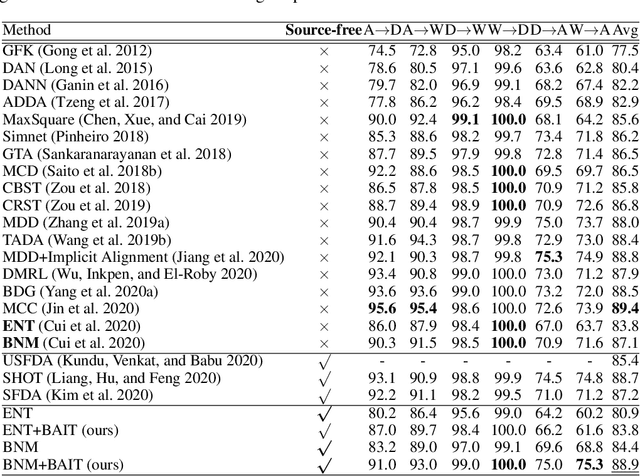
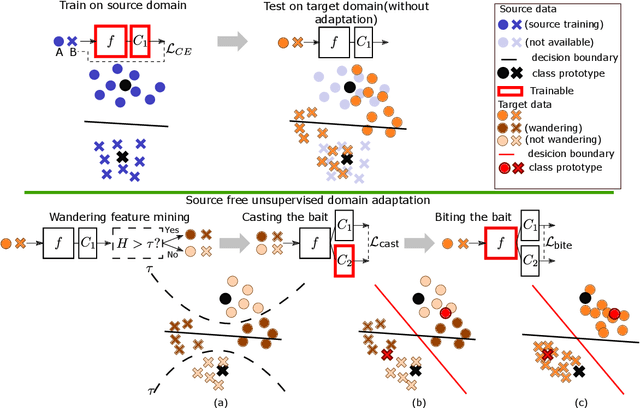
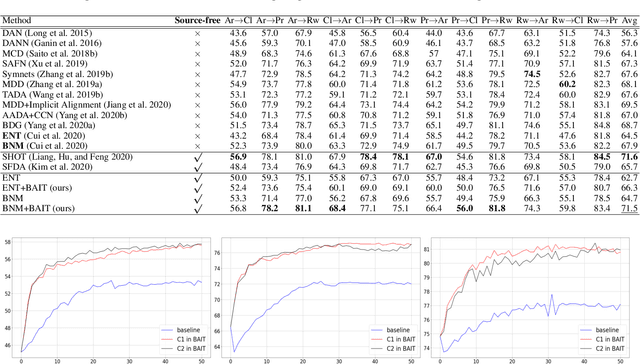
Unsupervised domain adaptation (UDA) aims to transfer the knowledge learned from labeled source domain to unlabeled target domain. Existing UDA methods require access to the data from the source domain, during adaptation to the target domain, which may not be feasible in some real-world situations. In this paper, we address Source-free Unsupervised Domain Adaptation (SFUDA), where the model has no access to any source data during the adaptation period. We propose a novel framework named BAIT to tackle SFUDA. Specifically, we first train the model on source domain. With the source-specific classifier head (referred to as anchor classifier) fixed, we further introduce a new learnable classifier head (referred to as bait classifier), which is initialized by the anchor classifier. When adapting the source model to the target domain, the source data are no more accessible and the bait classifier aims to push the target features towards the right side of the decision boundary of the anchor classifier, thus achieving the feature alignment. Experiment results show that proposed BAIT achieves state-of-the-art performance compared with existing normal UDA methods and several SFUDA methods.
Bookworm continual learning: beyond zero-shot learning and continual learning
Jul 06, 2020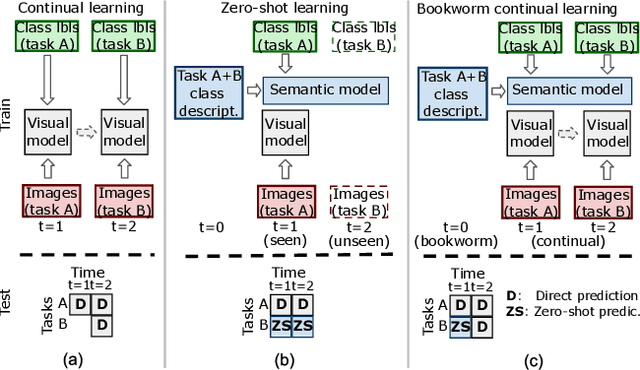
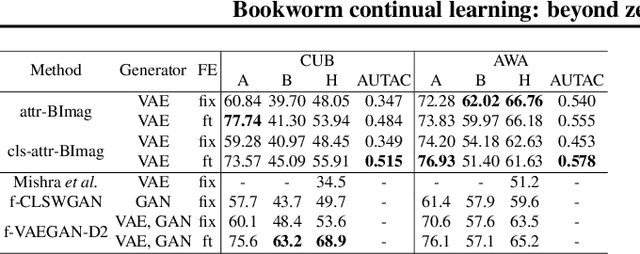
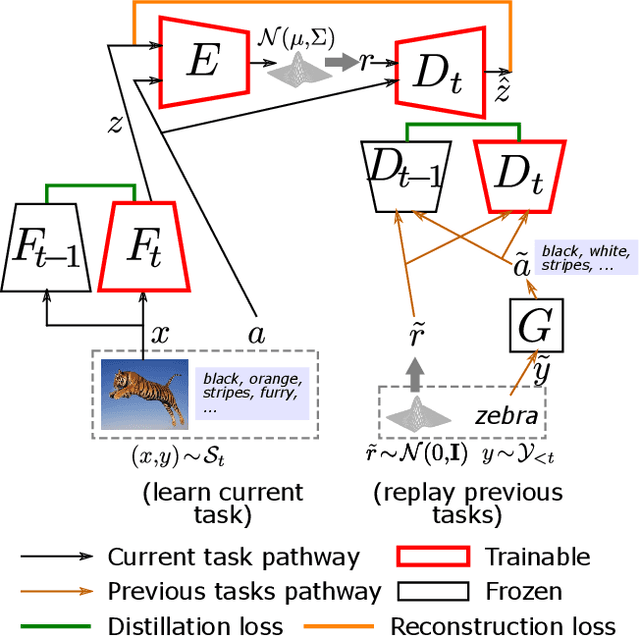
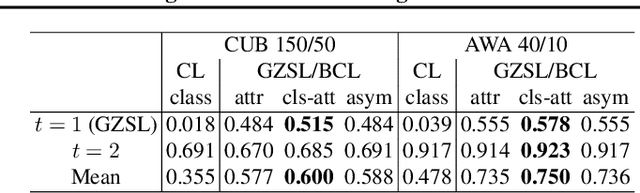
We propose bookworm continual learning(BCL), a flexible setting where unseen classes can be inferred via a semantic model, and the visual model can be updated continually. Thus BCL generalizes both continual learning (CL) and zero-shot learning (ZSL). We also propose the bidirectional imagination (BImag) framework to address BCL where features of both past and future classes are generated. We observe that conditioning the feature generator on attributes can actually harm the continual learning ability, and propose two variants (joint class-attribute conditioning and asymmetric generation) to alleviate this problem.
Simple and effective localized attribute representations for zero-shot learning
Jun 17, 2020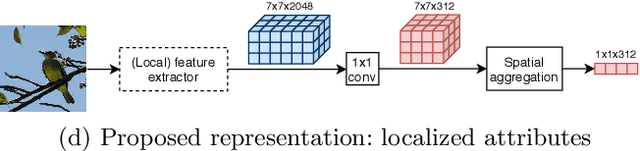
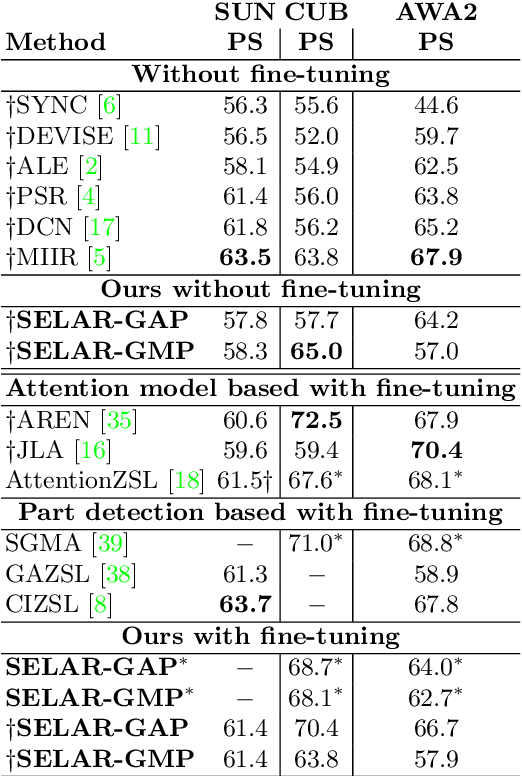

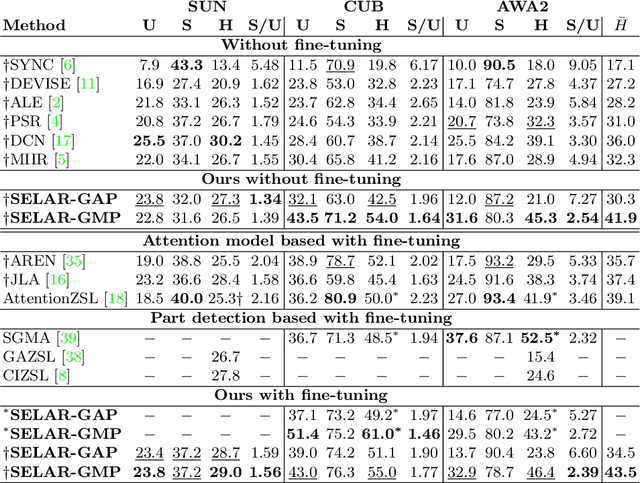
Zero-shot learning (ZSL) aims to discriminate images from unseen classes by exploiting relations to seen classes via their semantic descriptions. Some recent papers have shown the importance of localized features together with fine-tuning the feature extractor to obtain discriminative and transferable features. However, these methods require complex attention or part detection modules to perform explicit localization in the visual space. In contrast, in this paper we propose localizing representations in the semantic/attribute space, with a simple but effective pipeline where localization is implicit. Focusing on attribute representations, we show that our method obtains state-of-the-art performance on CUB and SUN datasets, and also achieves competitive results on AWA2 dataset, outperforming generally more complex methods with explicit localization in the visual space. Our method can be implemented easily, which can be used as a new baseline for zero shot-learning. In addition, our localized representations are highly interpretable as attribute-specific heatmaps.
Distributed Learning and Inference with Compressed Images
Apr 22, 2020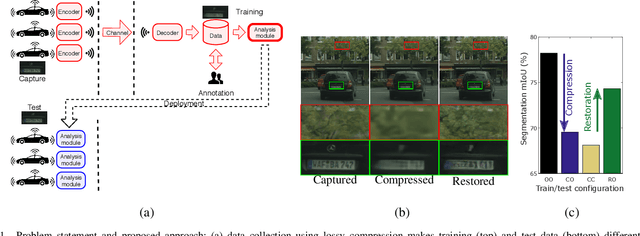
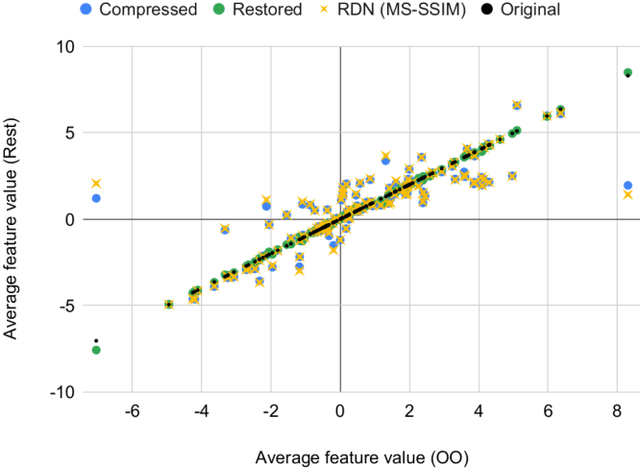

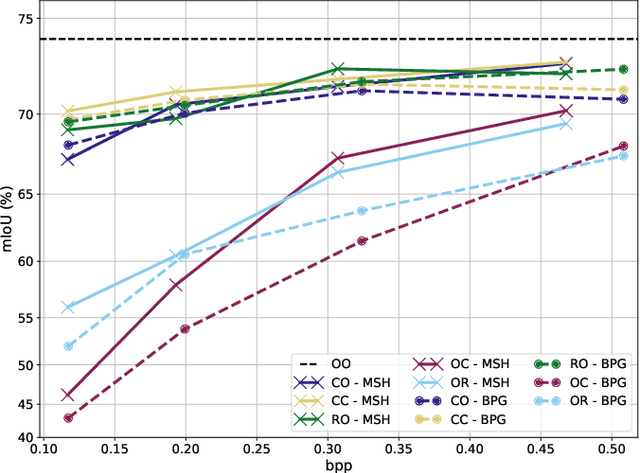
Modern computer vision requires processing large amounts of data, both while training the model and/or during inference, once the model is deployed. Scenarios where images are captured and processed in physically separated locations are increasingly common (e.g. autonomous vehicles, cloud computing). In addition, many devices suffer from limited resources to store or transmit data (e.g. storage space, channel capacity). In these scenarios, lossy image compression plays a crucial role to effectively increase the number of images collected under such constraints. However, lossy compression entails some undesired degradation of the data that may harm the performance of the downstream analysis task at hand, since important semantic information may be lost in the process. Moreover, we may only have compressed images at training time but are able to use original images at inference time, or vice versa, and in such a case, the downstream model suffers from covariate shift. In this paper, we analyze this phenomenon, with a special focus on vision-based perception for autonomous driving as a paradigmatic scenario. We see that loss of semantic information and covariate shift do indeed exist, resulting in a drop in performance that depends on the compression rate. In order to address the problem, we propose dataset restoration, based on image restoration with generative adversarial networks (GANs). Our method is agnostic to both the particular image compression method and the downstream task; and has the advantage of not adding additional cost to the deployed models, which is particularly important in resource-limited devices. The presented experiments focus on semantic segmentation as a challenging use case, cover a broad range of compression rates and diverse datasets, and show how our method is able to significantly alleviate the negative effects of compression on the downstream visual task.
Generative Feature Replay For Class-Incremental Learning
Apr 20, 2020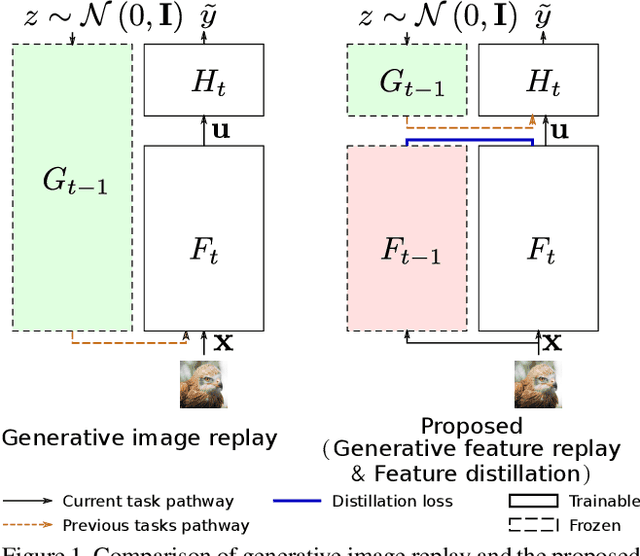

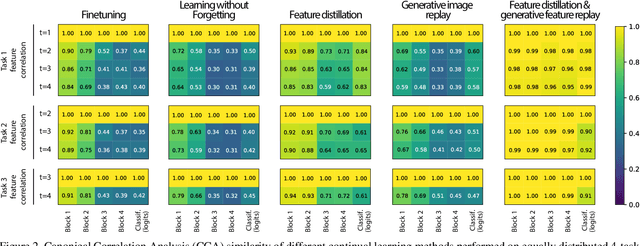
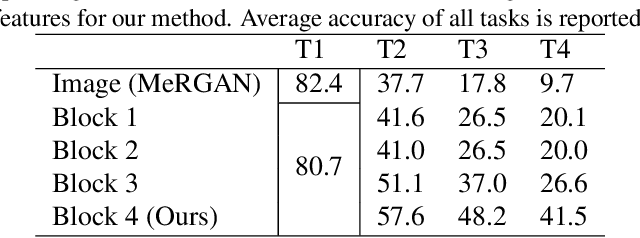
Humans are capable of learning new tasks without forgetting previous ones, while neural networks fail due to catastrophic forgetting between new and previously-learned tasks. We consider a class-incremental setting which means that the task-ID is unknown at inference time. The imbalance between old and new classes typically results in a bias of the network towards the newest ones. This imbalance problem can either be addressed by storing exemplars from previous tasks, or by using image replay methods. However, the latter can only be applied to toy datasets since image generation for complex datasets is a hard problem. We propose a solution to the imbalance problem based on generative feature replay which does not require any exemplars. To do this, we split the network into two parts: a feature extractor and a classifier. To prevent forgetting, we combine generative feature replay in the classifier with feature distillation in the feature extractor. Through feature generation, our method reduces the complexity of generative replay and prevents the imbalance problem. Our approach is computationally efficient and scalable to large datasets. Experiments confirm that our approach achieves state-of-the-art results on CIFAR-100 and ImageNet, while requiring only a fraction of the storage needed for exemplar-based continual learning. Code available at \url{https://github.com/xialeiliu/GFR-IL}.
Semantic Drift Compensation for Class-Incremental Learning
Apr 01, 2020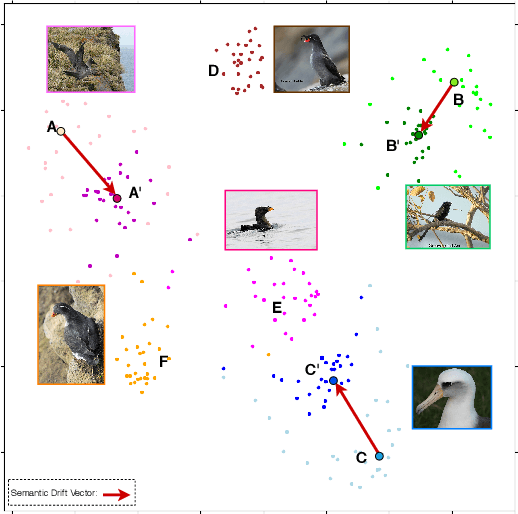
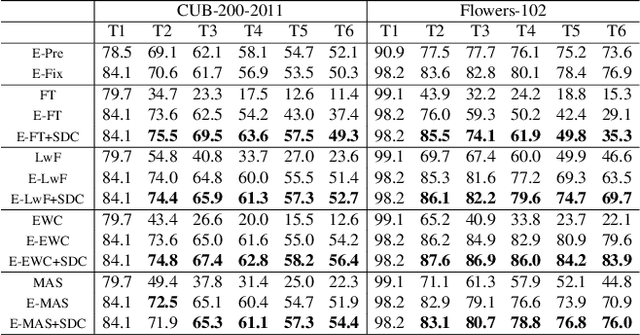
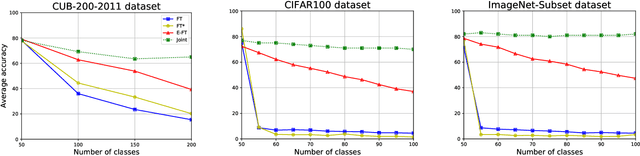
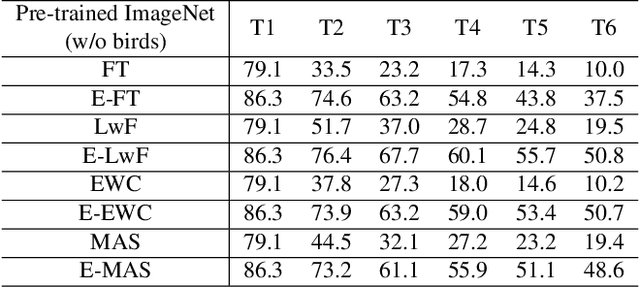
Class-incremental learning of deep networks sequentially increases the number of classes to be classified. During training, the network has only access to data of one task at a time, where each task contains several classes. In this setting, networks suffer from catastrophic forgetting which refers to the drastic drop in performance on previous tasks. The vast majority of methods have studied this scenario for classification networks, where for each new task the classification layer of the network must be augmented with additional weights to make room for the newly added classes. Embedding networks have the advantage that new classes can be naturally included into the network without adding new weights. Therefore, we study incremental learning for embedding networks. In addition, we propose a new method to estimate the drift, called semantic drift, of features and compensate for it without the need of any exemplars. We approximate the drift of previous tasks based on the drift that is experienced by current task data. We perform experiments on fine-grained datasets, CIFAR100 and ImageNet-Subset. We demonstrate that embedding networks suffer significantly less from catastrophic forgetting. We outperform existing methods which do not require exemplars and obtain competitive results compared to methods which store exemplars. Furthermore, we show that our proposed SDC when combined with existing methods to prevent forgetting consistently improves results.
Variable Rate Deep Image Compression with Modulated Autoencoder
Dec 11, 2019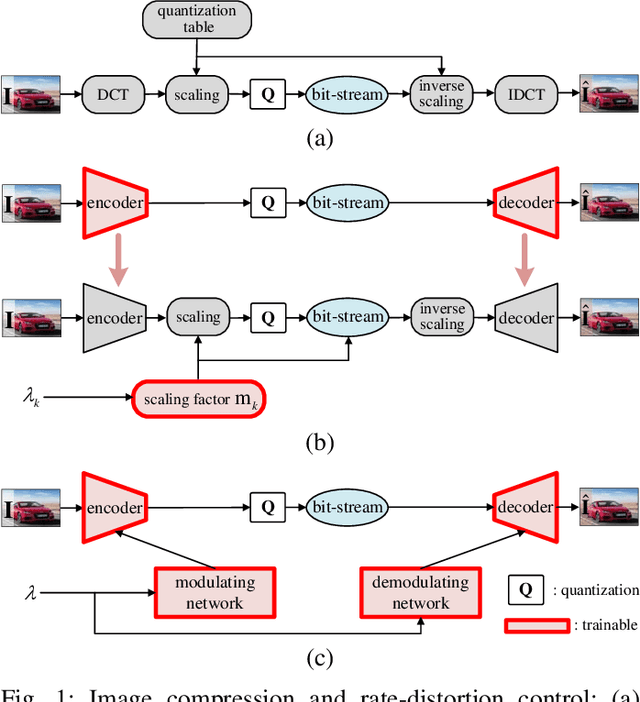
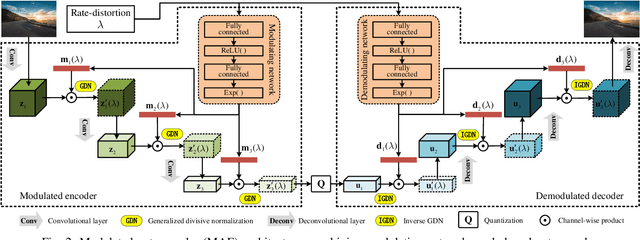
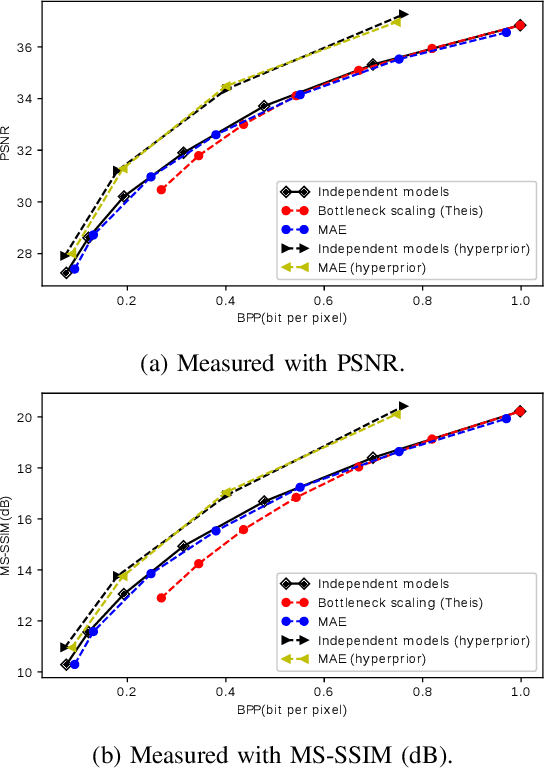
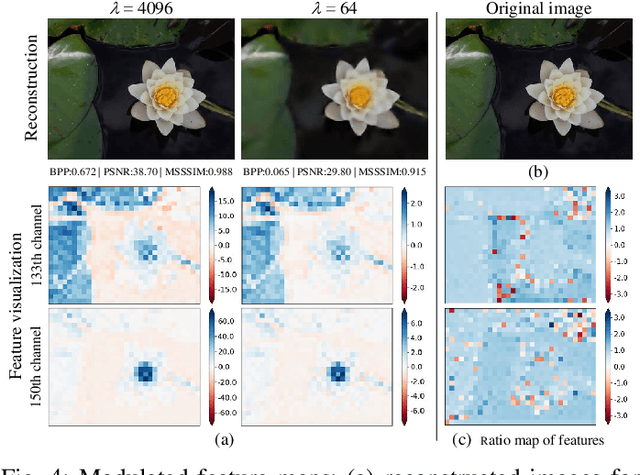
Variable rate is a requirement for flexible and adaptable image and video compression. However, deep image compression methods are optimized for a single fixed rate-distortion tradeoff. While this can be addressed by training multiple models for different tradeoffs, the memory requirements increase proportionally to the number of models. Scaling the bottleneck representation of a shared autoencoder can provide variable rate compression with a single shared autoencoder. However, the R-D performance using this simple mechanism degrades in low bitrates, and also shrinks the effective range of bit rates. Addressing these limitations, we formulate the problem of variable rate-distortion optimization for deep image compression, and propose modulated autoencoders (MAEs), where the representations of a shared autoencoder are adapted to the specific rate-distortion tradeoff via a modulation network. Jointly training this modulated autoencoder and modulation network provides an effective way to navigate the R-D operational curve. Our experiments show that the proposed method can achieve almost the same R-D performance of independent models with significantly fewer parameters.
MineGAN: effective knowledge transfer from GANs to target domains with few images
Dec 11, 2019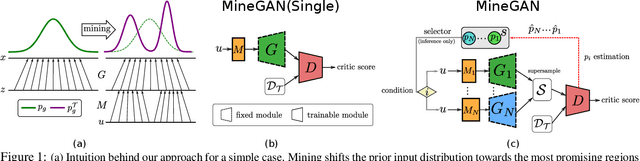
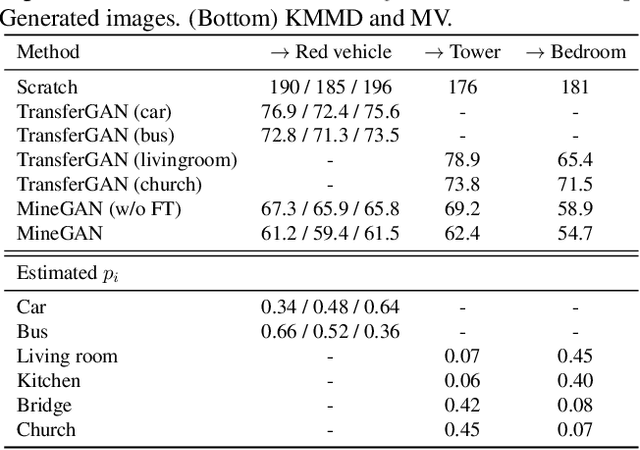
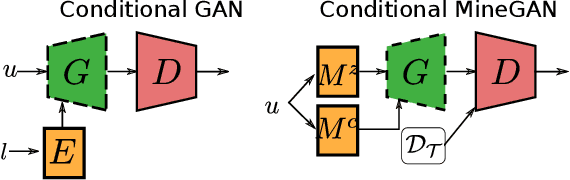
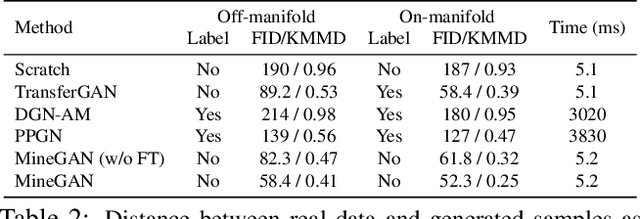
One of the attractive characteristics of deep neural networks is their ability to transfer knowledge obtained in one domain to other related domains. As a result, high-quality networks can be trained in domains with relatively little training data. This property has been extensively studied for discriminative networks but has received significantly less attention for generative models.Given the often enormous effort required to train GANs, both computationally as well as in the dataset collection, the re-use of pretrained GANs is a desirable objective. We propose a novel knowledge transfer method for generative models based on mining the knowledge that is most beneficial to a specific target domain, either from a single or multiple pretrained GANs. This is done using a miner network that identifies which part of the generative distribution of each pretrained GAN outputs samples closest to the target domain. Mining effectively steers GAN sampling towards suitable regions of the latent space, which facilitates the posterior finetuning and avoids pathologies of other methods such as mode collapse and lack of flexibility. We perform experiments on several complex datasets using various GAN architectures (BigGAN, Progressive GAN) and show that the proposed method, called MineGAN, effectively transfers knowledge to domains with few target images, outperforming existing methods. In addition, MineGAN can successfully transfer knowledge from multiple pretrained GANs.