 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoresets for Time Series Clustering
Oct 28, 2021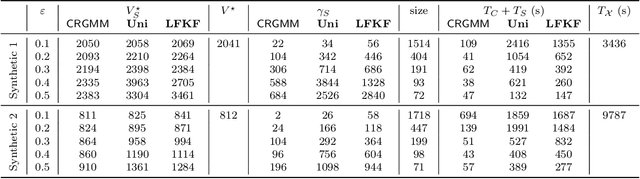
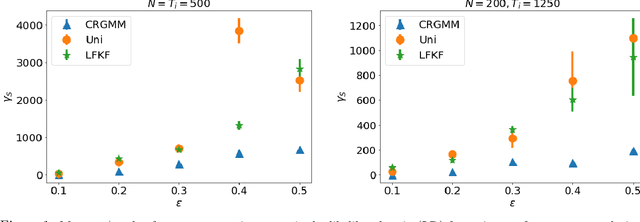
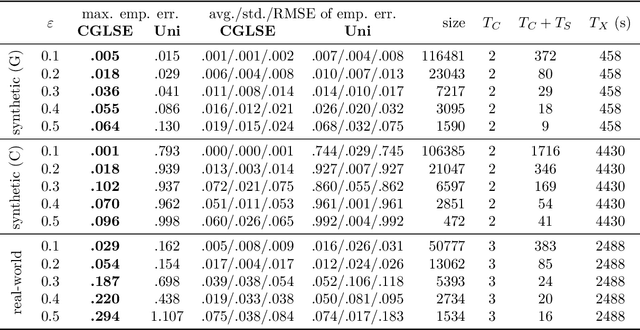
We study the problem of constructing coresets for clustering problems with time series data. This problem has gained importance across many fields including biology, medicine, and economics due to the proliferation of sensors facilitating real-time measurement and rapid drop in storage costs. In particular, we consider the setting where the time series data on $N$ entities is generated from a Gaussian mixture model with autocorrelations over $k$ clusters in $\mathbb{R}^d$. Our main contribution is an algorithm to construct coresets for the maximum likelihood objective for this mixture model. Our algorithm is efficient, and under a mild boundedness assumption on the covariance matrices of the underlying Gaussians, the size of the coreset is independent of the number of entities $N$ and the number of observations for each entity, and depends only polynomially on $k$, $d$ and $1/\varepsilon$, where $\varepsilon$ is the error parameter. We empirically assess the performance of our coreset with synthetic data.
CAC: A Clustering Based Framework for Classification
Feb 23, 2021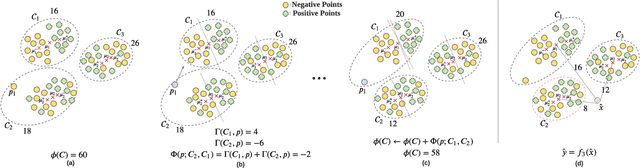
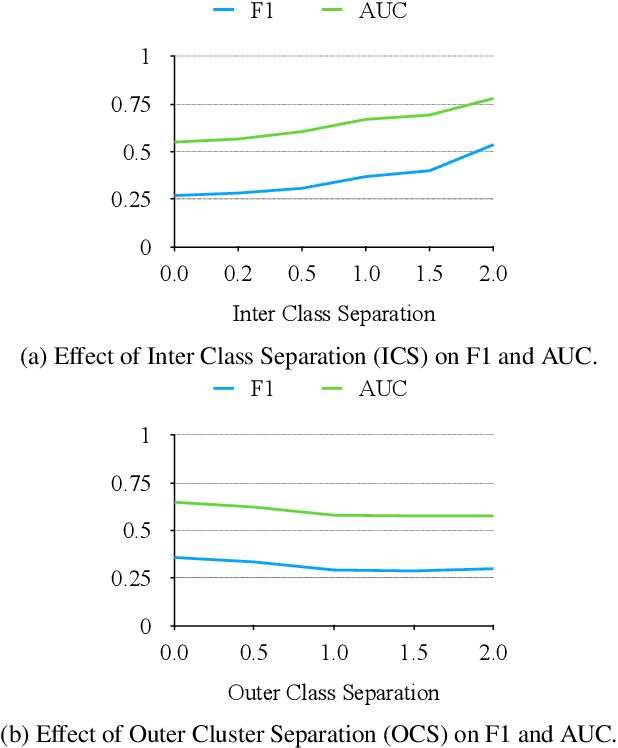
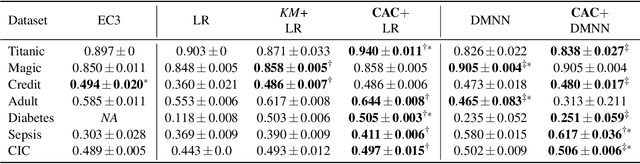
In data containing heterogeneous subpopulations, classification performance benefits from incorporating the knowledge of cluster structure in the classifier. Previous methods for such combined clustering and classification either are classifier-specific and not generic or independently perform clustering and classifier training, which may not form clusters that can potentially benefit classifier performance. The question of how to perform clustering to improve the performance of classifiers trained on the clusters has received scant attention in previous literature despite its importance in several real-world applications. In this paper, we theoretically analyze when and how clustering may help in obtaining accurate classifiers. We design a simple, efficient, and generic framework called Classification Aware Clustering (CAC), to find clusters that are well suited for being used as training datasets by classifiers for each underlying subpopulation. Our experiments on synthetic and real benchmark datasets demonstrate the efficacy of CAC over previous methods for combined clustering and classification.
Coresets for Regressions with Panel Data
Nov 03, 2020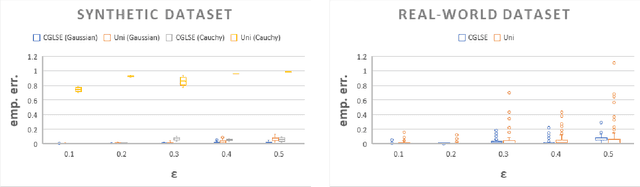
This paper introduces the problem of coresets for regression problems to panel data settings. We first define coresets for several variants of regression problems with panel data and then present efficient algorithms to construct coresets of size that depend polynomially on 1/$\varepsilon$ (where $\varepsilon$ is the error parameter) and the number of regression parameters - independent of the number of individuals in the panel data or the time units each individual is observed for. Our approach is based on the Feldman-Langberg framework in which a key step is to upper bound the "total sensitivity" that is roughly the sum of maximum influences of all individual-time pairs taken over all possible choices of regression parameters. Empirically, we assess our approach with synthetic and real-world datasets; the coreset sizes constructed using our approach are much smaller than the full dataset and coresets indeed accelerate the running time of computing the regression objective.
Fair Classification with Noisy Protected Attributes
Jun 08, 2020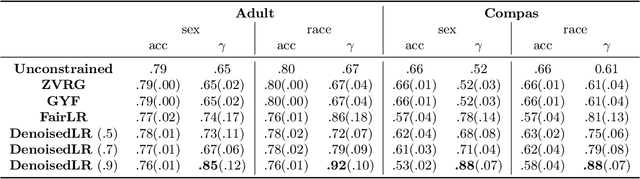

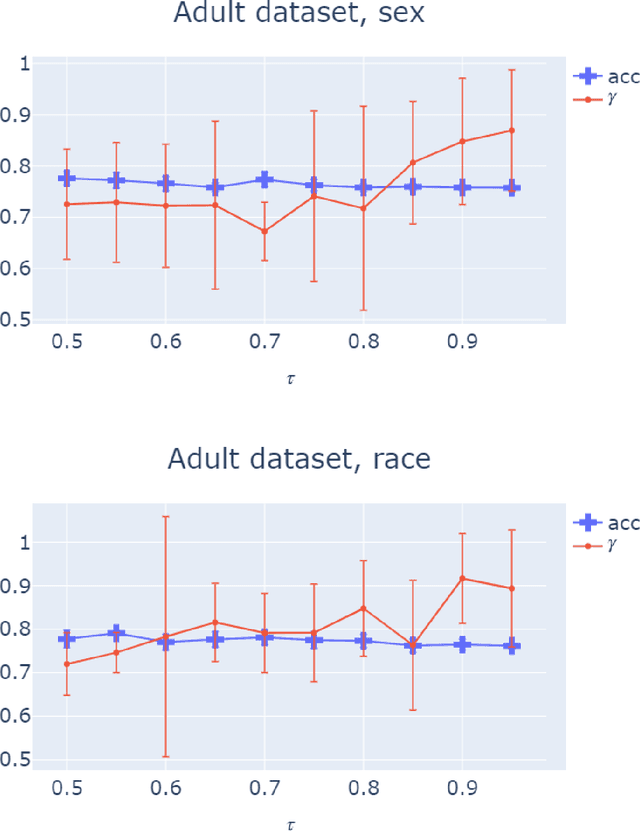
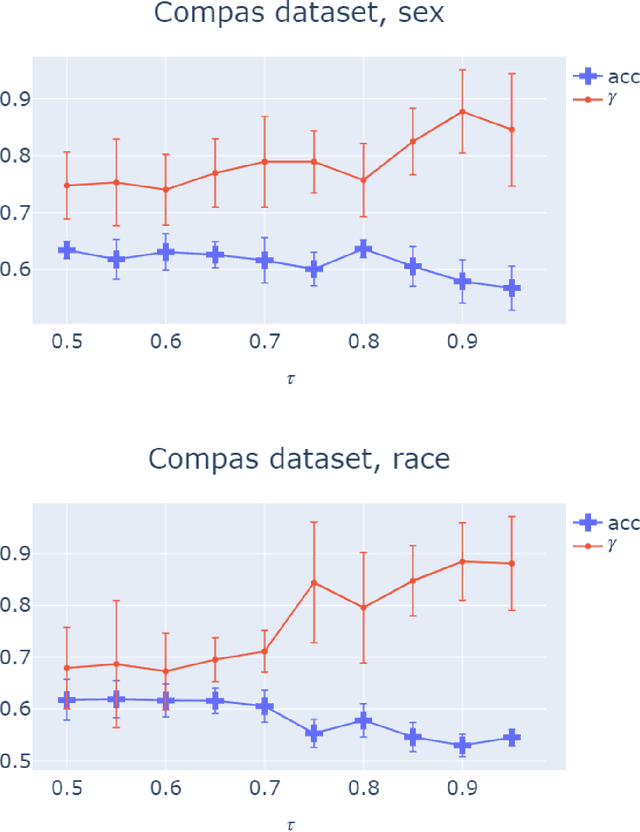
Due to the growing deployment of classification algorithms in various social contexts, developing methods that are fair with respect to protected attributes such as gender or race is an important problem. However, the information about protected attributes in datasets may be inaccurate due to either issues with data collection or when the protected attributes used are themselves predicted by algorithms. Such inaccuracies can prevent existing fair classification algorithms from achieving desired fairness guarantees. Motivated by this, we study fair classification problems when the protected attributes in the data may be ``noisy''. In particular, we consider a noise model where any protected type may be flipped to another with some fixed probability. We propose a ``denoised'' fair optimization formulation that can incorporate very general fairness goals via a set of constraints, mitigates the effects of such noise perturbations, and comes with provable guarantees. Empirically, we show that our framework can lead to near-perfect statistical parity with only a slight loss in accuracy for significant noise levels.
Coresets for Clustering with Fairness Constraints
Aug 12, 2019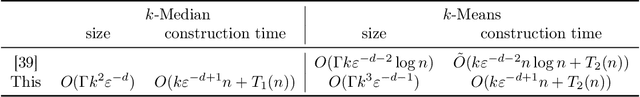


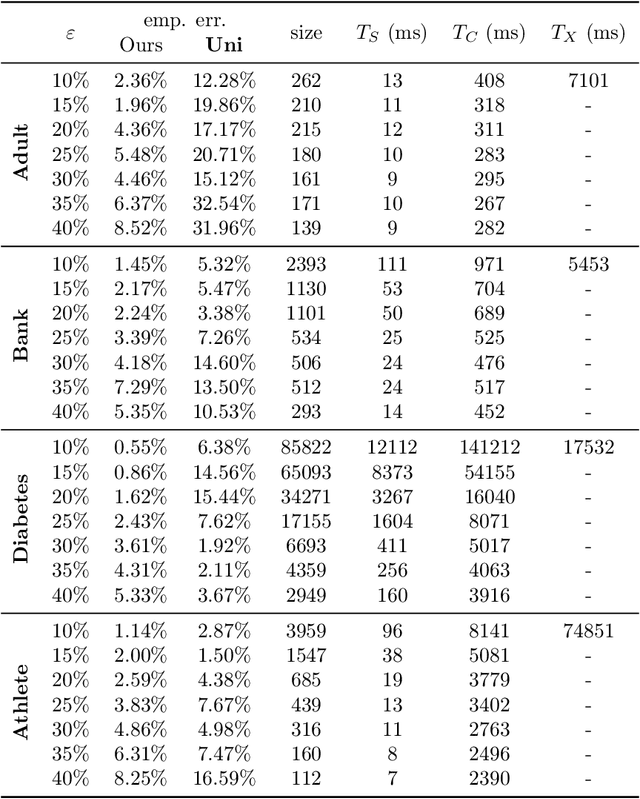
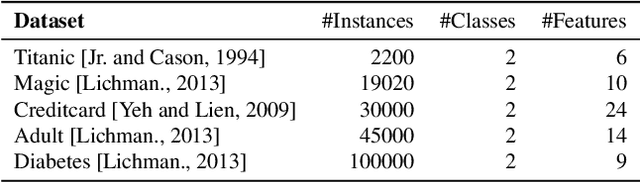
In a recent work, [19] studied the following "fair" variants of classical clustering problems such as $k$-means and $k$-median: given a set of $n$ data points in $\mathbb{R}^d$ and a binary type associated to each data point, the goal is to cluster the points while ensuring that the proportion of each type in each cluster is roughly the same as its underlying proportion. Subsequent work has focused on either extending this setting to when each data point has multiple, non-disjoint sensitive types such as race and gender [6], or to address the problem that the clustering algorithms in the above work do not scale well. The main contribution of this paper is an approach to clustering with fairness constraints that involve multiple, non-disjoint types, that is also scalable. Our approach is based on novel constructions of coresets: for the $k$-median objective, we construct an $\varepsilon$-coreset of size $O(\Gamma k^2 \varepsilon^{-d})$ where $\Gamma$ is the number of distinct collections of groups that a point may belong to, and for the $k$-means objective, we show how to construct an $\varepsilon$-coreset of size $O(\Gamma k^3\varepsilon^{-d-1})$. The former result is the first known coreset construction for the fair clustering problem with the $k$-median objective, and the latter result removes the dependence on the size of the full dataset as in [39] and generalizes it to multiple, non-disjoint types. Plugging our coresets into existing algorithms for fair clustering such as [5] results in the fastest algorithms for several cases. Empirically, we assess our approach over the \textbf{Adult}, \textbf{Bank} and \textbf{Diabetes} dataset, and show that the coreset sizes are much smaller than the full dataset. We also achieve a speed-up to recent fair clustering algorithms [5,6] on a large dataset \textbf{Census1990} by incorporating our coreset construction.
Stable and Fair Classification
Feb 26, 2019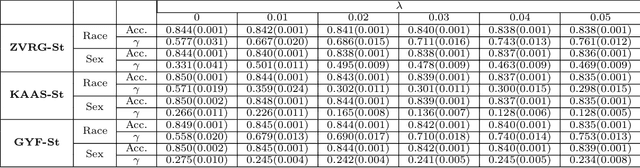
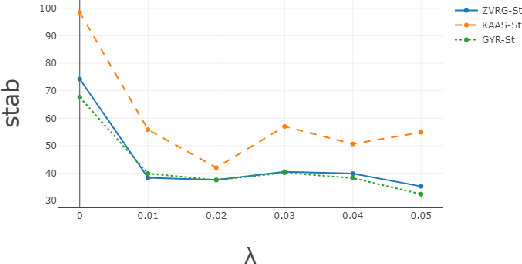
Fair classification has been a topic of intense study in machine learning, and several algorithms have been proposed towards this important task. However, in a recent study, Friedler et al. observed that fair classification algorithms may not be stable with respect to variations in the training dataset -- a crucial consideration in several real-world applications. Motivated by their work, we study the problem of designing classification algorithms that are both fair and stable. We propose an extended framework based on fair classification algorithms that are formulated as optimization problems, by introducing a stability-focused regularization term. Theoretically, we prove a stability guarantee, that was lacking in fair classification algorithms, and also provide an accuracy guarantee for our extended framework. Our accuracy guarantee can be used to inform the selection of the regularization parameter in our framework. To the best of our knowledge, this is the first work that combines stability and fairness in automated decision-making tasks. We assess the benefits of our approach empirically by extending several fair classification algorithms that are shown to achieve the best balance between fairness and accuracy over the Adult dataset. Our empirical results show that our framework indeed improves the stability at only a slight sacrifice in accuracy.
Classification with Fairness Constraints: A Meta-Algorithm with Provable Guarantees
Aug 02, 2018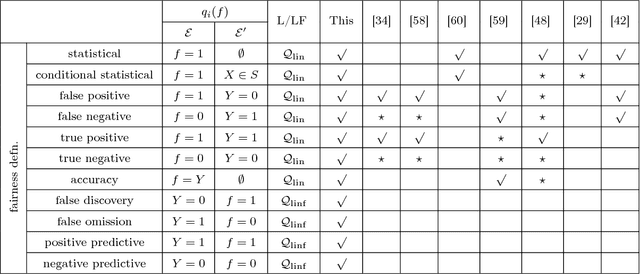
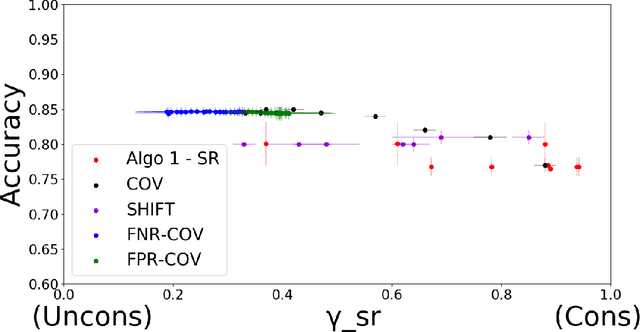
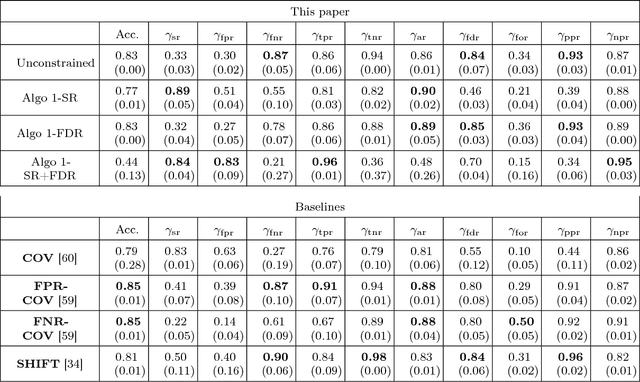
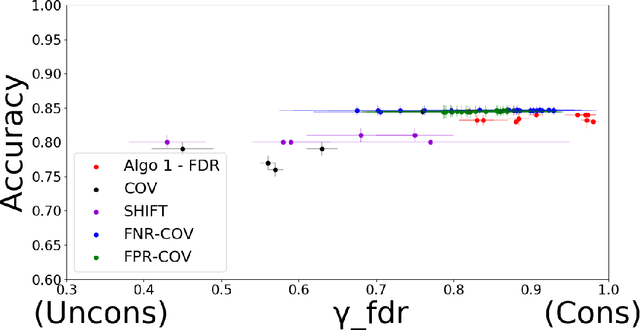
Developing classification algorithms that are fair with respect to sensitive attributes of the data has become an important problem due to the growing deployment of classification algorithms in various social contexts. Several recent works have focused on fairness with respect to a specific metric, modeled the corresponding fair classification problem as a constrained optimization problem, and developed tailored algorithms to solve them. Despite this, there still remain important metrics for which we do not have fair classifiers and many of the aforementioned algorithms do not come with theoretical guarantees; perhaps because the resulting optimization problem is non-convex. The main contribution of this paper is a new meta-algorithm for classification that takes as input a large class of fairness constraints, with respect to multiple non-disjoint sensitive attributes, and which comes with provable guarantees. This is achieved by first developing a meta-algorithm for a large family of classification problems with convex constraints, and then showing that classification problems with general types of fairness constraints can be reduced to those in this family. We present empirical results that show that our algorithm can achieve near-perfect fairness with respect to various fairness metrics, and that the loss in accuracy due to the imposed fairness constraints is often small. Overall, this work unifies several prior works on fair classification, presents a practical algorithm with theoretical guarantees, and can handle fairness metrics that were previously not possible.
Multiwinner Voting with Fairness Constraints
Jun 18, 2018

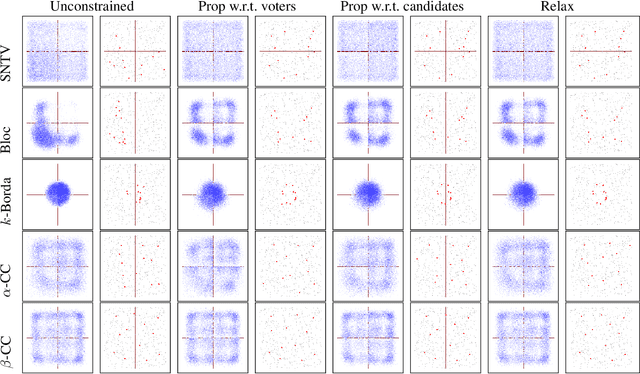

Multiwinner voting rules are used to select a small representative subset of candidates or items from a larger set given the preferences of voters. However, if candidates have sensitive attributes such as gender or ethnicity (when selecting a committee), or specified types such as political leaning (when selecting a subset of news items), an algorithm that chooses a subset by optimizing a multiwinner voting rule may be unbalanced in its selection -- it may under or over represent a particular gender or political orientation in the examples above. We introduce an algorithmic framework for multiwinner voting problems when there is an additional requirement that the selected subset should be "fair" with respect to a given set of attributes. Our framework provides the flexibility to (1) specify fairness with respect to multiple, non-disjoint attributes (e.g., ethnicity and gender) and (2) specify a score function. We study the computational complexity of this constrained multiwinner voting problem for monotone and submodular score functions and present several approximation algorithms and matching hardness of approximation results for various attribute group structure and types of score functions. We also present simulations that suggest that adding fairness constraints may not affect the scores significantly when compared to the unconstrained case.
SVM via Saddle Point Optimization: New Bounds and Distributed Algorithms
Jan 28, 2018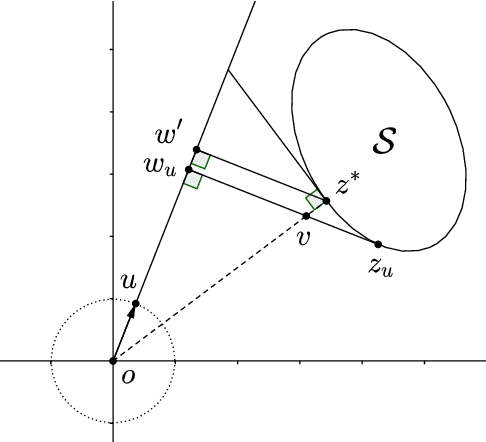
We study two important SVM variants: hard-margin SVM (for linearly separable cases) and $\nu$-SVM (for linearly non-separable cases). We propose new algorithms from the perspective of saddle point optimization. Our algorithms achieve $(1-\epsilon)$-approximations with running time $\tilde{O}(nd+n\sqrt{d / \epsilon})$ for both variants, where $n$ is the number of points and $d$ is the dimensionality. To the best of our knowledge, the current best algorithm for $\nu$-SVM is based on quadratic programming approach which requires $\Omega(n^2 d)$ time in worst case~\cite{joachims1998making,platt199912}. In the paper, we provide the first nearly linear time algorithm for $\nu$-SVM. The current best algorithm for hard margin SVM achieved by Gilbert algorithm~\cite{gartner2009coresets} requires $O(nd / \epsilon )$ time. Our algorithm improves the running time by a factor of $\sqrt{d}/\sqrt{\epsilon}$. Moreover, our algorithms can be implemented in the distributed settings naturally. We prove that our algorithms require $\tilde{O}(k(d +\sqrt{d/\epsilon}))$ communication cost, where $k$ is the number of clients, which almost matches the theoretical lower bound. Numerical experiments support our theory and show that our algorithms converge faster on high dimensional, large and dense data sets, as compared to previous methods.