 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBSQ: Exploring Bit-Level Sparsity for Mixed-Precision Neural Network Quantization
Feb 20, 2021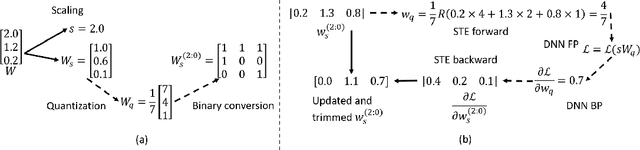

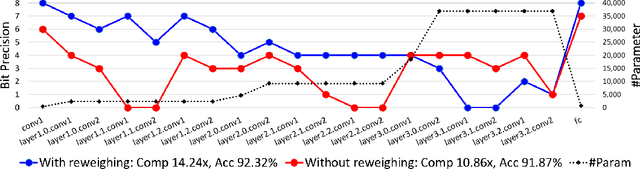
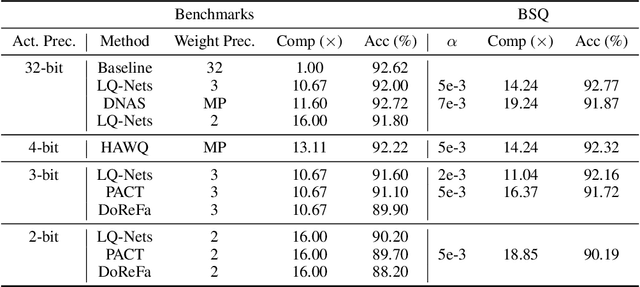
Mixed-precision quantization can potentially achieve the optimal tradeoff between performance and compression rate of deep neural networks, and thus, have been widely investigated. However, it lacks a systematic method to determine the exact quantization scheme. Previous methods either examine only a small manually-designed search space or utilize a cumbersome neural architecture search to explore the vast search space. These approaches cannot lead to an optimal quantization scheme efficiently. This work proposes bit-level sparsity quantization (BSQ) to tackle the mixed-precision quantization from a new angle of inducing bit-level sparsity. We consider each bit of quantized weights as an independent trainable variable and introduce a differentiable bit-sparsity regularizer. BSQ can induce all-zero bits across a group of weight elements and realize the dynamic precision reduction, leading to a mixed-precision quantization scheme of the original model. Our method enables the exploration of the full mixed-precision space with a single gradient-based optimization process, with only one hyperparameter to tradeoff the performance and compression. BSQ achieves both higher accuracy and higher bit reduction on various model architectures on the CIFAR-10 and ImageNet datasets comparing to previous methods.
LotteryFL: Personalized and Communication-Efficient Federated Learning with Lottery Ticket Hypothesis on Non-IID Datasets
Aug 07, 2020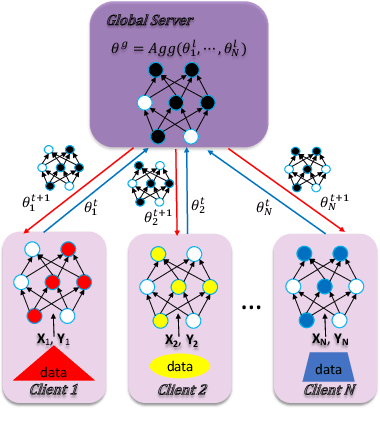
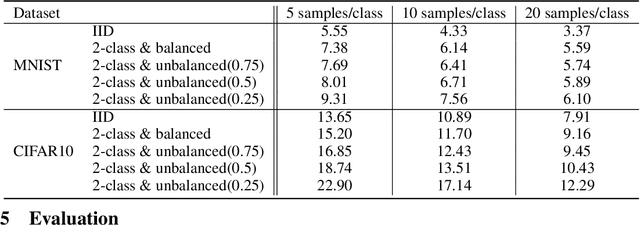
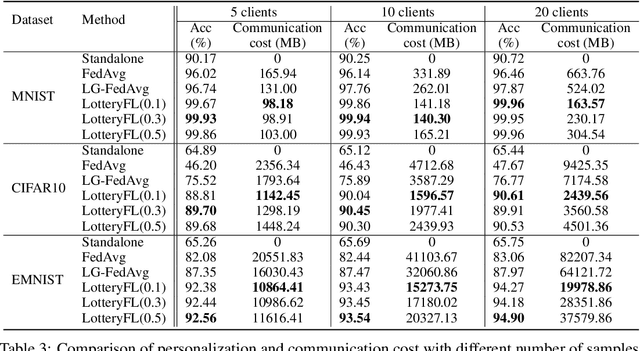
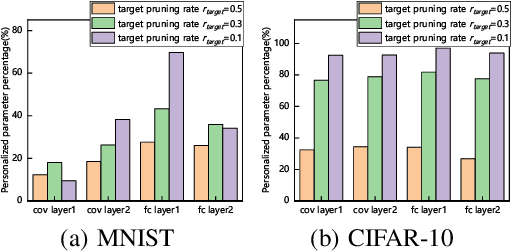
Federated learning is a popular distributed machine learning paradigm with enhanced privacy. Its primary goal is learning a global model that offers good performance for the participants as many as possible. The technology is rapidly advancing with many unsolved challenges, among which statistical heterogeneity (i.e., non-IID) and communication efficiency are two critical ones that hinder the development of federated learning. In this work, we propose LotteryFL -- a personalized and communication-efficient federated learning framework via exploiting the Lottery Ticket hypothesis. In LotteryFL, each client learns a lottery ticket network (i.e., a subnetwork of the base model) by applying the Lottery Ticket hypothesis, and only these lottery networks will be communicated between the server and clients. Rather than learning a shared global model in classic federated learning, each client learns a personalized model via LotteryFL; the communication cost can be significantly reduced due to the compact size of lottery networks. To support the training and evaluation of our framework, we construct non-IID datasets based on MNIST, CIFAR-10 and EMNIST by taking feature distribution skew, label distribution skew and quantity skew into consideration. Experiments on these non-IID datasets demonstrate that LotteryFL significantly outperforms existing solutions in terms of personalization and communication cost.
Exploration of object recognition from 3D point cloud
Jul 05, 2017
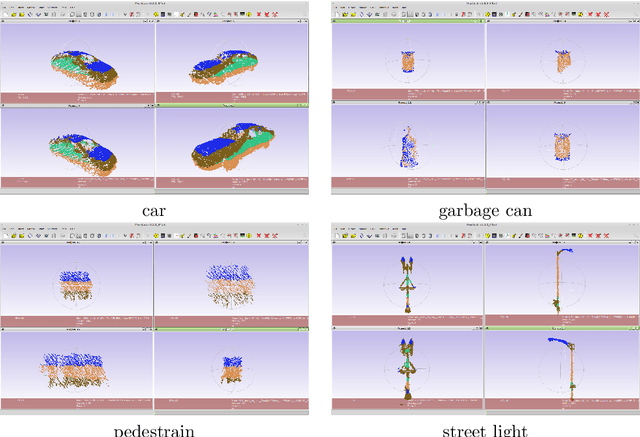
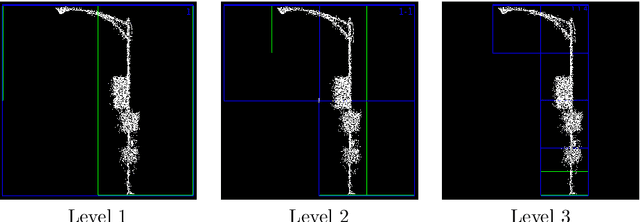
We present our latest experiment results of object recognition from 3D point cloud data collected through moving car.