 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Sample Quality with Kernels
Sep 13, 2017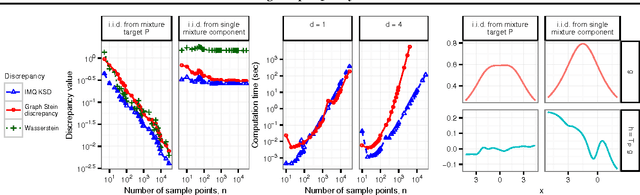
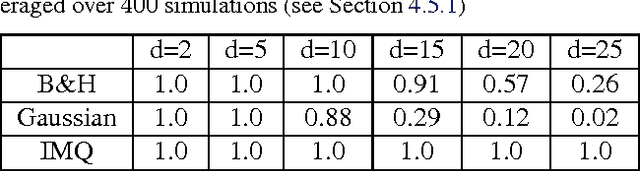
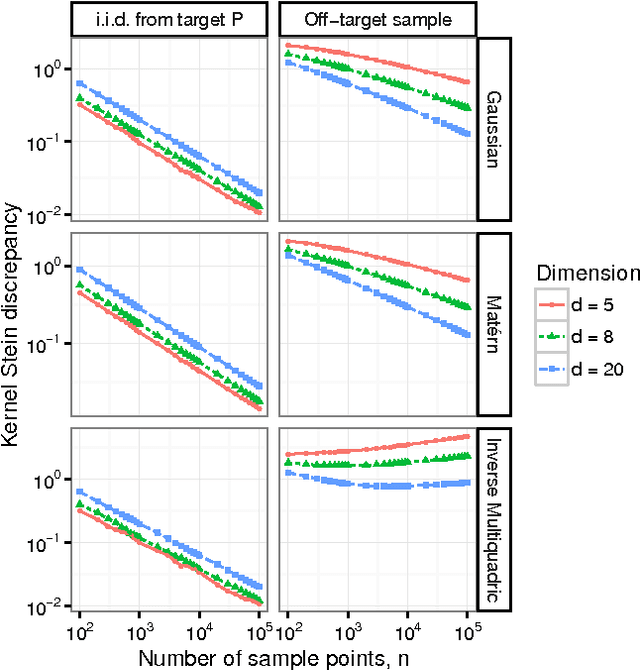
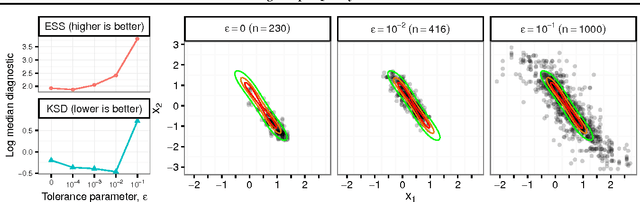
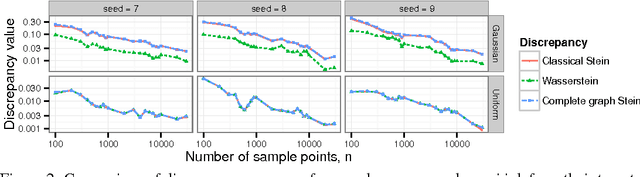
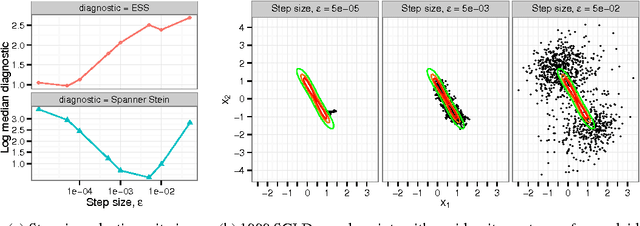
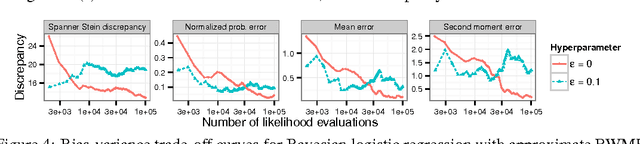
Approximate Markov chain Monte Carlo (MCMC) offers the promise of more rapid sampling at the cost of more biased inference. Since standard MCMC diagnostics fail to detect these biases, researchers have developed computable Stein discrepancy measures that provably determine the convergence of a sample to its target distribution. This approach was recently combined with the theory of reproducing kernels to define a closed-form kernel Stein discrepancy (KSD) computable by summing kernel evaluations across pairs of sample points. We develop a theory of weak convergence for KSDs based on Stein's method, demonstrate that commonly used KSDs fail to detect non-convergence even for Gaussian targets, and show that kernels with slowly decaying tails provably determine convergence for a large class of target distributions. The resulting convergence-determining KSDs are suitable for comparing biased, exact, and deterministic sample sequences and simpler to compute and parallelize than alternative Stein discrepancies. We use our tools to compare biased samplers, select sampler hyperparameters, and improve upon existing KSD approaches to one-sample hypothesis testing and sample quality improvement.
Improving Gibbs Sampler Scan Quality with DoGS
Jul 18, 2017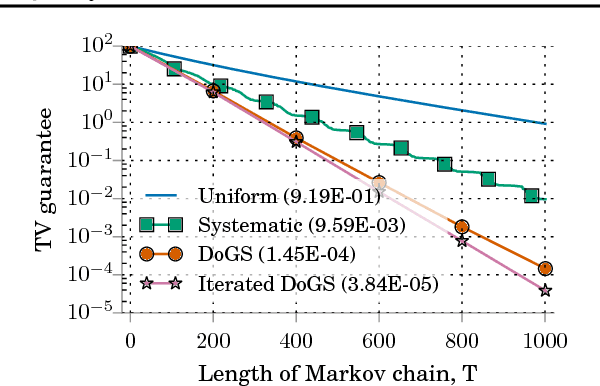
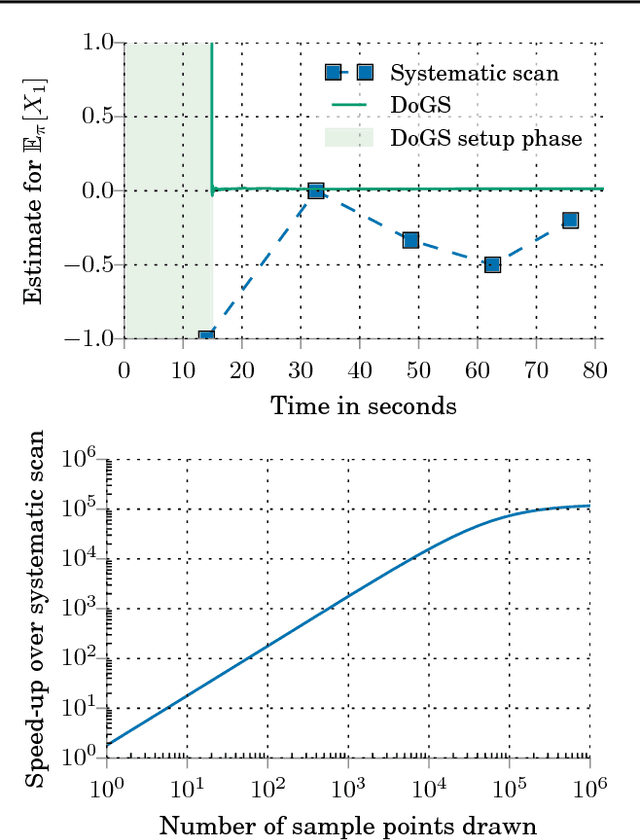
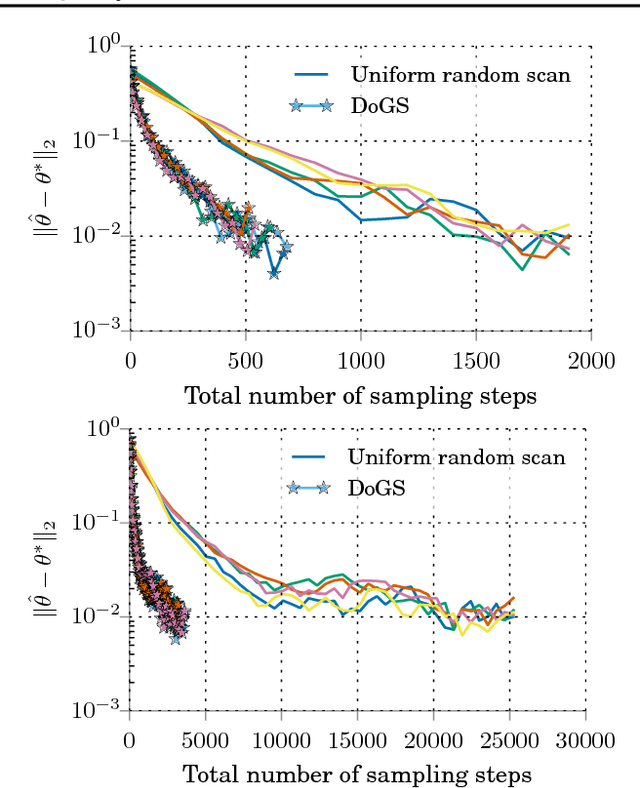
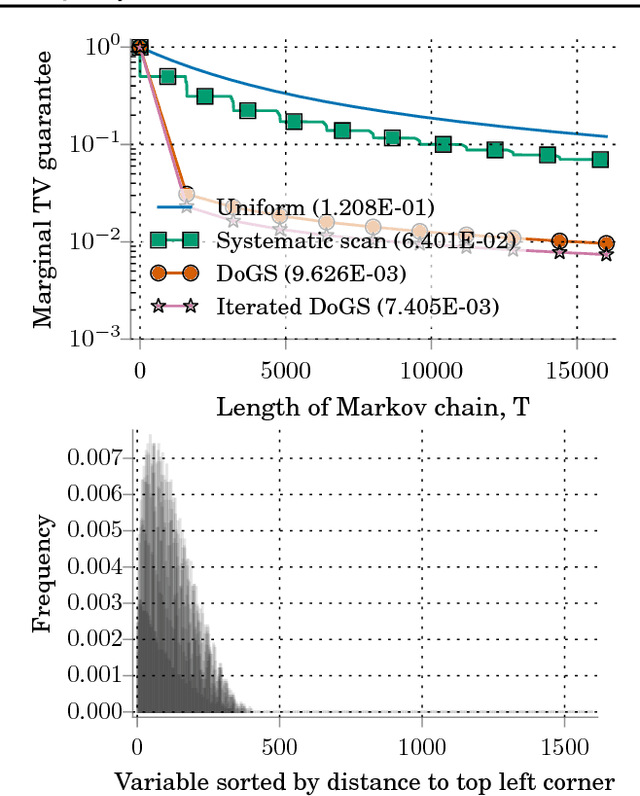
The pairwise influence matrix of Dobrushin has long been used as an analytical tool to bound the rate of convergence of Gibbs sampling. In this work, we use Dobrushin influence as the basis of a practical tool to certify and efficiently improve the quality of a discrete Gibbs sampler. Our Dobrushin-optimized Gibbs samplers (DoGS) offer customized variable selection orders for a given sampling budget and variable subset of interest, explicit bounds on total variation distance to stationarity, and certifiable improvements over the standard systematic and uniform random scan Gibbs samplers. In our experiments with joint image segmentation and object recognition, Markov chain Monte Carlo maximum likelihood estimation, and Ising model inference, DoGS consistently deliver higher-quality inferences with significantly smaller sampling budgets than standard Gibbs samplers.
Measuring Sample Quality with Stein's Method
Mar 06, 2017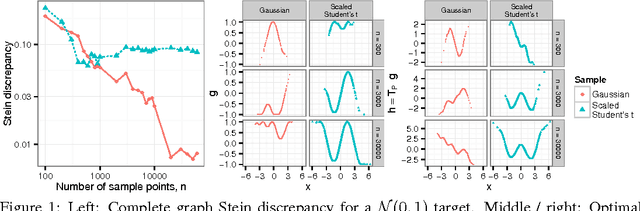
To improve the efficiency of Monte Carlo estimation, practitioners are turning to biased Markov chain Monte Carlo procedures that trade off asymptotic exactness for computational speed. The reasoning is sound: a reduction in variance due to more rapid sampling can outweigh the bias introduced. However, the inexactness creates new challenges for sampler and parameter selection, since standard measures of sample quality like effective sample size do not account for asymptotic bias. To address these challenges, we introduce a new computable quality measure based on Stein's method that quantifies the maximum discrepancy between sample and target expectations over a large class of test functions. We use our tool to compare exact, biased, and deterministic sample sequences and illustrate applications to hyperparameter selection, convergence rate assessment, and quantifying bias-variance tradeoffs in posterior inference.
Jet-Images -- Deep Learning Edition
Jan 22, 2017
Building on the notion of a particle physics detector as a camera and the collimated streams of high energy particles, or jets, it measures as an image, we investigate the potential of machine learning techniques based on deep learning architectures to identify highly boosted W bosons. Modern deep learning algorithms trained on jet images can out-perform standard physically-motivated feature driven approaches to jet tagging. We develop techniques for visualizing how these features are learned by the network and what additional information is used to improve performance. This interplay between physically-motivated feature driven tools and supervised learning algorithms is general and can be used to significantly increase the sensitivity to discover new particles and new forces, and gain a deeper understanding of the physics within jets.
* 32 pages, 24 figures. Version that is published in JHEP
Weighted Classification Cascades for Optimizing Discovery Significance in the HiggsML Challenge
Sep 10, 2015We introduce a minorization-maximization approach to optimizing common measures of discovery significance in high energy physics. The approach alternates between solving a weighted binary classification problem and updating class weights in a simple, closed-form manner. Moreover, an argument based on convex duality shows that an improvement in weighted classification error on any round yields a commensurate improvement in discovery significance. We complement our derivation with experimental results from the 2014 Higgs boson machine learning challenge.
Fuzzy Jets
Sep 07, 2015
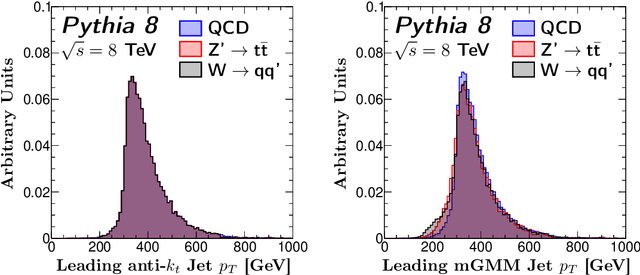
Collimated streams of particles produced in high energy physics experiments are organized using clustering algorithms to form jets. To construct jets, the experimental collaborations based at the Large Hadron Collider (LHC) primarily use agglomerative hierarchical clustering schemes known as sequential recombination. We propose a new class of algorithms for clustering jets that use infrared and collinear safe mixture models. These new algorithms, known as fuzzy jets, are clustered using maximum likelihood techniques and can dynamically determine various properties of jets like their size. We show that the fuzzy jet size adds additional information to conventional jet tagging variables. Furthermore, we study the impact of pileup and show that with some slight modifications to the algorithm, fuzzy jets can be stable up to high pileup interaction multiplicities.
Corrupted Sensing: Novel Guarantees for Separating Structured Signals
Feb 04, 2014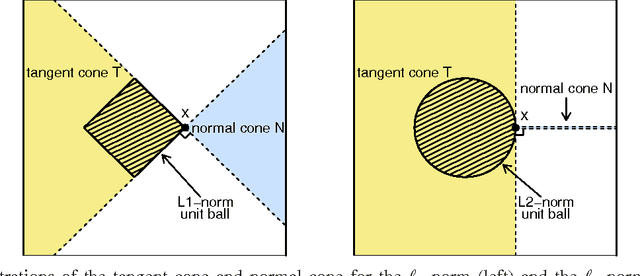
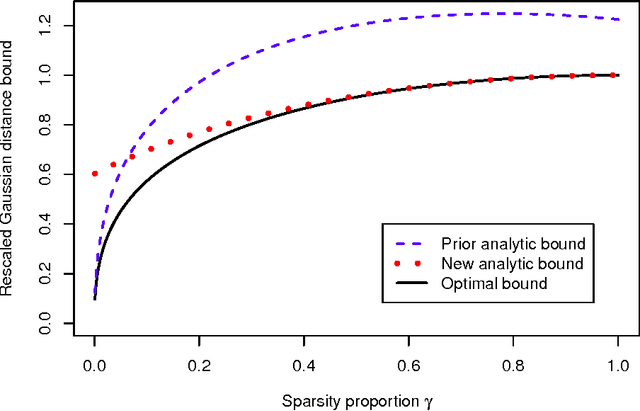
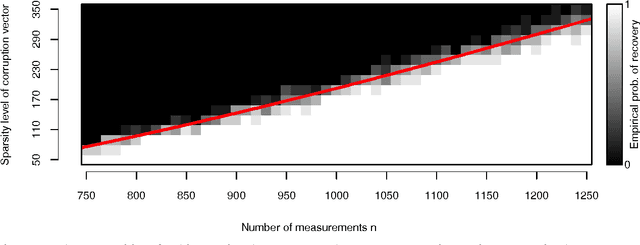
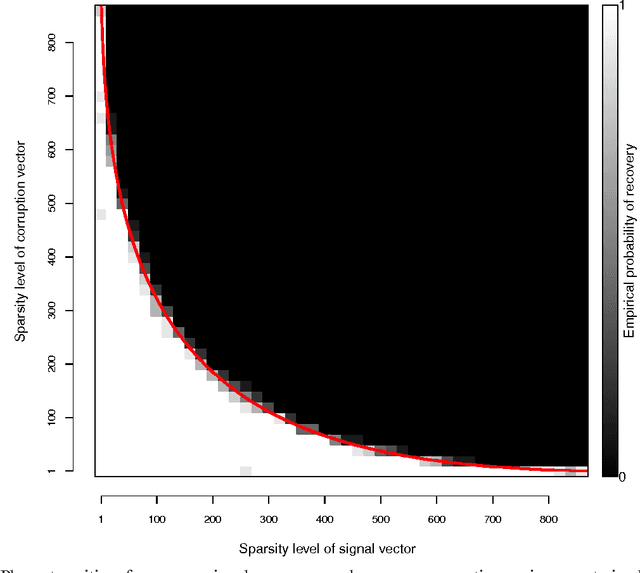
We study the problem of corrupted sensing, a generalization of compressed sensing in which one aims to recover a signal from a collection of corrupted or unreliable measurements. While an arbitrary signal cannot be recovered in the face of arbitrary corruption, tractable recovery is possible when both signal and corruption are suitably structured. We quantify the relationship between signal recovery and two geometric measures of structure, the Gaussian complexity of a tangent cone and the Gaussian distance to a subdifferential. We take a convex programming approach to disentangling signal and corruption, analyzing both penalized programs that trade off between signal and corruption complexity, and constrained programs that bound the complexity of signal or corruption when prior information is available. In each case, we provide conditions for exact signal recovery from structured corruption and stable signal recovery from structured corruption with added unstructured noise. Our simulations demonstrate close agreement between our theoretical recovery bounds and the sharp phase transitions observed in practice. In addition, we provide new interpretable bounds for the Gaussian complexity of sparse vectors, block-sparse vectors, and low-rank matrices, which lead to sharper guarantees of recovery when combined with our results and those in the literature.
* http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=6712045
The asymptotics of ranking algorithms
Nov 26, 2013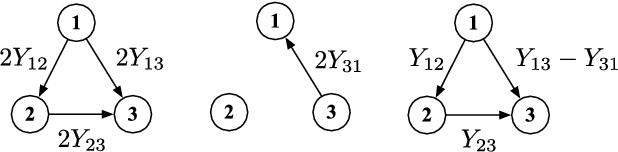
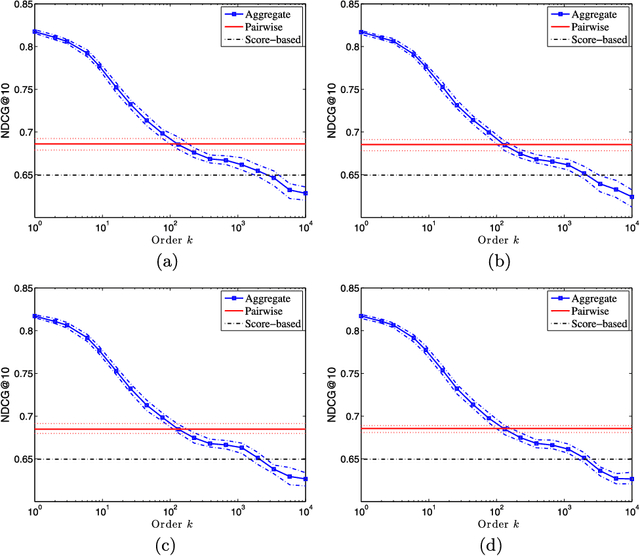
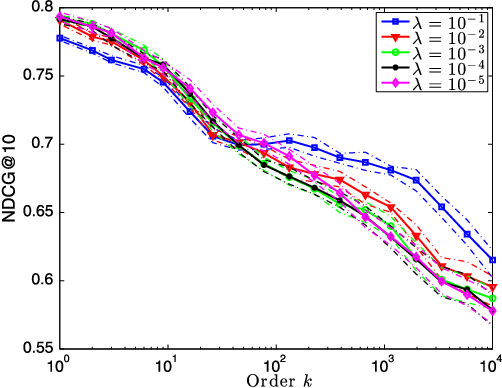
We consider the predictive problem of supervised ranking, where the task is to rank sets of candidate items returned in response to queries. Although there exist statistical procedures that come with guarantees of consistency in this setting, these procedures require that individuals provide a complete ranking of all items, which is rarely feasible in practice. Instead, individuals routinely provide partial preference information, such as pairwise comparisons of items, and more practical approaches to ranking have aimed at modeling this partial preference data directly. As we show, however, such an approach raises serious theoretical challenges. Indeed, we demonstrate that many commonly used surrogate losses for pairwise comparison data do not yield consistency; surprisingly, we show inconsistency even in low-noise settings. With these negative results as motivation, we present a new approach to supervised ranking based on aggregation of partial preferences, and we develop $U$-statistic-based empirical risk minimization procedures. We present an asymptotic analysis of these new procedures, showing that they yield consistency results that parallel those available for classification. We complement our theoretical results with an experiment studying the new procedures in a large-scale web-ranking task.
* Published in at http://dx.doi.org/10.1214/13-AOS1142 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Distributed Matrix Completion and Robust Factorization
Oct 28, 2013
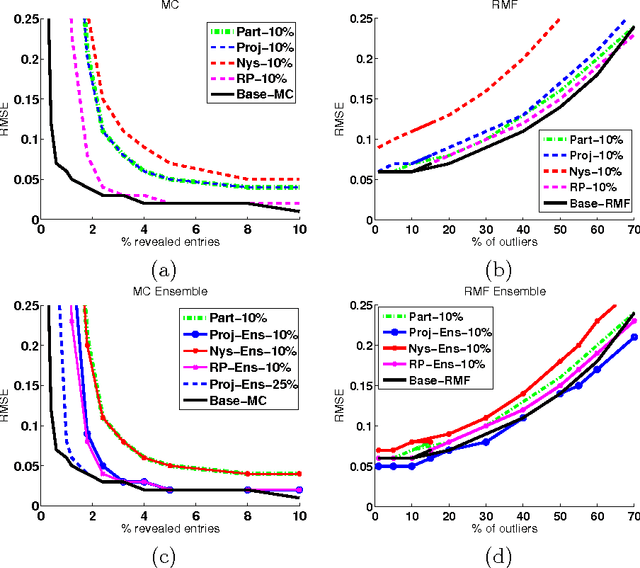
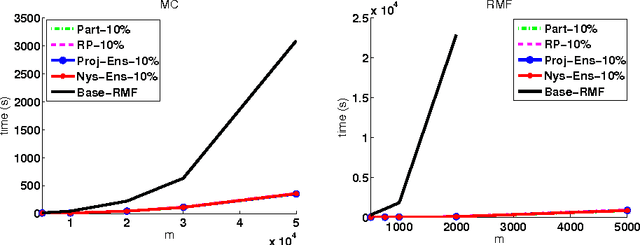
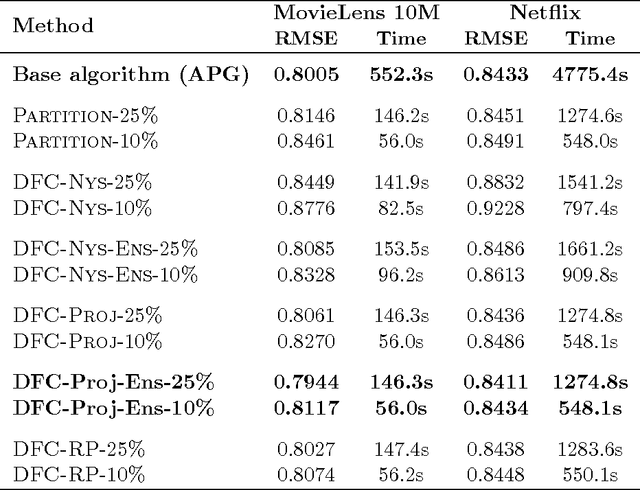
If learning methods are to scale to the massive sizes of modern datasets, it is essential for the field of machine learning to embrace parallel and distributed computing. Inspired by the recent development of matrix factorization methods with rich theory but poor computational complexity and by the relative ease of mapping matrices onto distributed architectures, we introduce a scalable divide-and-conquer framework for noisy matrix factorization. We present a thorough theoretical analysis of this framework in which we characterize the statistical errors introduced by the "divide" step and control their magnitude in the "conquer" step, so that the overall algorithm enjoys high-probability estimation guarantees comparable to those of its base algorithm. We also present experiments in collaborative filtering and video background modeling that demonstrate the near-linear to superlinear speed-ups attainable with this approach.
Distributed Low-rank Subspace Segmentation
Oct 16, 2013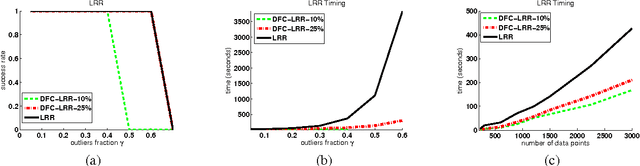
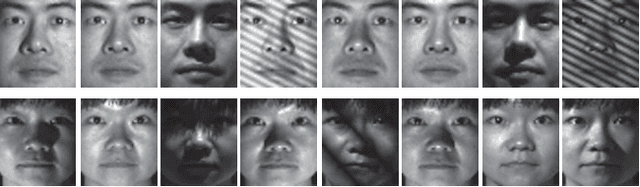
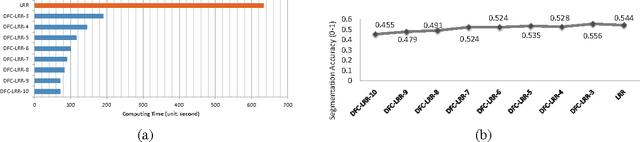
Vision problems ranging from image clustering to motion segmentation to semi-supervised learning can naturally be framed as subspace segmentation problems, in which one aims to recover multiple low-dimensional subspaces from noisy and corrupted input data. Low-Rank Representation (LRR), a convex formulation of the subspace segmentation problem, is provably and empirically accurate on small problems but does not scale to the massive sizes of modern vision datasets. Moreover, past work aimed at scaling up low-rank matrix factorization is not applicable to LRR given its non-decomposable constraints. In this work, we propose a novel divide-and-conquer algorithm for large-scale subspace segmentation that can cope with LRR's non-decomposable constraints and maintains LRR's strong recovery guarantees. This has immediate implications for the scalability of subspace segmentation, which we demonstrate on a benchmark face recognition dataset and in simulations. We then introduce novel applications of LRR-based subspace segmentation to large-scale semi-supervised learning for multimedia event detection, concept detection, and image tagging. In each case, we obtain state-of-the-art results and order-of-magnitude speed ups.