 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZebrafish Counting Using Event Stream Data
Apr 18, 2025



Zebrafish share a high degree of homology with human genes and are commonly used as model organism in biomedical research. For medical laboratories, counting zebrafish is a daily task. Due to the tiny size of zebrafish, manual visual counting is challenging. Existing counting methods are either not applicable to small fishes or have too many limitations. The paper proposed a zebrafish counting algorithm based on the event stream data. Firstly, an event camera is applied for data acquisition. Secondly, camera calibration and image fusion were preformed successively. Then, the trajectory information was used to improve the counting accuracy. Finally, the counting results were averaged over an empirical of period and rounded up to get the final results. To evaluate the accuracy of the algorithm, 20 zebrafish were put in a four-liter breeding tank. Among 100 counting trials, the average accuracy reached 97.95%. As compared with traditional algorithms, the proposed one offers a simpler implementation and achieves higher accuracy.
A Comprehensive Survey and Guide to Multimodal Large Language Models in Vision-Language Tasks
Nov 09, 2024



This survey and application guide to multimodal large language models(MLLMs) explores the rapidly developing field of MLLMs, examining their architectures, applications, and impact on AI and Generative Models. Starting with foundational concepts, we delve into how MLLMs integrate various data types, including text, images, video and audio, to enable complex AI systems for cross-modal understanding and generation. It covers essential topics such as training methods, architectural components, and practical applications in various fields, from visual storytelling to enhanced accessibility. Through detailed case studies and technical analysis, the text examines prominent MLLM implementations while addressing key challenges in scalability, robustness, and cross-modal learning. Concluding with a discussion of ethical considerations, responsible AI development, and future directions, this authoritative resource provides both theoretical frameworks and practical insights. It offers a balanced perspective on the opportunities and challenges in the development and deployment of MLLMs, and is highly valuable for researchers, practitioners, and students interested in the intersection of natural language processing and computer vision.
SIG-VC: A Speaker Information Guided Zero-shot Voice Conversion System for Both Human Beings and Machines
Nov 06, 2021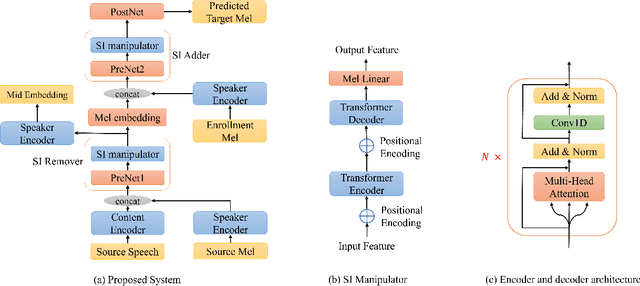
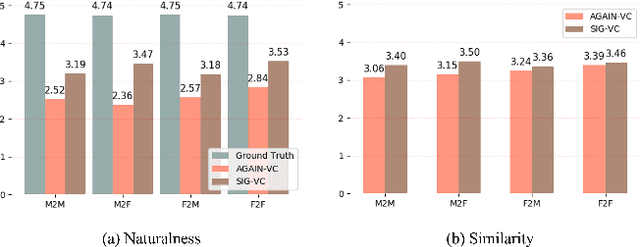
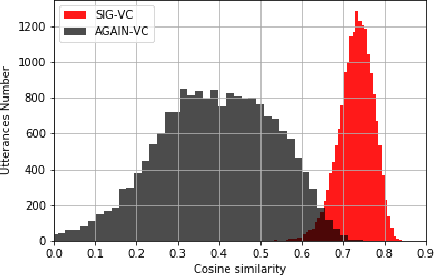
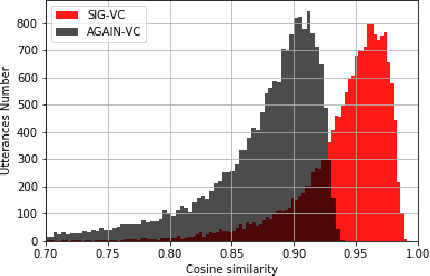
Nowadays, as more and more systems achieve good performance in traditional voice conversion (VC) tasks, people's attention gradually turns to VC tasks under extreme conditions. In this paper, we propose a novel method for zero-shot voice conversion. We aim to obtain intermediate representations for speaker-content disentanglement of speech to better remove speaker information and get pure content information. Accordingly, our proposed framework contains a module that removes the speaker information from the acoustic feature of the source speaker. Moreover, speaker information control is added to our system to maintain the voice cloning performance. The proposed system is evaluated by subjective and objective metrics. Results show that our proposed system significantly reduces the trade-off problem in zero-shot voice conversion, while it also manages to have high spoofing power to the speaker verification system.