 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Need for Visual Context in Multimodal Machine Translation
Mar 20, 2019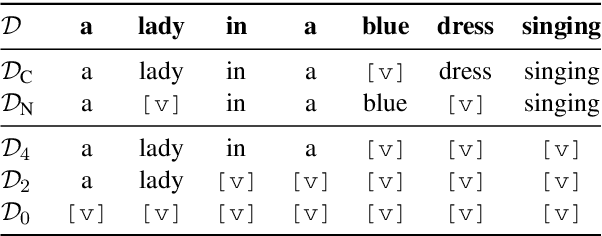
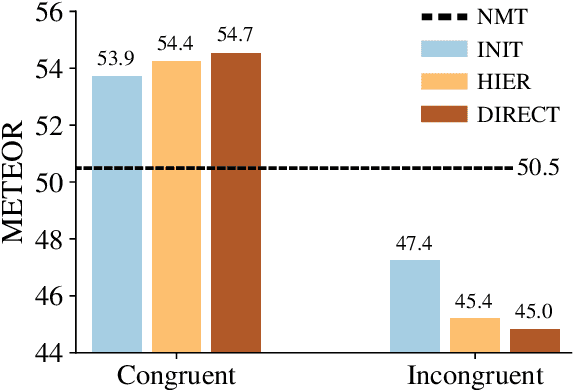


Current work on multimodal machine translation (MMT) has suggested that the visual modality is either unnecessary or only marginally beneficial. We posit that this is a consequence of the very simple, short and repetitive sentences used in the only available dataset for the task (Multi30K), rendering the source text sufficient as context. In the general case, however, we believe that it is possible to combine visual and textual information in order to ground translations. In this paper we probe the contribution of the visual modality to state-of-the-art MMT models by conducting a systematic analysis where we partially deprive the models from source-side textual context. Our results show that under limited textual context, models are capable of leveraging the visual input to generate better translations. This contradicts the current belief that MMT models disregard the visual modality because of either the quality of the image features or the way they are integrated into the model.
How2: A Large-scale Dataset for Multimodal Language Understanding
Nov 01, 2018
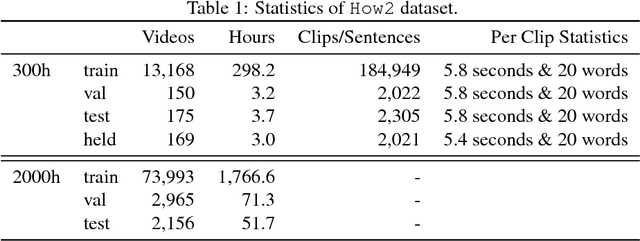
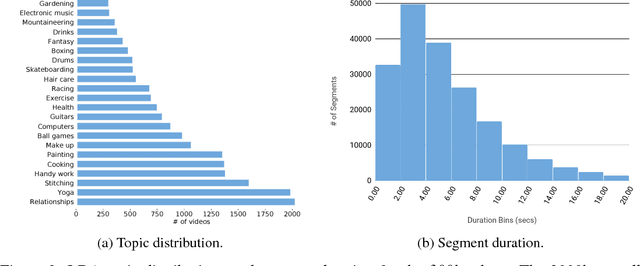

In this paper, we introduce How2, a multimodal collection of instructional videos with English subtitles and crowdsourced Portuguese translations. We also present integrated sequence-to-sequence baselines for machine translation, automatic speech recognition, spoken language translation, and multimodal summarization. By making available data and code for several multimodal natural language tasks, we hope to stimulate more research on these and similar challenges, to obtain a deeper understanding of multimodality in language processing.
Assessing Crosslingual Discourse Relations in Machine Translation
Oct 07, 2018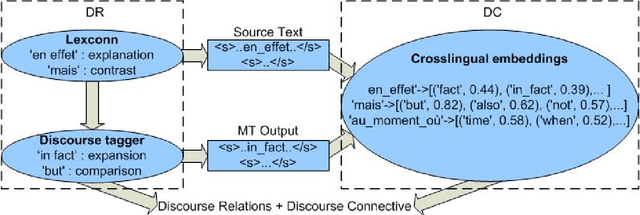
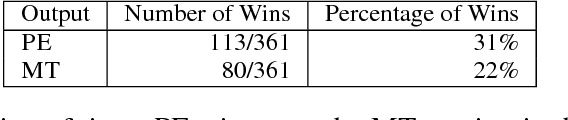
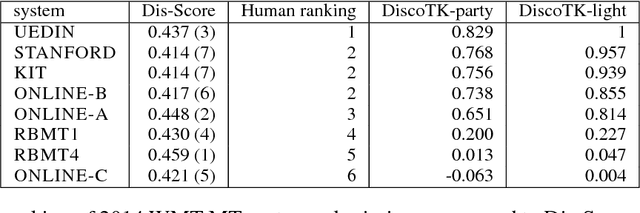
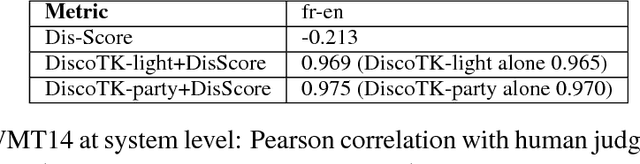
In an attempt to improve overall translation quality, there has been an increasing focus on integrating more linguistic elements into Machine Translation (MT). While significant progress has been achieved, especially recently with neural models, automatically evaluating the output of such systems is still an open problem. Current practice in MT evaluation relies on a single reference translation, even though there are many ways of translating a particular text, and it tends to disregard higher level information such as discourse. We propose a novel approach that assesses the translated output based on the source text rather than the reference translation, and measures the extent to which the semantics of the discourse elements (discourse relations, in particular) in the source text are preserved in the MT output. The challenge is to detect the discourse relations in the source text and determine whether these relations are correctly transferred crosslingually to the target language -- without a reference translation. This methodology could be used independently for discourse-level evaluation, or as a component in other metrics, at a time where substantial amounts of MT are online and would benefit from evaluation where the source text serves as a benchmark.
End-to-end Image Captioning Exploits Multimodal Distributional Similarity
Sep 11, 2018
We hypothesize that end-to-end neural image captioning systems work seemingly well because they exploit and learn `distributional similarity' in a multimodal feature space by mapping a test image to similar training images in this space and generating a caption from the same space. To validate our hypothesis, we focus on the `image' side of image captioning, and vary the input image representation but keep the RNN text generation component of a CNN-RNN model constant. Our analysis indicates that image captioning models (i) are capable of separating structure from noisy input representations; (ii) suffer virtually no significant performance loss when a high dimensional representation is compressed to a lower dimensional space; (iii) cluster images with similar visual and linguistic information together. Our findings indicate that our distributional similarity hypothesis holds. We conclude that regardless of the image representation used image captioning systems seem to match images and generate captions in a learned joint image-text semantic subspace.
Exploring Gap Filling as a Cheaper Alternative to Reading Comprehension Questionnaires when Evaluating Machine Translation for Gisting
Sep 02, 2018
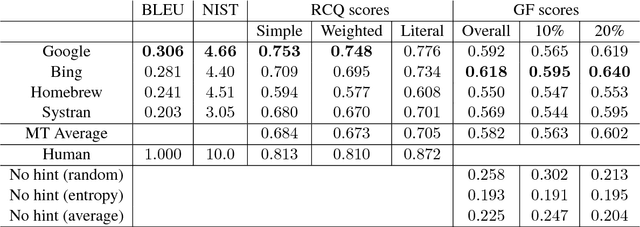

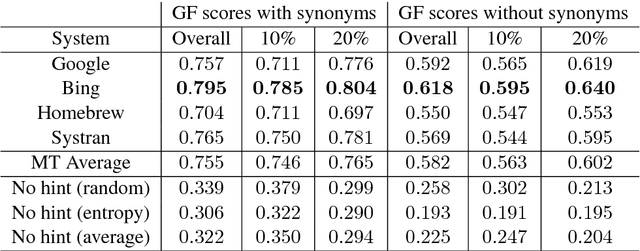
A popular application of machine translation (MT) is gisting: MT is consumed as is to make sense of text in a foreign language. Evaluation of the usefulness of MT for gisting is surprisingly uncommon. The classical method uses reading comprehension questionnaires (RCQ), in which informants are asked to answer professionally-written questions in their language about a foreign text that has been machine-translated into their language. Recently, gap-filling (GF), a form of cloze testing, has been proposed as a cheaper alternative to RCQ. In GF, certain words are removed from reference translations and readers are asked to fill the gaps left using the machine-translated text as a hint. This paper reports, for thefirst time, a comparative evaluation, using both RCQ and GF, of translations from multiple MT systems for the same foreign texts, and a systematic study on the effect of variables such as gap density, gap-selection strategies, and document context in GF. The main findings of the study are: (a) both RCQ and GF clearly identify MT to be useful, (b) global RCQ and GF rankings for the MT systems are mostly in agreement, (c) GF scores vary very widely across informants, making comparisons among MT systems hard, and (d) unlike RCQ, which is framed around documents, GF evaluation can be framed at the sentence level. These findings support the use of GF as a cheaper alternative to RCQ.
Defoiling Foiled Image Captions
May 16, 2018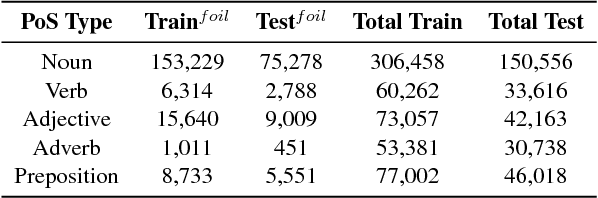

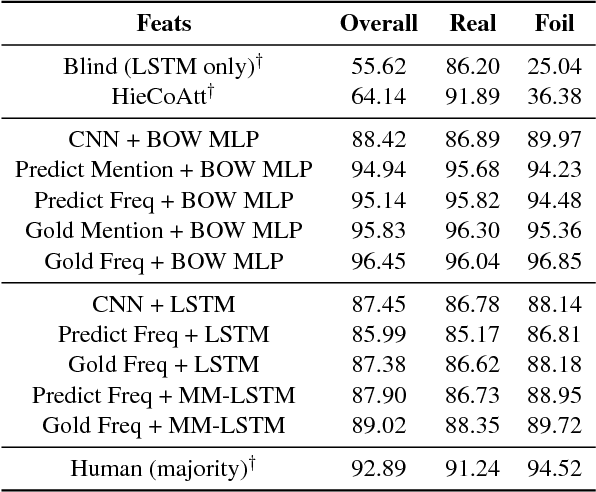
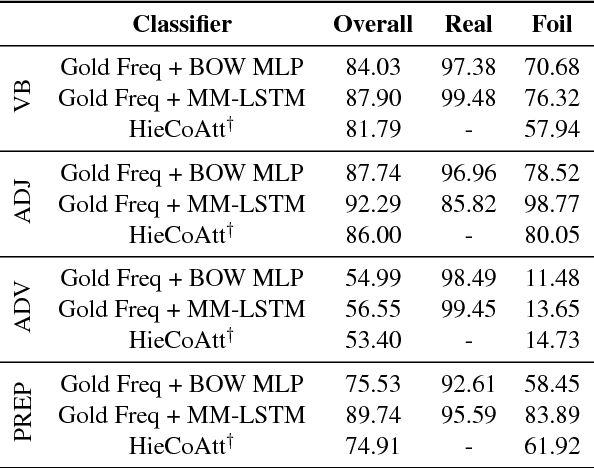
We address the task of detecting foiled image captions, i.e. identifying whether a caption contains a word that has been deliberately replaced by a semantically similar word, thus rendering it inaccurate with respect to the image being described. Solving this problem should in principle require a fine-grained understanding of images to detect linguistically valid perturbations in captions. In such contexts, encoding sufficiently descriptive image information becomes a key challenge. In this paper, we demonstrate that it is possible to solve this task using simple, interpretable yet powerful representations based on explicit object information. Our models achieve state-of-the-art performance on a standard dataset, with scores exceeding those achieved by humans on the task. We also measure the upper-bound performance of our models using gold standard annotations. Our analysis reveals that the simpler model performs well even without image information, suggesting that the dataset contains strong linguistic bias.
A Report on the Complex Word Identification Shared Task 2018
Apr 24, 2018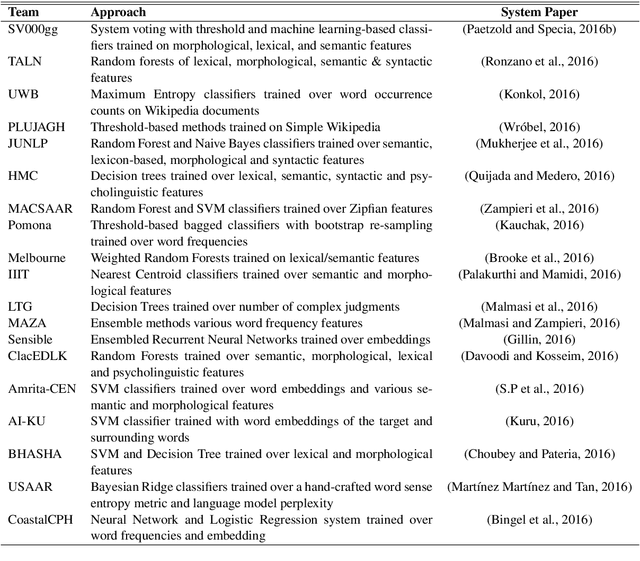
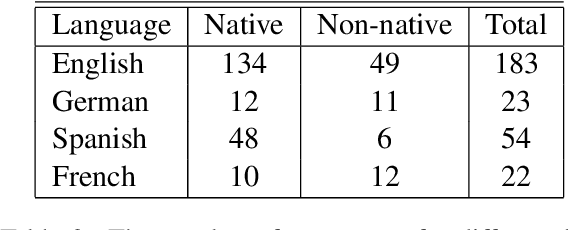
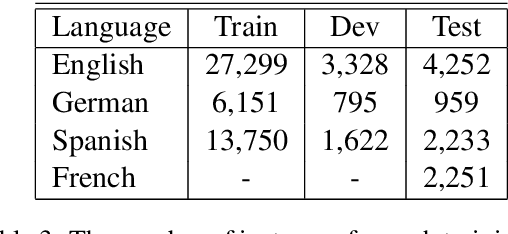
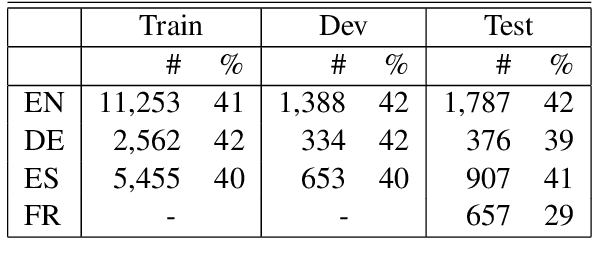
We report the findings of the second Complex Word Identification (CWI) shared task organized as part of the BEA workshop co-located with NAACL-HLT'2018. The second CWI shared task featured multilingual and multi-genre datasets divided into four tracks: English monolingual, German monolingual, Spanish monolingual, and a multilingual track with a French test set, and two tasks: binary classification and probabilistic classification. A total of 12 teams submitted their results in different task/track combinations and 11 of them wrote system description papers that are referred to in this report and appear in the BEA workshop proceedings.
Object Counts! Bringing Explicit Detections Back into Image Captioning
Apr 23, 2018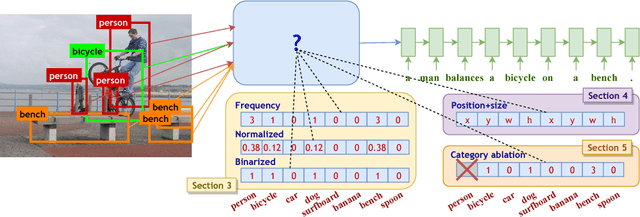
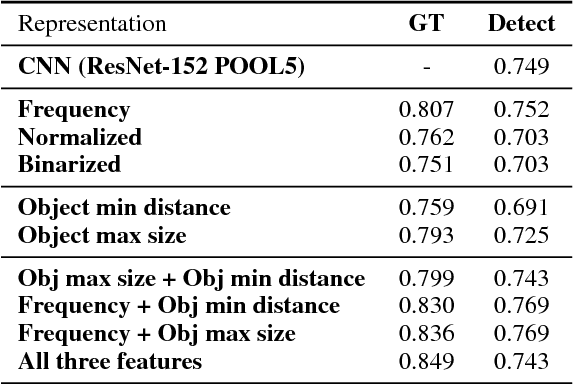


The use of explicit object detectors as an intermediate step to image captioning - which used to constitute an essential stage in early work - is often bypassed in the currently dominant end-to-end approaches, where the language model is conditioned directly on a mid-level image embedding. We argue that explicit detections provide rich semantic information, and can thus be used as an interpretable representation to better understand why end-to-end image captioning systems work well. We provide an in-depth analysis of end-to-end image captioning by exploring a variety of cues that can be derived from such object detections. Our study reveals that end-to-end image captioning systems rely on matching image representations to generate captions, and that encoding the frequency, size and position of objects are complementary and all play a role in forming a good image representation. It also reveals that different object categories contribute in different ways towards image captioning.
Findings of the Second Shared Task on Multimodal Machine Translation and Multilingual Image Description
Oct 19, 2017
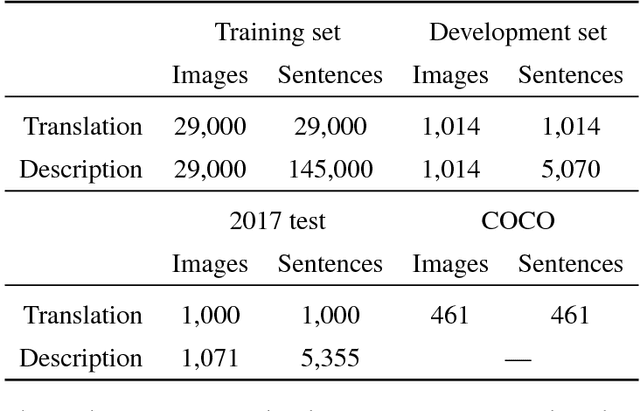
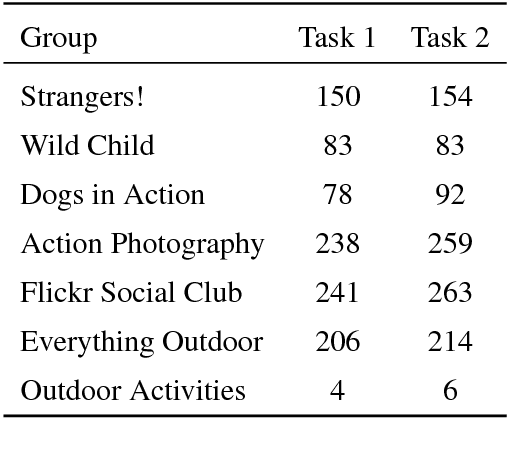

We present the results from the second shared task on multimodal machine translation and multilingual image description. Nine teams submitted 19 systems to two tasks. The multimodal translation task, in which the source sentence is supplemented by an image, was extended with a new language (French) and two new test sets. The multilingual image description task was changed such that at test time, only the image is given. Compared to last year, multimodal systems improved, but text-only systems remain competitive.
Complex Word Identification: Challenges in Data Annotation and System Performance
Oct 13, 2017
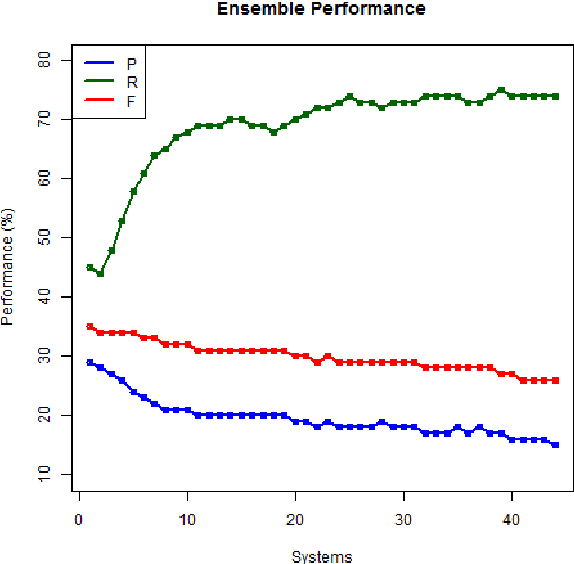
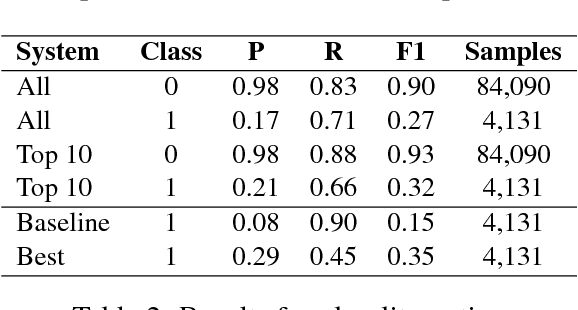
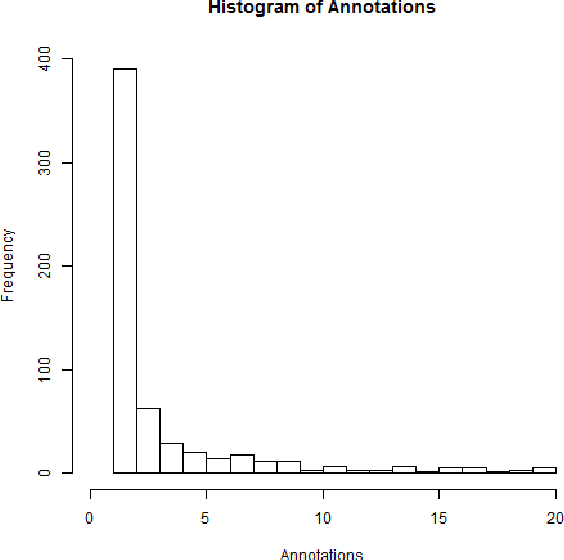
This paper revisits the problem of complex word identification (CWI) following up the SemEval CWI shared task. We use ensemble classifiers to investigate how well computational methods can discriminate between complex and non-complex words. Furthermore, we analyze the classification performance to understand what makes lexical complexity challenging. Our findings show that most systems performed poorly on the SemEval CWI dataset, and one of the reasons for that is the way in which human annotation was performed.