 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Architecture for Benign-Malignant Classification of Mammography ROIs
Apr 14, 2026Accurate characterization of suspicious breast lesions in mammography is important for early diagnosis and treatment planning. While Convolutional Neural Networks (CNNs) are effective at extracting local visual patterns, they are less suited to modeling long-range dependencies. Vision Transformers (ViTs) address this limitation through self-attention, but their quadratic computational cost can be prohibitive. This paper presents a hybrid architecture that combines EfficientNetV2-M for local feature extraction with Vision Mamba, a State Space Model (SSM), for efficient global context modeling. The proposed model performs binary classification of abnormality-centered mammography regions of interest (ROIs) from the CBIS-DDSM dataset into benign and malignant classes. By combining a strong CNN backbone with a linear-complexity sequence model, the approach achieves strong lesion-level classification performance in an ROI-based setting.
Brain-inspired automated visual object discovery and detection
Sep 30, 2019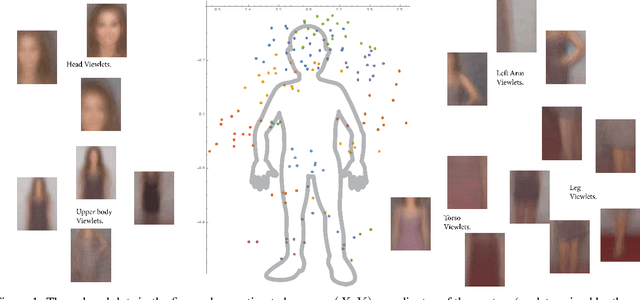
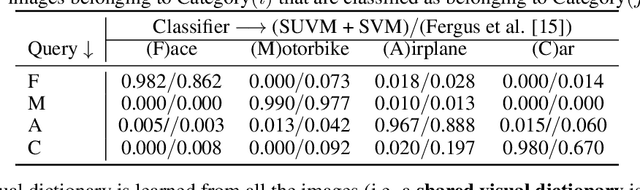
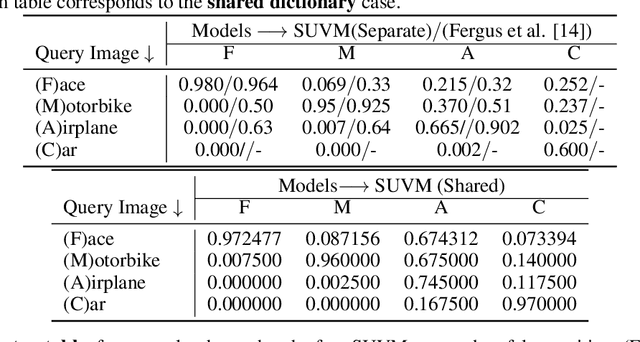

Despite significant recent progress, machine vision systems lag considerably behind their biological counterparts in performance, scalability, and robustness. A distinctive hallmark of the brain is its ability to automatically discover and model objects, at multiscale resolutions, from repeated exposures to unlabeled contextual data and then to be able to robustly detect the learned objects under various nonideal circumstances, such as partial occlusion and different view angles. Replication of such capabilities in a machine would require three key ingredients: (i) access to large-scale perceptual data of the kind that humans experience, (ii) flexible representations of objects, and (iii) an efficient unsupervised learning algorithm. The Internet fortunately provides unprecedented access to vast amounts of visual data. This paper leverages the availability of such data to develop a scalable framework for unsupervised learning of object prototypes--brain-inspired flexible, scale, and shift invariant representations of deformable objects (e.g., humans, motorcycles, cars, airplanes) comprised of parts, their different configurations and views, and their spatial relationships. Computationally, the object prototypes are represented as geometric associative networks using probabilistic constructs such as Markov random fields. We apply our framework to various datasets and show that our approach is computationally scalable and can construct accurate and operational part-aware object models much more efficiently than in much of the recent computer vision literature. We also present efficient algorithms for detection and localization in new scenes of objects and their partial views.