 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProMUSE: Progressive Multi-modal Uncertainty-guided Staged Evidential Alzheimer Disease Classification
Jun 11, 2026Alzheimer's disease (AD) is a fatal disorder that destroys memory and cognitive skills in the elderly population. Most treatments for AD are effective in the early stage, leading to an increasing demand for early AD diagnosis. AD diagnosis increasingly relies on multimodal data such as clinical assessments, structural Magnetic Resonance Imaging (MRI), and Positron Emission Tomography (PET) imaging. However, MRI and PET acquisition remain costly and not universally accessible, making full-modality inference impractical in real-world clinical workflows. We propose ProMUSE, a Progressive Multi-modal Uncertainty Guided Staged Evidential Network that adaptively determines when additional modalities are necessary, helping reduce the overall cost of data acquisition while maintaining accuracy. ProMUSE first performs evidential classification using low-cost clinical data and quantifies uncertainty via a Dirichlet-based subjective logic model. When uncertainty exceeds a learned threshold, ProMUSE progressively incorporates MRI or PET features, fusing modality-wise belief and uncertainty through Dempster-Shafer theory to obtain a calibrated multimodal prediction. This staged acquisition strategy enables accurate diagnosis while minimizing reliance on expensive imaging. Experiments on ADNI, AIBL, and OASIS across CN-AD, CN-MCI, and MCI-AD tasks demonstrate that ProMUSE achieves competitive or superior accuracy compared to full-modality baselines while reducing MRI/PET usage by 50-90%, yielding substantial cost savings. These results highlight ProMUSE as a practical, uncertainty-aware, and resource-efficient solution for real-world AD screening.
HSEvo: Elevating Automatic Heuristic Design with Diversity-Driven Harmony Search and Genetic Algorithm Using LLMs
Dec 19, 2024



Automatic Heuristic Design (AHD) is an active research area due to its utility in solving complex search and NP-hard combinatorial optimization problems in the real world. The recent advancements in Large Language Models (LLMs) introduce new possibilities by coupling LLMs with evolutionary computation to automatically generate heuristics, known as LLM-based Evolutionary Program Search (LLM-EPS). While previous LLM-EPS studies obtained great performance on various tasks, there is still a gap in understanding the properties of heuristic search spaces and achieving a balance between exploration and exploitation, which is a critical factor in large heuristic search spaces. In this study, we address this gap by proposing two diversity measurement metrics and perform an analysis on previous LLM-EPS approaches, including FunSearch, EoH, and ReEvo. Results on black-box AHD problems reveal that while EoH demonstrates higher diversity than FunSearch and ReEvo, its objective score is unstable. Conversely, ReEvo's reflection mechanism yields good objective scores but fails to optimize diversity effectively. With this finding in mind, we introduce HSEvo, an adaptive LLM-EPS framework that maintains a balance between diversity and convergence with a harmony search algorithm. Through experimentation, we find that HSEvo achieved high diversity indices and good objective scores while remaining cost-effective. These results underscore the importance of balancing exploration and exploitation and understanding heuristic search spaces in designing frameworks in LLM-EPS.
A High-Quality and Large-Scale Dataset for English-Vietnamese Speech Translation
Aug 08, 2022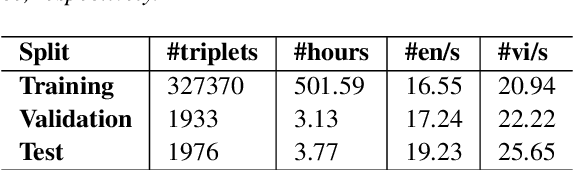


In this paper, we introduce a high-quality and large-scale benchmark dataset for English-Vietnamese speech translation with 508 audio hours, consisting of 331K triplets of (sentence-lengthed audio, English source transcript sentence, Vietnamese target subtitle sentence). We also conduct empirical experiments using strong baselines and find that the traditional "Cascaded" approach still outperforms the modern "End-to-End" approach. To the best of our knowledge, this is the first large-scale English-Vietnamese speech translation study. We hope both our publicly available dataset and study can serve as a starting point for future research and applications on English-Vietnamese speech translation. Our dataset is available at https://github.com/VinAIResearch/PhoST
PhoMT: A High-Quality and Large-Scale Benchmark Dataset for Vietnamese-English Machine Translation
Oct 23, 2021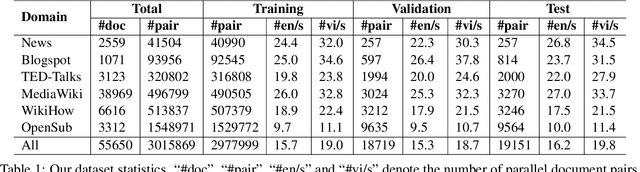
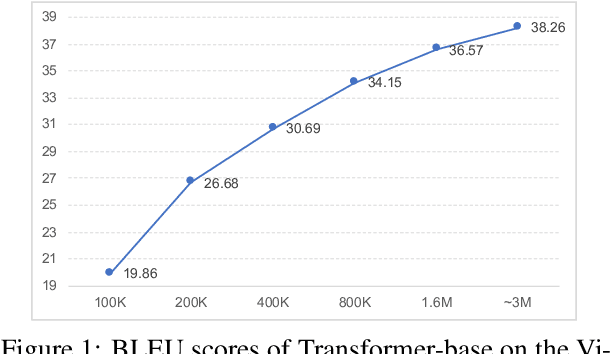
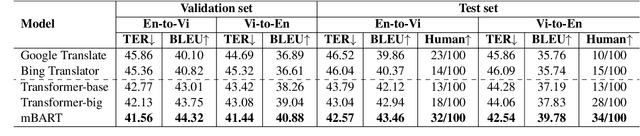
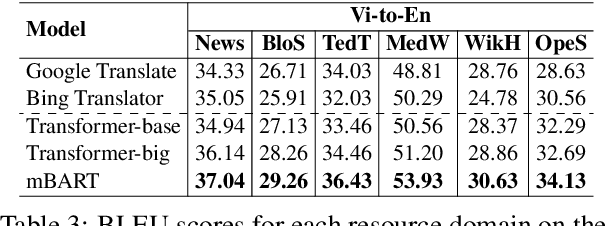
We introduce a high-quality and large-scale Vietnamese-English parallel dataset of 3.02M sentence pairs, which is 2.9M pairs larger than the benchmark Vietnamese-English machine translation corpus IWSLT15. We conduct experiments comparing strong neural baselines and well-known automatic translation engines on our dataset and find that in both automatic and human evaluations: the best performance is obtained by fine-tuning the pre-trained sequence-to-sequence denoising auto-encoder mBART. To our best knowledge, this is the first large-scale Vietnamese-English machine translation study. We hope our publicly available dataset and study can serve as a starting point for future research and applications on Vietnamese-English machine translation.
WNUT-2020 Task 2: Identification of Informative COVID-19 English Tweets
Oct 16, 2020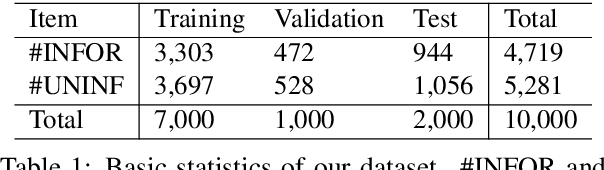
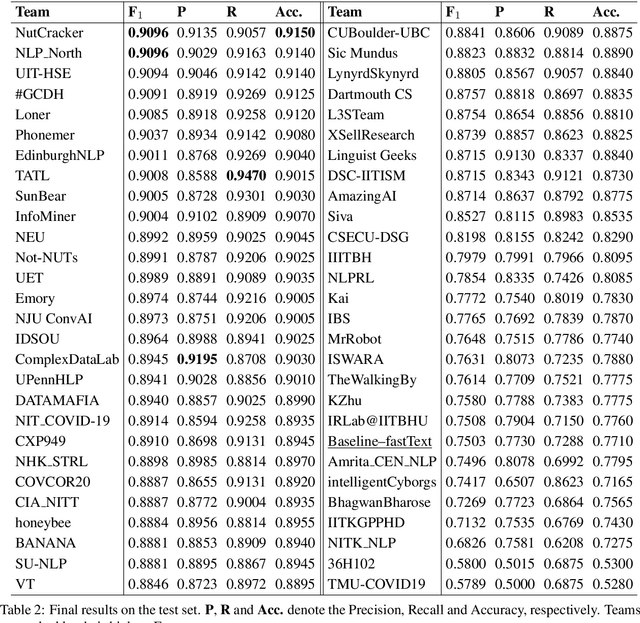
In this paper, we provide an overview of the WNUT-2020 shared task on the identification of informative COVID-19 English Tweets. We describe how we construct a corpus of 10K Tweets and organize the development and evaluation phases for this task. In addition, we also present a brief summary of results obtained from the final system evaluation submissions of 55 teams, finding that (i) many systems obtain very high performance, up to 0.91 F1 score, (ii) the majority of the submissions achieve substantially higher results than the baseline fastText (Joulin et al., 2017), and (iii) fine-tuning pre-trained language models on relevant language data followed by supervised training performs well in this task.