 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Q-Learning with Reference-Advantage Decomposition: Almost Optimal Regret and Logarithmic Communication Cost
May 29, 2024In this paper, we consider model-free federated reinforcement learning for tabular episodic Markov decision processes. Under the coordination of a central server, multiple agents collaboratively explore the environment and learn an optimal policy without sharing their raw data. Despite recent advances in federated Q-learning algorithms achieving near-linear regret speedup with low communication cost, existing algorithms only attain suboptimal regrets compared to the information bound. We propose a novel model-free federated Q-learning algorithm, termed FedQ-Advantage. Our algorithm leverages reference-advantage decomposition for variance reduction and operates under two distinct mechanisms: synchronization between the agents and the server, and policy update, both triggered by events. We prove that our algorithm not only requires a lower logarithmic communication cost but also achieves an almost optimal regret, reaching the information bound up to a logarithmic factor and near-linear regret speedup compared to its single-agent counterpart when the time horizon is sufficiently large.
A Unified Combination Framework for Dependent Tests with Applications to Microbiome Association Studies
Apr 14, 2024We introduce a novel meta-analysis framework to combine dependent tests under a general setting, and utilize it to synthesize various microbiome association tests that are calculated from the same dataset. Our development builds upon the classical meta-analysis methods of aggregating $p$-values and also a more recent general method of combining confidence distributions, but makes generalizations to handle dependent tests. The proposed framework ensures rigorous statistical guarantees, and we provide a comprehensive study and compare it with various existing dependent combination methods. Notably, we demonstrate that the widely used Cauchy combination method for dependent tests, referred to as the vanilla Cauchy combination in this article, can be viewed as a special case within our framework. Moreover, the proposed framework provides a way to address the problem when the distributional assumptions underlying the vanilla Cauchy combination are violated. Our numerical results demonstrate that ignoring the dependence among the to-be-combined components may lead to a severe size distortion phenomenon. Compared to the existing $p$-value combination methods, including the vanilla Cauchy combination method, the proposed combination framework can handle the dependence accurately and utilizes the information efficiently to construct tests with accurate size and enhanced power. The development is applied to Microbiome Association Studies, where we aggregate information from multiple existing tests using the same dataset. The combined tests harness the strengths of each individual test across a wide range of alternative spaces, %resulting in a significant enhancement of testing power across a wide range of alternative spaces, enabling more efficient and meaningful discoveries of vital microbiome associations.
A Copula Graphical Model for Multi-Attribute Data using Optimal Transport
Apr 10, 2024



Motivated by modern data forms such as images and multi-view data, the multi-attribute graphical model aims to explore the conditional independence structure among vectors. Under the Gaussian assumption, the conditional independence between vectors is characterized by blockwise zeros in the precision matrix. To relax the restrictive Gaussian assumption, in this paper, we introduce a novel semiparametric multi-attribute graphical model based on a new copula named Cyclically Monotone Copula. This new copula treats the distribution of the node vectors as multivariate marginals and transforms them into Gaussian distributions based on the optimal transport theory. Since the model allows the node vectors to have arbitrary continuous distributions, it is more flexible than the classical Gaussian copula method that performs coordinatewise Gaussianization. We establish the concentration inequalities of the estimated covariance matrices and provide sufficient conditions for selection consistency of the group graphical lasso estimator. For the setting with high-dimensional attributes, a {Projected Cyclically Monotone Copula} model is proposed to address the curse of dimensionality issue that arises from solving high-dimensional optimal transport problems. Numerical results based on synthetic and real data show the efficiency and flexibility of our methods.
Federated Q-Learning: Linear Regret Speedup with Low Communication Cost
Dec 22, 2023


In this paper, we consider federated reinforcement learning for tabular episodic Markov Decision Processes (MDP) where, under the coordination of a central server, multiple agents collaboratively explore the environment and learn an optimal policy without sharing their raw data. While linear speedup in the number of agents has been achieved for some metrics, such as convergence rate and sample complexity, in similar settings, it is unclear whether it is possible to design a model-free algorithm to achieve linear regret speedup with low communication cost. We propose two federated Q-Learning algorithms termed as FedQ-Hoeffding and FedQ-Bernstein, respectively, and show that the corresponding total regrets achieve a linear speedup compared with their single-agent counterparts when the time horizon is sufficiently large, while the communication cost scales logarithmically in the total number of time steps $T$. Those results rely on an event-triggered synchronization mechanism between the agents and the server, a novel step size selection when the server aggregates the local estimates of the state-action values to form the global estimates, and a set of new concentration inequalities to bound the sum of non-martingale differences. This is the first work showing that linear regret speedup and logarithmic communication cost can be achieved by model-free algorithms in federated reinforcement learning.
A New Inexact Proximal Linear Algorithm with Adaptive Stopping Criteria for Robust Phase Retrieval
Apr 25, 2023This paper considers the robust phase retrieval problem, which can be cast as a nonsmooth and nonconvex optimization problem. We propose a new inexact proximal linear algorithm with the subproblem being solved inexactly. Our contributions are two adaptive stopping criteria for the subproblem. The convergence behavior of the proposed methods is analyzed. Through experiments on both synthetic and real datasets, we demonstrate that our methods are much more efficient than existing methods, such as the original proximal linear algorithm and the subgradient method.
A Graphical Point Process Framework for Understanding Removal Effects in Multi-Touch Attribution
Feb 13, 2023



Marketers employ various online advertising channels to reach customers, and they are particularly interested in attribution for measuring the degree to which individual touchpoints contribute to an eventual conversion. The availability of individual customer-level path-to-purchase data and the increasing number of online marketing channels and types of touchpoints bring new challenges to this fundamental problem. We aim to tackle the attribution problem with finer granularity by conducting attribution at the path level. To this end, we develop a novel graphical point process framework to study the direct conversion effects and the full relational structure among numerous types of touchpoints simultaneously. Utilizing the temporal point process of conversion and the graphical structure, we further propose graphical attribution methods to allocate proper path-level conversion credit, called the attribution score, to individual touchpoints or corresponding channels for each customer's path to purchase. Our proposed attribution methods consider the attribution score as the removal effect, and we use the rigorous probabilistic definition to derive two types of removal effects. We examine the performance of our proposed methods in extensive simulation studies and compare their performance with commonly used attribution models. We also demonstrate the performance of the proposed methods in a real-world attribution application.
Theoretical Guarantees for Sparse Principal Component Analysis based on the Elastic Net
Dec 29, 2022Sparse principal component analysis (SPCA) has been widely used for dimensionality reduction and feature extraction in high-dimensional data analysis. Despite there are many methodological and theoretical developments in the past two decades, the theoretical guarantees of the popular SPCA algorithm proposed by Zou, Hastie & Tibshirani (2006) based on the elastic net are still unknown. We aim to close this important theoretical gap in this paper. We first revisit the SPCA algorithm of Zou et al. (2006) and present our implementation. Also, we study a computationally more efficient variant of the SPCA algorithm in Zou et al. (2006) that can be considered as the limiting case of SPCA. We provide the guarantees of convergence to a stationary point for both algorithms. We prove that, under a sparse spiked covariance model, both algorithms can recover the principal subspace consistently under mild regularity conditions. We show that their estimation error bounds match the best available bounds of existing works or the minimax rates up to some logarithmic factors. Moreover, we demonstrate the numerical performance of both algorithms in simulation studies.
Nonlinear Sufficient Dimension Reduction for Distribution-on-Distribution Regression
Jul 11, 2022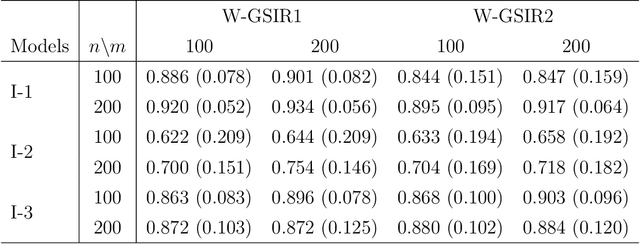
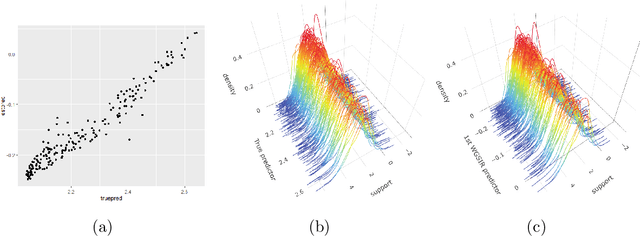
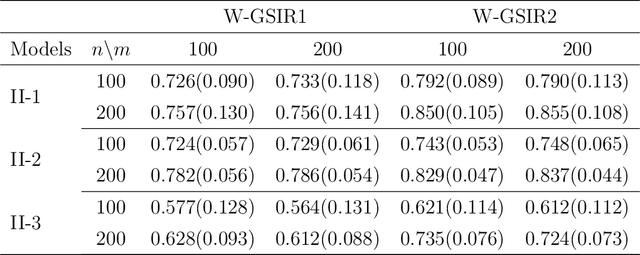
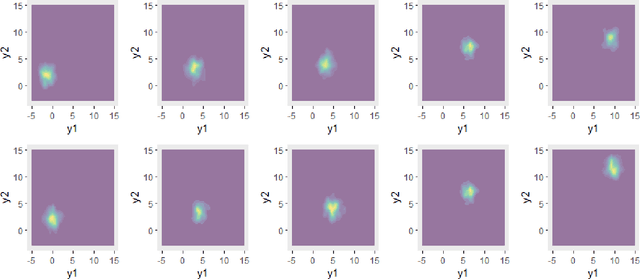
We introduce a novel framework for nonlinear sufficient dimension reduction where both the predictor and the response are distributional data, which are modeled as members of a metric space. Our key step to achieving the nonlinear sufficient dimension reduction is to build universal kernels on the metric spaces, which results in reproducing kernel Hilbert spaces for the predictor and response that are rich enough to characterize the conditional independence that determines sufficient dimension reduction. For univariate distributions, we use the well-known quantile representation of the Wasserstein distance to construct the universal kernel; for multivariate distributions, we resort to the recently developed sliced Wasserstein distance to achieve this purpose. Since the sliced Wasserstein distance can be computed by aggregation of quantile representation of the univariate Wasserstein distance, the computation of multivariate Wasserstein distance is kept at a manageable level. The method is applied to several data sets, including fertility and mortality distribution data and Calgary temperature data.
An additive graphical model for discrete data
Dec 29, 2021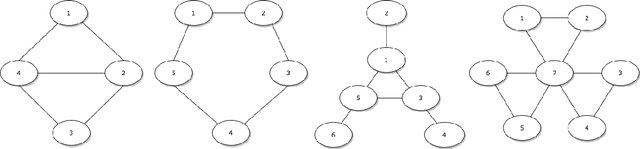
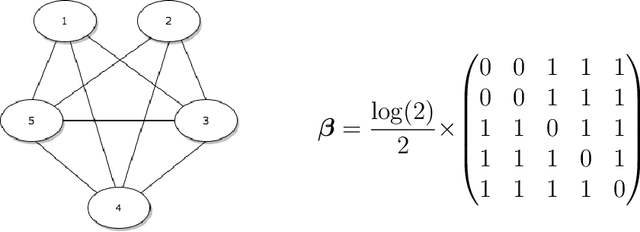
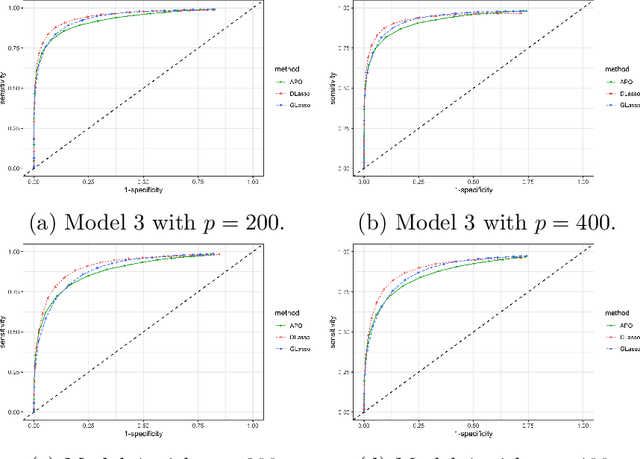
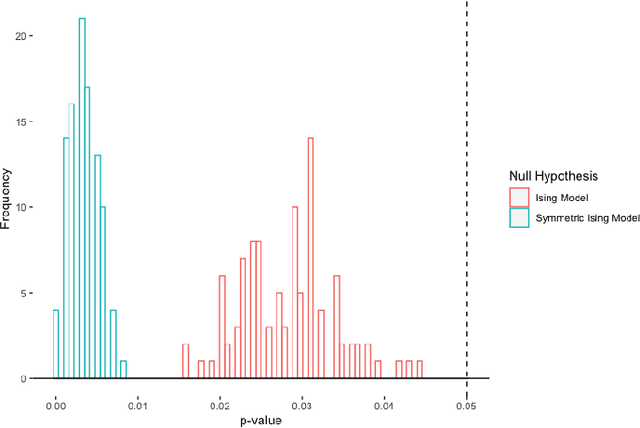
We introduce a nonparametric graphical model for discrete node variables based on additive conditional independence. Additive conditional independence is a three way statistical relation that shares similar properties with conditional independence by satisfying the semi-graphoid axioms. Based on this relation we build an additive graphical model for discrete variables that does not suffer from the restriction of a parametric model such as the Ising model. We develop an estimator of the new graphical model via the penalized estimation of the discrete version of the additive precision operator and establish the consistency of the estimator under the ultrahigh-dimensional setting. Along with these methodological developments, we also exploit the properties of discrete random variables to uncover a deeper relation between additive conditional independence and conditional independence than previously known. The new graphical model reduces to a conditional independence graphical model under certain sparsity conditions. We conduct simulation experiments and analysis of an HIV antiretroviral therapy data set to compare the new method with existing ones.
Dimension Reduction and Data Visualization for Fréchet Regression
Oct 01, 2021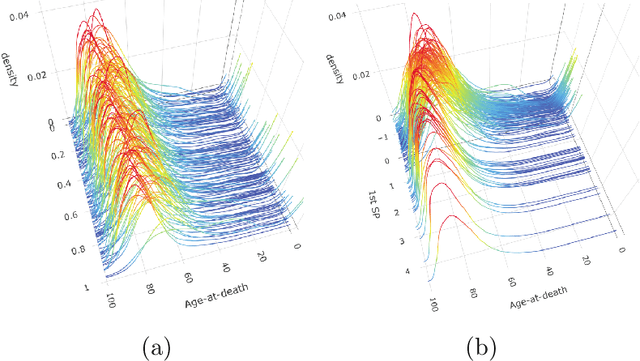
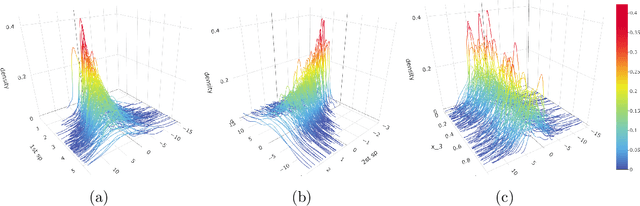
With the rapid development of data collection techniques, complex data objects that are not in the Euclidean space are frequently encountered in new statistical applications. Fr\'echet regression model (Peterson & M\"uller 2019) provides a promising framework for regression analysis with metric space-valued responses. In this paper, we introduce a flexible sufficient dimension reduction (SDR) method for Fr\'echet regression to achieve two purposes: to mitigate the curse of dimensionality caused by high-dimensional predictors, and to provide a tool for data visualization for Fr\'echet regression. Our approach is flexible enough to turn any existing SDR method for Euclidean (X,Y) into one for Euclidean X and metric space-valued Y. The basic idea is to first map the metric-space valued random object $Y$ to a real-valued random variable $f(Y)$ using a class of functions, and then perform classical SDR to the transformed data. If the class of functions is sufficiently rich, then we are guaranteed to uncover the Fr\'echet SDR space. We showed that such a class, which we call an ensemble, can be generated by a universal kernel. We established the consistency and asymptotic convergence rate of the proposed methods. The finite-sample performance of the proposed methods is illustrated through simulation studies for several commonly encountered metric spaces that include Wasserstein space, the space of symmetric positive definite matrices, and the sphere. We illustrated the data visualization aspect of our method by exploring the human mortality distribution data across countries and by studying the distribution of hematoma density.