 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLoG: Benchmarking Continual Learning of Image Generation Models
Jun 07, 2024



Continual Learning (CL) poses a significant challenge in Artificial Intelligence, aiming to mirror the human ability to incrementally acquire knowledge and skills. While extensive research has focused on CL within the context of classification tasks, the advent of increasingly powerful generative models necessitates the exploration of Continual Learning of Generative models (CLoG). This paper advocates for shifting the research focus from classification-based CL to CLoG. We systematically identify the unique challenges presented by CLoG compared to traditional classification-based CL. We adapt three types of existing CL methodologies, replay-based, regularization-based, and parameter-isolation-based methods to generative tasks and introduce comprehensive benchmarks for CLoG that feature great diversity and broad task coverage. Our benchmarks and results yield intriguing insights that can be valuable for developing future CLoG methods. Additionally, we will release a codebase designed to facilitate easy benchmarking and experimentation in CLoG publicly at https://github.com/linhaowei1/CLoG. We believe that shifting the research focus to CLoG will benefit the continual learning community and illuminate the path for next-generation AI-generated content (AIGC) in a lifelong learning paradigm.
ICAL: Implicit Character-Aided Learning for Enhanced Handwritten Mathematical Expression Recognition
May 15, 2024Significant progress has been made in the field of handwritten mathematical expression recognition, while existing encoder-decoder methods are usually difficult to model global information in \LaTeX. Therefore, this paper introduces a novel approach, Implicit Character-Aided Learning (ICAL), to mine the global expression information and enhance handwritten mathematical expression recognition. Specifically, we propose the Implicit Character Construction Module (ICCM) to predict implicit character sequences and use a Fusion Module to merge the outputs of the ICCM and the decoder, thereby producing corrected predictions. By modeling and utilizing implicit character information, ICAL achieves a more accurate and context-aware interpretation of handwritten mathematical expressions. Experimental results demonstrate that ICAL notably surpasses the state-of-the-art(SOTA) models, improving the expression recognition rate (ExpRate) by 2.21\%/1.75\%/1.28\% on the CROHME 2014/2016/2019 datasets respectively, and achieves a remarkable 69.25\% on the challenging HME100k test set. We make our code available on the GitHub: https://github.com/qingzhenduyu/ICAL
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Apr 16, 2024Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain background knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
Cycle Invariant Positional Encoding for Graph Representation Learning
Nov 30, 2023



Cycles are fundamental elements in graph-structured data and have demonstrated their effectiveness in enhancing graph learning models. To encode such information into a graph learning framework, prior works often extract a summary quantity, ranging from the number of cycles to the more sophisticated persistence diagram summaries. However, more detailed information, such as which edges are encoded in a cycle, has not yet been used in graph neural networks. In this paper, we make one step towards addressing this gap, and propose a structure encoding module, called CycleNet, that encodes cycle information via edge structure encoding in a permutation invariant manner. To efficiently encode the space of all cycles, we start with a cycle basis (i.e., a minimal set of cycles generating the cycle space) which we compute via the kernel of the 1-dimensional Hodge Laplacian of the input graph. To guarantee the encoding is invariant w.r.t. the choice of cycle basis, we encode the cycle information via the orthogonal projector of the cycle basis, which is inspired by BasisNet proposed by Lim et al. We also develop a more efficient variant which however requires that the input graph has a unique shortest cycle basis. To demonstrate the effectiveness of the proposed module, we provide some theoretical understandings of its expressive power. Moreover, we show via a range of experiments that networks enhanced by our CycleNet module perform better in various benchmarks compared to several existing SOTA models.
Recognition-Guided Diffusion Model for Scene Text Image Super-Resolution
Nov 22, 2023Scene Text Image Super-Resolution (STISR) aims to enhance the resolution and legibility of text within low-resolution (LR) images, consequently elevating recognition accuracy in Scene Text Recognition (STR). Previous methods predominantly employ discriminative Convolutional Neural Networks (CNNs) augmented with diverse forms of text guidance to address this issue. Nevertheless, they remain deficient when confronted with severely blurred images, due to their insufficient generation capability when little structural or semantic information can be extracted from original images. Therefore, we introduce RGDiffSR, a Recognition-Guided Diffusion model for scene text image Super-Resolution, which exhibits great generative diversity and fidelity even in challenging scenarios. Moreover, we propose a Recognition-Guided Denoising Network, to guide the diffusion model generating LR-consistent results through succinct semantic guidance. Experiments on the TextZoom dataset demonstrate the superiority of RGDiffSR over prior state-of-the-art methods in both text recognition accuracy and image fidelity.
Improving Table Structure Recognition with Visual-Alignment Sequential Coordinate Modeling
Mar 20, 2023



Table structure recognition aims to extract the logical and physical structure of unstructured table images into a machine-readable format. The latest end-to-end image-to-text approaches simultaneously predict the two structures by two decoders, where the prediction of the physical structure (the bounding boxes of the cells) is based on the representation of the logical structure. However, the previous methods struggle with imprecise bounding boxes as the logical representation lacks local visual information. To address this issue, we propose an end-to-end sequential modeling framework for table structure recognition called VAST. It contains a novel coordinate sequence decoder triggered by the representation of the non-empty cell from the logical structure decoder. In the coordinate sequence decoder, we model the bounding box coordinates as a language sequence, where the left, top, right and bottom coordinates are decoded sequentially to leverage the inter-coordinate dependency. Furthermore, we propose an auxiliary visual-alignment loss to enforce the logical representation of the non-empty cells to contain more local visual details, which helps produce better cell bounding boxes. Extensive experiments demonstrate that our proposed method can achieve state-of-the-art results in both logical and physical structure recognition. The ablation study also validates that the proposed coordinate sequence decoder and the visual-alignment loss are the keys to the success of our method.
Efficiently Counting Substructures by Subgraph GNNs without Running GNN on Subgraphs
Mar 19, 2023



Using graph neural networks (GNNs) to approximate specific functions such as counting graph substructures is a recent trend in graph learning. Among these works, a popular way is to use subgraph GNNs, which decompose the input graph into a collection of subgraphs and enhance the representation of the graph by applying GNN to individual subgraphs. Although subgraph GNNs are able to count complicated substructures, they suffer from high computational and memory costs. In this paper, we address a non-trivial question: can we count substructures efficiently with GNNs? To answer the question, we first theoretically show that the distance to the rooted nodes within subgraphs is key to boosting the counting power of subgraph GNNs. We then encode such information into structural embeddings, and precompute the embeddings to avoid extracting information over all subgraphs via GNNs repeatedly. Experiments on various benchmarks show that the proposed model can preserve the counting power of subgraph GNNs while running orders of magnitude faster.
CoMER: Modeling Coverage for Transformer-based Handwritten Mathematical Expression Recognition
Jul 18, 2022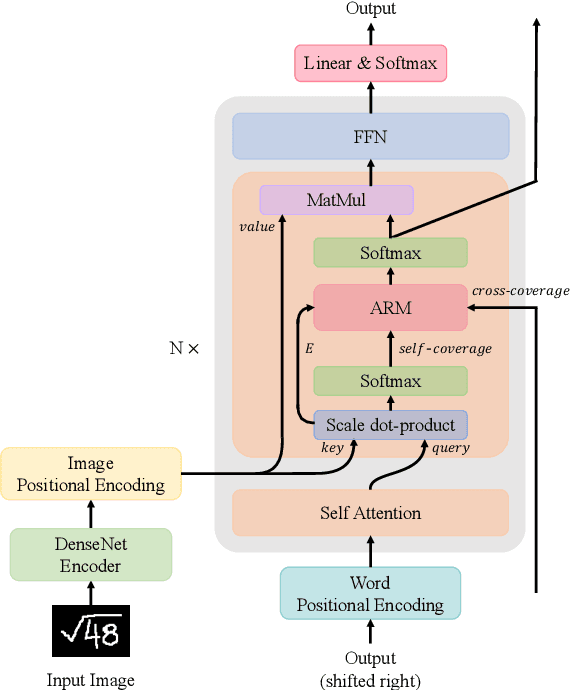
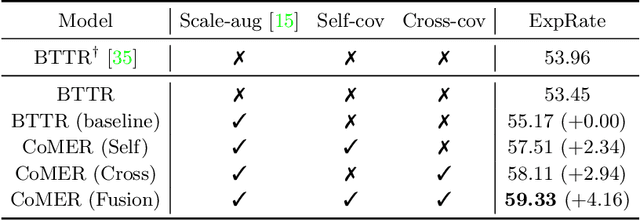
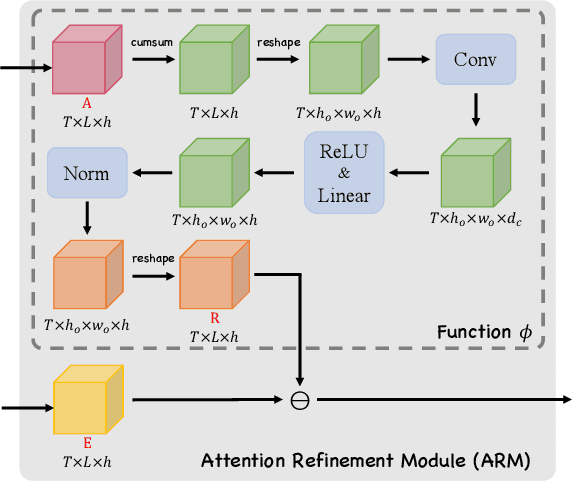
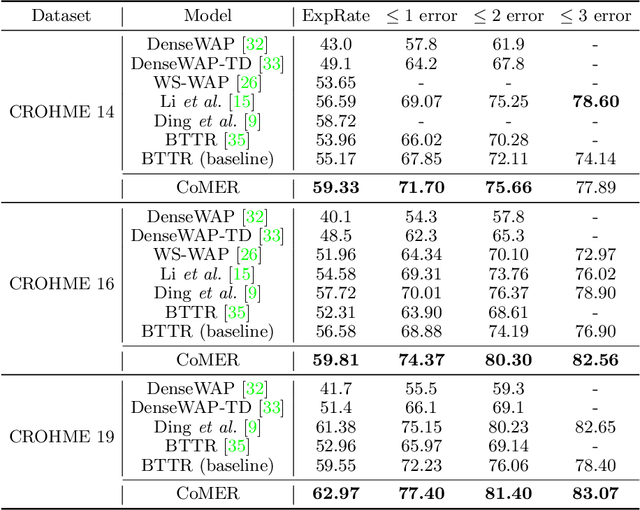
The Transformer-based encoder-decoder architecture has recently made significant advances in recognizing handwritten mathematical expressions. However, the transformer model still suffers from the lack of coverage problem, making its expression recognition rate (ExpRate) inferior to its RNN counterpart. Coverage information, which records the alignment information of the past steps, has proven effective in the RNN models. In this paper, we propose CoMER, a model that adopts the coverage information in the transformer decoder. Specifically, we propose a novel Attention Refinement Module (ARM) to refine the attention weights with past alignment information without hurting its parallelism. Furthermore, we take coverage information to the extreme by proposing self-coverage and cross-coverage, which utilize the past alignment information from the current and previous layers. Experiments show that CoMER improves the ExpRate by 0.61%/2.09%/1.59% compared to the current state-of-the-art model, and reaches 59.33%/59.81%/62.97% on the CROHME 2014/2016/2019 test sets.
Neural Approximation of Extended Persistent Homology on Graphs
Jan 28, 2022

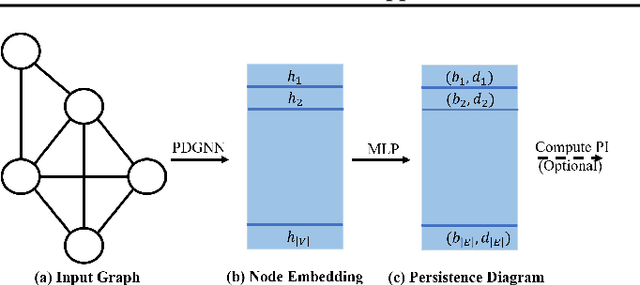
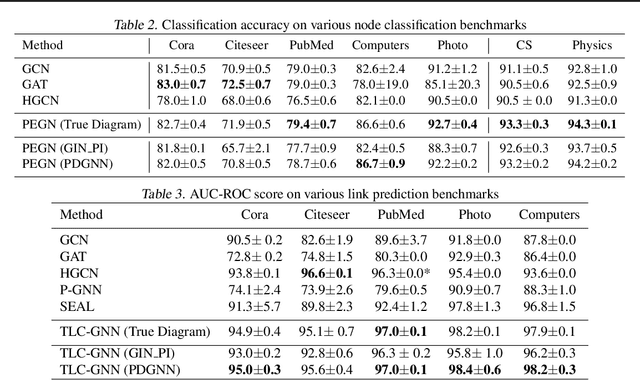
Persistent homology is a widely used theory in topological data analysis. In the context of graph learning, topological features based on persistent homology have been used to capture potentially high-order structural information so as to augment existing graph neural network methods. However, computing extended persistent homology summaries remains slow for large and dense graphs, especially since in learning applications one has to carry out this computation potentially many times. Inspired by recent success in neural algorithmic reasoning, we propose a novel learning method to compute extended persistence diagrams on graphs. The proposed neural network aims to simulate a specific algorithm and learns to compute extended persistence diagrams for new graphs efficiently. Experiments on approximating extended persistence diagrams and several downstream graph representation learning tasks demonstrate the effectiveness of our method. Our method is also efficient; on large and dense graphs, we accelerate the computation by nearly 100 times.
A Topological View of Rule Learning in Knowledge Graphs
Oct 06, 2021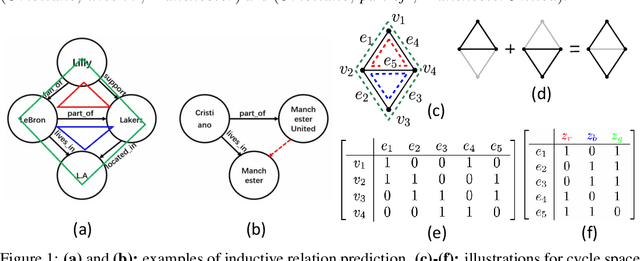
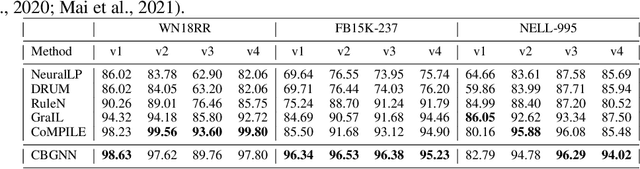
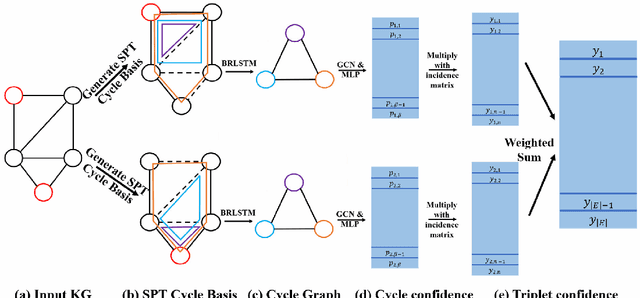
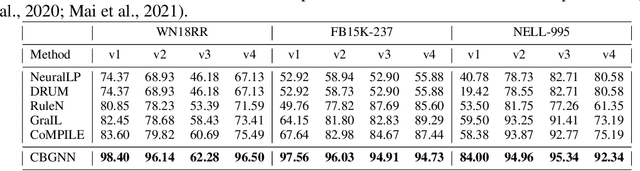
Inductive relation prediction is an important learning task for knowledge graph completion. One can use the existence of rules, namely a sequence of relations, to predict the relation between two entities. Previous works view rules as paths and primarily focus on the searching of paths between entities. The space of paths is huge, and one has to sacrifice either efficiency or accuracy. In this paper, we consider rules in knowledge graphs as cycles and show that the space of cycles has a unique structure based on the theory of algebraic topology. By exploring the linear structure of the cycle space, we can improve the searching efficiency of rules. We propose to collect cycle bases that span the space of cycles. We build a novel GNN framework on the collected cycles to learn the representations of cycles, and to predict the existence/non-existence of a relation. Our method achieves state-of-the-art performance on benchmarks.