 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Estimation of Conditional Moment Models
Jun 12, 2020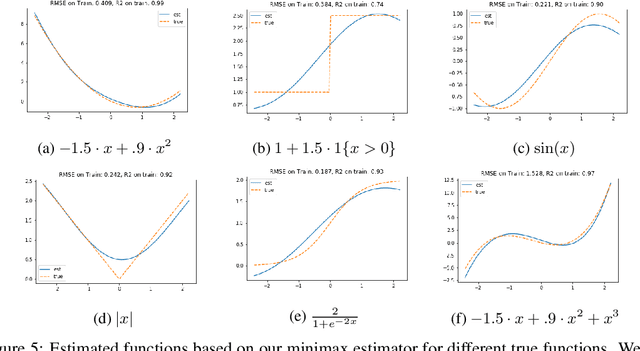
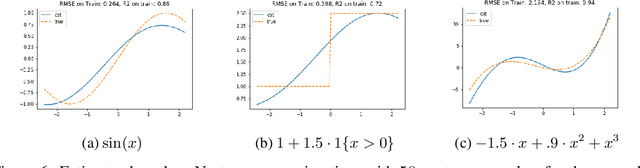
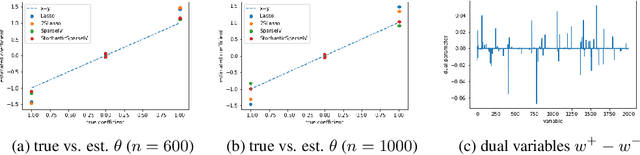
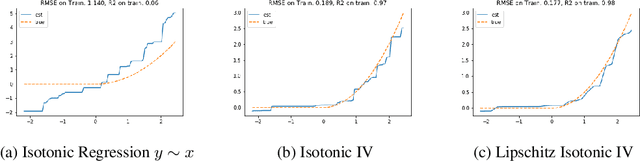
We develop an approach for estimating models described via conditional moment restrictions, with a prototypical application being non-parametric instrumental variable regression. We introduce a min-max criterion function, under which the estimation problem can be thought of as solving a zero-sum game between a modeler who is optimizing over the hypothesis space of the target model and an adversary who identifies violating moments over a test function space. We analyze the statistical estimation rate of the resulting estimator for arbitrary hypothesis spaces, with respect to an appropriate analogue of the mean squared error metric, for ill-posed inverse problems. We show that when the minimax criterion is regularized with a second moment penalty on the test function and the test function space is sufficiently rich, then the estimation rate scales with the critical radius of the hypothesis and test function spaces, a quantity which typically gives tight fast rates. Our main result follows from a novel localized Rademacher analysis of statistical learning problems defined via minimax objectives. We provide applications of our main results for several hypothesis spaces used in practice such as: reproducing kernel Hilbert spaces, high dimensional sparse linear functions, spaces defined via shape constraints, ensemble estimators such as random forests, and neural networks. For each of these applications we provide computationally efficient optimization methods for solving the corresponding minimax problem (e.g. stochastic first-order heuristics for neural networks). In several applications, we show how our modified mean squared error rate, combined with conditions that bound the ill-posedness of the inverse problem, lead to mean squared error rates. We conclude with an extensive experimental analysis of the proposed methods.
Optimal Thinning of MCMC Output
May 08, 2020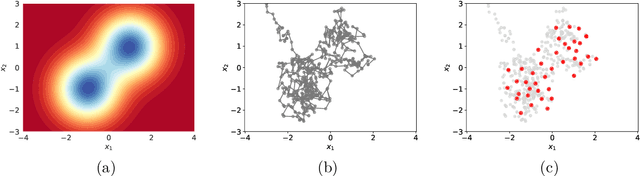


The use of heuristics to assess the convergence and compress the output of Markov chain Monte Carlo can be sub-optimal in terms of the empirical approximations that are produced. Typically a number of the initial states are attributed to "burn in" and removed, whilst the chain can be "thinned" if compression is also required. In this paper we consider the problem of selecting a subset of states, of fixed cardinality, such that the approximation provided by their empirical distribution is close to optimal. A novel method is proposed, based on greedy minimisation of a kernel Stein discrepancy, that is suitable for problems where heavy compression is required. Theoretical results guarantee consistency of the method and its effectiveness is demonstrated in the challenging context of parameter inference for ordinary differential equations. Software is available in the "Stein Thinning" package in both Python and MATLAB, and example code is included.
Weighted Meta-Learning
Mar 20, 2020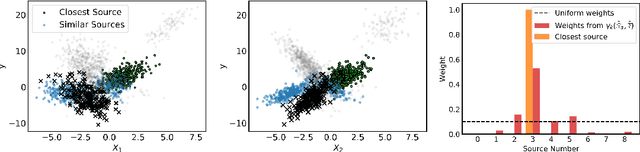
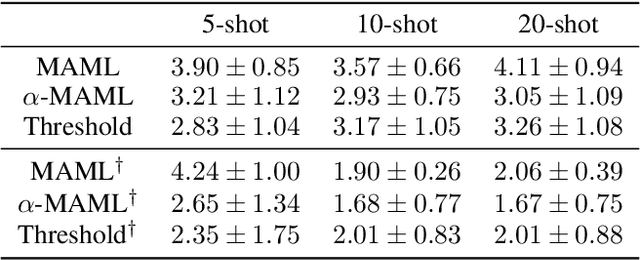
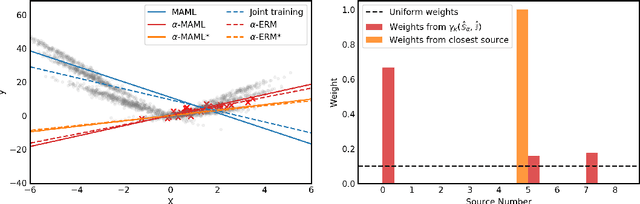
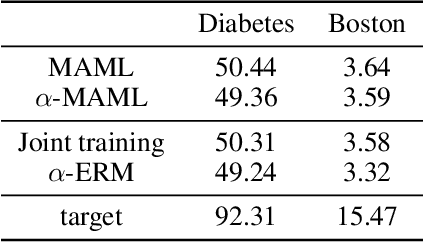
Meta-learning leverages related source tasks to learn an initialization that can be quickly fine-tuned to a target task with limited labeled examples. However, many popular meta-learning algorithms, such as model-agnostic meta-learning (MAML), only assume access to the target samples for fine-tuning. In this work, we provide a general framework for meta-learning based on weighting the loss of different source tasks, where the weights are allowed to depend on the target samples. In this general setting, we provide upper bounds on the distance of the weighted empirical risk of the source tasks and expected target risk in terms of an integral probability metric (IPM) and Rademacher complexity, which apply to a number of meta-learning settings including MAML and a weighted MAML variant. We then develop a learning algorithm based on minimizing the error bound with respect to an empirical IPM, including a weighted MAML algorithm, $\alpha$-MAML. Finally, we demonstrate empirically on several regression problems that our weighted meta-learning algorithm is able to find better initializations than uniformly-weighted meta-learning algorithms, such as MAML.
Approximate Cross-validation: Guarantees for Model Assessment and Selection
Mar 02, 2020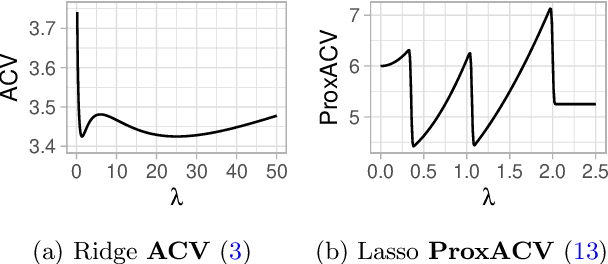
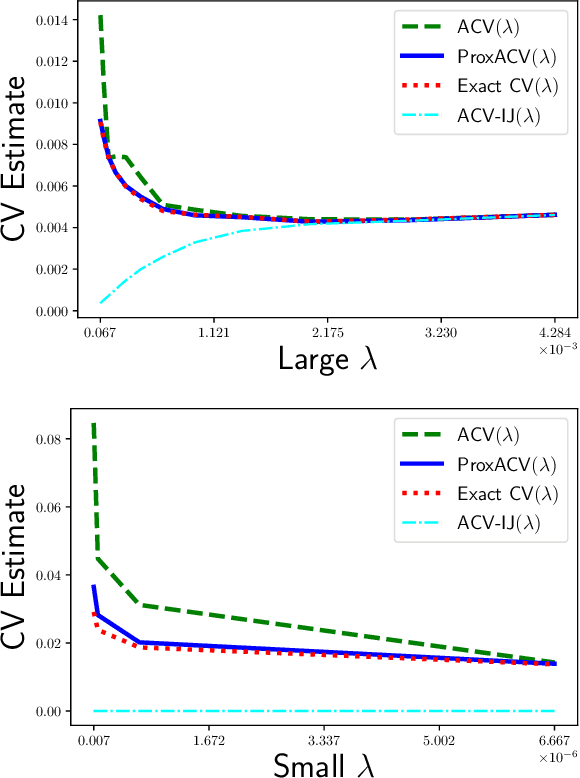
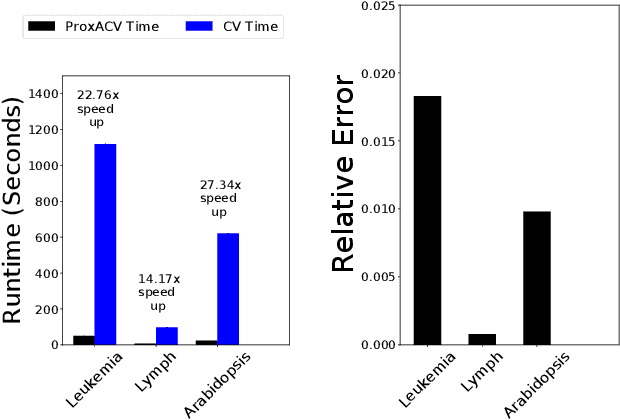
Cross-validation (CV) is a popular approach for assessing and selecting predictive models. However, when the number of folds is large, CV suffers from a need to repeatedly refit a learning procedure on a large number of training datasets. Recent work in empirical risk minimization (ERM) approximates the expensive refitting with a single Newton step warm-started from the full training set optimizer. While this can greatly reduce runtime, several open questions remain including whether these approximations lead to faithful model selection and whether they are suitable for non-smooth objectives. We address these questions with three main contributions: (i) we provide uniform non-asymptotic, deterministic model assessment guarantees for approximate CV; (ii) we show that (roughly) the same conditions also guarantee model selection performance comparable to CV; (iii) we provide a proximal Newton extension of the approximate CV framework for non-smooth prediction problems and develop improved assessment guarantees for problems such as l1-regularized ERM.
Importance Sampling via Local Sensitivity
Nov 04, 2019
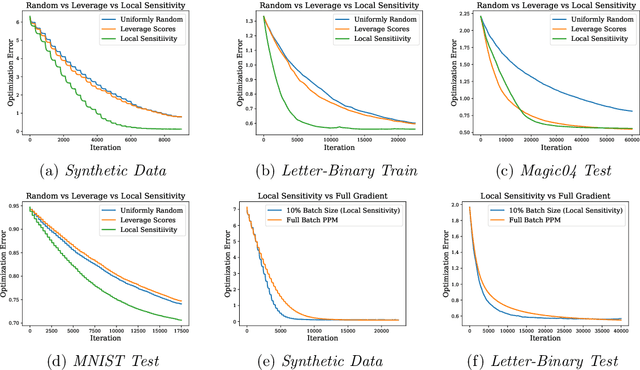
Given a loss function $F:\mathcal{X} \rightarrow \mathbb{R}^+$ that can be written as the sum of losses over a large set of inputs $a_1,\ldots, a_n$, it is often desirable to approximate $F$ by subsampling the input points. Strong theoretical guarantees require taking into account the importance of each point, measured by how much its individual loss contributes to $F(x)$. Maximizing this importance over all $x \in \mathcal{X}$ yields the \emph{sensitivity score} of $a_i$. Sampling with probabilities proportional to these scores gives strong provable guarantees, allowing one to approximately minimize of $F$ using just the subsampled points. Unfortunately, sensitivity sampling is difficult to apply since 1) it is unclear how to efficiently compute the sensitivity scores and 2) the sample size required is often too large to be useful. We propose overcoming both obstacles by introducing the \emph{local sensitivity}, which measures data point importance in a ball around some center $x_0$. We show that the local sensitivity can be efficiently estimated using the \emph{leverage scores} of a quadratic approximation to $F$, and that the sample size required to approximate $F$ around $x_0$ can be bounded. We propose employing local sensitivity sampling in an iterative optimization method and illustrate its usefulness by analyzing its convergence when $F$ is smooth and convex.
Debiasing Linear Prediction
Aug 06, 2019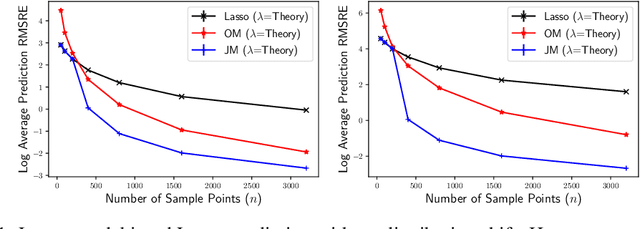
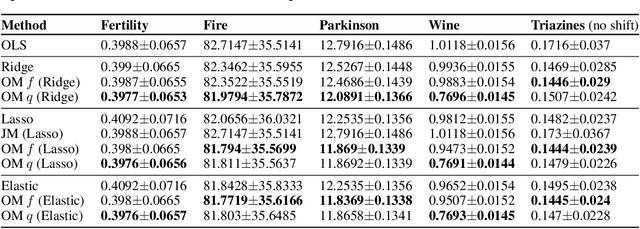
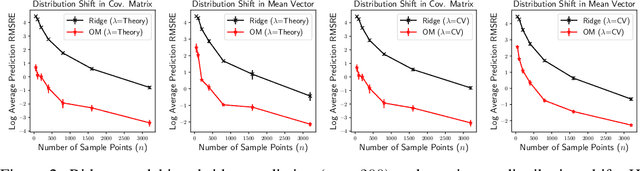
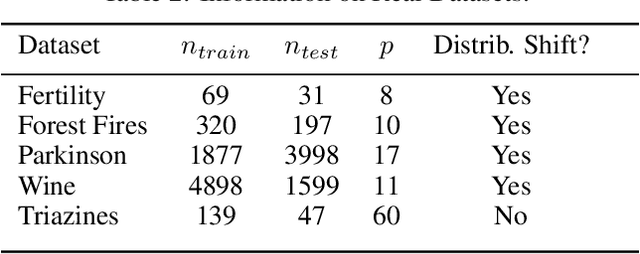
Standard methods in supervised learning separate training and prediction: the model is fit independently of any test points it may encounter. However, can knowledge of the next test point $\mathbf{x}_{\star}$ be exploited to improve prediction accuracy? We address this question in the context of linear prediction, showing how debiasing techniques can be used transductively to combat regularization bias. We first lower bound the $\mathbf{x}_{\star}$ prediction error of ridge regression and the Lasso, showing that they must incur significant bias in certain test directions. Then, building on techniques from semi-parametric inference, we provide non-asymptotic upper bounds on the $\mathbf{x}_{\star}$ prediction error of two transductive, debiased prediction rules. We conclude by showing the efficacy of our methods on both synthetic and real data, highlighting the improvements test-point-tailored debiasing can provide in settings with distribution shift.
A Kernel Stein Test for Comparing Latent Variable Models
Jul 01, 2019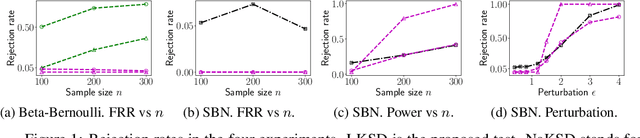

We propose a nonparametric, kernel-based test to assess the relative goodness of fit of latent variable models with intractable unnormalized densities. Our test generalises the kernel Stein discrepancy (KSD) tests of (Liu et al., 2016, Chwialkowski et al., 2016, Yang et al., 2018, Jitkrittum et al., 2018) which required exact access to unnormalized densities. Our new test relies on the simple idea of using an approximate observed-variable marginal in place of the exact, intractable one. As our main theoretical contribution, we prove that the new test, with a properly corrected threshold, has a well-controlled type-I error. In the case of models with low-dimensional latent structure and high-dimensional observations, our test significantly outperforms the relative maximum mean discrepancy test (Bounliphone et al., 2015) , which cannot exploit the latent structure.
Minimum Stein Discrepancy Estimators
Jun 19, 2019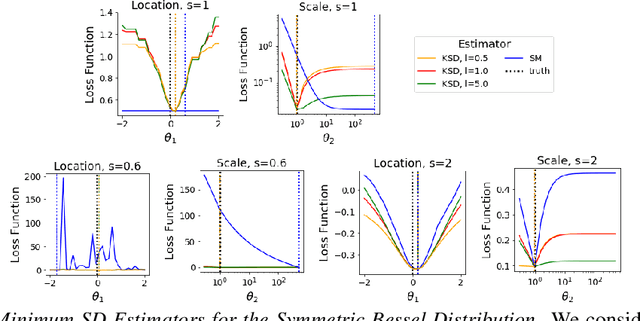

When maximum likelihood estimation is infeasible, one often turns to score matching, contrastive divergence, or minimum probability flow learning to obtain tractable parameter estimates. We provide a unifying perspective of these techniques as minimum Stein discrepancy estimators and use this lens to design new diffusion kernel Stein discrepancy (DKSD) and diffusion score matching (DSM) estimators with complementary strengths. We establish the consistency, asymptotic normality, and robustness of DKSD and DSM estimators, derive stochastic Riemannian gradient descent algorithms for their efficient optimization, and demonstrate their advantages over score matching in models with non-smooth densities or heavy tailed distributions.
Stochastic Runge-Kutta Accelerates Langevin Monte Carlo and Beyond
Jun 19, 2019
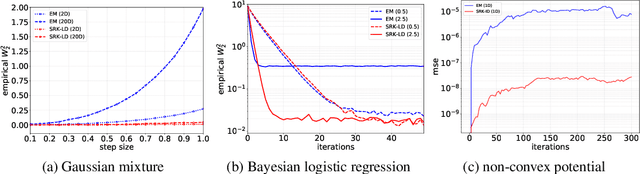
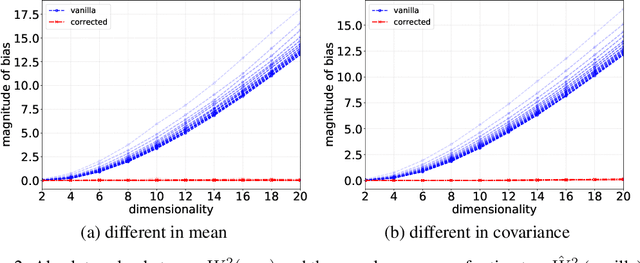
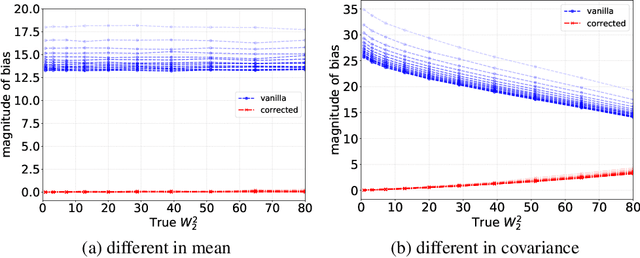
Sampling with Markov chain Monte Carlo methods typically amounts to discretizing some continuous-time dynamics with numerical integration. In this paper, we establish the convergence rate of sampling algorithms obtained by discretizing smooth It\^o diffusions exhibiting fast Wasserstein-$2$ contraction, based on local deviation properties of the integration scheme. In particular, we study a sampling algorithm constructed by discretizing the overdamped Langevin diffusion with the method of stochastic Runge-Kutta. For strongly convex potentials that are smooth up to a certain order, its iterates converge to the target distribution in $2$-Wasserstein distance in $\tilde{\mathcal{O}}(d\epsilon^{-2/3})$ iterations. This improves upon the best-known rate for strongly log-concave sampling based on the overdamped Langevin equation using only the gradient oracle without adjustment. In addition, we extend our analysis of stochastic Runge-Kutta methods to uniformly dissipative diffusions with possibly non-convex potentials and show they achieve better rates compared to the Euler-Maruyama scheme in terms of the dependence on tolerance $\epsilon$. Numerical studies show that these algorithms lead to better stability and lower asymptotic errors.
Stein Point Markov Chain Monte Carlo
May 09, 2019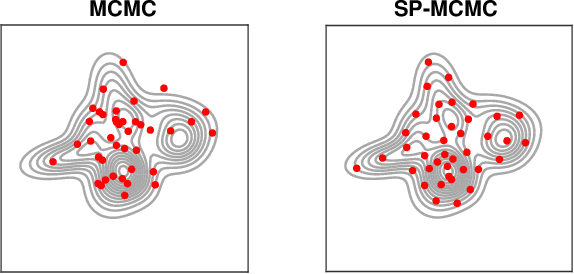
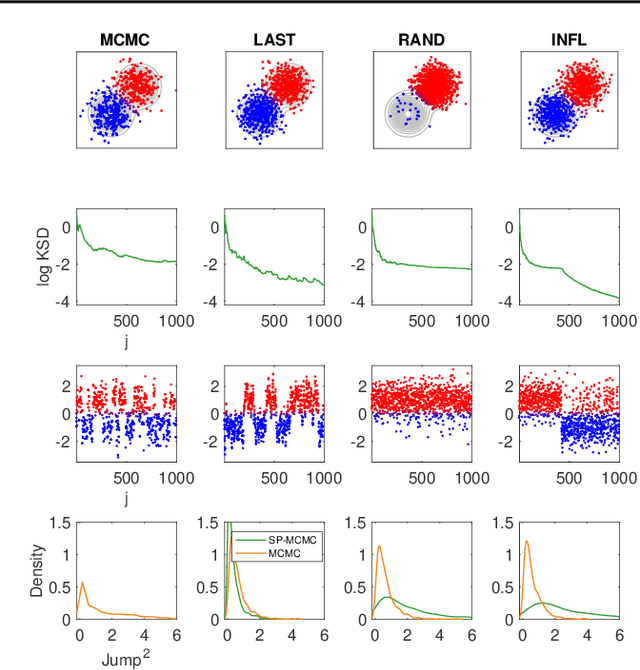
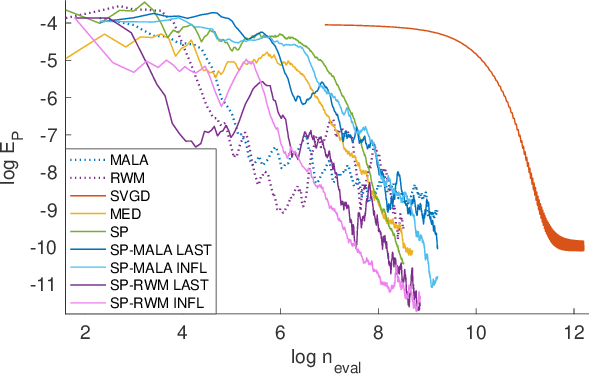
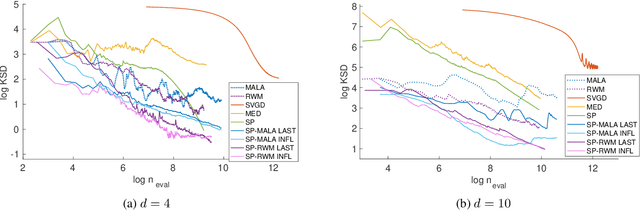
An important task in machine learning and statistics is the approximation of a probability measure by an empirical measure supported on a discrete point set. Stein Points are a class of algorithms for this task, which proceed by sequentially minimising a Stein discrepancy between the empirical measure and the target and, hence, require the solution of a non-convex optimisation problem to obtain each new point. This paper removes the need to solve this optimisation problem by, instead, selecting each new point based on a Markov chain sample path. This significantly reduces the computational cost of Stein Points and leads to a suite of algorithms that are straightforward to implement. The new algorithms are illustrated on a set of challenging Bayesian inference problems, and rigorous theoretical guarantees of consistency are established.