 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvMath: A Convolutional Sequence Network for Mathematical Expression Recognition
Paper and Code
Dec 23, 2020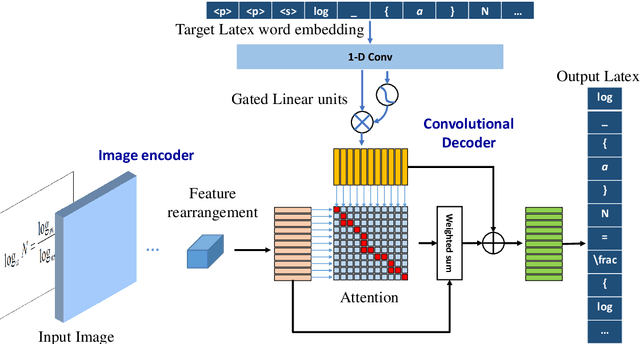
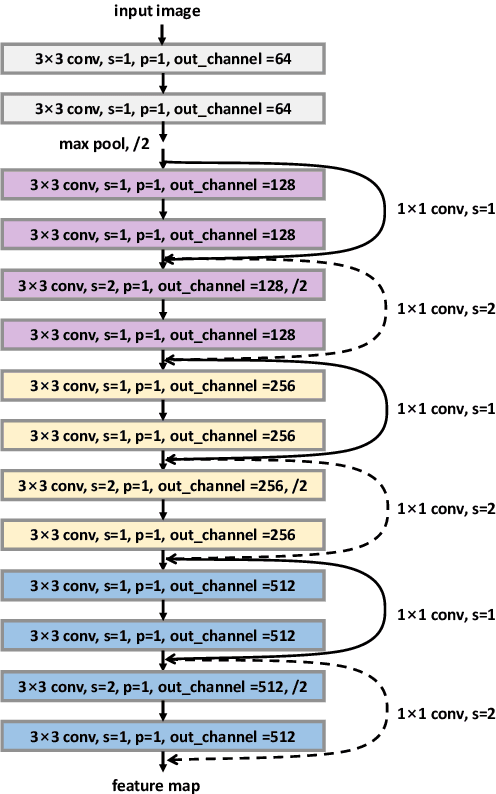
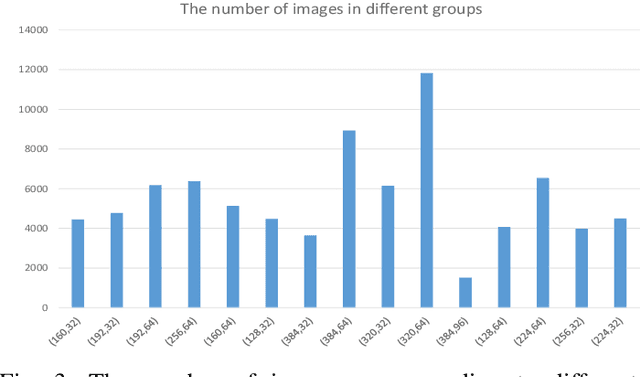

Despite the recent advances in optical character recognition (OCR), mathematical expressions still face a great challenge to recognize due to their two-dimensional graphical layout. In this paper, we propose a convolutional sequence modeling network, ConvMath, which converts the mathematical expression description in an image into a LaTeX sequence in an end-to-end way. The network combines an image encoder for feature extraction and a convolutional decoder for sequence generation. Compared with other Long Short Term Memory(LSTM) based encoder-decoder models, ConvMath is entirely based on convolution, thus it is easy to perform parallel computation. Besides, the network adopts multi-layer attention mechanism in the decoder, which allows the model to align output symbols with source feature vectors automatically, and alleviates the problem of lacking coverage while training the model. The performance of ConvMath is evaluated on an open dataset named IM2LATEX-100K, including 103556 samples. The experimental results demonstrate that the proposed network achieves state-of-the-art accuracy and much better efficiency than previous methods.