 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARIA: Adaptive Region-Based Importance Allocation for Conditional Diffusion Distillation
Jun 22, 2026Distilling conditional diffusion models aims to transfer the behavior of a large teacher to a smaller student while preserving alignment across conditioning inputs. Unlike recognition tasks, knowledge distillation in conditional diffusion often struggles to transfer knowledge beyond the training distribution, since the predicted noise strongly depends on the conditioning signal. As a result, effective distillation requires exploring a large conditioning space. In practical settings, this creates a major bottleneck. Paired image-condition data may be limited, and generating synthetic images for every available condition is often computationally infeasible, while the pool of conditions, such as text prompts, can be extremely large. Recent work addresses this issue by switching conditions during training, exposing the student to a broader conditioning space without changing the distillation objective. Yet this raises a complementary question: once a large conditioning corpus is available, how should the training effort be allocated? In this work, we introduce ARIA, a framework that adaptively allocates training effort across coarse regions of the conditioning space. By maintaining online estimates of teacher-student discrepancy at the region level, ARIA focuses updates where misalignment persists while preserving the original distillation objective. Empirically, ARIA improves over RC across most architectures and settings, with the clearest gains observed in unseen and underrepresented regimes. We also provide a theoretical analysis showing that the proposed tracking mechanism follows the evolving discrepancy during training under bounded variance and drift assumptions.
Supportive Token Revealing for Fast Diffusion Language Model Decoding
Jun 02, 2026Discrete diffusion language models can generate text efficiently by updating multiple masked positions in parallel, but this parallelism introduces a quality-latency trade-off. Aggressive decoding may commit mutually dependent tokens too early, while conservative decoding requires many denoising steps. Existing methods address this tension by deciding which tokens are safe to reveal using confidence or dependency criteria. However, avoiding unsafe commits does not necessarily make the remaining masked sequence easy to decode, since uncertain tokens may depend on masked tokens, creating a bottleneck for denoising steps. We propose AXON, a training-free module that can be added on top of existing parallel decoding strategies for diffusion language models. Rather than replacing the base decoder, AXON monitors the remaining uncertain masked tokens and intervenes only when their current state suggests that additional context is needed. It then shifts the criterion from which tokens are safest to reveal to which confident reveals would best support later denoising. AXON selects anchors, confident masked tokens that uncertain positions attend to, using attention, uncertainty, and confidence signals. Experiments on reasoning and code-generation benchmarks across multiple diffusion language models show that AXON improves the quality-latency trade-off of existing parallel decoders, often reducing the number of function evaluations while maintaining or improving accuracy.
SpurAudio: A Benchmark for Studying Shortcut Learning in Few-Shot Audio Classification
May 13, 2026Few-shot classification (FSC) is widely used for learning from limited labeled data, yet most evaluations implicitly assume that target concepts are independent of contextual cues. In real-world settings, however, examples often appear within rich contexts, allowing models to exploit spurious correlations between foreground content and background signals. While such effects have been studied in few-shot image classification, their role in few-shot audio classification remains largely unexplored, and existing audio benchmarks offer limited control over contextual structure. We introduce SpurAudio, a benchmark that leverages the natural separability of foreground events and background environments in audio to enable controlled, multi-level evaluation of contextual shifts across support and query sets. Using this benchmark, we show that many state-of-the-art few-shot methods suffer severe performance degradation when background correlations are disrupted, despite achieving similar accuracy under standard evaluation protocols. Crucially, this vulnerability persists even in large pretrained audio foundation models, ruling out limited backbone capacity as an explanation. Moreover, methods that appear comparable under conventional benchmarks can exhibit markedly different sensitivity to spurious correlations, revealing systematic algorithmic strengths and vulnerabilities tied to how feature representations interact with classifier heads at inference time. These findings provide new insight into the behavior of few-shot methods in audio and highlight the need for benchmarks that explicitly probe context dependence when evaluating FSC models.
SymDrift: One-Shot Generative Modeling under Symmetries
May 07, 2026Generative modeling of physical systems, such as molecules, requires learning distributions that are invariant under global symmetries, such as rotations in three-dimensional space. Equivariant diffusion and flow matching models can incorporate such invariances effectively, even when trained on a non-invariant empirical distribution, but they typically rely on costly multi-step sampling. Recently, drifting models have emerged as an efficient alternative, enabling single-step generation and achieving state-of-the-art performance in generative modeling tasks. However, we show that drifting models face a symmetry-specific challenge, since an equivariant generator does not generally produce the same drifting field as the one obtained from the symmetrized target distribution. Addressing this issue would require expensive symmetrization of the empirical distribution. To avoid this cost, we propose SymDrift, a framework that makes the drifting field itself symmetry-aware. We introduce two complementary strategies: (i) a symmetrized drift in coordinate space based on optimal alignment, and (ii) a $G$-invariant embedding that removes symmetry ambiguity by construction. Empirically, SymDrift outperforms existing one-shot methods on standard benchmarks for conformer and transition state generation, while remaining competitive with significantly more expensive multi-step approaches. By enabling one-shot inference, SymDrift reduces computational overhead by up to 40$\times$ compared to existing baselines, making it promising for high-throughput applications such as virtual drug screening and large-scale reaction network exploration.
Improving Model Classification by Optimizing the Training Dataset
Jul 22, 2025



In the era of data-centric AI, the ability to curate high-quality training data is as crucial as model design. Coresets offer a principled approach to data reduction, enabling efficient learning on large datasets through importance sampling. However, conventional sensitivity-based coreset construction often falls short in optimizing for classification performance metrics, e.g., $F1$ score, focusing instead on loss approximation. In this work, we present a systematic framework for tuning the coreset generation process to enhance downstream classification quality. Our method introduces new tunable parameters--including deterministic sampling, class-wise allocation, and refinement via active sampling, beyond traditional sensitivity scores. Through extensive experiments on diverse datasets and classifiers, we demonstrate that tuned coresets can significantly outperform both vanilla coresets and full dataset training on key classification metrics, offering an effective path towards better and more efficient model training.
Practical $0.385$-Approximation for Submodular Maximization Subject to a Cardinality Constraint
May 22, 2024



Non-monotone constrained submodular maximization plays a crucial role in various machine learning applications. However, existing algorithms often struggle with a trade-off between approximation guarantees and practical efficiency. The current state-of-the-art is a recent $0.401$-approximation algorithm, but its computational complexity makes it highly impractical. The best practical algorithms for the problem only guarantee $1/e$-approximation. In this work, we present a novel algorithm for submodular maximization subject to a cardinality constraint that combines a guarantee of $0.385$-approximation with a low and practical query complexity of $O(n+k^2)$. Furthermore, we evaluate the empirical performance of our algorithm in experiments based on various machine learning applications, including Movie Recommendation, Image Summarization, and more. These experiments demonstrate the efficacy of our approach.
Bridging the Gap Between General and Down-Closed Convex Sets in Submodular Maximization
Jan 17, 2024
Optimization of DR-submodular functions has experienced a notable surge in significance in recent times, marking a pivotal development within the domain of non-convex optimization. Motivated by real-world scenarios, some recent works have delved into the maximization of non-monotone DR-submodular functions over general (not necessarily down-closed) convex set constraints. Up to this point, these works have all used the minimum $\ell_\infty$ norm of any feasible solution as a parameter. Unfortunately, a recent hardness result due to Mualem \& Feldman~\cite{mualem2023resolving} shows that this approach cannot yield a smooth interpolation between down-closed and non-down-closed constraints. In this work, we suggest novel offline and online algorithms that provably provide such an interpolation based on a natural decomposition of the convex body constraint into two distinct convex bodies: a down-closed convex body and a general convex body. We also empirically demonstrate the superiority of our proposed algorithms across three offline and two online applications.
ORBSLAM3-Enhanced Autonomous Toy Drones: Pioneering Indoor Exploration
Dec 20, 2023Navigating toy drones through uncharted GPS-denied indoor spaces poses significant difficulties due to their reliance on GPS for location determination. In such circumstances, the necessity for achieving proper navigation is a primary concern. In response to this formidable challenge, we introduce a real-time autonomous indoor exploration system tailored for drones equipped with a monocular \emph{RGB} camera. Our system utilizes \emph{ORB-SLAM3}, a state-of-the-art vision feature-based SLAM, to handle both the localization of toy drones and the mapping of unmapped indoor terrains. Aside from the practicability of \emph{ORB-SLAM3}, the generated maps are represented as sparse point clouds, making them prone to the presence of outlier data. To address this challenge, we propose an outlier removal algorithm with provable guarantees. Furthermore, our system incorporates a novel exit detection algorithm, ensuring continuous exploration by the toy drone throughout the unfamiliar indoor environment. We also transform the sparse point to ensure proper path planning using existing path planners. To validate the efficacy and efficiency of our proposed system, we conducted offline and real-time experiments on the autonomous exploration of indoor spaces. The results from these endeavors demonstrate the effectiveness of our methods.
Submodular Minimax Optimization: Finding Effective Sets
May 26, 2023



Despite the rich existing literature about minimax optimization in continuous settings, only very partial results of this kind have been obtained for combinatorial settings. In this paper, we fill this gap by providing a characterization of submodular minimax optimization, the problem of finding a set (for either the min or the max player) that is effective against every possible response. We show when and under what conditions we can find such sets. We also demonstrate how minimax submodular optimization provides robust solutions for downstream machine learning applications such as (i) efficient prompt engineering for question answering, (ii) prompt engineering for dialog state tracking, (iii) identifying robust waiting locations for ride-sharing, (iv) ride-share difficulty kernelization, and (v) finding adversarial images. Our experiments demonstrate that our proposed algorithms consistently outperform other baselines.
Resolving the Approximability of Offline and Online Non-monotone DR-Submodular Maximization over General Convex Sets
Oct 12, 2022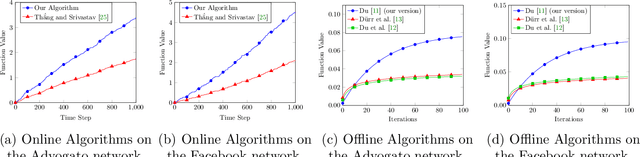
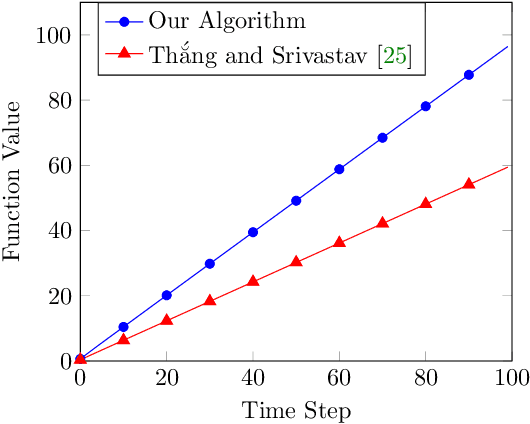
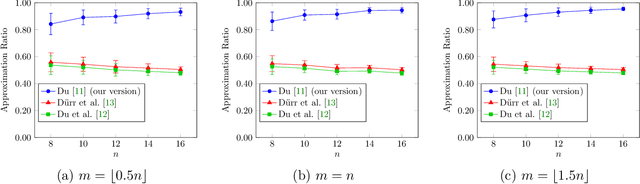
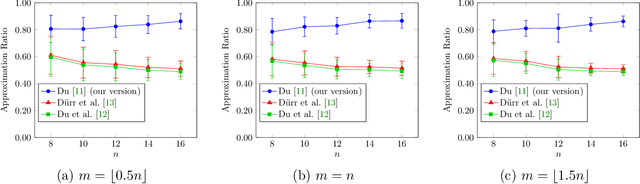
In recent years, maximization of DR-submodular continuous functions became an important research field, with many real-worlds applications in the domains of machine learning, communication systems, operation research and economics. Most of the works in this field study maximization subject to down-closed convex set constraints due to an inapproximability result by Vondr\'ak (2013). However, Durr et al. (2021) showed that one can bypass this inapproximability by proving approximation ratios that are functions of $m$, the minimum $\ell_{\infty}$-norm of any feasible vector. Given this observation, it is possible to get results for maximizing a DR-submodular function subject to general convex set constraints, which has led to multiple works on this problem. The most recent of which is a polynomial time $\tfrac{1}{4}(1 - m)$-approximation offline algorithm due to Du (2022). However, only a sub-exponential time $\tfrac{1}{3\sqrt{3}}(1 - m)$-approximation algorithm is known for the corresponding online problem. In this work, we present a polynomial time online algorithm matching the $\tfrac{1}{4}(1 - m)$-approximation of the state-of-the-art offline algorithm. We also present an inapproximability result showing that our online algorithm and Du's (2022) offline algorithm are both optimal in a strong sense. Finally, we study the empirical performance of our algorithm and the algorithm of Du (which was only theoretically studied previously), and show that they consistently outperform previously suggested algorithms on revenue maximization, location summarization and quadratic programming applications.