 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence and Dispersity Speak: Characterising Prediction Matrix for Unsupervised Accuracy Estimation
Feb 02, 2023



This work aims to assess how well a model performs under distribution shifts without using labels. While recent methods study prediction confidence, this work reports prediction dispersity is another informative cue. Confidence reflects whether the individual prediction is certain; dispersity indicates how the overall predictions are distributed across all categories. Our key insight is that a well-performing model should give predictions with high confidence and high dispersity. That is, we need to consider both properties so as to make more accurate estimates. To this end, we use the nuclear norm that has been shown to be effective in characterizing both properties. Extensive experiments validate the effectiveness of nuclear norm for various models (e.g., ViT and ConvNeXt), different datasets (e.g., ImageNet and CUB-200), and diverse types of distribution shifts (e.g., style shift and reproduction shift). We show that the nuclear norm is more accurate and robust in accuracy estimation than existing methods. Furthermore, we validate the feasibility of other measurements (e.g., mutual information maximization) for characterizing dispersity and confidence. Lastly, we investigate the limitation of the nuclear norm, study its improved variant under severe class imbalance, and discuss potential directions.
Large-Scale Traffic Data Imputation with Spatiotemporal Semantic Understanding
Jan 27, 2023Large-scale data missing is a challenging problem in Intelligent Transportation Systems (ITS). Many studies have been carried out to impute large-scale traffic data by considering their spatiotemporal correlations at a network level. In existing traffic data imputations, however, rich semantic information of a road network has been largely ignored when capturing network-wide spatiotemporal correlations. This study proposes a Graph Transformer for Traffic Data Imputation (GT-TDI) model to impute large-scale traffic data with spatiotemporal semantic understanding of a road network. Specifically, the proposed model introduces semantic descriptions consisting of network-wide spatial and temporal information of traffic data to help the GT-TDI model capture spatiotemporal correlations at a network level. The proposed model takes incomplete data, the social connectivity of sensors, and semantic descriptions as input to perform imputation tasks with the help of Graph Neural Networks (GNN) and Transformer. On the PeMS freeway dataset, extensive experiments are conducted to compare the proposed GT-TDI model with conventional methods, tensor factorization methods, and deep learning-based methods. The results show that the proposed GT-TDI outperforms existing methods in complex missing patterns and diverse missing rates. The code of the GT-TDI model will be available at https://github.com/KP-Zhang/GT-TDI.
CircNet: Meshing 3D Point Clouds with Circumcenter Detection
Jan 23, 2023Reconstructing 3D point clouds into triangle meshes is a key problem in computational geometry and surface reconstruction. Point cloud triangulation solves this problem by providing edge information to the input points. Since no vertex interpolation is involved, it is beneficial to preserve sharp details on the surface. Taking advantage of learning-based techniques in triangulation, existing methods enumerate the complete combinations of candidate triangles, which is both complex and inefficient. In this paper, we leverage the duality between a triangle and its circumcenter, and introduce a deep neural network that detects the circumcenters to achieve point cloud triangulation. Specifically, we introduce multiple anchor priors to divide the neighborhood space of each point. The neural network then learns to predict the presences and locations of circumcenters under the guidance of those anchors. We extract the triangles dual to the detected circumcenters to form a primitive mesh, from which an edge-manifold mesh is produced via simple post-processing. Unlike existing learning-based triangulation methods, the proposed method bypasses an exhaustive enumeration of triangle combinations and local surface parameterization. We validate the efficiency, generalization, and robustness of our method on prominent datasets of both watertight and open surfaces. The code and trained models are provided at https://github.com/Ruitao-L/CircNet.
High-Fidelity Guided Image Synthesis with Latent Diffusion Models
Nov 30, 2022Controllable image synthesis with user scribbles has gained huge public interest with the recent advent of text-conditioned latent diffusion models. The user scribbles control the color composition while the text prompt provides control over the overall image semantics. However, we note that prior works in this direction suffer from an intrinsic domain shift problem, wherein the generated outputs often lack details and resemble simplistic representations of the target domain. In this paper, we propose a novel guided image synthesis framework, which addresses this problem by modeling the output image as the solution of a constrained optimization problem. We show that while computing an exact solution to the optimization is infeasible, an approximation of the same can be achieved while just requiring a single pass of the reverse diffusion process. Additionally, we show that by simply defining a cross-attention based correspondence between the input text tokens and the user stroke-painting, the user is also able to control the semantics of different painted regions without requiring any conditional training or finetuning. Human user study results show that the proposed approach outperforms the previous state-of-the-art by over 85.32% on the overall user satisfaction scores. Project page for our paper is available at https://1jsingh.github.io/gradop.
Generalizable Re-Identification from Videos with Cycle Association
Nov 08, 2022In this paper, we are interested in learning a generalizable person re-identification (re-ID) representation from unlabeled videos. Compared with 1) the popular unsupervised re-ID setting where the training and test sets are typically under the same domain, and 2) the popular domain generalization (DG) re-ID setting where the training samples are labeled, our novel scenario combines their key challenges: the training samples are unlabeled, and collected form various domains which do no align with the test domain. In other words, we aim to learn a representation in an unsupervised manner and directly use the learned representation for re-ID in novel domains. To fulfill this goal, we make two main contributions: First, we propose Cycle Association (CycAs), a scalable self-supervised learning method for re-ID with low training complexity; and second, we construct a large-scale unlabeled re-ID dataset named LMP-video, tailored for the proposed method. Specifically, CycAs learns re-ID features by enforcing cycle consistency of instance association between temporally successive video frame pairs, and the training cost is merely linear to the data size, making large-scale training possible. On the other hand, the LMP-video dataset is extremely large, containing 50 million unlabeled person images cropped from over 10K Youtube videos, therefore is sufficient to serve as fertile soil for self-supervised learning. Trained on LMP-video, we show that CycAs learns good generalization towards novel domains. The achieved results sometimes even outperform supervised domain generalizable models. Remarkably, CycAs achieves 82.2% Rank-1 on Market-1501 and 49.0% Rank-1 on MSMT17 with zero human annotation, surpassing state-of-the-art supervised DG re-ID methods. Moreover, we also demonstrate the superiority of CycAs under the canonical unsupervised re-ID and the pretrain-and-finetune scenarios.
Learning to Structure an Image with Few Colors and Beyond
Aug 17, 2022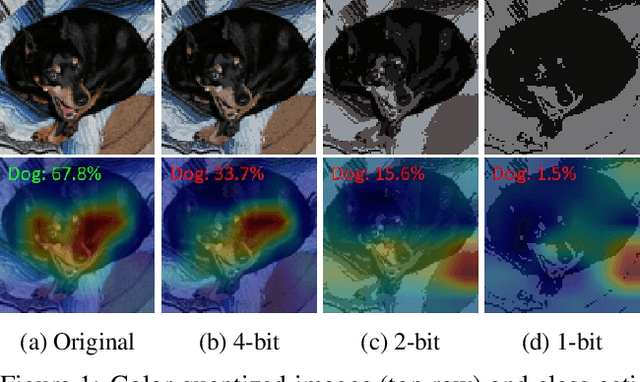
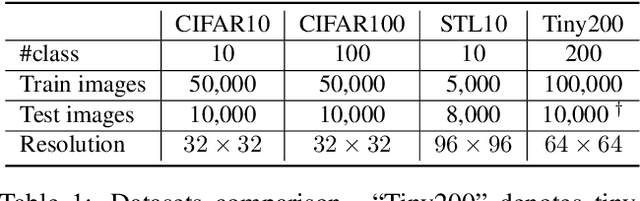

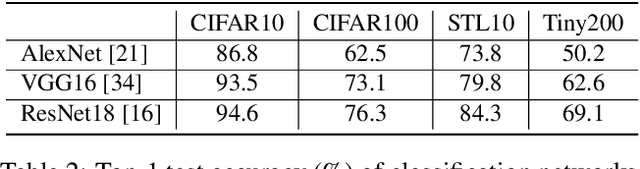
Color and structure are the two pillars that combine to give an image its meaning. Interested in critical structures for neural network recognition, we isolate the influence of colors by limiting the color space to just a few bits, and find structures that enable network recognition under such constraints. To this end, we propose a color quantization network, ColorCNN, which learns to structure an image in limited color spaces by minimizing the classification loss. Building upon the architecture and insights of ColorCNN, we introduce ColorCNN+, which supports multiple color space size configurations, and addresses the previous issues of poor recognition accuracy and undesirable visual fidelity under large color spaces. Via a novel imitation learning approach, ColorCNN+ learns to cluster colors like traditional color quantization methods. This reduces overfitting and helps both visual fidelity and recognition accuracy under large color spaces. Experiments verify that ColorCNN+ achieves very competitive results under most circumstances, preserving both key structures for network recognition and visual fidelity with accurate colors. We further discuss differences between key structures and accurate colors, and their specific contributions to network recognition. For potential applications, we show that ColorCNNs can be used as image compression methods for network recognition.
Multi-View Correlation Consistency for Semi-Supervised Semantic Segmentation
Aug 17, 2022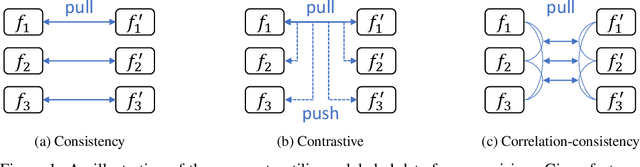
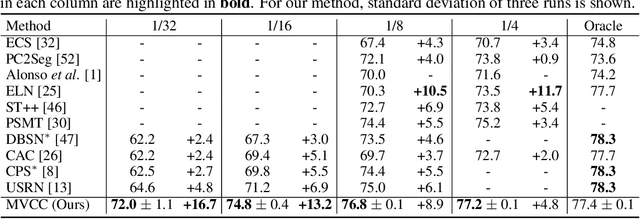
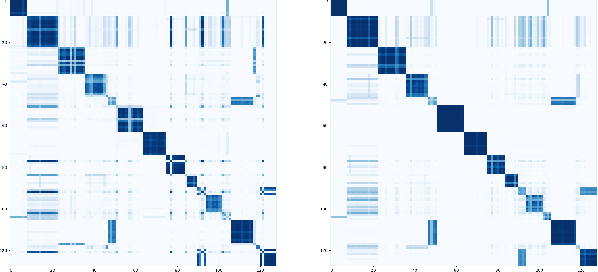
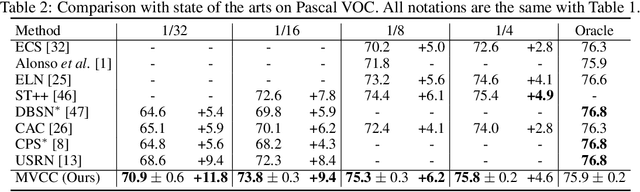
Semi-supervised semantic segmentation needs rich and robust supervision on unlabeled data. Consistency learning enforces the same pixel to have similar features in different augmented views, which is a robust signal but neglects relationships with other pixels. In comparison, contrastive learning considers rich pairwise relationships, but it can be a conundrum to assign binary positive-negative supervision signals for pixel pairs. In this paper, we take the best of both worlds and propose multi-view correlation consistency (MVCC) learning: it considers rich pairwise relationships in self-correlation matrices and matches them across views to provide robust supervision. Together with this correlation consistency loss, we propose a view-coherent data augmentation strategy that guarantees pixel-pixel correspondence between different views. In a series of semi-supervised settings on two datasets, we report competitive accuracy compared with the state-of-the-art methods. Notably, on Cityscapes, we achieve 76.8% mIoU with 1/8 labeled data, just 0.6% shy from the fully supervised oracle.
Paint2Pix: Interactive Painting based Progressive Image Synthesis and Editing
Aug 17, 2022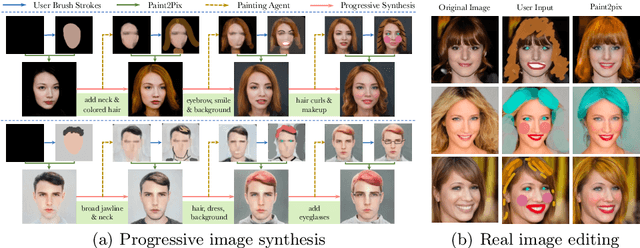
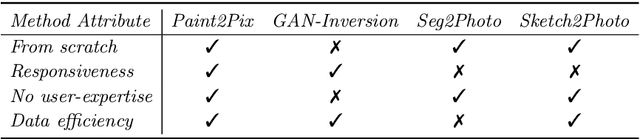
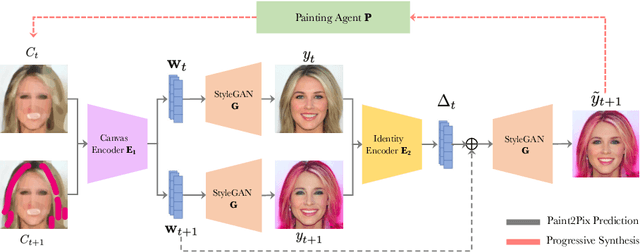
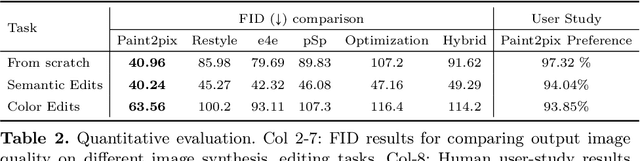
Controllable image synthesis with user scribbles is a topic of keen interest in the computer vision community. In this paper, for the first time we study the problem of photorealistic image synthesis from incomplete and primitive human paintings. In particular, we propose a novel approach paint2pix, which learns to predict (and adapt) "what a user wants to draw" from rudimentary brushstroke inputs, by learning a mapping from the manifold of incomplete human paintings to their realistic renderings. When used in conjunction with recent works in autonomous painting agents, we show that paint2pix can be used for progressive image synthesis from scratch. During this process, paint2pix allows a novice user to progressively synthesize the desired image output, while requiring just few coarse user scribbles to accurately steer the trajectory of the synthesis process. Furthermore, we find that our approach also forms a surprisingly convenient approach for real image editing, and allows the user to perform a diverse range of custom fine-grained edits through the addition of only a few well-placed brushstrokes. Supplemental video and demo are available at https://1jsingh.github.io/paint2pix
* ECCV 2022
On the Strong Correlation Between Model Invariance and Generalization
Jul 14, 2022

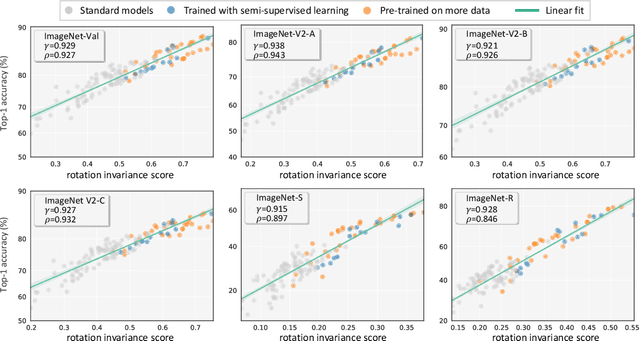
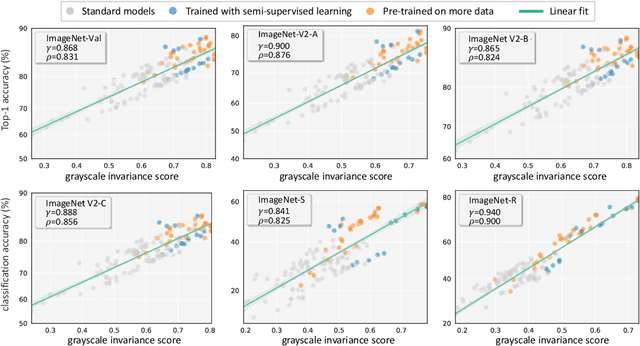
Generalization and invariance are two essential properties of any machine learning model. Generalization captures a model's ability to classify unseen data while invariance measures consistency of model predictions on transformations of the data. Existing research suggests a positive relationship: a model generalizing well should be invariant to certain visual factors. Building on this qualitative implication we make two contributions. First, we introduce effective invariance (EI), a simple and reasonable measure of model invariance which does not rely on image labels. Given predictions on a test image and its transformed version, EI measures how well the predictions agree and with what level of confidence. Second, using invariance scores computed by EI, we perform large-scale quantitative correlation studies between generalization and invariance, focusing on rotation and grayscale transformations. From a model-centric view, we observe generalization and invariance of different models exhibit a strong linear relationship, on both in-distribution and out-of-distribution datasets. From a dataset-centric view, we find a certain model's accuracy and invariance linearly correlated on different test sets. Apart from these major findings, other minor but interesting insights are also discussed.
Multiview Detection with Cardboard Human Modeling
Jul 10, 2022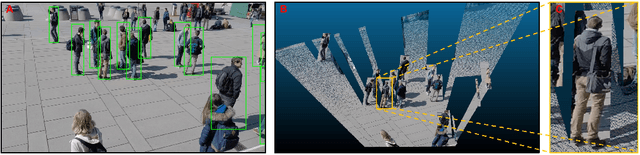
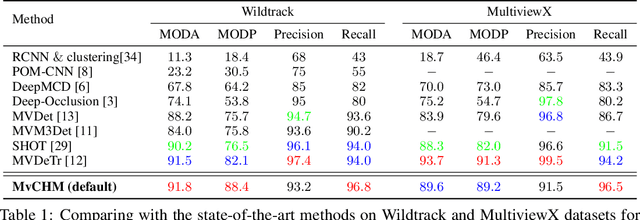
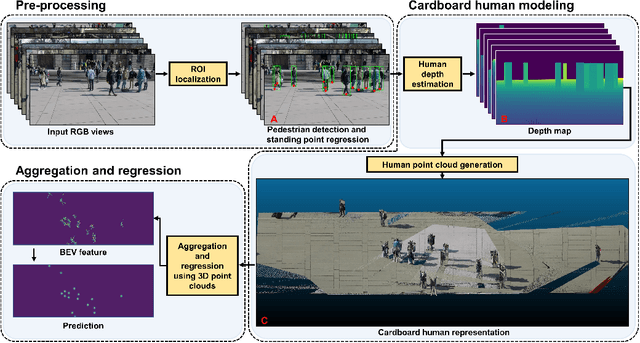

Multiview detection uses multiple calibrated cameras with overlapping fields of views to locate occluded pedestrians. In this field, existing methods typically adopt a "human modeling - aggregation" strategy. To find robust pedestrian representations, some intuitively use locations of detected 2D bounding boxes, while others use entire frame features projected to the ground plane. However, the former does not consider human appearance and leads to many ambiguities, and the latter suffers from projection errors due to the lack of accurate height of the human torso and head. In this paper, we propose a new pedestrian representation scheme based on human point clouds modeling. Specifically, using ray tracing for holistic human depth estimation, we model pedestrians as upright, thin cardboard point clouds on the ground. Then, we aggregate the point clouds of the pedestrian cardboard across multiple views for a final decision. Compared with existing representations, the proposed method explicitly leverages human appearance and reduces projection errors significantly by relatively accurate height estimation. On two standard evaluation benchmarks, the proposed method achieves very competitive results.