 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic identification of outliers in Hubble Space Telescope galaxy images
Jan 07, 2021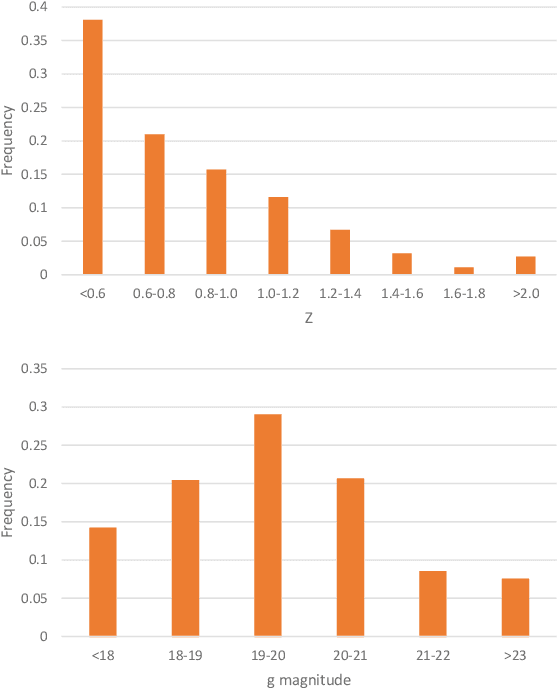


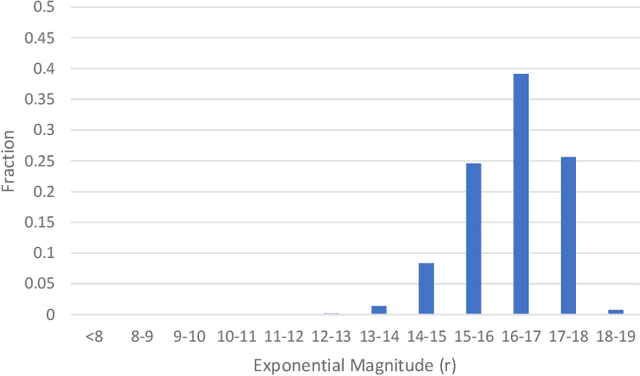
Rare extragalactic objects can carry substantial information about the past, present, and future universe. Given the size of astronomical databases in the information era it can be assumed that very many outlier galaxies are included in existing and future astronomical databases. However, manual search for these objects is impractical due to the required labor, and therefore the ability to detect such objects largely depends on computer algorithms. This paper describes an unsupervised machine learning algorithm for automatic detection of outlier galaxy images, and its application to several Hubble Space Telescope fields. The algorithm does not require training, and therefore is not dependent on the preparation of clean training sets. The application of the algorithm to a large collection of galaxies detected a variety of outlier galaxy images. The algorithm is not perfect in the sense that not all objects detected by the algorithm are indeed considered outliers, but it reduces the dataset by two orders of magnitude to allow practical manual identification. The catalogue contains 147 objects that would be very difficult to identify without using automation.
A catalog of broad morphology of Pan-STARRS galaxies based on deep learning
Oct 12, 2020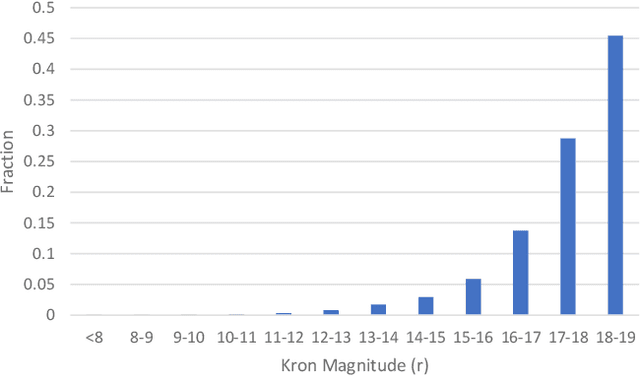


Autonomous digital sky surveys such as Pan-STARRS have the ability to image a very large number of galactic and extra-galactic objects, and the large and complex nature of the image data reinforces the use of automation. Here we describe the design and implementation of a data analysis process for automatic broad morphology annotation of galaxies, and applied it to the data of Pan-STARRS DR1. The process is based on filters followed by a two-step convolutional neural network (CNN) classification. Training samples are generated by using an augmented and balanced set of manually classified galaxies. Results are evaluated for accuracy by comparison to the annotation of Pan-STARRS included in a previous broad morphology catalog of SDSS galaxies. Our analysis shows that a CNN combined with several filters is an effective approach for annotating the galaxies and removing unclean images. The catalog contains morphology labels for 1,662,190 galaxies with ~95% accuracy. The accuracy can be further improved by selecting labels above certain confidence thresholds. The catalog is publicly available.
Algorithms and Statistical Models for Scientific Discovery in the Petabyte Era
Nov 05, 2019The field of astronomy has arrived at a turning point in terms of size and complexity of both datasets and scientific collaboration. Commensurately, algorithms and statistical models have begun to adapt --- e.g., via the onset of artificial intelligence --- which itself presents new challenges and opportunities for growth. This white paper aims to offer guidance and ideas for how we can evolve our technical and collaborative frameworks to promote efficient algorithmic development and take advantage of opportunities for scientific discovery in the petabyte era. We discuss challenges for discovery in large and complex data sets; challenges and requirements for the next stage of development of statistical methodologies and algorithmic tool sets; how we might change our paradigms of collaboration and education; and the ethical implications of scientists' contributions to widely applicable algorithms and computational modeling. We start with six distinct recommendations that are supported by the commentary following them. This white paper is related to a larger corpus of effort that has taken place within and around the Petabytes to Science Workshops (https://petabytestoscience.github.io/).
Computer Analysis of Architecture Using Automatic Image Understanding
Oct 17, 2018



In the past few years, computer vision and pattern recognition systems have been becoming increasingly more powerful, expanding the range of automatic tasks enabled by machine vision. Here we show that computer analysis of building images can perform quantitative analysis of architecture, and quantify similarities between city architectural styles in a quantitative fashion. Images of buildings from 18 cities and three countries were acquired using Google StreetView, and were used to train a machine vision system to automatically identify the location of the imaged building based on the image visual content. Experimental results show that the automatic computer analysis can automatically identify the geographical location of the StreetView image. More importantly, the algorithm was able to group the cities and countries and provide a phylogeny of the similarities between architectural styles as captured by StreetView images. These results demonstrate that computer vision and pattern recognition algorithms can perform the complex cognitive task of analyzing images of buildings, and can be used to measure and quantify visual similarities and differences between different styles of architectures. This experiment provides a new paradigm for studying architecture, based on a quantitative approach that can enhance the traditional manual observation and analysis. The source code used for the analysis is open and publicly available.
Combining human and machine learning for morphological analysis of galaxy images
Sep 28, 2014
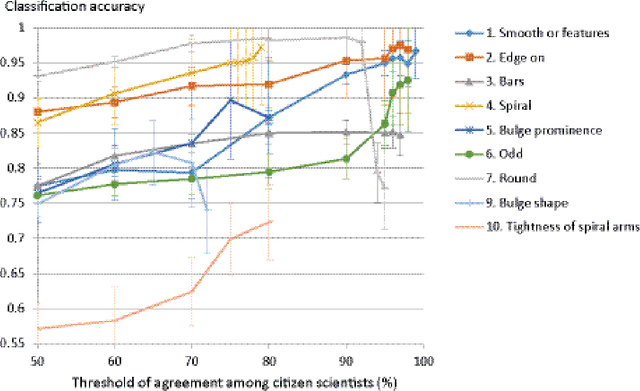
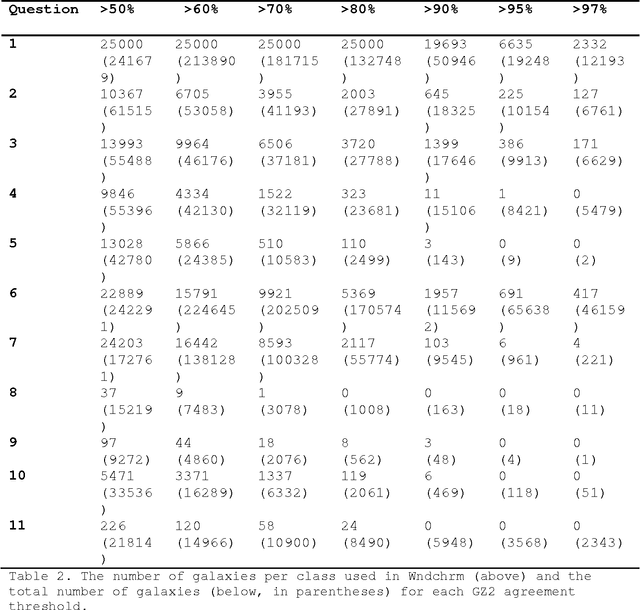
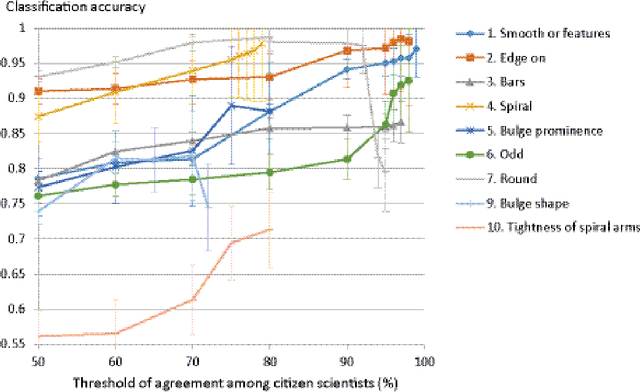
The increasing importance of digital sky surveys collecting many millions of galaxy images has reinforced the need for robust methods that can perform morphological analysis of large galaxy image databases. Citizen science initiatives such as Galaxy Zoo showed that large datasets of galaxy images can be analyzed effectively by non-scientist volunteers, but since databases generated by robotic telescopes grow much faster than the processing power of any group of citizen scientists, it is clear that computer analysis is required. Here we propose to use citizen science data for training machine learning systems, and show experimental results demonstrating that machine learning systems can be trained with citizen science data. Our findings show that the performance of machine learning depends on the quality of the data, which can be improved by using samples that have a high degree of agreement between the citizen scientists. The source code of the method is publicly available.