 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelping Crisis Responders Find the Informative Needle in the Tweet Haystack
Jan 29, 2018
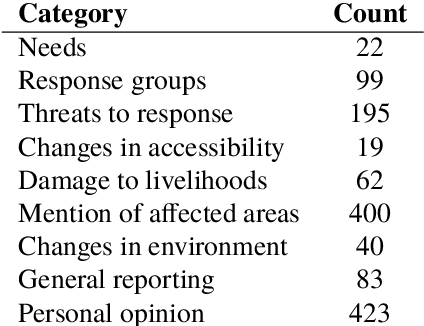
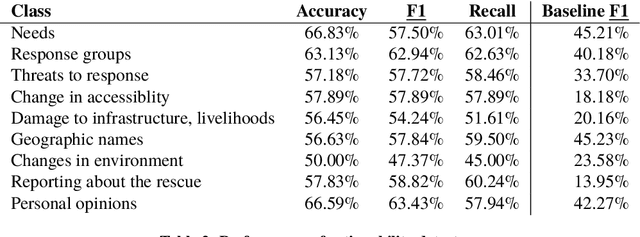
Crisis responders are increasingly using social media, data and other digital sources of information to build a situational understanding of a crisis situation in order to design an effective response. However with the increased availability of such data, the challenge of identifying relevant information from it also increases. This paper presents a successful automatic approach to handling this problem. Messages are filtered for informativeness based on a definition of the concept drawn from prior research and crisis response experts. Informative messages are tagged for actionable data -- for example, people in need, threats to rescue efforts, changes in environment, and so on. In all, eight categories of actionability are identified. The two components -- informativeness and actionability classification -- are packaged together as an openly-available tool called Emina (Emergent Informativeness and Actionability).
Tracking the Diffusion of Named Entities
Dec 29, 2017
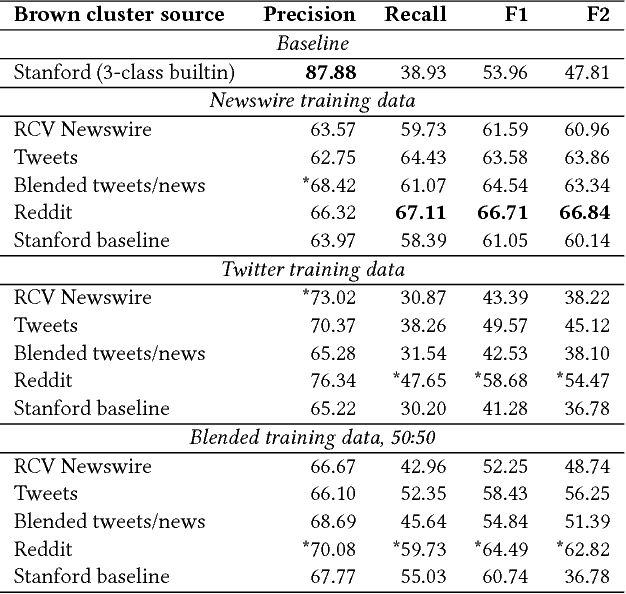
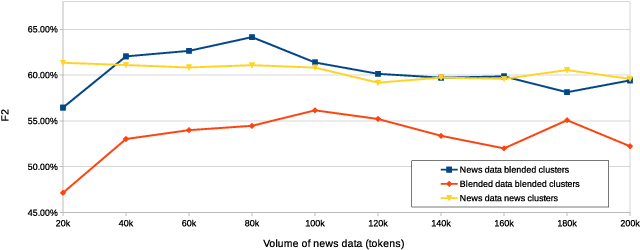
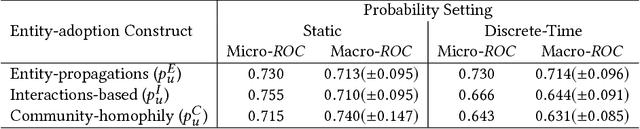
Existing studies of how information diffuses across social networks have thus far concentrated on analysing and recovering the spread of deterministic innovations such as URLs, hashtags, and group membership. However investigating how mentions of real-world entities appear and spread has yet to be explored, largely due to the computationally intractable nature of performing large-scale entity extraction. In this paper we present, to the best of our knowledge, one of the first pieces of work to closely examine the diffusion of named entities on social media, using Reddit as our case study platform. We first investigate how named entities can be accurately recognised and extracted from discussion posts. We then use these extracted entities to study the patterns of entity cascades and how the probability of a user adopting an entity (i.e. mentioning it) is associated with exposures to the entity. We put these pieces together by presenting a parallelised diffusion model that can forecast the probability of entity adoption, finding that the influence of adoption between users can be characterised by their prior interactions -- as opposed to whether the users propagated entity-adoptions beforehand. Our findings have important implications for researchers studying influence and language, and for community analysts who wish to understand entity-level influence dynamics.
Simple Open Stance Classification for Rumour Analysis
Sep 14, 2017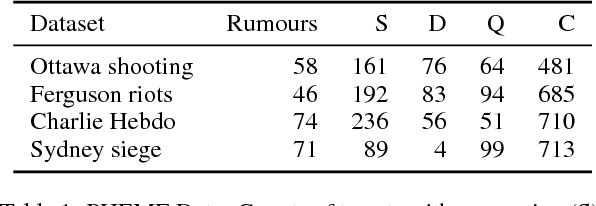
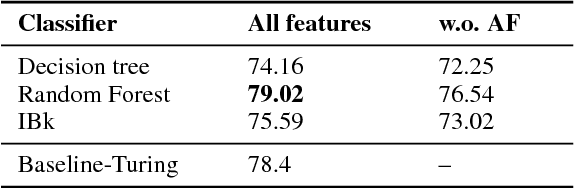


Stance classification determines the attitude, or stance, in a (typically short) text. The task has powerful applications, such as the detection of fake news or the automatic extraction of attitudes toward entities or events in the media. This paper describes a surprisingly simple and efficient classification approach to open stance classification in Twitter, for rumour and veracity classification. The approach profits from a novel set of automatically identifiable problem-specific features, which significantly boost classifier accuracy and achieve above state-of-the-art results on recent benchmark datasets. This calls into question the value of using complex sophisticated models for stance classification without first doing informed feature extraction.
SemEval-2017 Task 8: RumourEval: Determining rumour veracity and support for rumours
Apr 20, 2017
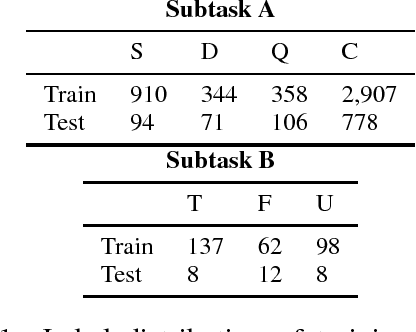

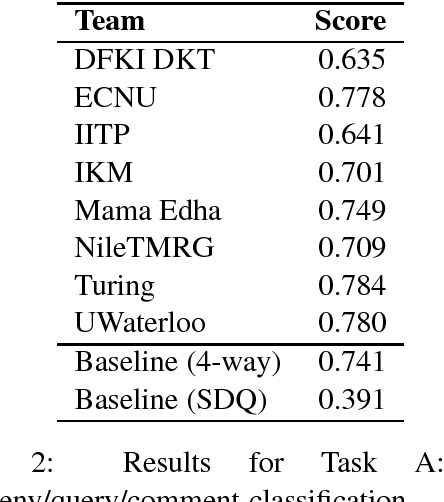
Media is full of false claims. Even Oxford Dictionaries named "post-truth" as the word of 2016. This makes it more important than ever to build systems that can identify the veracity of a story, and the kind of discourse there is around it. RumourEval is a SemEval shared task that aims to identify and handle rumours and reactions to them, in text. We present an annotation scheme, a large dataset covering multiple topics - each having their own families of claims and replies - and use these to pose two concrete challenges as well as the results achieved by participants on these challenges.
Generalisation in Named Entity Recognition: A Quantitative Analysis
Mar 07, 2017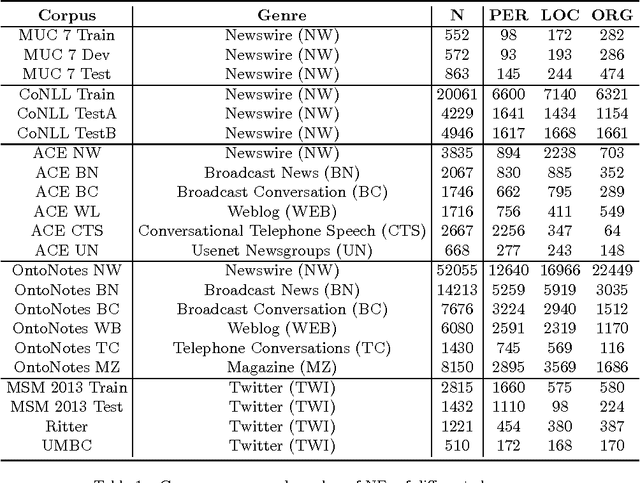
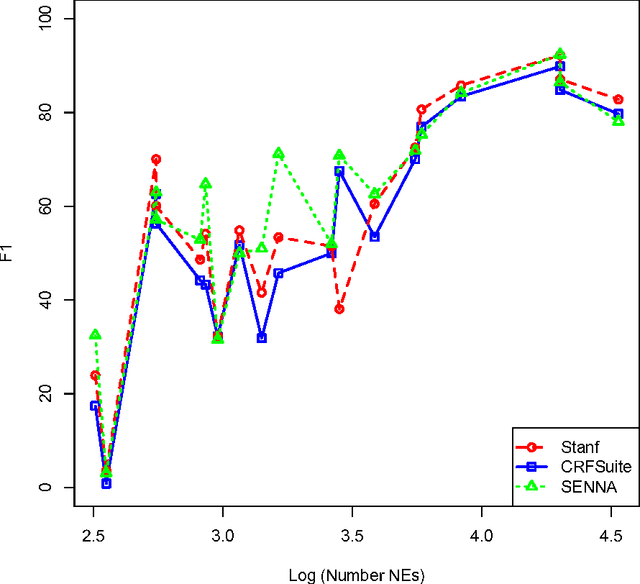

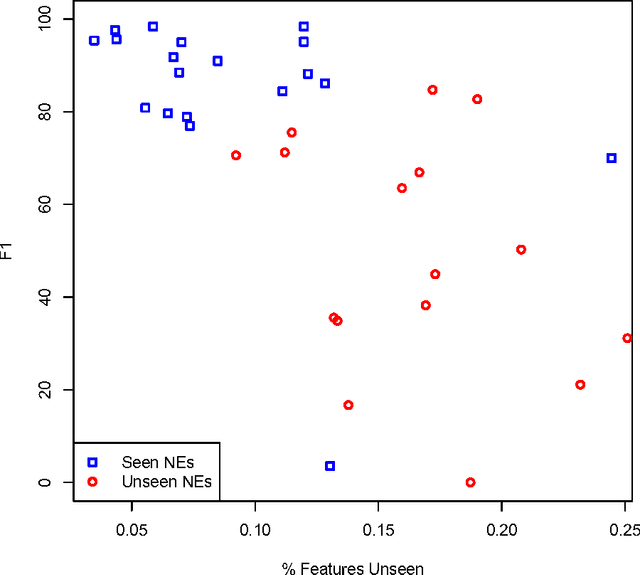
Named Entity Recognition (NER) is a key NLP task, which is all the more challenging on Web and user-generated content with their diverse and continuously changing language. This paper aims to quantify how this diversity impacts state-of-the-art NER methods, by measuring named entity (NE) and context variability, feature sparsity, and their effects on precision and recall. In particular, our findings indicate that NER approaches struggle to generalise in diverse genres with limited training data. Unseen NEs, in particular, play an important role, which have a higher incidence in diverse genres such as social media than in more regular genres such as newswire. Coupled with a higher incidence of unseen features more generally and the lack of large training corpora, this leads to significantly lower F1 scores for diverse genres as compared to more regular ones. We also find that leading systems rely heavily on surface forms found in training data, having problems generalising beyond these, and offer explanations for this observation.
Desiderata for Vector-Space Word Representations
Aug 06, 2016A plethora of vector-space representations for words is currently available, which is growing. These consist of fixed-length vectors containing real values, which represent a word. The result is a representation upon which the power of many conventional information processing and data mining techniques can be brought to bear, as long as the representations are designed with some forethought and fit certain constraints. This paper details desiderata for the design of vector space representations of words.
USFD: Twitter NER with Drift Compensation and Linked Data
Nov 10, 2015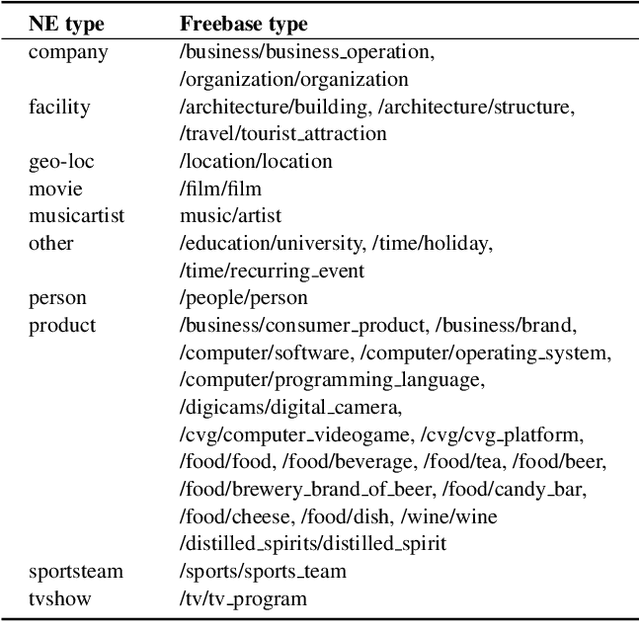
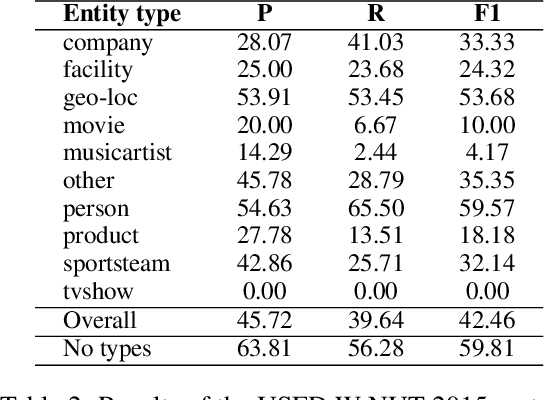
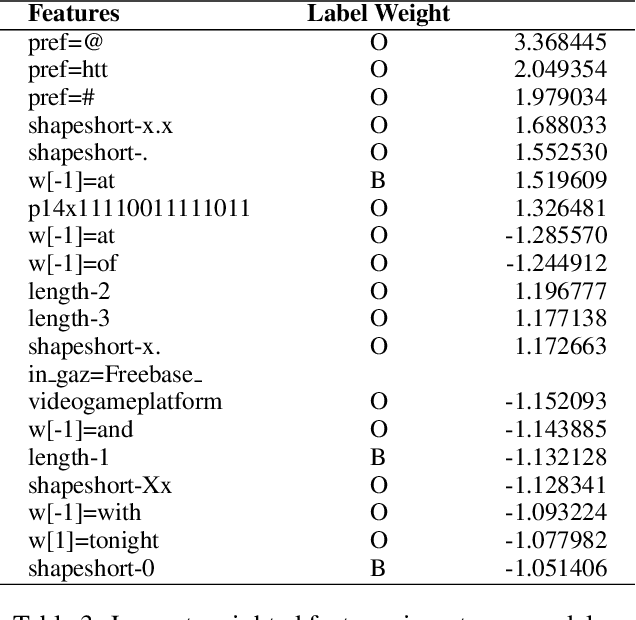
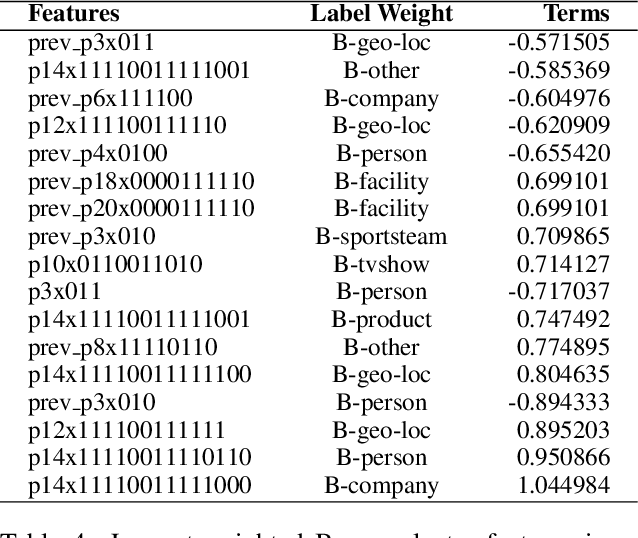
This paper describes a pilot NER system for Twitter, comprising the USFD system entry to the W-NUT 2015 NER shared task. The goal is to correctly label entities in a tweet dataset, using an inventory of ten types. We employ structured learning, drawing on gazetteers taken from Linked Data, and on unsupervised clustering features, and attempting to compensate for stylistic and topic drift - a key challenge in social media text. Our result is competitive; we provide an analysis of the components of our methodology, and an examination of the target dataset in the context of this task.
* Paper in ACL anthology: https://aclweb.org/anthology/W/W15/W15-4306.bib
Analysis of Named Entity Recognition and Linking for Tweets
Oct 27, 2014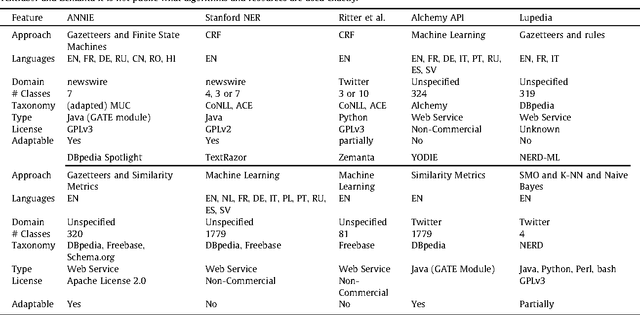
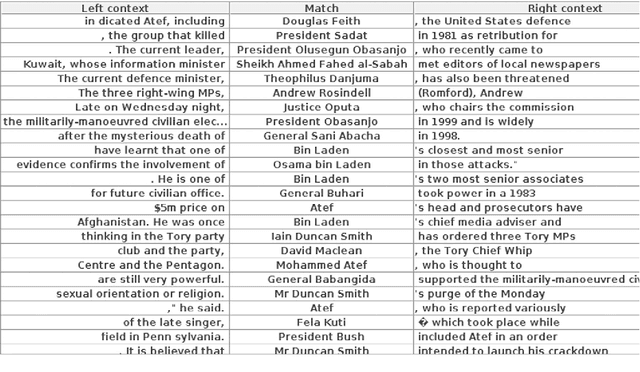

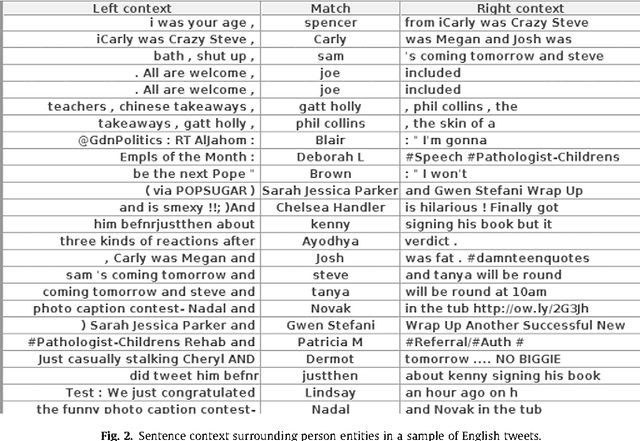
Applying natural language processing for mining and intelligent information access to tweets (a form of microblog) is a challenging, emerging research area. Unlike carefully authored news text and other longer content, tweets pose a number of new challenges, due to their short, noisy, context-dependent, and dynamic nature. Information extraction from tweets is typically performed in a pipeline, comprising consecutive stages of language identification, tokenisation, part-of-speech tagging, named entity recognition and entity disambiguation (e.g. with respect to DBpedia). In this work, we describe a new Twitter entity disambiguation dataset, and conduct an empirical analysis of named entity recognition and disambiguation, investigating how robust a number of state-of-the-art systems are on such noisy texts, what the main sources of error are, and which problems should be further investigated to improve the state of the art.
* 35 pages, accepted to journal Information Processing and Management
TempEval-3: Evaluating Events, Time Expressions, and Temporal Relations
May 25, 2014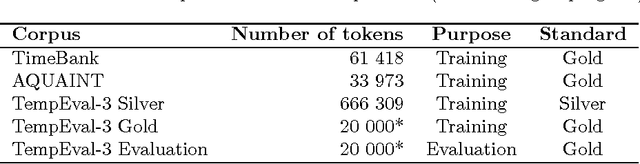
We describe the TempEval-3 task which is currently in preparation for the SemEval-2013 evaluation exercise. The aim of TempEval is to advance research on temporal information processing. TempEval-3 follows on from previous TempEval events, incorporating: a three-part task structure covering event, temporal expression and temporal relation extraction; a larger dataset; and single overall task quality scores.
Clinical TempEval
Mar 19, 2014We describe the Clinical TempEval task which is currently in preparation for the SemEval-2015 evaluation exercise. This task involves identifying and describing events, times and the relations between them in clinical text. Six discrete subtasks are included, focusing on recognising mentions of times and events, describing those mentions for both entity types, identifying the relation between an event and the document creation time, and identifying narrative container relations.