 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnly Time Can Tell: Discovering Temporal Data for Temporal Modeling
Jul 19, 2019
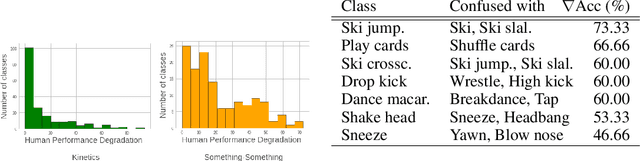


Understanding temporal information and how the visual world changes over time is a fundamental ability of intelligent systems. In video understanding, temporal information is at the core of many current challenges, including compression, efficient inference, motion estimation or summarization. However, in current video datasets it has been observed that action classes can often be recognized without any temporal information from a single frame of video. As a result, both benchmarking and training in these datasets may give an unintentional advantage to models with strong image understanding capabilities, as opposed to those with strong temporal understanding. In this paper we address this problem head on by identifying action classes where temporal information is actually necessary to recognize them and call these "temporal classes". Selecting temporal classes using a computational method would bias the process. Instead, we propose a methodology based on a simple and effective human annotation experiment. We remove just the temporal information by shuffling frames in time and measure if the action can still be recognized. Classes that cannot be recognized when frames are not in order are included in the temporal Dataset. We observe that this set is statistically different from other static classes, and that performance in it correlates with a network's ability to capture temporal information. Thus we use it as a benchmark on current popular networks, which reveals a series of interesting facts. We also explore the effect of training on the temporal dataset, and observe that this leads to better generalization in unseen classes, demonstrating the need for more temporal data. We hope that the proposed dataset of temporal categories will help guide future research in temporal modeling for better video understanding.
UniDual: A Unified Model for Image and Video Understanding
Jun 12, 2019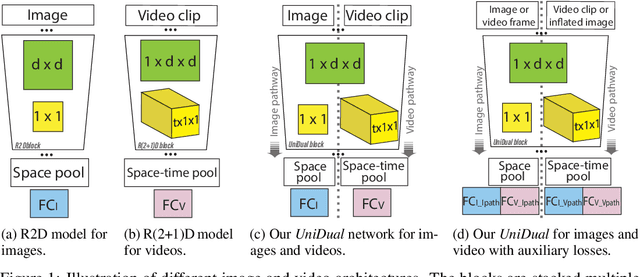
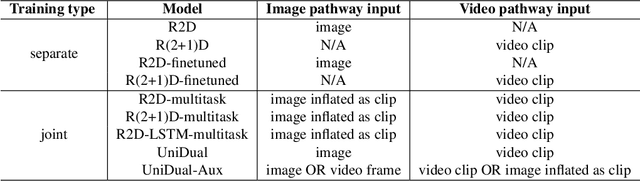
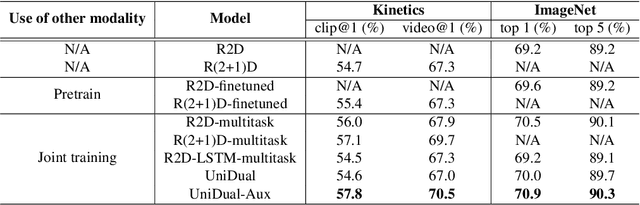
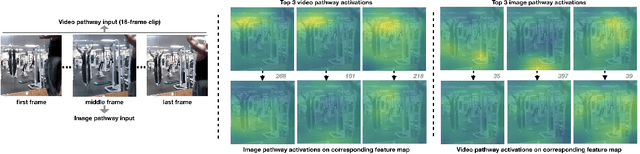
Although a video is effectively a sequence of images, visual perception systems typically model images and videos separately, thus failing to exploit the correlation and the synergy provided by these two media. While a few prior research efforts have explored the benefits of leveraging still-image datasets for video analysis, or vice-versa, most of these attempts have been limited to pretraining a model on one type of visual modality and then adapting it via finetuning on the other modality. In contrast, in this paper we introduce a framework that enables joint training of a unified model on mixed collections of image and video examples spanning different tasks. The key ingredient in our architecture design is a new network block, which we name UniDual. It consists of a shared 2D spatial convolution followed by two parallel point-wise convolutional layers, one devoted to images and the other one used for videos. For video input, the point-wise filtering implements a temporal convolution. For image input, it performs a pixel-wise nonlinear transformation. Repeated stacking of such blocks gives rise to a network where images and videos undergo partially distinct execution pathways, unified by spatial convolutions (capturing commonalities in visual appearance) but separated by point-wise operations (modeling patterns specific to each modality). Extensive experiments on Kinetics and ImageNet demonstrate that our UniDual model jointly trained on these datasets yields substantial accuracy gains for both tasks, compared to 1) training separate models, 2) traditional multi-task learning and 3) the conventional framework of pretraining-followed-by-finetuning. On Kinetics, the UniDual architecture applied to a state-of-the-art video backbone model (R(2+1)D-152) yields an additional video@1 accuracy gain of 1.5%.
Video Modeling with Correlation Networks
Jun 07, 2019
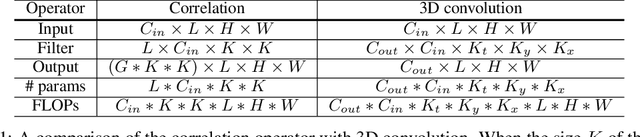
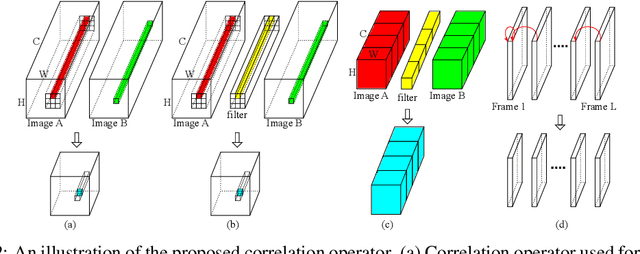
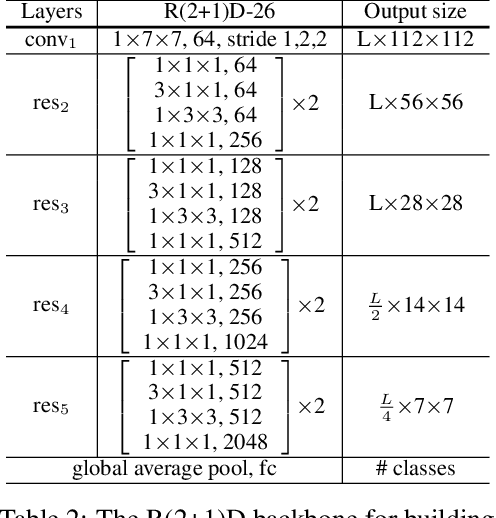
Motion is a salient cue to recognize actions in video. Modern action recognition models leverage motion information either explicitly by using optical flow as input or implicitly by means of 3D convolutional filters that simultaneously capture appearance and motion information. This paper proposes an alternative approach based on a learnable correlation operator that can be used to establish frame-to-frame matches over convolutional feature maps in the different layers of the network. The proposed architecture enables the fusion of this explicit temporal matching information with traditional appearance cues captured by 2D convolution. Our correlation network compares favorably with widely-used 3D CNNs for video modeling, and achieves competitive results over the prominent two-stream network while being much faster to train. We empirically demonstrate that correlation networks produce strong results on a variety of video datasets, and outperform the state of the art on three popular benchmarks for action recognition: Kinetics, Something-Something and Diving48.
Learning Temporal Pose Estimation from Sparsely-Labeled Videos
Jun 06, 2019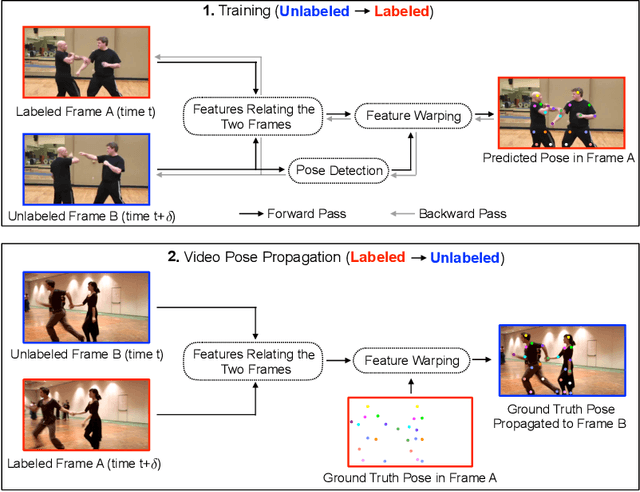

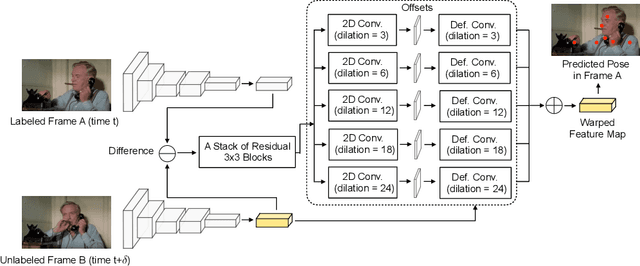
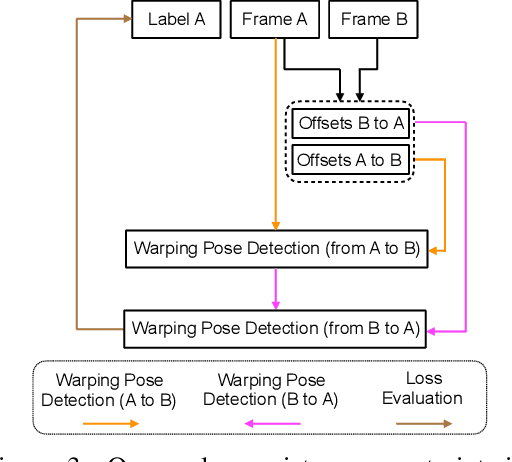
Modern approaches for multi-person pose estimation in video require large amounts of dense annotations. However, labeling every frame in a video is costly and labor intensive. To reduce the need for dense annotations, we propose a PoseWarper network that leverages training videos with sparse annotations (every k frames) to learn to perform dense temporal pose propagation and estimation. Given a pair of video frames---a labeled Frame A and an unlabeled Frame B---we train our model to predict human pose in Frame A using the features from Frame B by means of deformable convolutions to implicitly learn the pose warping between A and B. We demonstrate that we can leverage our trained PoseWarper for several applications. First, at inference time we can reverse the application direction of our network in order to propagate pose information from manually annotated frames to unlabeled frames. This makes it possible to generate pose annotations for the entire video given only a few manually-labeled frames. Compared to modern label propagation methods based on optical flow, our warping mechanism is much more compact (6M vs 39M parameters), and also more accurate (88.7% mAP vs 83.8% mAP). We also show that we can improve the accuracy of a pose estimator by training it on an augmented dataset obtained by adding our propagated poses to the original manual labels. Lastly, we can use our PoseWarper to aggregate temporal pose information from neighboring frames during inference. This allows our system to achieve state-of-the-art pose detection results on the PoseTrack2017 dataset.
Attentive Action and Context Factorization
Apr 10, 2019
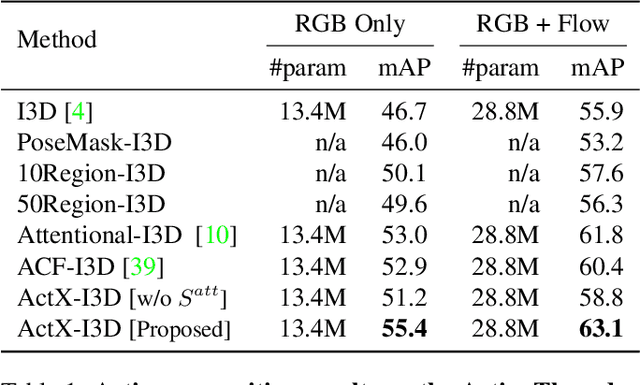
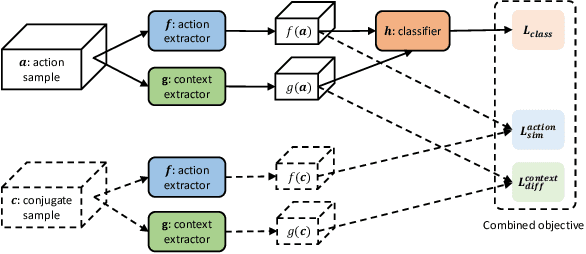
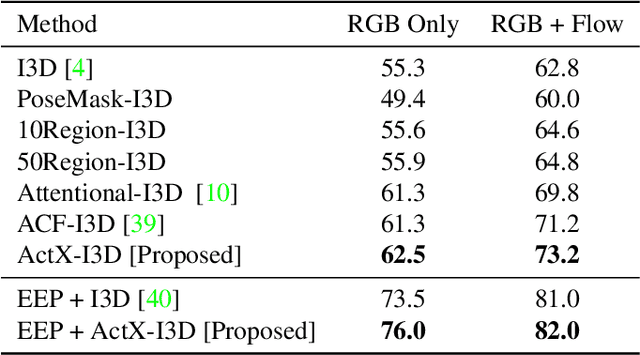
We propose a method for human action recognition, one that can localize the spatiotemporal regions that `define' the actions. This is a challenging task due to the subtlety of human actions in video and the co-occurrence of contextual elements. To address this challenge, we utilize conjugate samples of human actions, which are video clips that are contextually similar to human action samples but do not contain the action. We introduce a novel attentional mechanism that can spatially and temporally separate human actions from the co-occurring contextual factors. The separation of the action and context factors is weakly supervised, eliminating the need for laboriously detailed annotation of these two factors in training samples. Our method can be used to build human action classifiers with higher accuracy and better interpretability. Experiments on several human action recognition datasets demonstrate the quantitative and qualitative benefits of our approach.
SCSampler: Sampling Salient Clips from Video for Efficient Action Recognition
Apr 08, 2019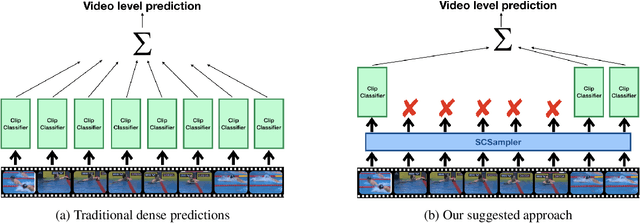


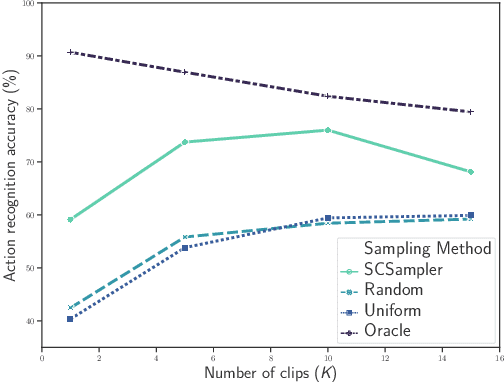
While many action recognition datasets consist of collections of brief, trimmed videos each containing a relevant action, videos in the real-world (e.g., on YouTube) exhibit very different properties: they are often several minutes long, where brief relevant clips are often interleaved with segments of extended duration containing little change. Applying densely an action recognition system to every temporal clip within such videos is prohibitively expensive. Furthermore, as we show in our experiments, this results in suboptimal recognition accuracy as informative predictions from relevant clips are outnumbered by meaningless classification outputs over long uninformative sections of the video. In this paper we introduce a lightweight `clip-sampling' model that can efficiently identify the most salient temporal clips within a long video. We demonstrate that the computational cost of action recognition on untrimmed videos can be dramatically reduced by invoking recognition only on these most salient clips. Furthermore, we show that this yields significant gains in recognition accuracy compared to analysis of all clips or randomly/uniformly selected clips. On Sports1M, our clip sampling scheme elevates the accuracy of an already state-of-the-art action classifier by 7% and reduces by more than 15 times its computational cost.
Video Classification with Channel-Separated Convolutional Networks
Apr 04, 2019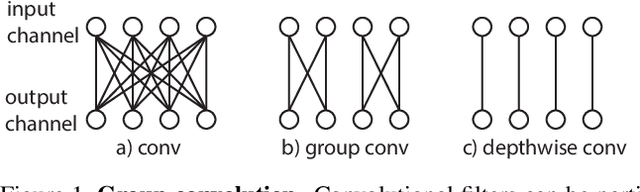
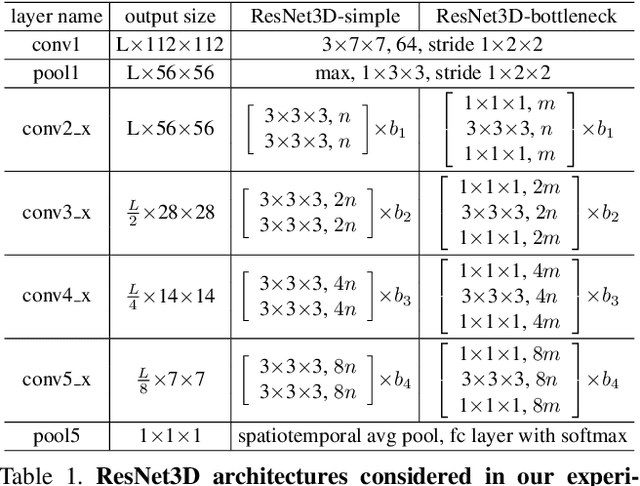
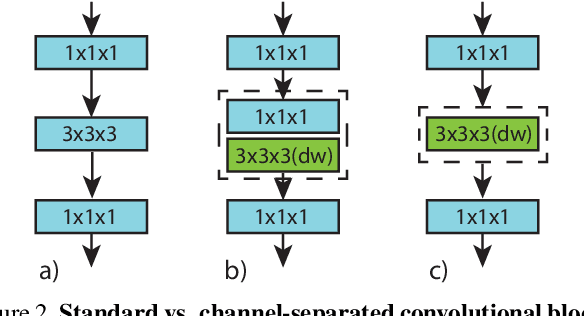
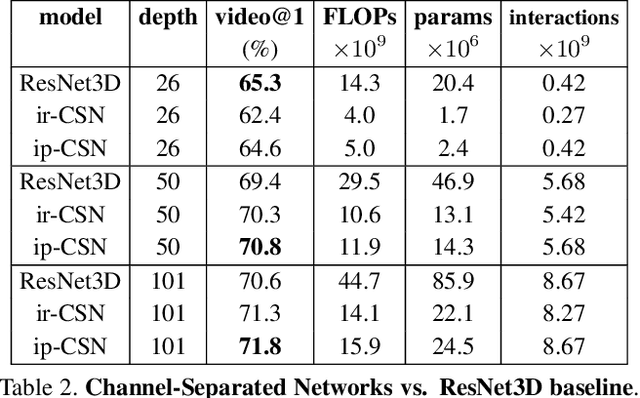
Group convolution has been shown to offer great computational savings in various 2D convolutional architectures for image classification. It is natural to ask: 1) if group convolution can help to alleviate the high computational cost of video classification networks; 2) what factors matter the most in 3D group convolutional networks; and 3) what are good computation/accuracy trade-offs with 3D group convolutional networks. This paper studies different effects of group convolution in 3D convolutional networks for video classification. We empirically demonstrate that the amount of channel interactions plays an important role in the accuracy of group convolutional networks. Our experiments suggest two main findings. First, it is a good practice to factorize 3D convolutions by separating channel interactions and spatiotemporal interactions as this leads to improved accuracy and lower computational cost. Second, 3D channel-separated convolutions provide a form of regularization, yielding lower training accuracy but higher test accuracy compared to 3D convolutions. These two empirical findings lead us to design an architecture -- Channel-Separated Convolutional Network (CSN) -- which is simple, efficient, yet accurate. On Kinetics and Sports1M, our CSNs significantly outperform state-of-the-art models while being 11-times more efficient.
DistInit: Learning Video Representations without a Single Labeled Video
Jan 26, 2019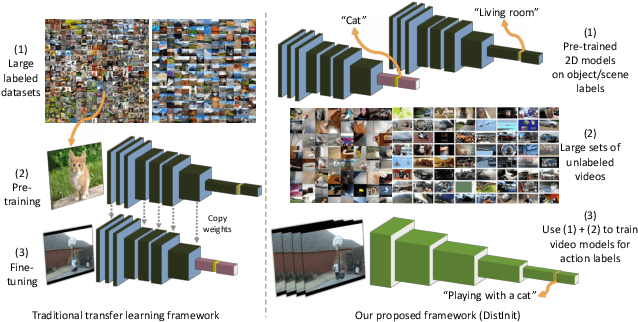
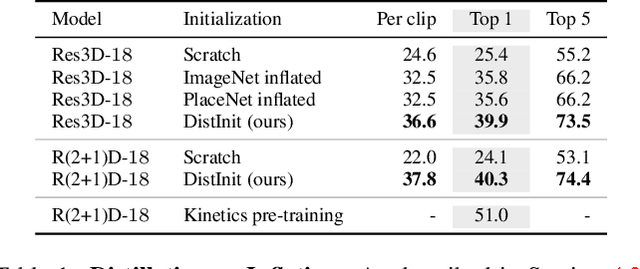
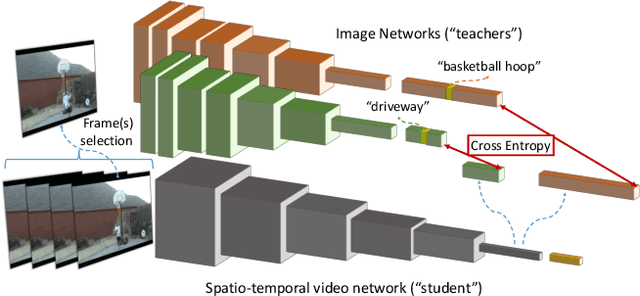

Video recognition models have progressed significantly over the past few years, evolving from shallow classifiers trained on hand-crafted features to deep spatiotemporal networks. However, labeled video data required to train such models has not been able to keep up with the ever increasing depth and sophistication of these networks. In this work we propose an alternative approach to learning video representations that requires no semantically labeled videos, and instead leverages the years of effort in collecting and labeling large and clean still-image datasets. We do so by using state-of-the-art models pre-trained on image datasets as "teachers" to train video models in a distillation framework. We demonstrate that our method learns truly spatiotemporal features, despite being trained only using supervision from still-image networks. Moreover, it learns good representations across different input modalities, using completely uncurated raw video data sources and with different 2D teacher models. Our method obtains strong transfer performance, outperforming standard techniques for bootstrapping video architectures from image-based models and obtains competitive performance with state-of-the-art approaches for video action recognition.
Learning Discriminative Motion Features Through Detection
Dec 11, 2018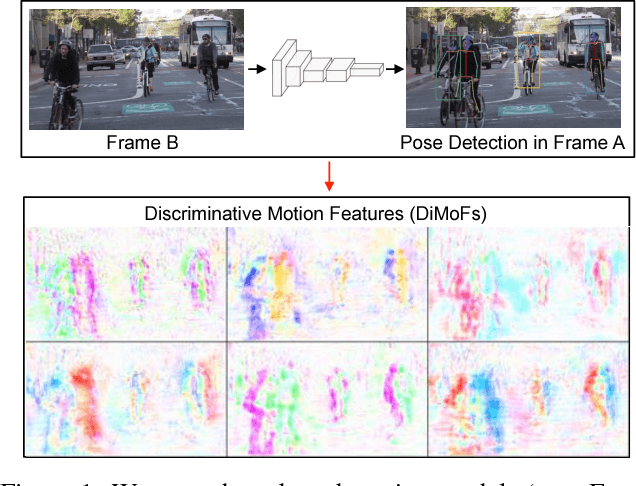

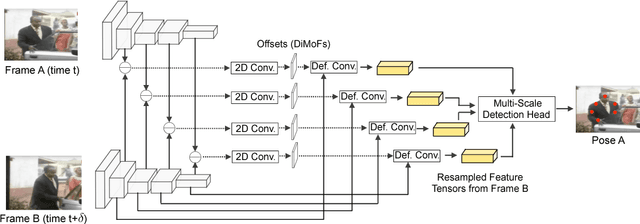

Despite huge success in the image domain, modern detection models such as Faster R-CNN have not been used nearly as much for video analysis. This is arguably due to the fact that detection models are designed to operate on single frames and as a result do not have a mechanism for learning motion representations directly from video. We propose a learning procedure that allows detection models such as Faster R-CNN to learn motion features directly from the RGB video data while being optimized with respect to a pose estimation task. Given a pair of video frames---Frame A and Frame B---we force our model to predict human pose in Frame A using the features from Frame B. We do so by leveraging deformable convolutions across space and time. Our network learns to spatially sample features from Frame B in order to maximize pose detection accuracy in Frame A. This naturally encourages our network to learn motion offsets encoding the spatial correspondences between the two frames. We refer to these motion offsets as DiMoFs (Discriminative Motion Features). In our experiments we show that our training scheme helps learn effective motion cues, which can be used to estimate and localize salient human motion. Furthermore, we demonstrate that as a byproduct, our model also learns features that lead to improved pose detection in still-images, and better keypoint tracking. Finally, we show how to leverage our learned model for the tasks of spatiotemporal action localization and fine-grained action recognition.
BranchConnect: Large-Scale Visual Recognition with Learned Branch Connections
Jul 29, 2018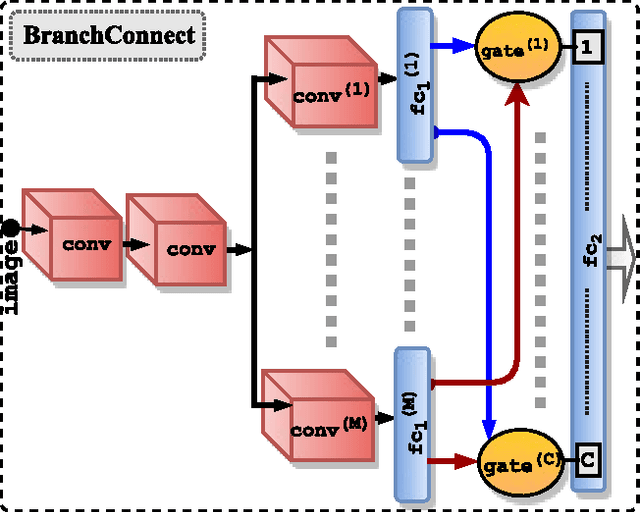
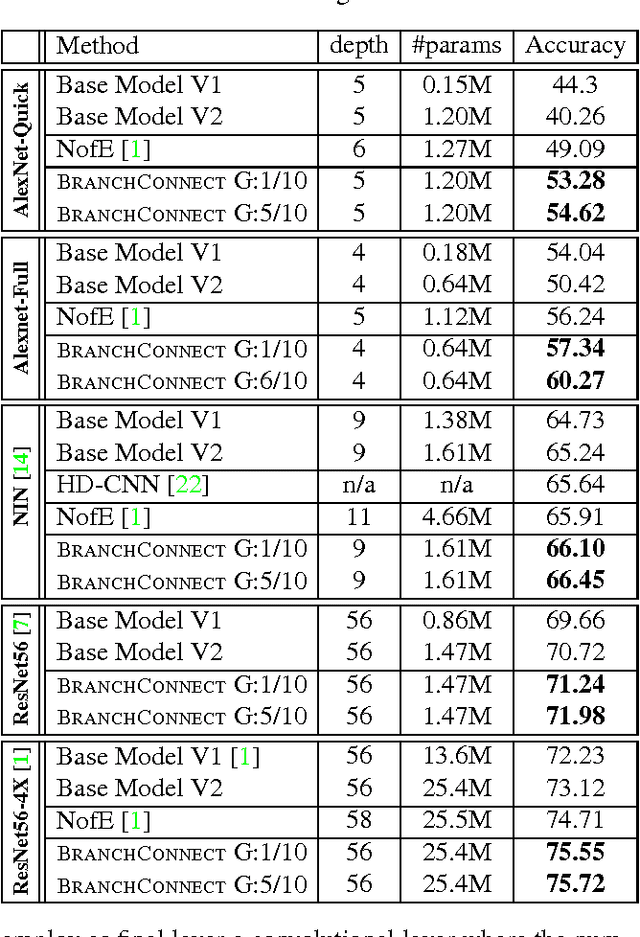
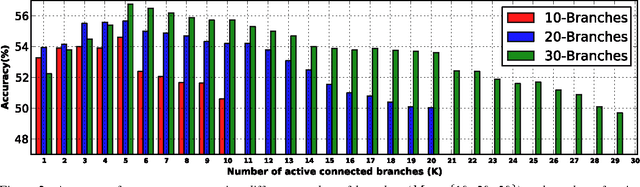
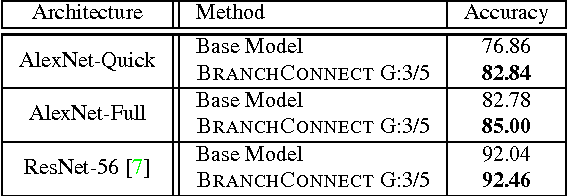
We introduce an architecture for large-scale image categorization that enables the end-to-end learning of separate visual features for the different classes to distinguish. The proposed model consists of a deep CNN shaped like a tree. The stem of the tree includes a sequence of convolutional layers common to all classes. The stem then splits into multiple branches implementing parallel feature extractors, which are ultimately connected to the final classification layer via learned gated connections. These learned gates determine for each individual class the subset of features to use. Such a scheme naturally encourages the learning of a heterogeneous set of specialized features through the separate branches and it allows each class to use the subset of features that are optimal for its recognition. We show the generality of our proposed method by reshaping several popular CNNs from the literature into our proposed architecture. Our experiments on the CIFAR100, CIFAR10, and Synth datasets show that in each case our resulting model yields a substantial improvement in accuracy over the original CNN. Our empirical analysis also suggests that our scheme acts as a form of beneficial regularization improving generalization performance.
* WACV 2018