 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Sparse Regularization: Simultaneously Optimizing Neural Network Robustness and Compactness
May 30, 2019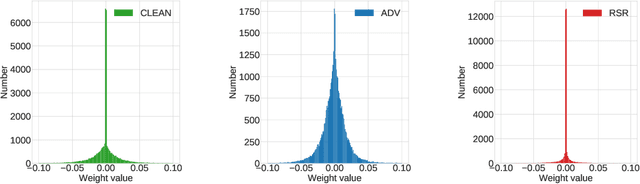
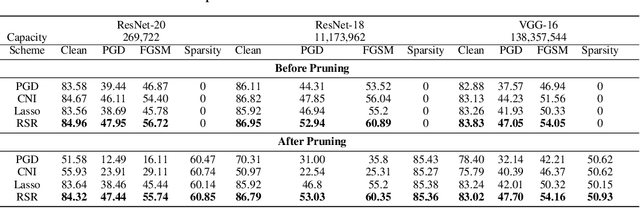
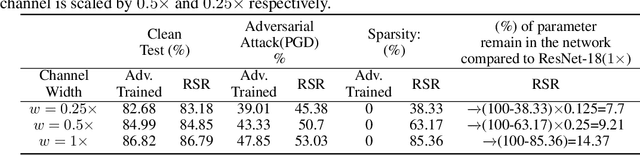
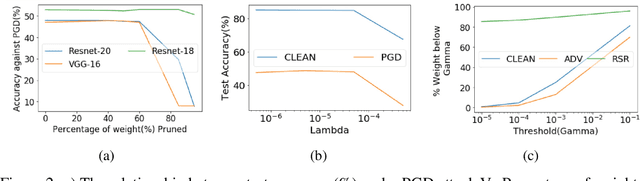
Deep Neural Network (DNN) trained by the gradient descent method is known to be vulnerable to maliciously perturbed adversarial input, aka. adversarial attack. As one of the countermeasures against adversarial attack, increasing the model capacity for DNN robustness enhancement was discussed and reported as an effective approach by many recent works. In this work, we show that shrinking the model size through proper weight pruning can even be helpful to improve the DNN robustness under adversarial attack. For obtaining a simultaneously robust and compact DNN model, we propose a multi-objective training method called Robust Sparse Regularization (RSR), through the fusion of various regularization techniques, including channel-wise noise injection, lasso weight penalty, and adversarial training. We conduct extensive experiments across popular ResNet-20, ResNet-18 and VGG-16 DNN architectures to demonstrate the effectiveness of RSR against popular white-box (i.e., PGD and FGSM) and black-box attacks. Thanks to RSR, 85% weight connections of ResNet-18 can be pruned while still achieving 0.68% and 8.72% improvement in clean- and perturbed-data accuracy respectively on CIFAR-10 dataset, in comparison to its PGD adversarial training baseline.
NATTACK: Learning the Distributions of Adversarial Examples for an Improved Black-Box Attack on Deep Neural Networks
May 13, 2019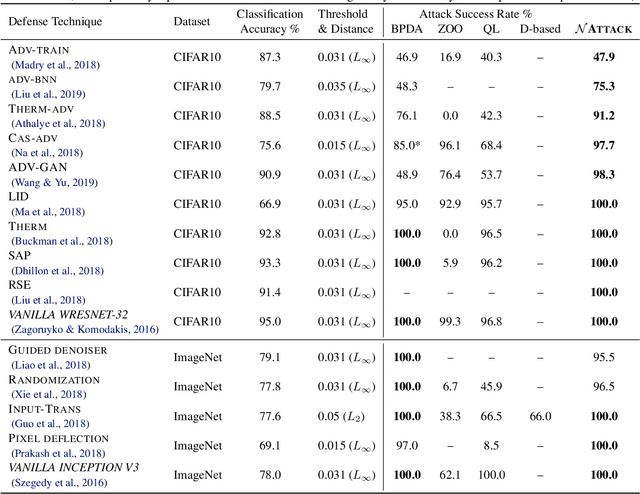
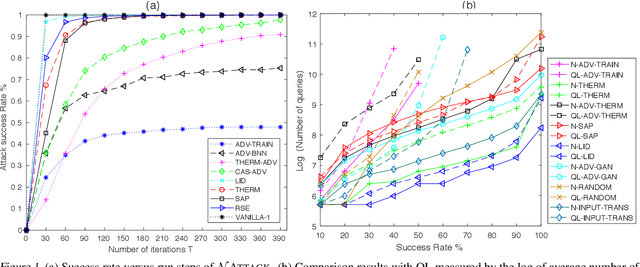
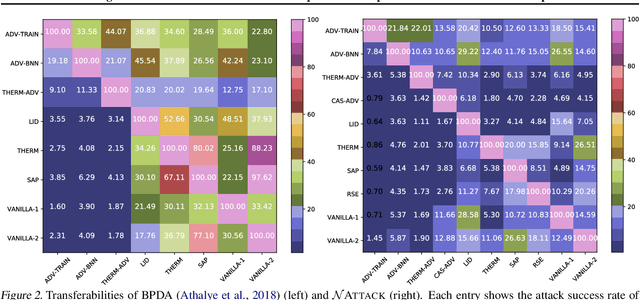
Powerful adversarial attack methods are vital for understanding how to construct robust deep neural networks (DNNs) and for thoroughly testing defense techniques. In this paper, we propose a black-box adversarial attack algorithm that can defeat both vanilla DNNs and those generated by various defense techniques developed recently. Instead of searching for an "optimal" adversarial example for a benign input to a targeted DNN, our algorithm finds a probability density distribution over a small region centered around the input, such that a sample drawn from this distribution is likely an adversarial example, without the need of accessing the DNN's internal layers or weights. Our approach is universal as it can successfully attack different neural networks by a single algorithm. It is also strong; according to the testing against 2 vanilla DNNs and 13 defended ones, it outperforms state-of-the-art black-box or white-box attack methods for most test cases. Additionally, our results reveal that adversarial training remains one of the best defense techniques, and the adversarial examples are not as transferable across defended DNNs as them across vanilla DNNs.
Frame-Recurrent Video Inpainting by Robust Optical Flow Inference
May 08, 2019
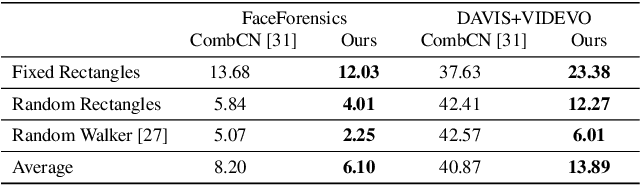
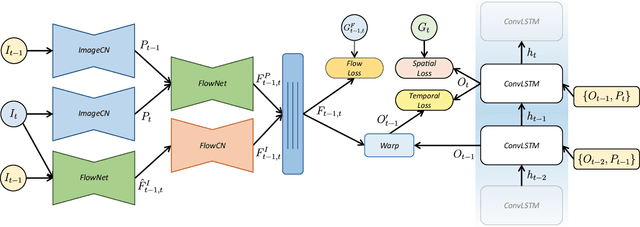
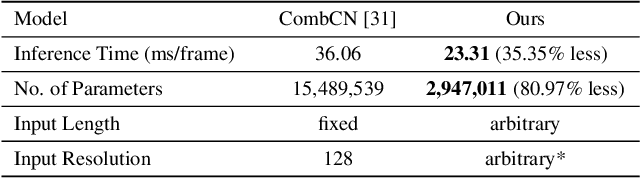
In this paper, we present a new inpainting framework for recovering missing regions of video frames. Compared with image inpainting, performing this task on video presents new challenges such as how to preserving temporal consistency and spatial details, as well as how to handle arbitrary input video size and length fast and efficiently. Towards this end, we propose a novel deep learning architecture which incorporates ConvLSTM and optical flow for modeling the spatial-temporal consistency in videos. It also saves much computational resource such that our method can handle videos with larger frame size and arbitrary length streamingly in real-time. Furthermore, to generate an accurate optical flow from corrupted frames, we propose a robust flow generation module, where two sources of flows are fed and a flow blending network is trained to fuse them. We conduct extensive experiments to evaluate our method in various scenarios and different datasets, both qualitatively and quantitatively. The experimental results demonstrate the superior of our method compared with the state-of-the-art inpainting approaches.
Depthwise Convolution is All You Need for Learning Multiple Visual Domains
Feb 19, 2019

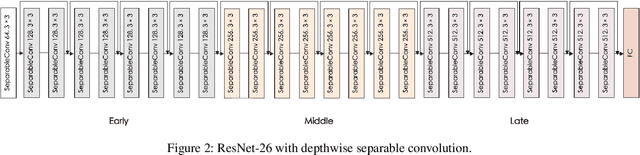
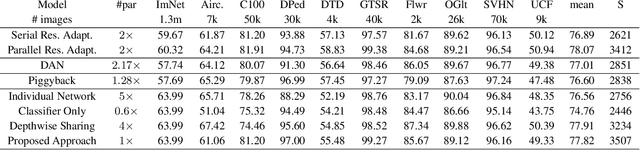
There is a growing interest in designing models that can deal with images from different visual domains. If there exists a universal structure in different visual domains that can be captured via a common parameterization, then we can use a single model for all domains rather than one model per domain. A model aware of the relationships between different domains can also be trained to work on new domains with less resources. However, to identify the reusable structure in a model is not easy. In this paper, we propose a multi-domain learning architecture based on depthwise separable convolution. The proposed approach is based on the assumption that images from different domains share cross-channel correlations but have domain-specific spatial correlations. The proposed model is compact and has minimal overhead when being applied to new domains. Additionally, we introduce a gating mechanism to promote soft sharing between different domains. We evaluate our approach on Visual Decathlon Challenge, a benchmark for testing the ability of multi-domain models. The experiments show that our approach can achieve the highest score while only requiring 50% of the parameters compared with the state-of-the-art approaches.
Learning to Adaptively Scale Recurrent Neural Networks
Feb 15, 2019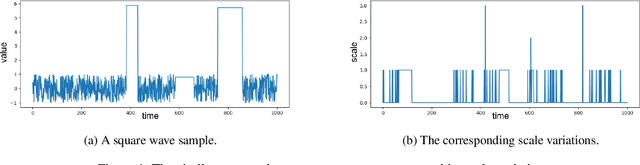

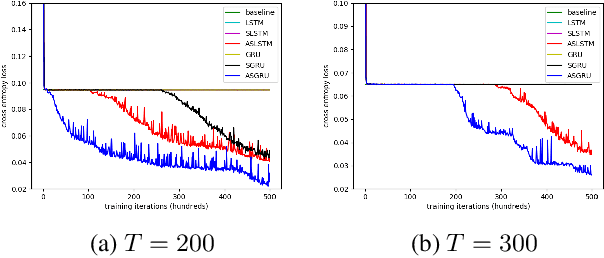
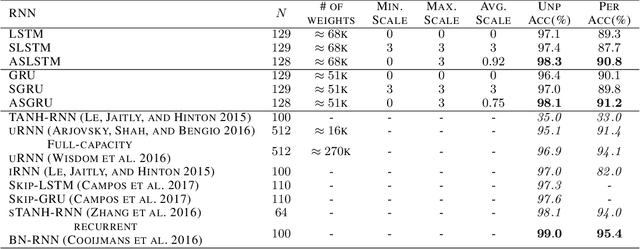
Recent advancements in recurrent neural network (RNN) research have demonstrated the superiority of utilizing multiscale structures in learning temporal representations of time series. Currently, most of multiscale RNNs use fixed scales, which do not comply with the nature of dynamical temporal patterns among sequences. In this paper, we propose Adaptively Scaled Recurrent Neural Networks (ASRNN), a simple but efficient way to handle this problem. Instead of using predefined scales, ASRNNs are able to learn and adjust scales based on different temporal contexts, making them more flexible in modeling multiscale patterns. Compared with other multiscale RNNs, ASRNNs are bestowed upon dynamical scaling capabilities with much simpler structures, and are easy to be integrated with various RNN cells. The experiments on multiple sequence modeling tasks indicate ASRNNs can efficiently adapt scales based on different sequence contexts and yield better performances than baselines without dynamical scaling abilities.
Asynchronous Delay-Aware Accelerated Proximal Coordinate Descent for Nonconvex Nonsmooth Problems
Feb 05, 2019
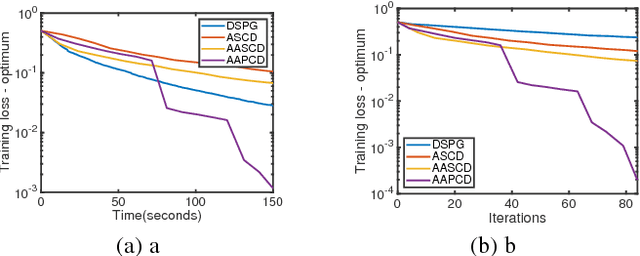
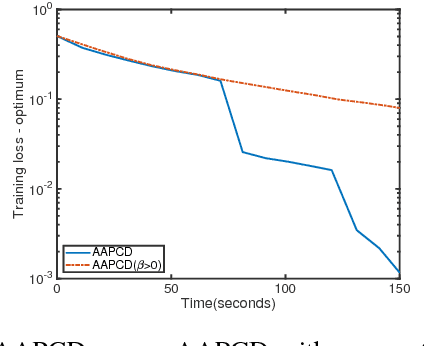
Nonconvex and nonsmooth problems have recently attracted considerable attention in machine learning. However, developing efficient methods for the nonconvex and nonsmooth optimization problems with certain performance guarantee remains a challenge. Proximal coordinate descent (PCD) has been widely used for solving optimization problems, but the knowledge of PCD methods in the nonconvex setting is very limited. On the other hand, the asynchronous proximal coordinate descent (APCD) recently have received much attention in order to solve large-scale problems. However, the accelerated variants of APCD algorithms are rarely studied. In this paper, we extend APCD method to the accelerated algorithm (AAPCD) for nonsmooth and nonconvex problems that satisfies the sufficient descent property, by comparing between the function values at proximal update and a linear extrapolated point using a delay-aware momentum value. To the best of our knowledge, we are the first to provide stochastic and deterministic accelerated extension of APCD algorithms for general nonconvex and nonsmooth problems ensuring that for both bounded delays and unbounded delays every limit point is a critical point. By leveraging Kurdyka-Lojasiewicz property, we will show linear and sublinear convergence rates for the deterministic AAPCD with bounded delays. Numerical results demonstrate the practical efficiency of our algorithm in speed.
AET vs. AED: Unsupervised Representation Learning by Auto-Encoding Transformations rather than Data
Jan 14, 2019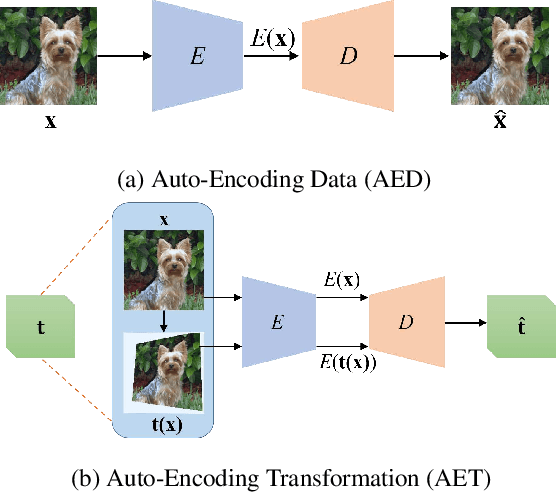
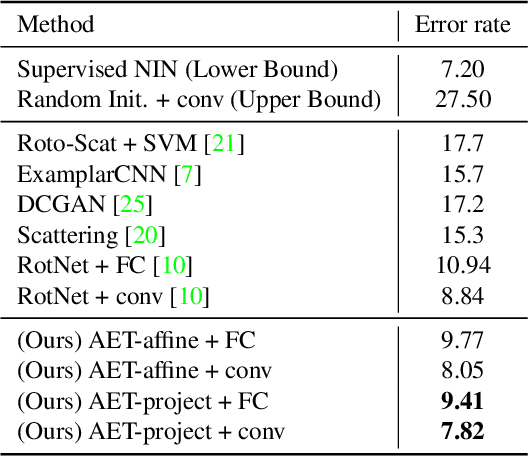
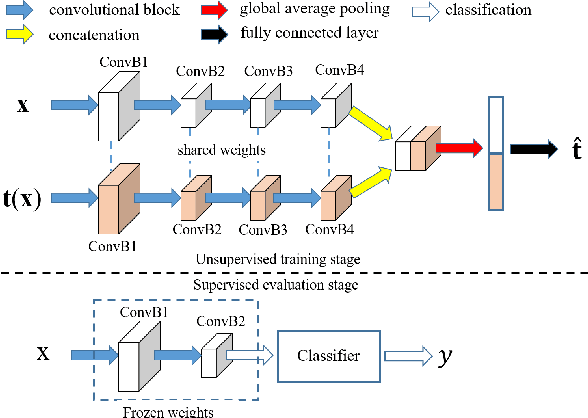

The success of deep neural networks often relies on a large amount of labeled examples, which can be difficult to obtain in many real scenarios. To address this challenge, unsupervised methods are strongly preferred for training neural networks without using any labeled data. In this paper, we present a novel paradigm of unsupervised representation learning by Auto-Encoding Transformation (AET) in contrast to the conventional Auto-Encoding Data (AED) approach. Given a randomly sampled transformation, AET seeks to predict it merely from the encoded features as accurately as possible at the output end. The idea is the following: as long as the unsupervised features successfully encode the essential information about the visual structures of original and transformed images, the transformation can be well predicted. We will show that this AET paradigm allows us to instantiate a large variety of transformations, from parameterized, to non-parameterized and GAN-induced ones. Our experiments show that AET greatly improves over existing unsupervised approaches, setting new state-of-the-art performances being greatly closer to the upper bounds by their fully supervised counterparts on CIFAR-10, ImageNet and Places datasets.
A Proximal Zeroth-Order Algorithm for Nonconvex Nonsmooth Problems
Oct 17, 2018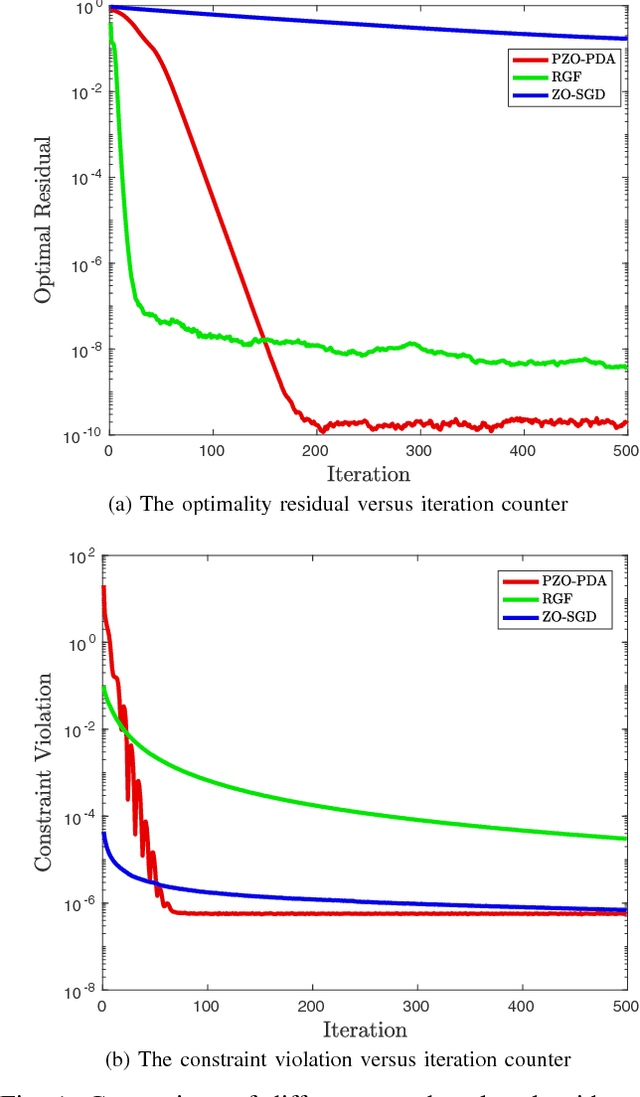
In this paper, we focus on solving an important class of nonconvex optimization problems which includes many problems for example signal processing over a networked multi-agent system and distributed learning over networks. Motivated by many applications in which the local objective function is the sum of smooth but possibly nonconvex part, and non-smooth but convex part subject to a linear equality constraint, this paper proposes a proximal zeroth-order primal dual algorithm (PZO-PDA) that accounts for the information structure of the problem. This algorithm only utilize the zeroth-order information (i.e., the functional values) of smooth functions, yet the flexibility is achieved for applications that only noisy information of the objective function is accessible, where classical methods cannot be applied. We prove convergence and rate of convergence for PZO-PDA. Numerical experiments are provided to validate the theoretical results.
How Local is the Local Diversity? Reinforcing Sequential Determinantal Point Processes with Dynamic Ground Sets for Supervised Video Summarization
Aug 24, 2018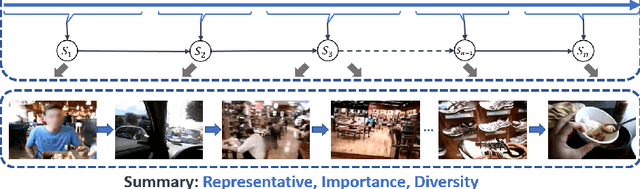
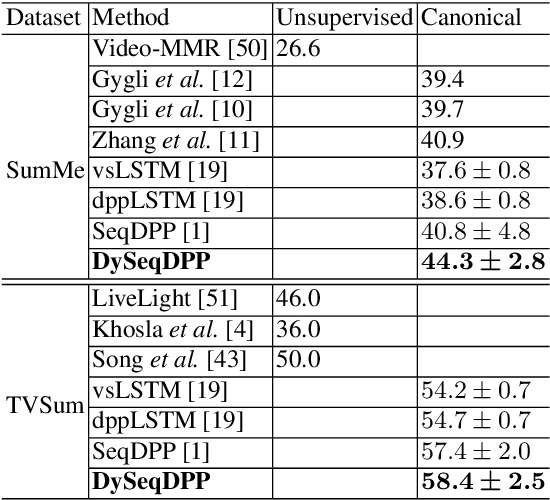
The large volume of video content and high viewing frequency demand automatic video summarization algorithms, of which a key property is the capability of modeling diversity. If videos are lengthy like hours-long egocentric videos, it is necessary to track the temporal structures of the videos and enforce local diversity. The local diversity refers to that the shots selected from a short time duration are diverse but visually similar shots are allowed to co-exist in the summary if they appear far apart in the video. In this paper, we propose a novel probabilistic model, built upon SeqDPP, to dynamically control the time span of a video segment upon which the local diversity is imposed. In particular, we enable SeqDPP to learn to automatically infer how local the local diversity is supposed to be from the input video. The resulting model is extremely involved to train by the hallmark maximum likelihood estimation (MLE), which further suffers from the exposure bias and non-differentiable evaluation metrics. To tackle these problems, we instead devise a reinforcement learning algorithm for training the proposed model. Extensive experiments verify the advantages of our model and the new learning algorithm over MLE-based methods.
A Semi-Supervised Two-Stage Approach to Learning from Noisy Labels
Mar 21, 2018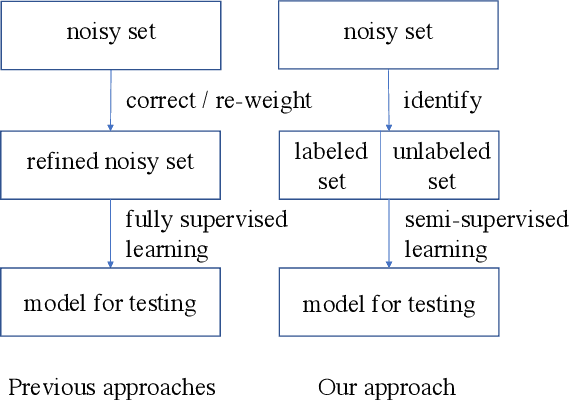
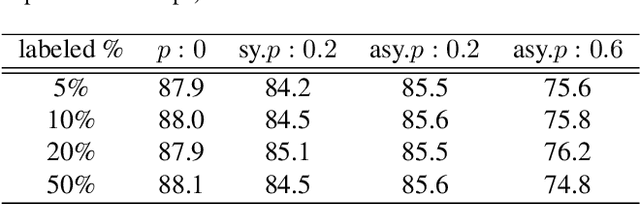
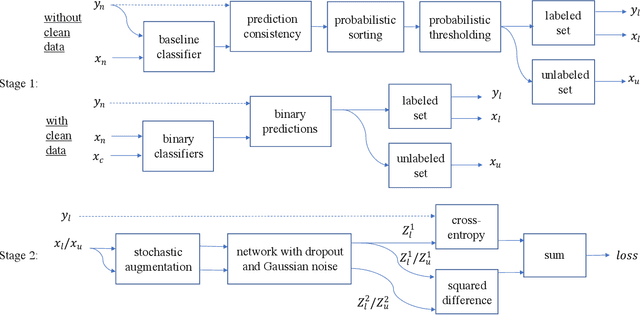

The recent success of deep neural networks is powered in part by large-scale well-labeled training data. However, it is a daunting task to laboriously annotate an ImageNet-like dateset. On the contrary, it is fairly convenient, fast, and cheap to collect training images from the Web along with their noisy labels. This signifies the need of alternative approaches to training deep neural networks using such noisy labels. Existing methods tackling this problem either try to identify and correct the wrong labels or reweigh the data terms in the loss function according to the inferred noisy rates. Both strategies inevitably incur errors for some of the data points. In this paper, we contend that it is actually better to ignore the labels of some of the data points than to keep them if the labels are incorrect, especially when the noisy rate is high. After all, the wrong labels could mislead a neural network to a bad local optimum. We suggest a two-stage framework for the learning from noisy labels. In the first stage, we identify a small portion of images from the noisy training set of which the labels are correct with a high probability. The noisy labels of the other images are ignored. In the second stage, we train a deep neural network in a semi-supervised manner. This framework effectively takes advantage of the whole training set and yet only a portion of its labels that are most likely correct. Experiments on three datasets verify the effectiveness of our approach especially when the noisy rate is high.