 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly-Economized Multi-View Binary Compression for Scalable Image Clustering
Sep 17, 2018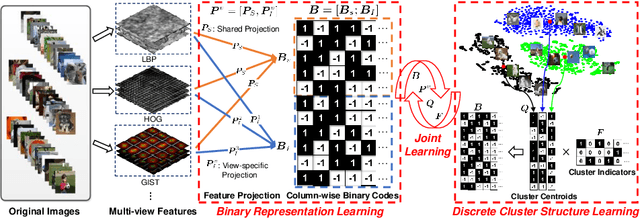
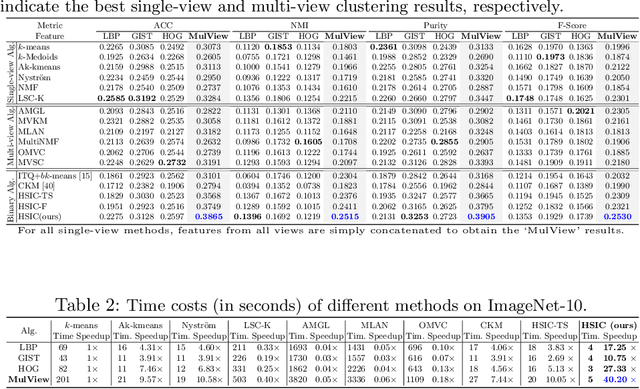
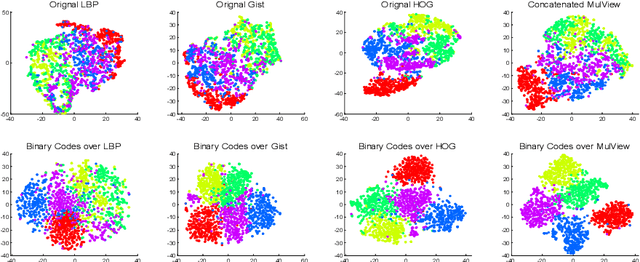
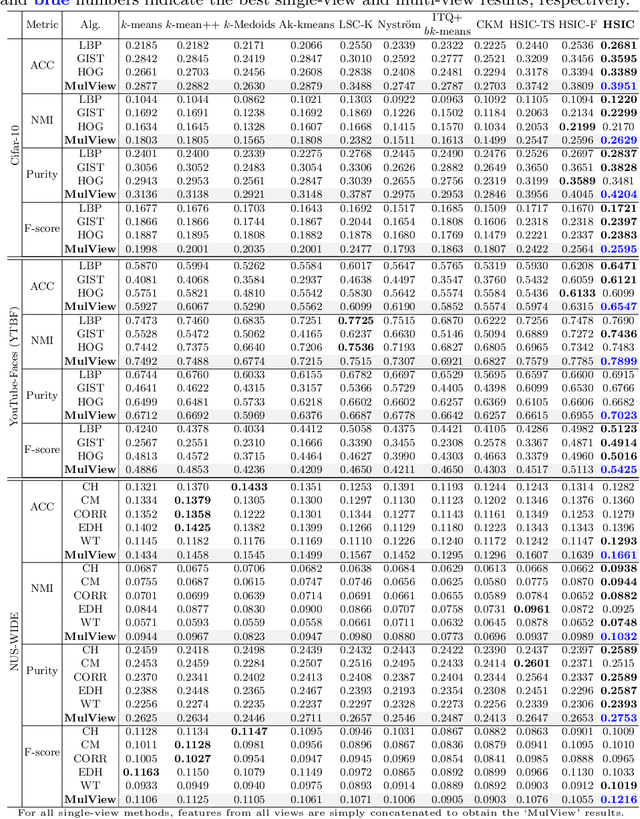
How to economically cluster large-scale multi-view images is a long-standing problem in computer vision. To tackle this challenge, we introduce a novel approach named Highly-economized Scalable Image Clustering (HSIC) that radically surpasses conventional image clustering methods via binary compression. We intuitively unify the binary representation learning and efficient binary cluster structure learning into a joint framework. In particular, common binary representations are learned by exploiting both sharable and individual information across multiple views to capture their underlying correlations. Meanwhile, cluster assignment with robust binary centroids is also performed via effective discrete optimization under L21-norm constraint. By this means, heavy continuous-valued Euclidean distance computations can be successfully reduced by efficient binary XOR operations during the clustering procedure. To our best knowledge, HSIC is the first binary clustering work specifically designed for scalable multi-view image clustering. Extensive experimental results on four large-scale image datasets show that HSIC consistently outperforms the state-of-the-art approaches, whilst significantly reducing computational time and memory footprint.
Pixel-level Semantics Guided Image Colorization
Aug 05, 2018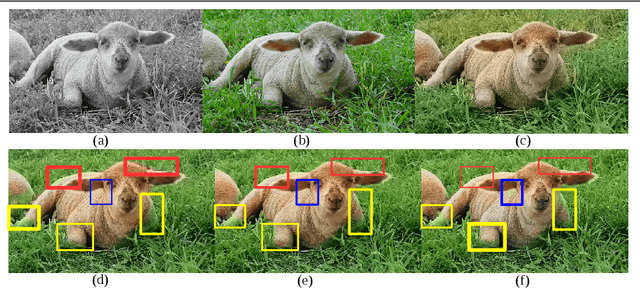

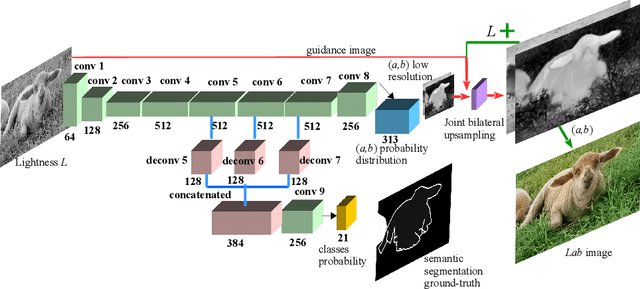
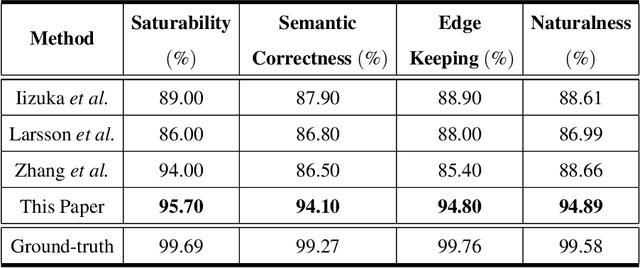
While many image colorization algorithms have recently shown the capability of producing plausible color versions from gray-scale photographs, they still suffer from the problems of context confusion and edge color bleeding. To address context confusion, we propose to incorporate the pixel-level object semantics to guide the image colorization. The rationale is that human beings perceive and distinguish colors based on the object's semantic categories. We propose a hierarchical neural network with two branches. One branch learns what the object is while the other branch learns the object's colors. The network jointly optimizes a semantic segmentation loss and a colorization loss. To attack edge color bleeding we generate more continuous color maps with sharp edges by adopting a joint bilateral upsamping layer at inference. Our network is trained on PASCAL VOC2012 and COCO-stuff with semantic segmentation labels and it produces more realistic and finer results compared to the colorization state-of-the-art.
Towards Universal Representation for Unseen Action Recognition
Mar 22, 2018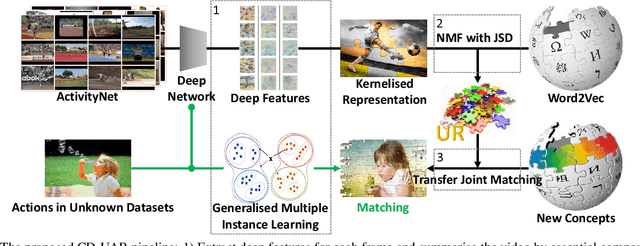
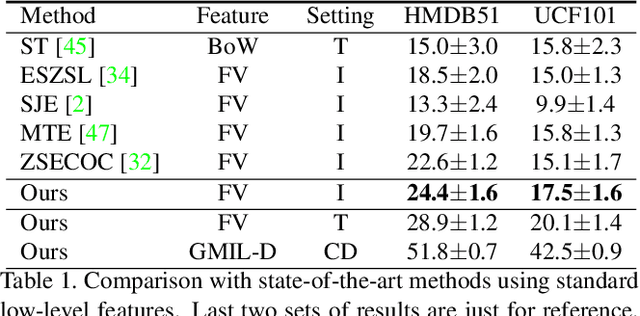

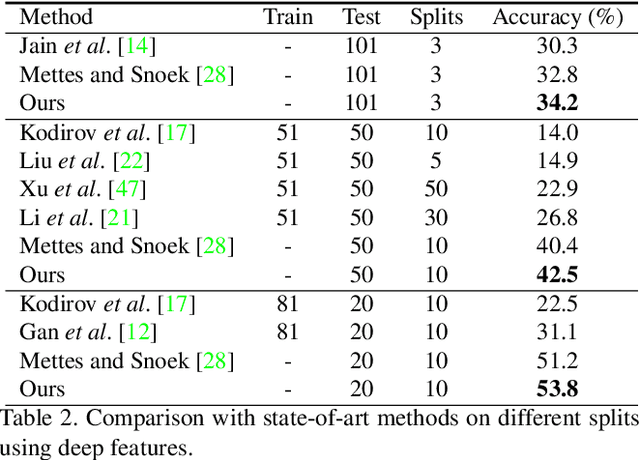
Unseen Action Recognition (UAR) aims to recognise novel action categories without training examples. While previous methods focus on inner-dataset seen/unseen splits, this paper proposes a pipeline using a large-scale training source to achieve a Universal Representation (UR) that can generalise to a more realistic Cross-Dataset UAR (CD-UAR) scenario. We first address UAR as a Generalised Multiple-Instance Learning (GMIL) problem and discover 'building-blocks' from the large-scale ActivityNet dataset using distribution kernels. Essential visual and semantic components are preserved in a shared space to achieve the UR that can efficiently generalise to new datasets. Predicted UR exemplars can be improved by a simple semantic adaptation, and then an unseen action can be directly recognised using UR during the test. Without further training, extensive experiments manifest significant improvements over the UCF101 and HMDB51 benchmarks.
Zero-Shot Sketch-Image Hashing
Mar 06, 2018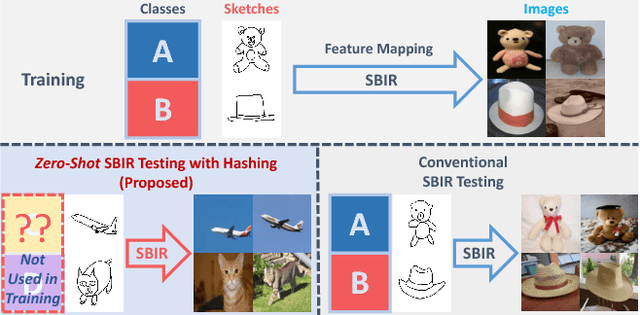
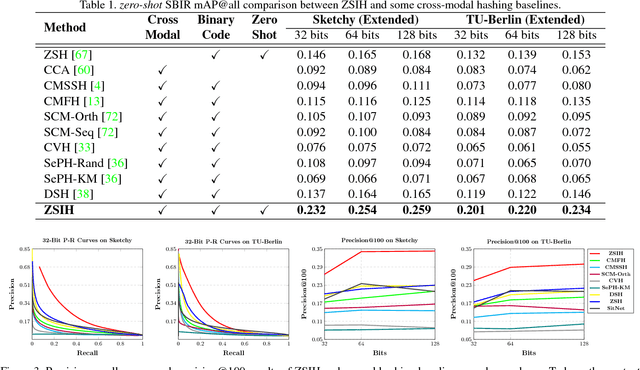
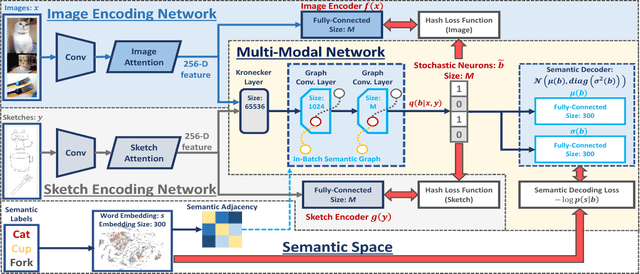
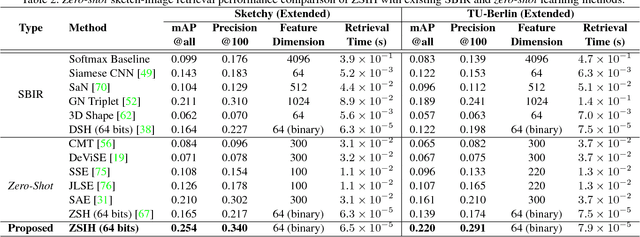
Recent studies show that large-scale sketch-based image retrieval (SBIR) can be efficiently tackled by cross-modal binary representation learning methods, where Hamming distance matching significantly speeds up the process of similarity search. Providing training and test data subjected to a fixed set of pre-defined categories, the cutting-edge SBIR and cross-modal hashing works obtain acceptable retrieval performance. However, most of the existing methods fail when the categories of query sketches have never been seen during training. In this paper, the above problem is briefed as a novel but realistic zero-shot SBIR hashing task. We elaborate the challenges of this special task and accordingly propose a zero-shot sketch-image hashing (ZSIH) model. An end-to-end three-network architecture is built, two of which are treated as the binary encoders. The third network mitigates the sketch-image heterogeneity and enhances the semantic relations among data by utilizing the Kronecker fusion layer and graph convolution, respectively. As an important part of ZSIH, we formulate a generative hashing scheme in reconstructing semantic knowledge representations for zero-shot retrieval. To the best of our knowledge, ZSIH is the first zero-shot hashing work suitable for SBIR and cross-modal search. Comprehensive experiments are conducted on two extended datasets, i.e., Sketchy and TU-Berlin with a novel zero-shot train-test split. The proposed model remarkably outperforms related works.
Video Salient Object Detection via Fully Convolutional Networks
Dec 09, 2017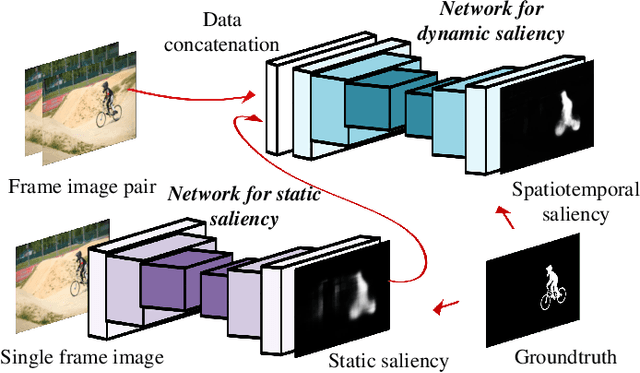
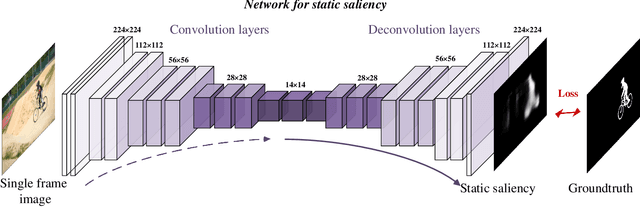
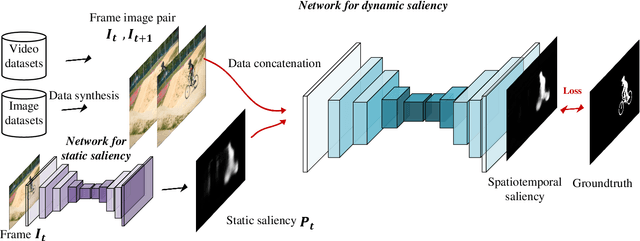

This paper proposes a deep learning model to efficiently detect salient regions in videos. It addresses two important issues: (1) deep video saliency model training with the absence of sufficiently large and pixel-wise annotated video data, and (2) fast video saliency training and detection. The proposed deep video saliency network consists of two modules, for capturing the spatial and temporal saliency information, respectively. The dynamic saliency model, explicitly incorporating saliency estimates from the static saliency model, directly produces spatiotemporal saliency inference without time-consuming optical flow computation. We further propose a novel data augmentation technique that simulates video training data from existing annotated image datasets, which enables our network to learn diverse saliency information and prevents overfitting with the limited number of training videos. Leveraging our synthetic video data (150K video sequences) and real videos, our deep video saliency model successfully learns both spatial and temporal saliency cues, thus producing accurate spatiotemporal saliency estimate. We advance the state-of-the-art on the DAVIS dataset (MAE of .06) and the FBMS dataset (MAE of .07), and do so with much improved speed (2fps with all steps).
* W. Wang, J. Shen, and L. Shao, Video salient object detection via fully convolutional networks, IEEE Trans. on Image Processing, 27(1):38-49, 2018 Code and results: https://github.com/wenguanwang/deepvideosaliency
Dual-reference Face Retrieval
Nov 22, 2017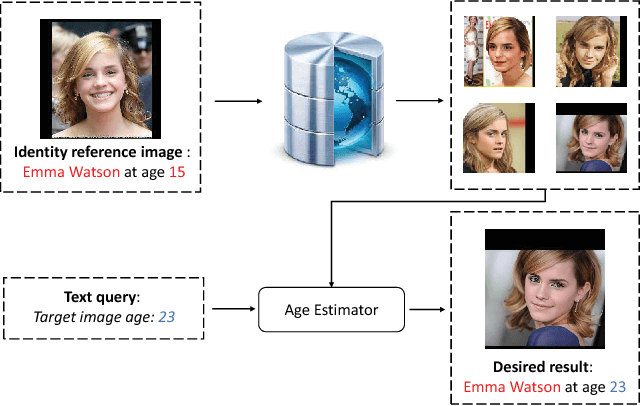
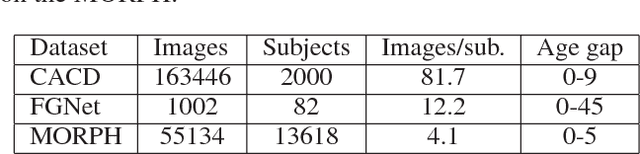

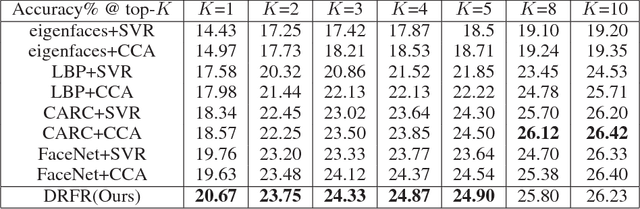
Face retrieval has received much attention over the past few decades, and many efforts have been made in retrieving face images against pose, illumination, and expression variations. However, the conventional works fail to meet the requirements of a potential and novel task --- retrieving a person's face image at a specific age, especially when the specific 'age' is not given as a numeral, i.e. 'retrieving someone's image at the similar age period shown by another person's image'. To tackle this problem, we propose a dual reference face retrieval framework in this paper, where the system takes two inputs: an identity reference image which indicates the target identity and an age reference image which reflects the target age. In our framework, the raw images are first projected on a joint manifold, which preserves both the age and identity locality. Then two similarity metrics of age and identity are exploited and optimized by utilizing our proposed quartet-based model. The experiments show promising results, outperforming hierarchical methods.
Latent Constrained Correlation Filter
Nov 11, 2017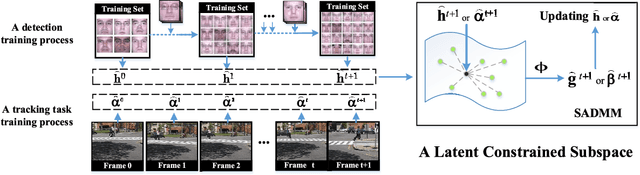
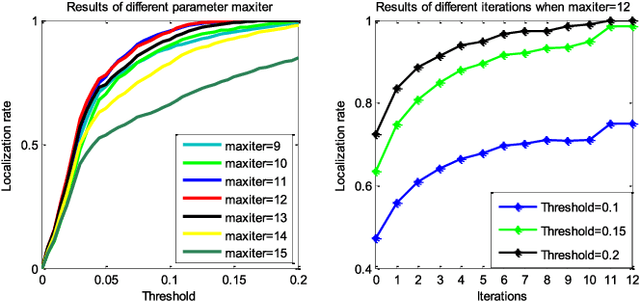
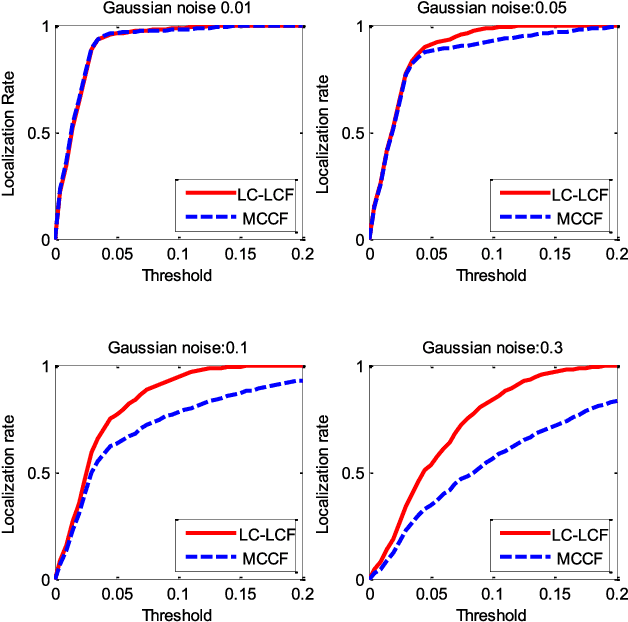
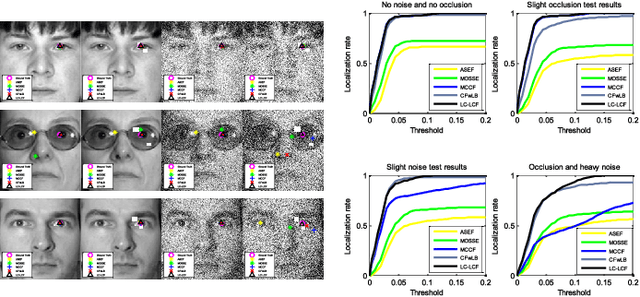
Correlation filters are special classifiers designed for shift-invariant object recognition, which are robust to pattern distortions. The recent literature shows that combining a set of sub-filters trained based on a single or a small group of images obtains the best performance. The idea is equivalent to estimating variable distribution based on the data sampling (bagging), which can be interpreted as finding solutions (variable distribution approximation) directly from sampled data space. However, this methodology fails to account for the variations existed in the data. In this paper, we introduce an intermediate step -- solution sampling -- after the data sampling step to form a subspace, in which an optimal solution can be estimated. More specifically, we propose a new method, named latent constrained correlation filters (LCCF), by mapping the correlation filters to a given latent subspace, and develop a new learning framework in the latent subspace that embeds distribution-related constraints into the original problem. To solve the optimization problem, we introduce a subspace based alternating direction method of multipliers (SADMM), which is proven to converge at the saddle point. Our approach is successfully applied to three different tasks, including eye localization, car detection and object tracking. Extensive experiments demonstrate that LCCF outperforms the state-of-the-art methods. The source code will be publicly available. https://github.com/bczhangbczhang/.
Deep Binaries: Encoding Semantic-Rich Cues for Efficient Textual-Visual Cross Retrieval
Aug 08, 2017



Cross-modal hashing is usually regarded as an effective technique for large-scale textual-visual cross retrieval, where data from different modalities are mapped into a shared Hamming space for matching. Most of the traditional textual-visual binary encoding methods only consider holistic image representations and fail to model descriptive sentences. This renders existing methods inappropriate to handle the rich semantics of informative cross-modal data for quality textual-visual search tasks. To address the problem of hashing cross-modal data with semantic-rich cues, in this paper, a novel integrated deep architecture is developed to effectively encode the detailed semantics of informative images and long descriptive sentences, named as Textual-Visual Deep Binaries (TVDB). In particular, region-based convolutional networks with long short-term memory units are introduced to fully explore image regional details while semantic cues of sentences are modeled by a text convolutional network. Additionally, we propose a stochastic batch-wise training routine, where high-quality binary codes and deep encoding functions are efficiently optimized in an alternating manner. Experiments are conducted on three multimedia datasets, i.e. Microsoft COCO, IAPR TC-12, and INRIA Web Queries, where the proposed TVDB model significantly outperforms state-of-the-art binary coding methods in the task of cross-modal retrieval.
Discriminative Block-Diagonal Representation Learning for Image Recognition
Jul 12, 2017
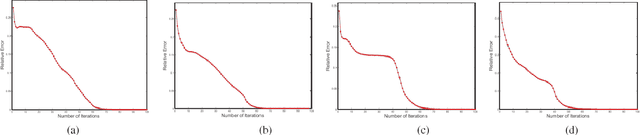
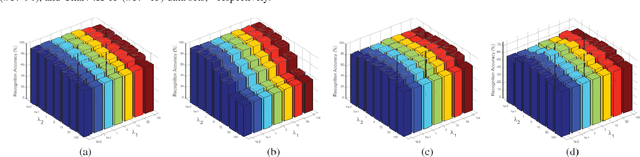
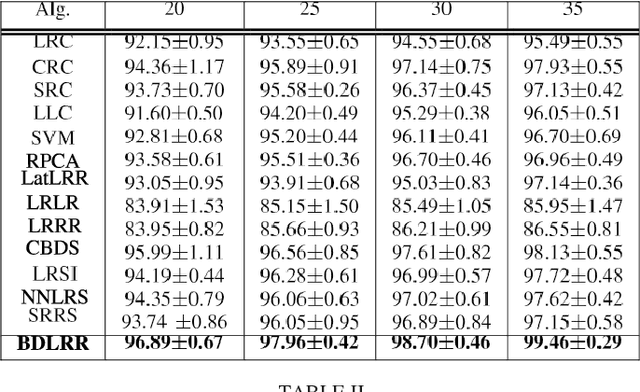
Existing block-diagonal representation researches mainly focuses on casting block-diagonal regularization on training data, while only little attention is dedicated to concurrently learning both block-diagonal representations of training and test data. In this paper, we propose a discriminative block-diagonal low-rank representation (BDLRR) method for recognition. In particular, the elaborate BDLRR is formulated as a joint optimization problem of shrinking the unfavorable representation from off-block-diagonal elements and strengthening the compact block-diagonal representation under the semi-supervised framework of low-rank representation. To this end, we first impose penalty constraints on the negative representation to eliminate the correlation between different classes such that the incoherence criterion of the extra-class representation is boosted. Moreover, a constructed subspace model is developed to enhance the self-expressive power of training samples and further build the representation bridge between the training and test samples, such that the coherence of the learned intra-class representation is consistently heightened. Finally, the resulting optimization problem is solved elegantly by employing an alternative optimization strategy, and a simple recognition algorithm on the learned representation is utilized for final prediction. Extensive experimental results demonstrate that the proposed method achieves superb recognition results on four face image datasets, three character datasets, and the fifteen scene multi-categories dataset. It not only shows superior potential on image recognition but also outperforms state-of-the-art methods.
DOTE: Dual cOnvolutional filTer lEarning for Super-Resolution and Cross-Modality Synthesis in MRI
Jun 15, 2017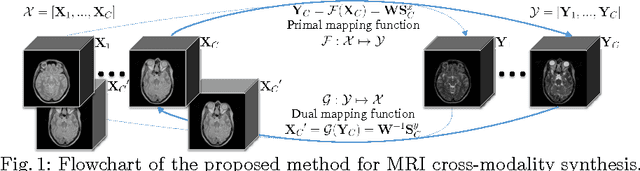
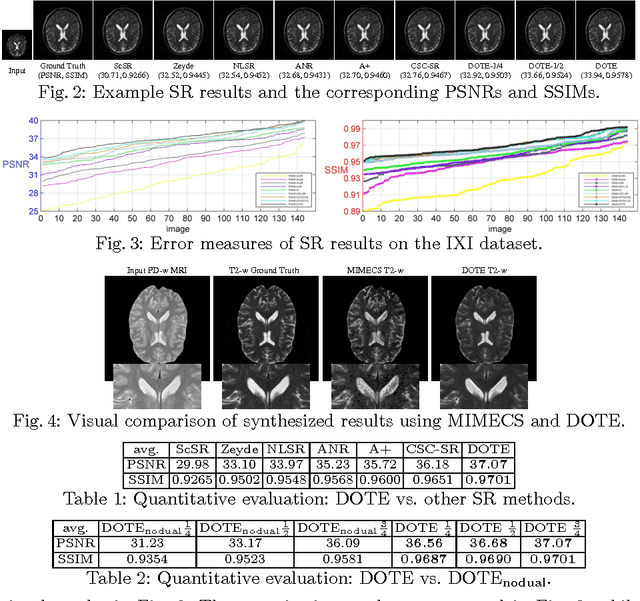
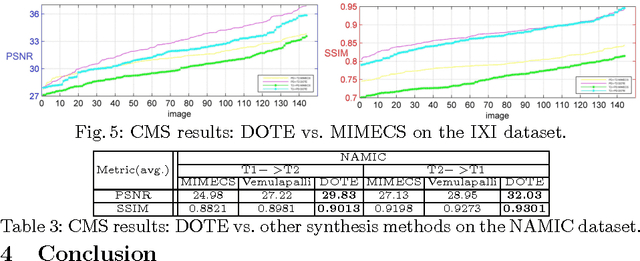
Cross-modal image synthesis is a topical problem in medical image computing. Existing methods for image synthesis are either tailored to a specific application, require large scale training sets, or are based on partitioning images into overlapping patches. In this paper, we propose a novel Dual cOnvolutional filTer lEarning (DOTE) approach to overcome the drawbacks of these approaches. We construct a closed loop joint filter learning strategy that generates informative feedback for model self-optimization. Our method can leverage data more efficiently thus reducing the size of the required training set. We extensively evaluate DOTE in two challenging tasks: image super-resolution and cross-modality synthesis. The experimental results demonstrate superior performance of our method over other state-of-the-art methods.