 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Speech Separation with Time-and-Frequency Cross-domain Joint Embedding and Clustering
Apr 16, 2019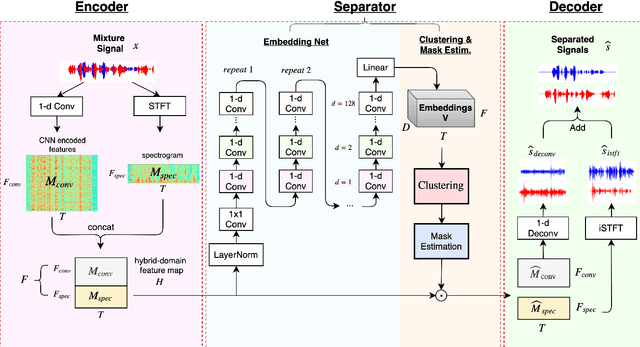
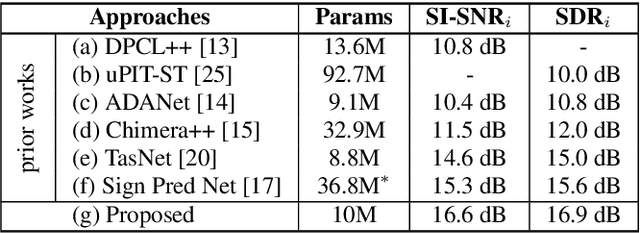
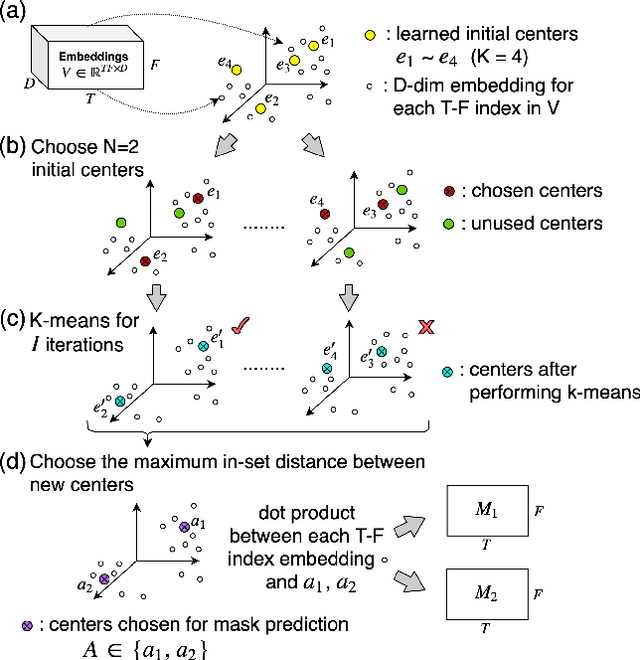
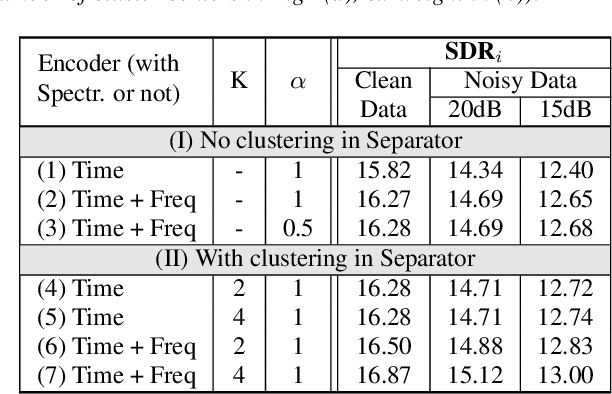
Speech separation has been very successful with deep learning techniques. Substantial effort has been reported based on approaches over spectrogram, which is well known as the standard time-and-frequency cross-domain representation for speech signals. It is highly correlated to the phonetic structure of speech, or "how the speech sounds" when perceived by human, but primarily frequency domain features carrying temporal behaviour. Very impressive work achieving speech separation over time domain was reported recently, probably because waveforms in time domain may describe the different realizations of speech in a more precise way than spectrogram. In this paper, we propose a framework properly integrating the above two directions, hoping to achieve both purposes. We construct a time-and-frequency feature map by concatenating the 1-dim convolution encoded feature map (for time domain) and the spectrogram (for frequency domain), which was then processed by an embedding network and clustering approaches very similar to those used in time and frequency domain prior works. In this way, the information in the time and frequency domains, as well as the interactions between them, can be jointly considered during embedding and clustering. Very encouraging results (state-of-the-art to our knowledge) were obtained with WSJ0-2mix dataset in preliminary experiments.
From Semi-supervised to Almost-unsupervised Speech Recognition with Very-low Resource by Jointly Learning Phonetic Structures from Audio and Text Embeddings
Apr 10, 2019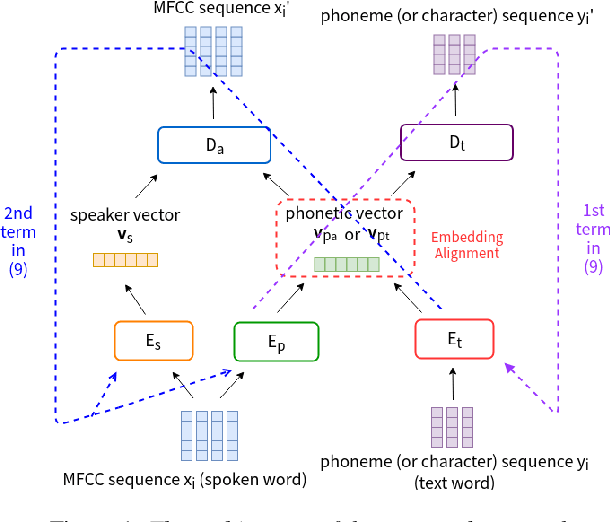
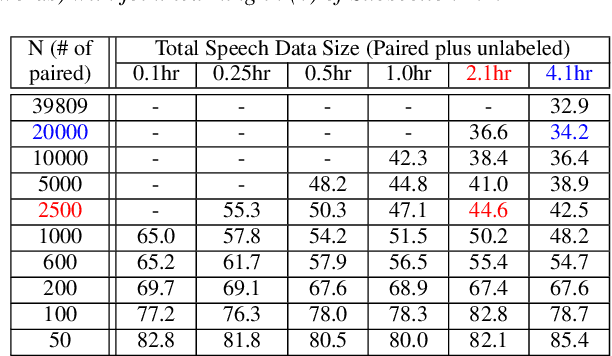
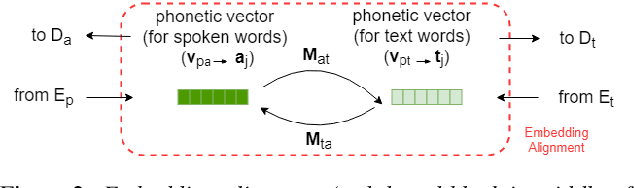

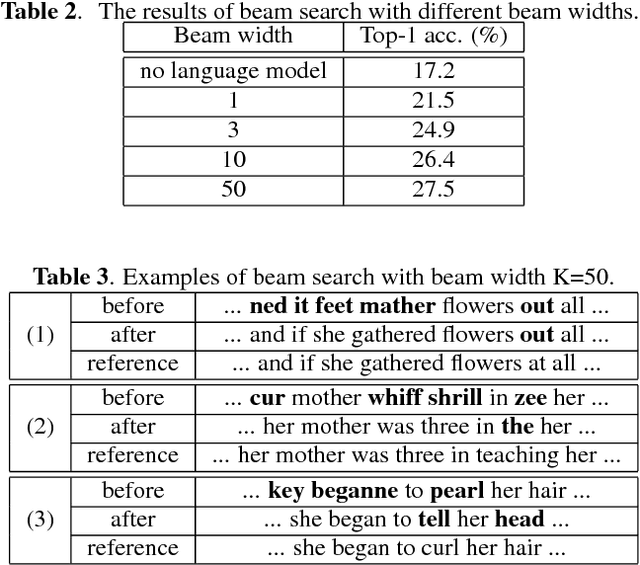
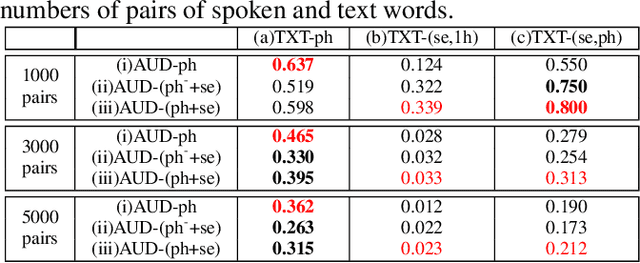
Producing a large amount of annotated speech data for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced. However, we note human babies start to learn the language by the sounds (or phonetic structures) of a small number of exemplar words, and "generalize" such knowledge to other words without hearing a large amount of data. We initiate some preliminary work in this direction. Audio Word2Vec is used to learn the phonetic structures from spoken words (signal segments), while another autoencoder is used to learn the phonetic structures from text words. The relationships among the above two can be learned jointly, or separately after the above two are well trained. This relationship can be used in speech recognition with very low resource. In the initial experiments on the TIMIT dataset, only 2.1 hours of speech data (in which 2500 spoken words were annotated and the rest unlabeled) gave a word error rate of 44.6%, and this number can be reduced to 34.2% if 4.1 hr of speech data (in which 20000 spoken words were annotated) were given. These results are not satisfactory, but a good starting point.
Completely Unsupervised Phoneme Recognition By A Generative Adversarial Network Harmonized With Iteratively Refined Hidden Markov Models
Apr 08, 2019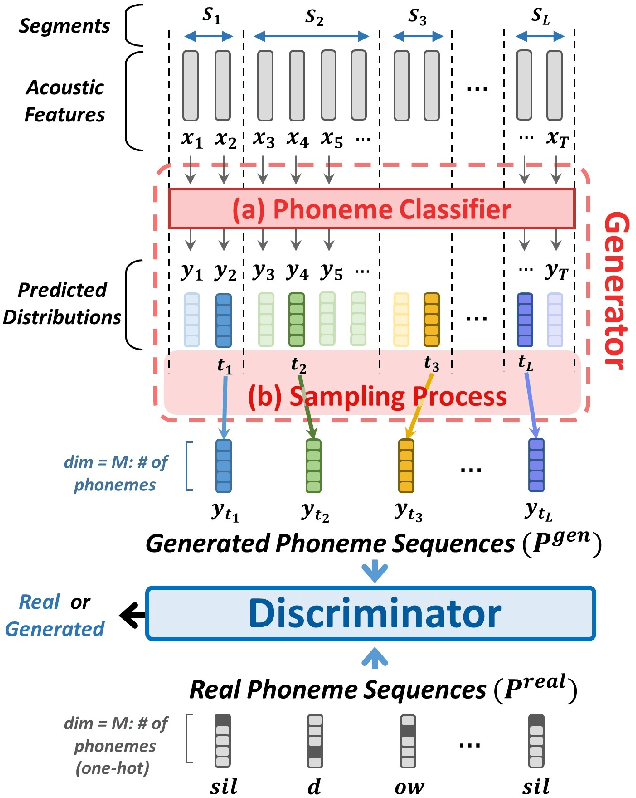
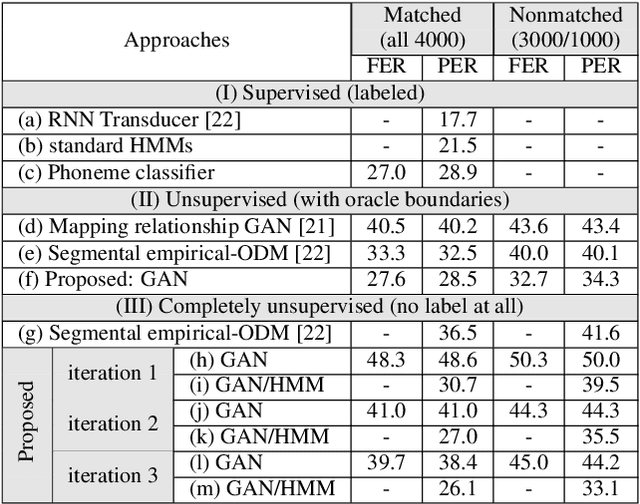
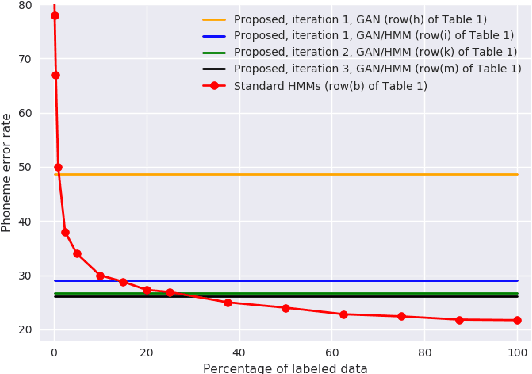
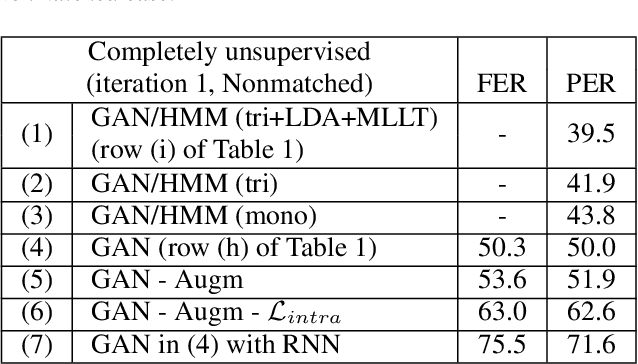
Producing a large annotated speech corpus for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced, but collecting a relatively big unlabeled data set for such languages is more achievable. This is why some initial effort have been reported on completely unsupervised speech recognition learned from unlabeled data only, although with relatively high error rates. In this paper, we develop a Generative Adversarial Network (GAN) to achieve this purpose, in which a Generator and a Discriminator learn from each other iteratively to improve the performance. We further use a set of Hidden Markov Models (HMMs) iteratively refined from the machine generated labels to work in harmony with the GAN. The initial experiments on TIMIT data set achieve an phone error rate of 33.1%, which is 8.5% lower than the previous state-of-the-art.
Improved Audio Embeddings by Adjacency-Based Clustering with Applications in Spoken Term Detection
Nov 07, 2018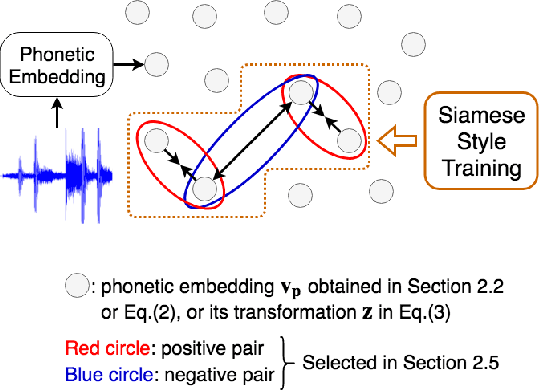
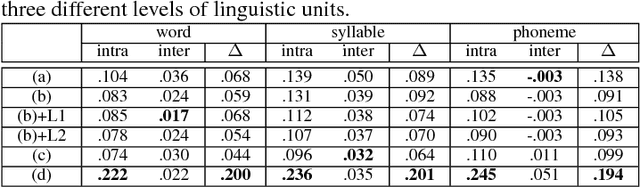
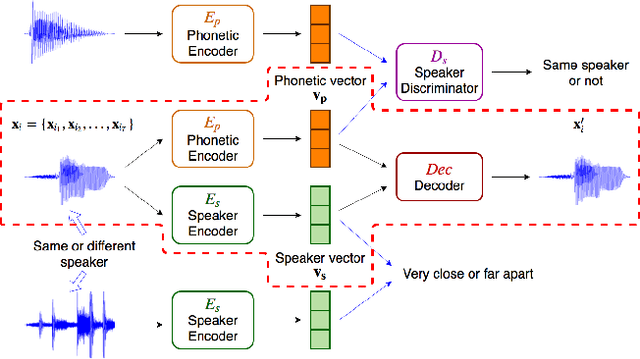

Embedding audio signal segments into vectors with fixed dimensionality is attractive because all following processing will be easier and more efficient, for example modeling, classifying or indexing. Audio Word2Vec previously proposed was shown to be able to represent audio segments for spoken words as such vectors carrying information about the phonetic structures of the signal segments. However, each linguistic unit (word, syllable, phoneme in text form) corresponds to unlimited number of audio segments with vector representations inevitably spread over the embedding space, which causes some confusion. It is therefore desired to better cluster the audio embeddings such that those corresponding to the same linguistic unit can be more compactly distributed. In this paper, inspired by Siamese networks, we propose some approaches to achieve the above goal. This includes identifying positive and negative pairs from unlabeled data for Siamese style training, disentangling acoustic factors such as speaker characteristics from the audio embedding, handling unbalanced data distribution, and having the embedding processes learn from the adjacency relationships among data points. All these can be done in an unsupervised way. Improved performance was obtained in preliminary experiments on the LibriSpeech data set, including clustering characteristics analysis and applications of spoken term detection.
Adversarial Training of End-to-end Speech Recognition Using a Criticizing Language Model
Nov 02, 2018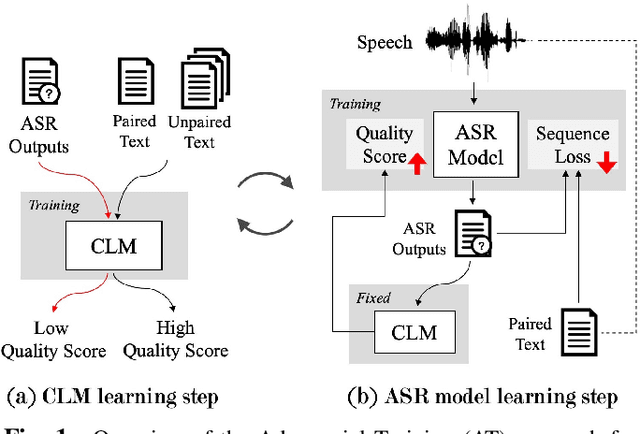
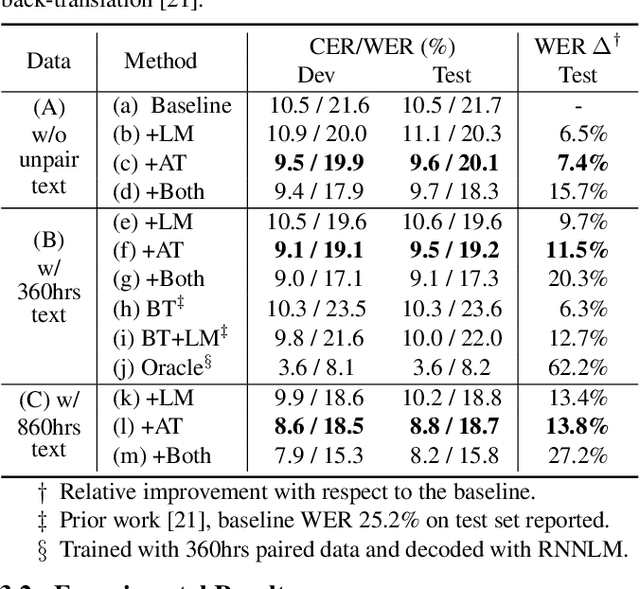
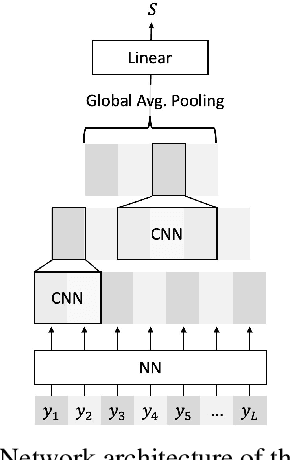
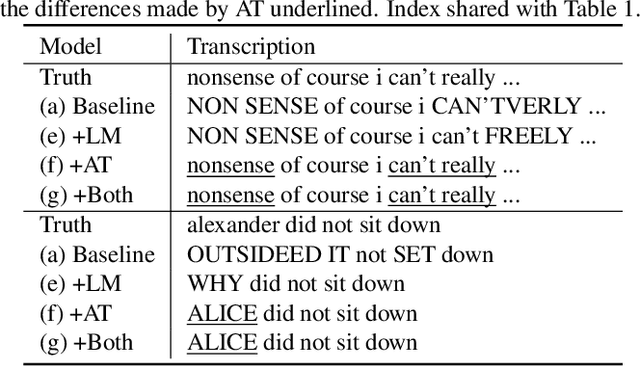
In this paper we proposed a novel Adversarial Training (AT) approach for end-to-end speech recognition using a Criticizing Language Model (CLM). In this way the CLM and the automatic speech recognition (ASR) model can challenge and learn from each other iteratively to improve the performance. Since the CLM only takes the text as input, huge quantities of unpaired text data can be utilized in this approach within end-to-end training. Moreover, AT can be applied to any end-to-end ASR model using any deep-learning-based language modeling frameworks, and compatible with any existing end-to-end decoding method. Initial results with an example experimental setup demonstrated the proposed approach is able to gain consistent improvements efficiently from auxiliary text data under different scenarios.
Almost-unsupervised Speech Recognition with Close-to-zero Resource Based on Phonetic Structures Learned from Very Small Unpaired Speech and Text Data
Oct 30, 2018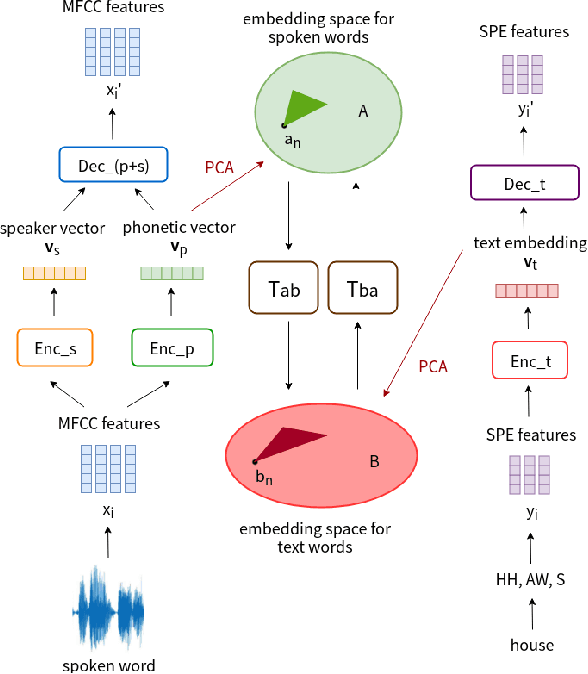
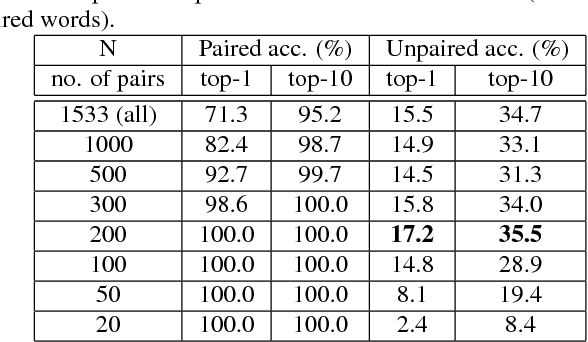
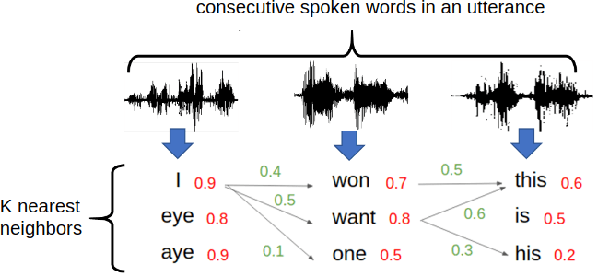
Producing a large amount of annotated speech data for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced. However, we note human babies start to learn the language by the sounds of a small number of exemplar words without hearing a large amount of data. We initiate some preliminary work in this direction in this paper. Audio Word2Vec is used to obtain embeddings of spoken words which carry phonetic information extracted from the signals. An autoencoder is used to generate embeddings of text words based on the articulatory features for the phoneme sequences. Both sets of embeddings for spoken and text words describe similar phonetic structures among words in their respective latent spaces. A mapping relation from the audio embeddings to text embeddings actually gives the word-level ASR. This can be learned by aligning a small number of spoken words and the corresponding text words in the embedding spaces. In the initial experiments only 200 annotated spoken words and one hour of speech data without annotation gave a word accuracy of 27.5%, which is low but a good starting point.
Phonetic-and-Semantic Embedding of Spoken Words with Applications in Spoken Content Retrieval
Sep 03, 2018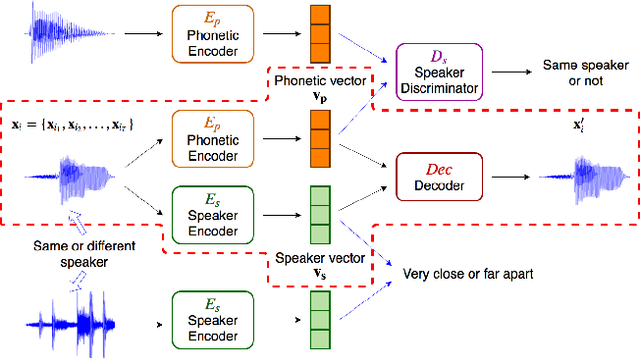
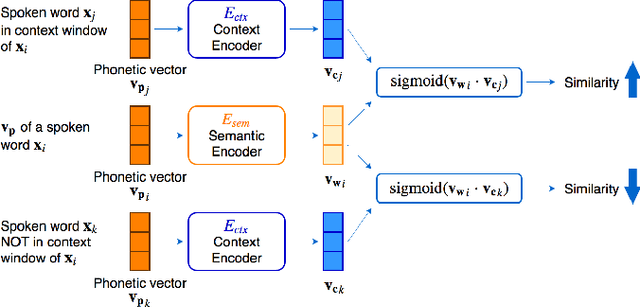
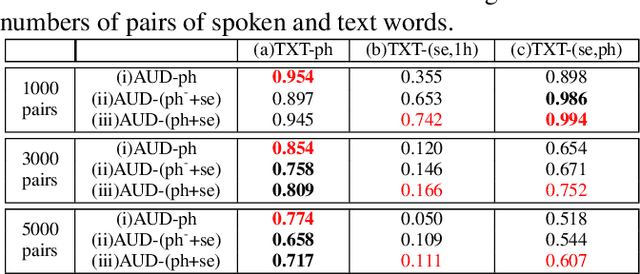
Word embedding or Word2Vec has been successful in offering semantics for text words learned from the context of words. Audio Word2Vec was shown to offer phonetic structures for spoken words (signal segments for words) learned from signals within spoken words. This paper proposes a two-stage framework to perform phonetic-and-semantic embedding on spoken words considering the context of the spoken words. Stage 1 performs phonetic embedding with speaker characteristics disentangled. Stage 2 then performs semantic embedding in addition. We further propose to evaluate the phonetic-and-semantic nature of the audio embeddings obtained in Stage 2 by parallelizing with text embeddings. In general, phonetic structure and semantics inevitably disturb each other. For example the words "brother" and "sister" are close in semantics but very different in phonetic structure, while the words "brother" and "bother" are in the other way around. But phonetic-and-semantic embedding is attractive, as shown in the initial experiments on spoken document retrieval. Not only spoken documents including the spoken query can be retrieved based on the phonetic structures, but spoken documents semantically related to the query but not including the query can also be retrieved based on the semantics.
Segmental Audio Word2Vec: Representing Utterances as Sequences of Vectors with Applications in Spoken Term Detection
Aug 07, 2018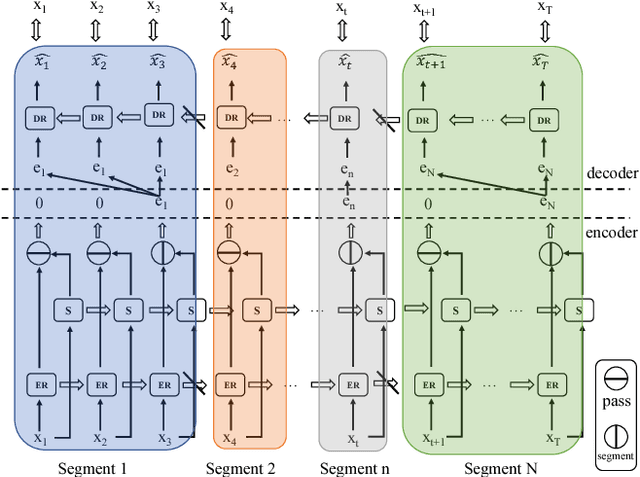

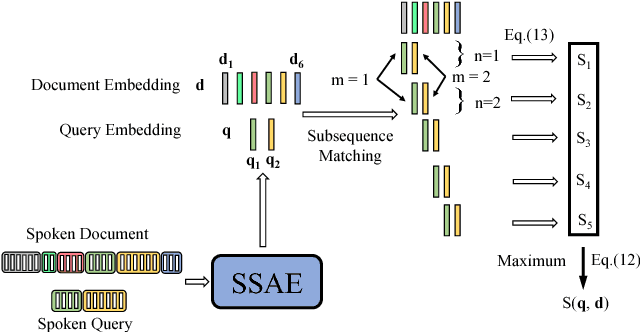
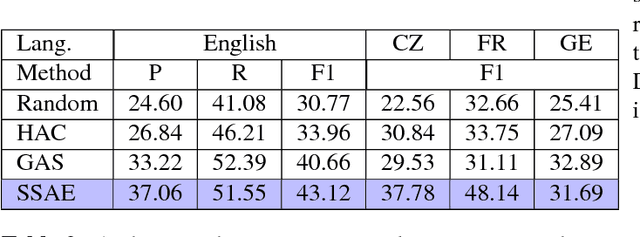
While Word2Vec represents words (in text) as vectors carrying semantic information, audio Word2Vec was shown to be able to represent signal segments of spoken words as vectors carrying phonetic structure information. Audio Word2Vec can be trained in an unsupervised way from an unlabeled corpus, except the word boundaries are needed. In this paper, we extend audio Word2Vec from word-level to utterance-level by proposing a new segmental audio Word2Vec, in which unsupervised spoken word boundary segmentation and audio Word2Vec are jointly learned and mutually enhanced, so an utterance can be directly represented as a sequence of vectors carrying phonetic structure information. This is achieved by a segmental sequence-to-sequence autoencoder (SSAE), in which a segmentation gate trained with reinforcement learning is inserted in the encoder. Experiments on English, Czech, French and German show very good performance in both unsupervised spoken word segmentation and spoken term detection applications (significantly better than frame-based DTW).
Multi-target Voice Conversion without Parallel Data by Adversarially Learning Disentangled Audio Representations
Jun 24, 2018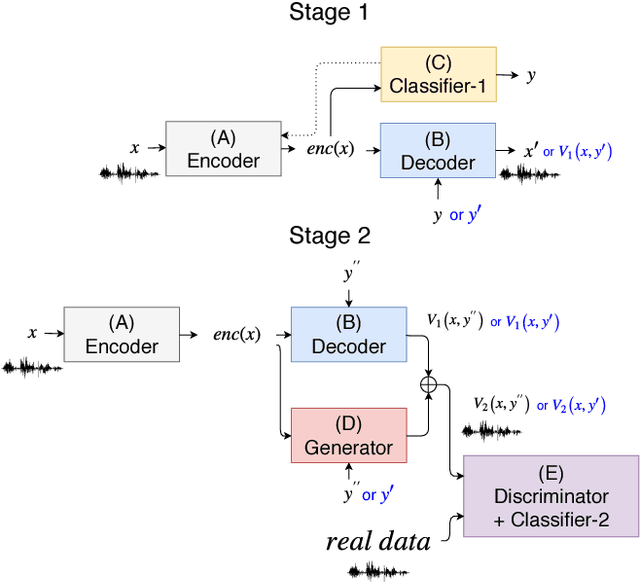
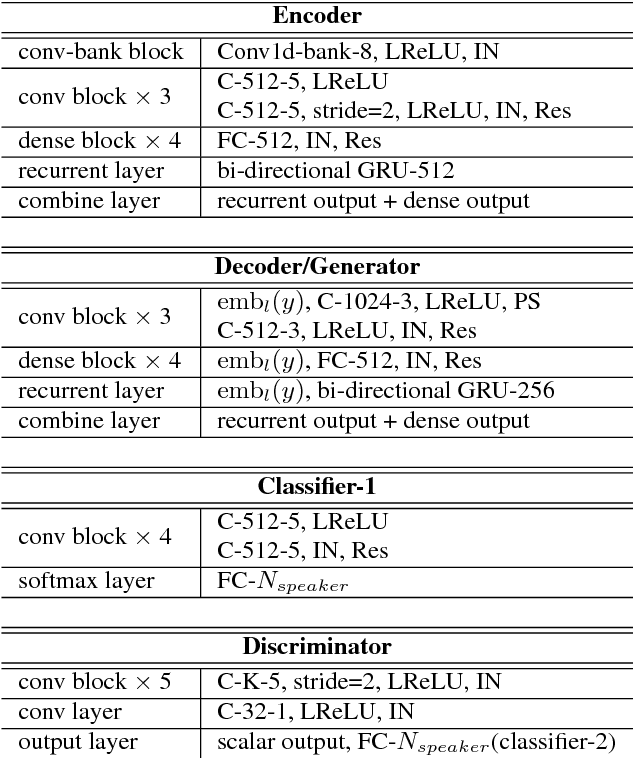
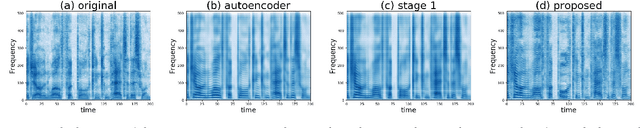
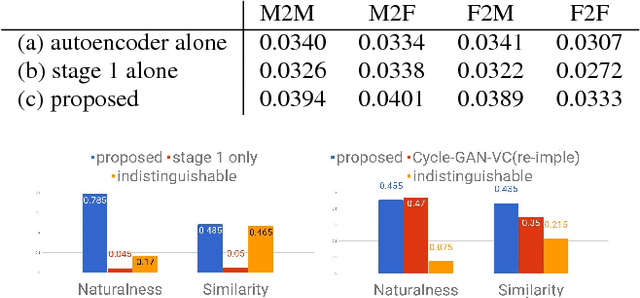
Recently, cycle-consistent adversarial network (Cycle-GAN) has been successfully applied to voice conversion to a different speaker without parallel data, although in those approaches an individual model is needed for each target speaker. In this paper, we propose an adversarial learning framework for voice conversion, with which a single model can be trained to convert the voice to many different speakers, all without parallel data, by separating the speaker characteristics from the linguistic content in speech signals. An autoencoder is first trained to extract speaker-independent latent representations and speaker embedding separately using another auxiliary speaker classifier to regularize the latent representation. The decoder then takes the speaker-independent latent representation and the target speaker embedding as the input to generate the voice of the target speaker with the linguistic content of the source utterance. The quality of decoder output is further improved by patching with the residual signal produced by another pair of generator and discriminator. A target speaker set size of 20 was tested in the preliminary experiments, and very good voice quality was obtained. Conventional voice conversion metrics are reported. We also show that the speaker information has been properly reduced from the latent representations.
Transcribing Lyrics From Commercial Song Audio: The First Step Towards Singing Content Processing
Apr 15, 2018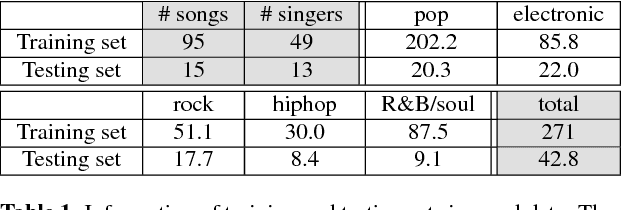
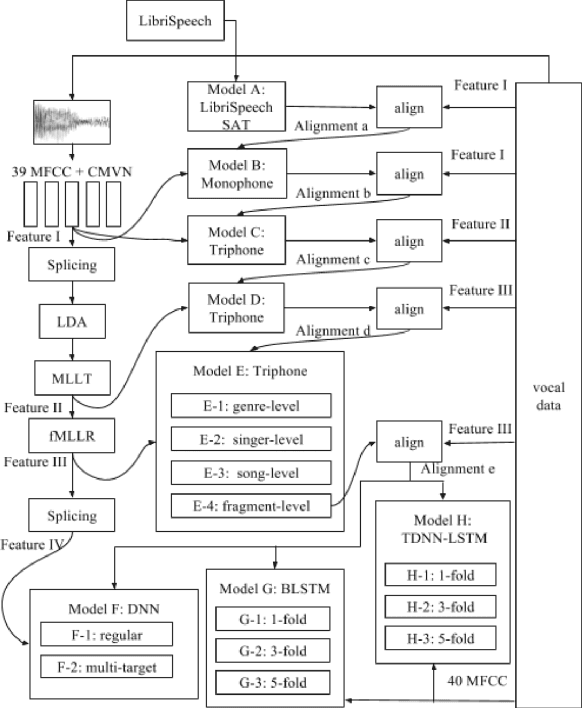
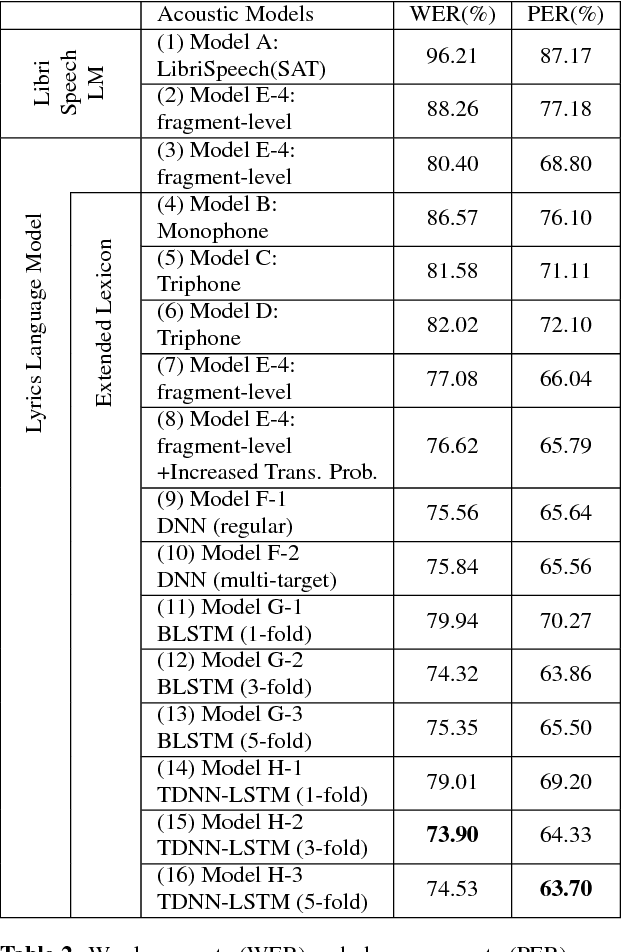
Spoken content processing (such as retrieval and browsing) is maturing, but the singing content is still almost completely left out. Songs are human voice carrying plenty of semantic information just as speech, and may be considered as a special type of speech with highly flexible prosody. The various problems in song audio, for example the significantly changing phone duration over highly flexible pitch contours, make the recognition of lyrics from song audio much more difficult. This paper reports an initial attempt towards this goal. We collected music-removed version of English songs directly from commercial singing content. The best results were obtained by TDNN-LSTM with data augmentation with 3-fold speed perturbation plus some special approaches. The WER achieved (73.90%) was significantly lower than the baseline (96.21%), but still relatively high.