 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Learning with Low-Level Auxiliary Tasks for Encoder-Decoder Based Speech Recognition
Apr 19, 2017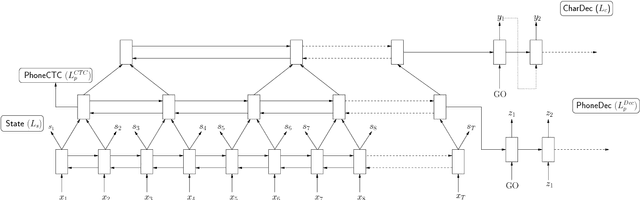
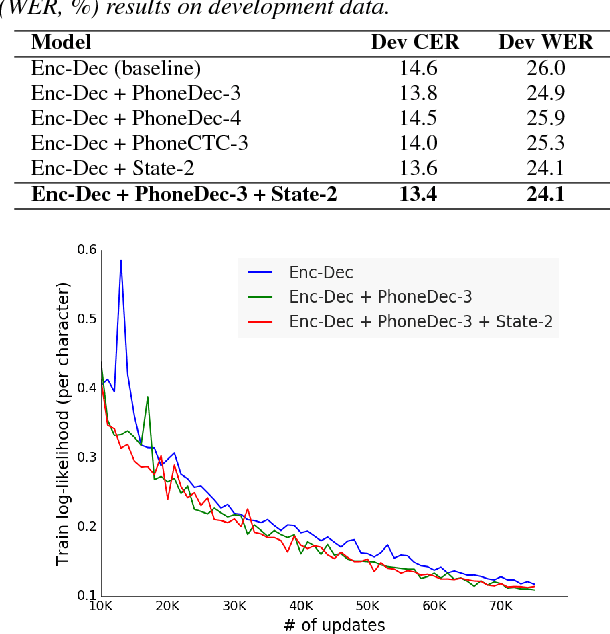
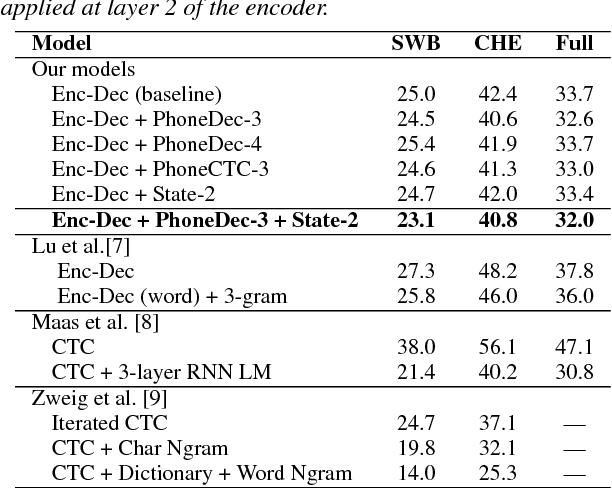
End-to-end training of deep learning-based models allows for implicit learning of intermediate representations based on the final task loss. However, the end-to-end approach ignores the useful domain knowledge encoded in explicit intermediate-level supervision. We hypothesize that using intermediate representations as auxiliary supervision at lower levels of deep networks may be a good way of combining the advantages of end-to-end training and more traditional pipeline approaches. We present experiments on conversational speech recognition where we use lower-level tasks, such as phoneme recognition, in a multitask training approach with an encoder-decoder model for direct character transcription. We compare multiple types of lower-level tasks and analyze the effects of the auxiliary tasks. Our results on the Switchboard corpus show that this approach improves recognition accuracy over a standard encoder-decoder model on the Eval2000 test set.
Sequence Training and Adaptation of Highway Deep Neural Networks
Mar 22, 2017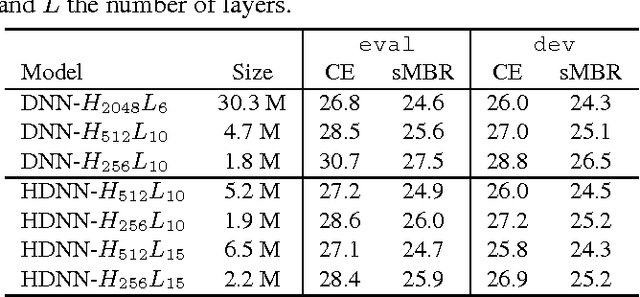
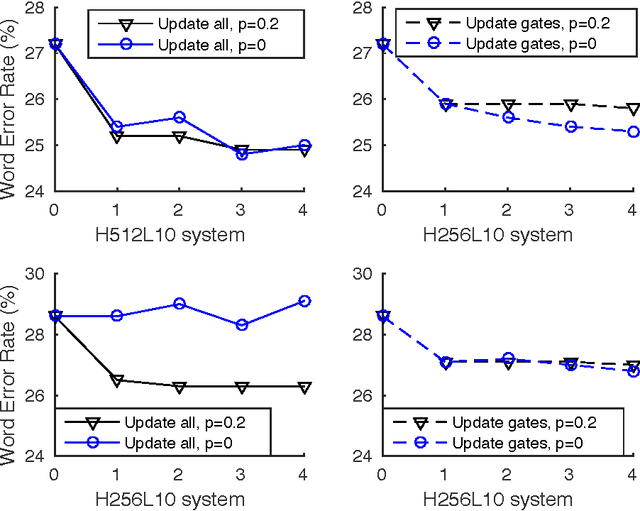
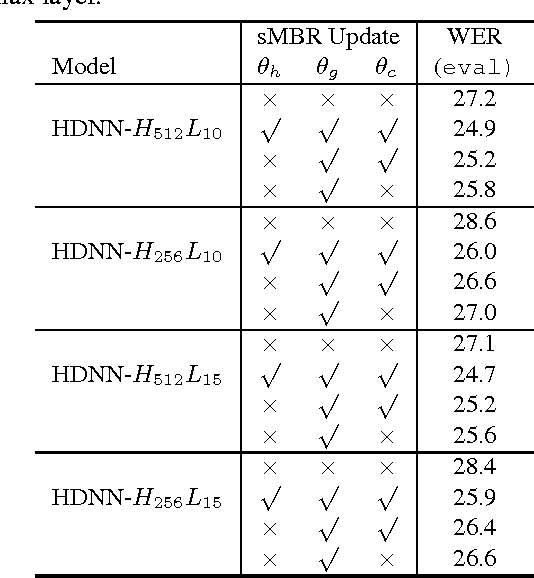
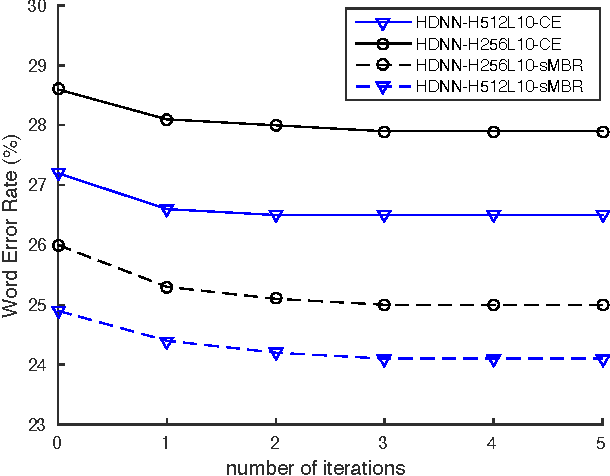
Highway deep neural network (HDNN) is a type of depth-gated feedforward neural network, which has shown to be easier to train with more hidden layers and also generalise better compared to conventional plain deep neural networks (DNNs). Previously, we investigated a structured HDNN architecture for speech recognition, in which the two gate functions were tied across all the hidden layers, and we were able to train a much smaller model without sacrificing the recognition accuracy. In this paper, we carry on the study of this architecture with sequence-discriminative training criterion and speaker adaptation techniques on the AMI meeting speech recognition corpus. We show that these two techniques improve speech recognition accuracy on top of the model trained with the cross entropy criterion. Furthermore, we demonstrate that the two gate functions that are tied across all the hidden layers are able to control the information flow over the whole network, and we can achieve considerable improvements by only updating these gate functions in both sequence training and adaptation experiments.
Knowledge Distillation for Small-footprint Highway Networks
Dec 20, 2016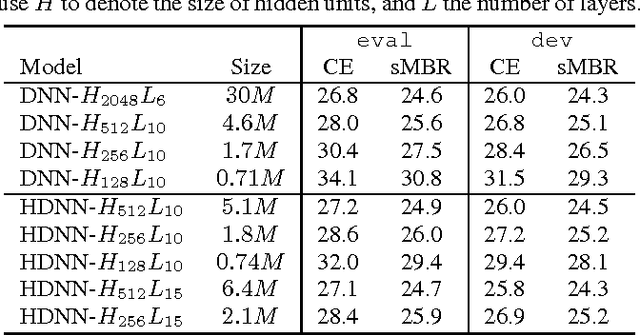
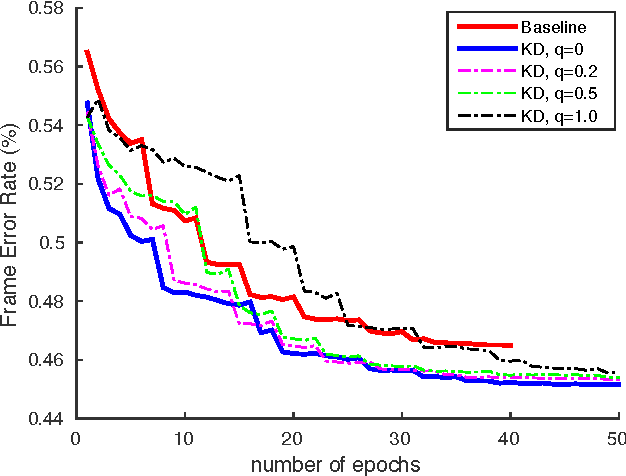
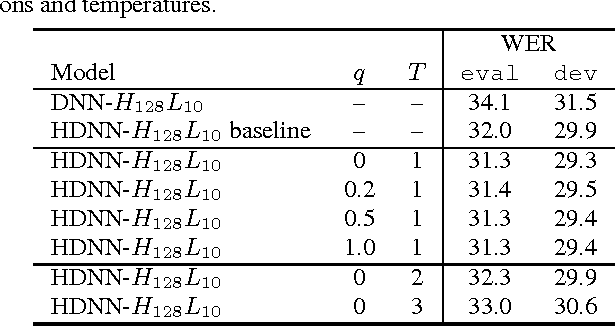
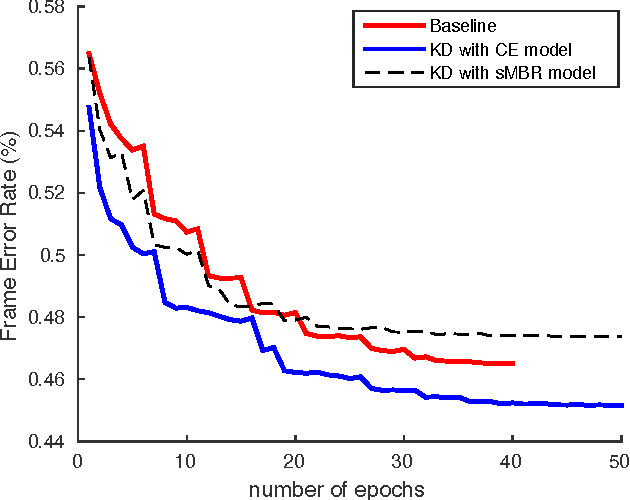
Deep learning has significantly advanced state-of-the-art of speech recognition in the past few years. However, compared to conventional Gaussian mixture acoustic models, neural network models are usually much larger, and are therefore not very deployable in embedded devices. Previously, we investigated a compact highway deep neural network (HDNN) for acoustic modelling, which is a type of depth-gated feedforward neural network. We have shown that HDNN-based acoustic models can achieve comparable recognition accuracy with much smaller number of model parameters compared to plain deep neural network (DNN) acoustic models. In this paper, we push the boundary further by leveraging on the knowledge distillation technique that is also known as {\it teacher-student} training, i.e., we train the compact HDNN model with the supervision of a high accuracy cumbersome model. Furthermore, we also investigate sequence training and adaptation in the context of teacher-student training. Our experiments were performed on the AMI meeting speech recognition corpus. With this technique, we significantly improved the recognition accuracy of the HDNN acoustic model with less than 0.8 million parameters, and narrowed the gap between this model and the plain DNN with 30 million parameters.
Segmental Recurrent Neural Networks for End-to-end Speech Recognition
Jun 20, 2016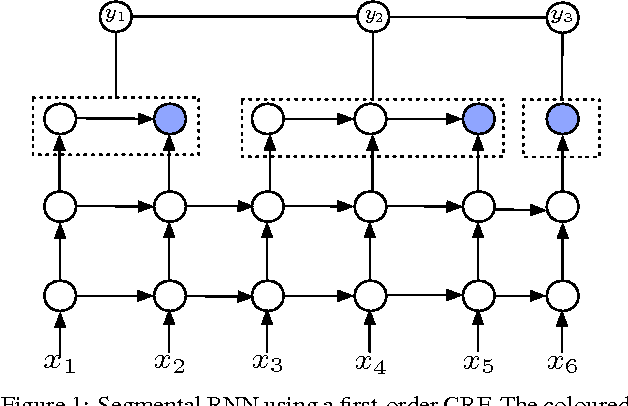

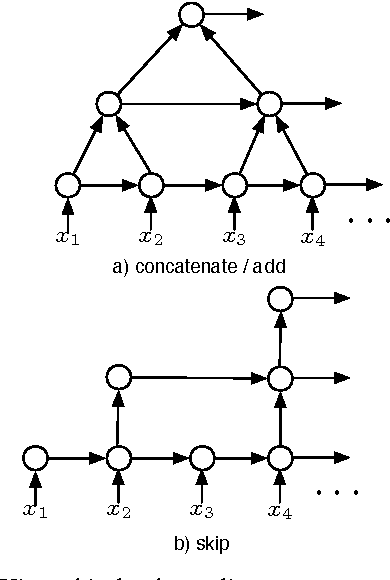
We study the segmental recurrent neural network for end-to-end acoustic modelling. This model connects the segmental conditional random field (CRF) with a recurrent neural network (RNN) used for feature extraction. Compared to most previous CRF-based acoustic models, it does not rely on an external system to provide features or segmentation boundaries. Instead, this model marginalises out all the possible segmentations, and features are extracted from the RNN trained together with the segmental CRF. In essence, this model is self-contained and can be trained end-to-end. In this paper, we discuss practical training and decoding issues as well as the method to speed up the training in the context of speech recognition. We performed experiments on the TIMIT dataset. We achieved 17.3 phone error rate (PER) from the first-pass decoding --- the best reported result using CRFs, despite the fact that we only used a zeroth-order CRF and without using any language model.
Top-down Tree Long Short-Term Memory Networks
Apr 03, 2016
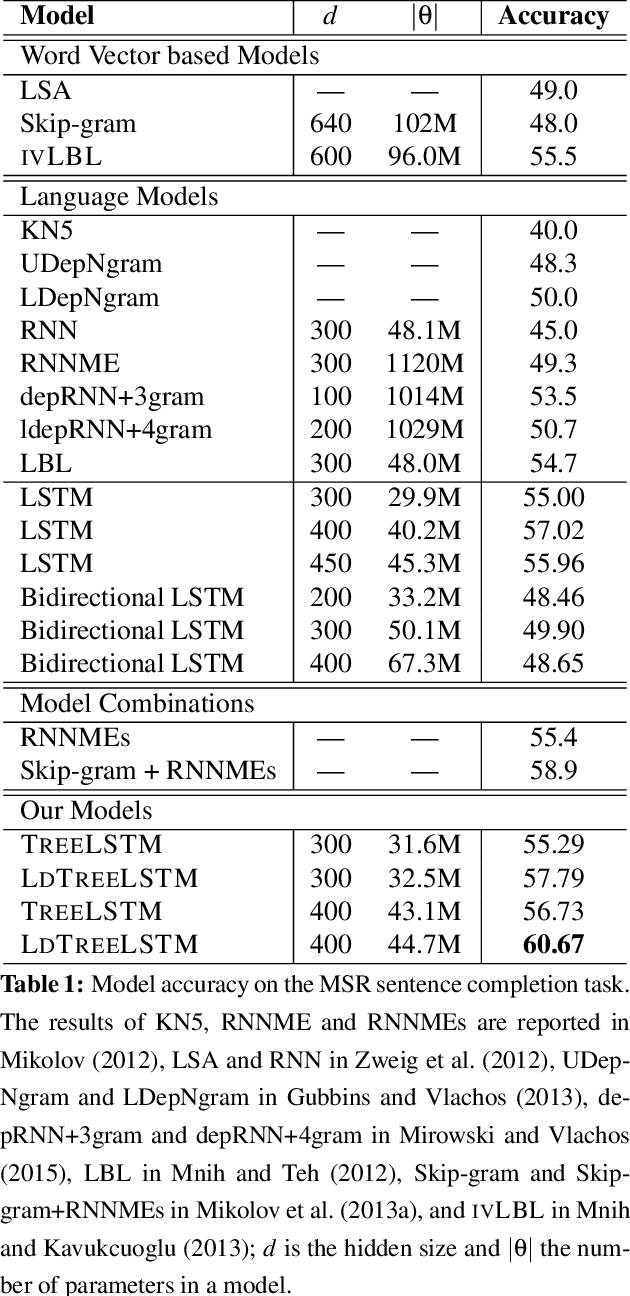
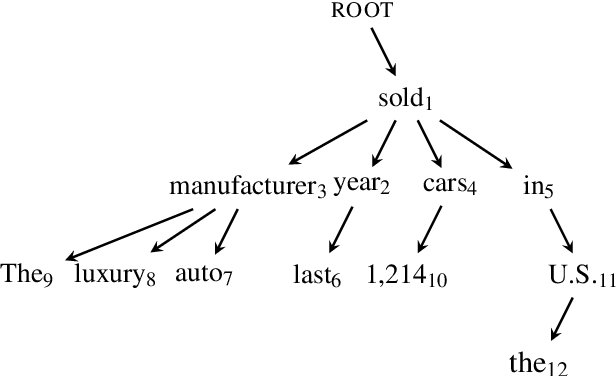

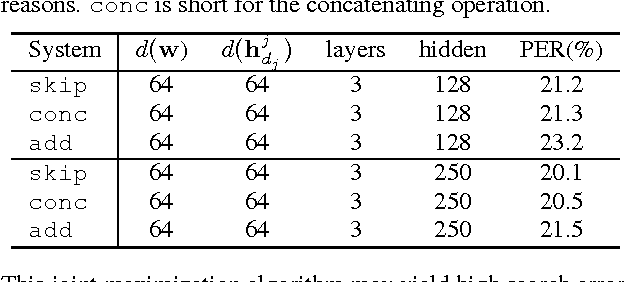
Long Short-Term Memory (LSTM) networks, a type of recurrent neural network with a more complex computational unit, have been successfully applied to a variety of sequence modeling tasks. In this paper we develop Tree Long Short-Term Memory (TreeLSTM), a neural network model based on LSTM, which is designed to predict a tree rather than a linear sequence. TreeLSTM defines the probability of a sentence by estimating the generation probability of its dependency tree. At each time step, a node is generated based on the representation of the generated sub-tree. We further enhance the modeling power of TreeLSTM by explicitly representing the correlations between left and right dependents. Application of our model to the MSR sentence completion challenge achieves results beyond the current state of the art. We also report results on dependency parsing reranking achieving competitive performance.
Tied Probabilistic Linear Discriminant Analysis for Speech Recognition
Nov 04, 2014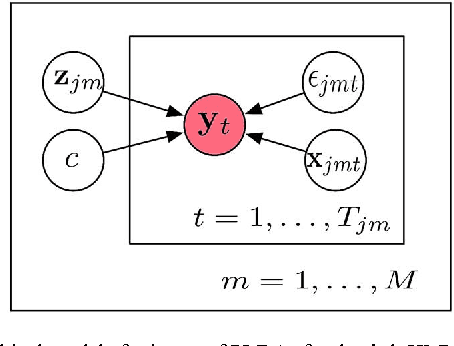
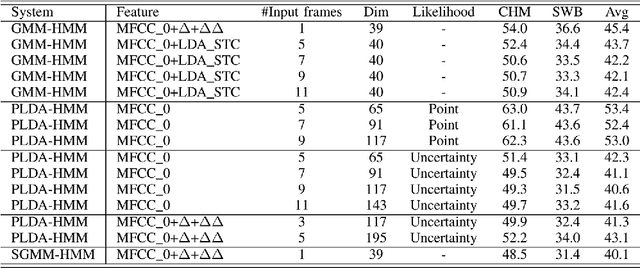
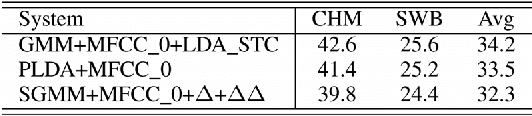
Acoustic models using probabilistic linear discriminant analysis (PLDA) capture the correlations within feature vectors using subspaces which do not vastly expand the model. This allows high dimensional and correlated feature spaces to be used, without requiring the estimation of multiple high dimension covariance matrices. In this letter we extend the recently presented PLDA mixture model for speech recognition through a tied PLDA approach, which is better able to control the model size to avoid overfitting. We carried out experiments using the Switchboard corpus, with both mel frequency cepstral coefficient features and bottleneck feature derived from a deep neural network. Reductions in word error rate were obtained by using tied PLDA, compared with the PLDA mixture model, subspace Gaussian mixture models, and deep neural networks.