 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Size-Performance Tradeoffs: Weighing PoS Tagger Models
Apr 16, 2021
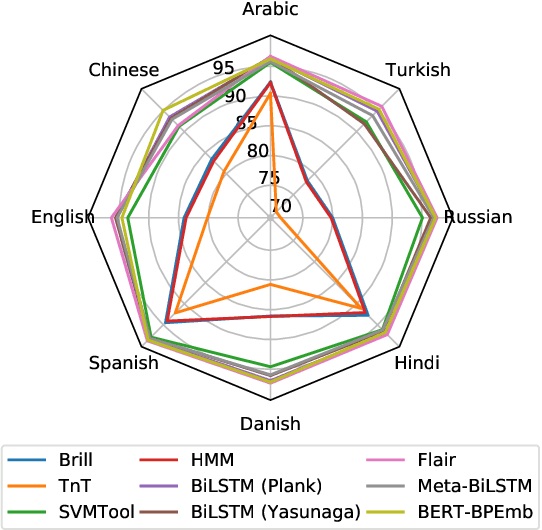
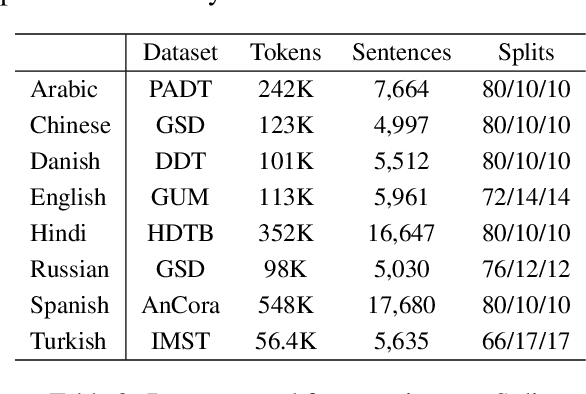
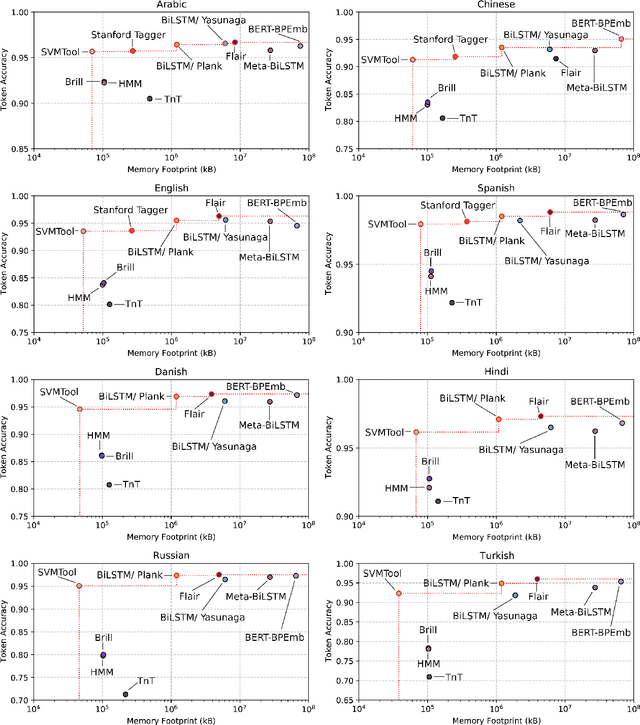
Improvement in machine learning-based NLP performance are often presented with bigger models and more complex code. This presents a trade-off: better scores come at the cost of larger tools; bigger models tend to require more during training and inference time. We present multiple methods for measuring the size of a model, and for comparing this with the model's performance. In a case study over part-of-speech tagging, we then apply these techniques to taggers for eight languages and present a novel analysis identifying which taggers are size-performance optimal. Results indicate that some classical taggers place on the size-performance skyline across languages. Further, although the deep models have highest performance for multiple scores, it is often not the most complex of these that reach peak performance.
Discriminating Between Similar Nordic Languages
Dec 11, 2020
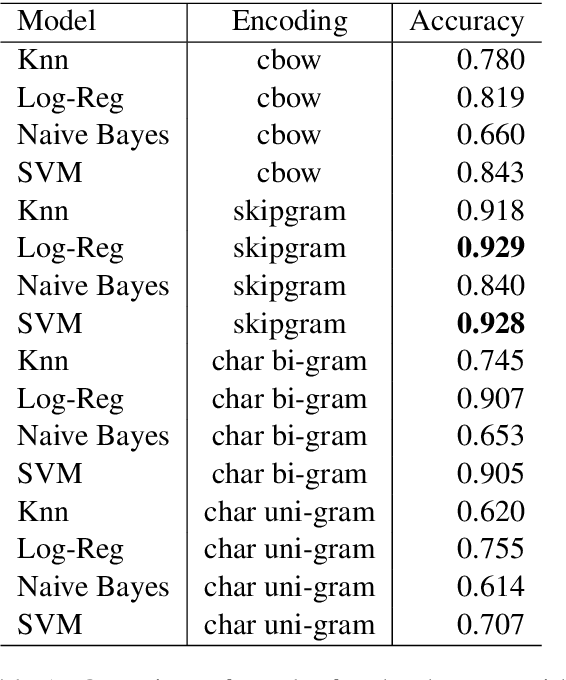
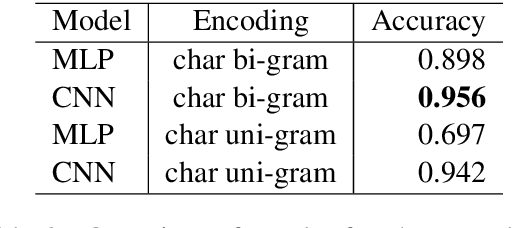
Automatic language identification is a challenging problem. Discriminating between closely related languages is especially difficult. This paper presents a machine learning approach for automatic language identification for the Nordic languages, which often suffer miscategorisation by existing state-of-the-art tools. Concretely we will focus on discrimination between six Nordic languages: Danish, Swedish, Norwegian (Nynorsk), Norwegian (Bokm{\aa}l), Faroese and Icelandic.
Power Consumption Variation over Activation Functions
Jun 12, 2020
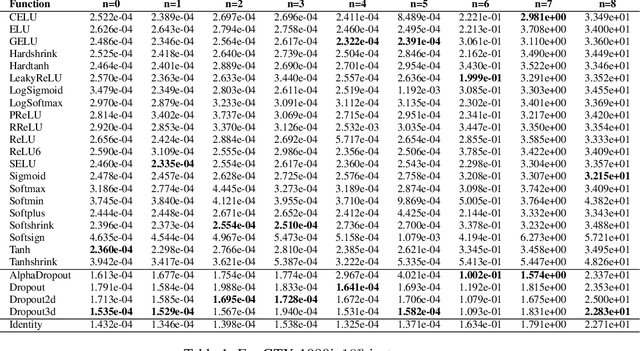
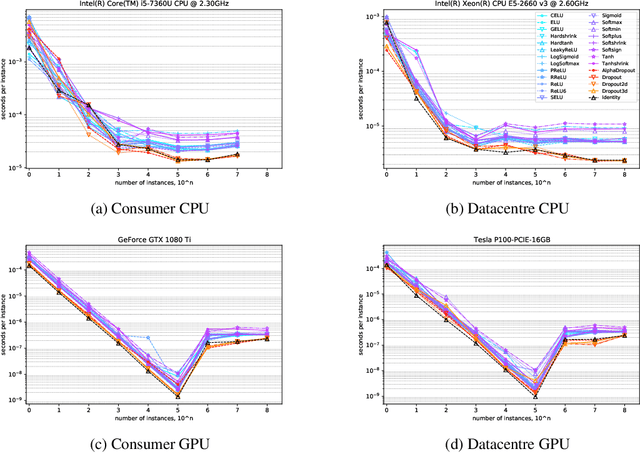
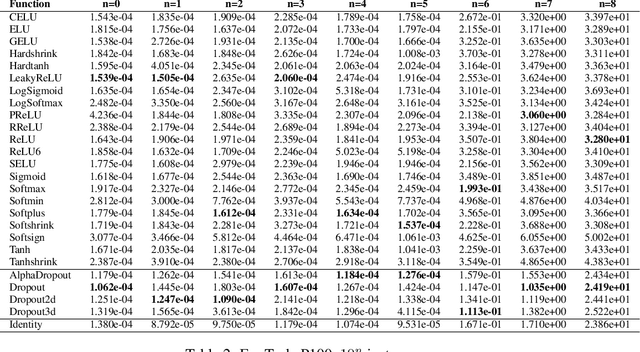
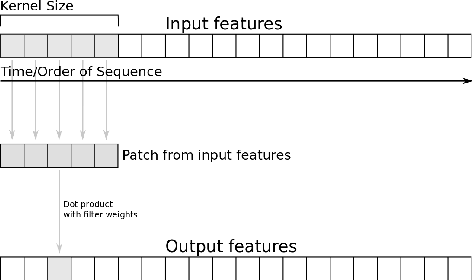
The power that machine learning models consume when making predictions can be affected by a model's architecture. This paper presents various estimates of power consumption for a range of different activation functions, a core factor in neural network model architecture design. Substantial differences in hardware performance exist between activation functions. This difference informs how power consumption in machine learning models can be reduced.
SemEval-2020 Task 12: Multilingual Offensive Language Identification in Social Media (OffensEval 2020)
Jun 12, 2020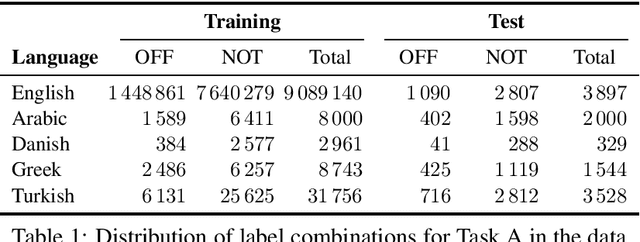
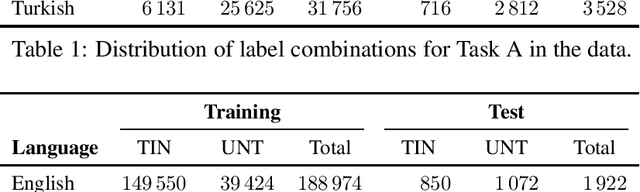
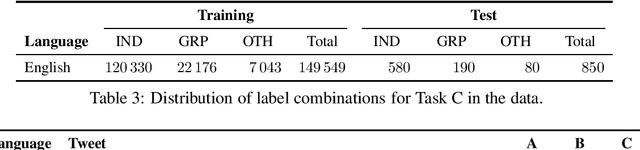

We present the results and main findings of SemEval-2020 Task 12 on Multilingual Offensive Language Identification in Social Media (OffensEval 2020). The task involves three subtasks corresponding to the hierarchical taxonomy of the OLID schema (Zampieri et al., 2019a) from OffensEval 2019. The task featured five languages: English, Arabic, Danish, Greek, and Turkish for Subtask A. In addition, English also featured Subtasks B and C. OffensEval 2020 was one of the most popular tasks at SemEval-2020 attracting a large number of participants across all subtasks and also across all languages. A total of 528 teams signed up to participate in the task, 145 teams submitted systems during the evaluation period, and 70 submitted system description papers.
Directions in Abusive Language Training Data: Garbage In, Garbage Out
Apr 06, 2020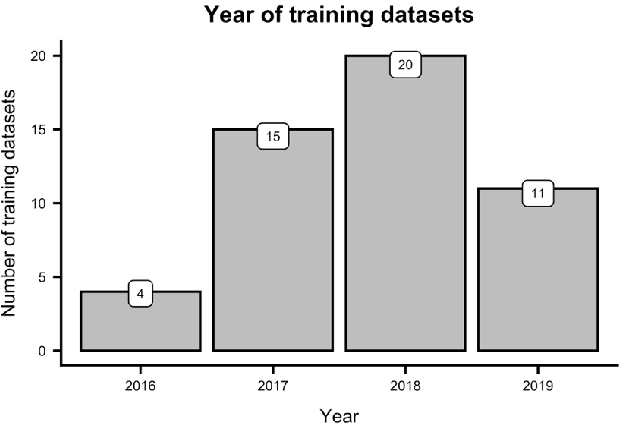
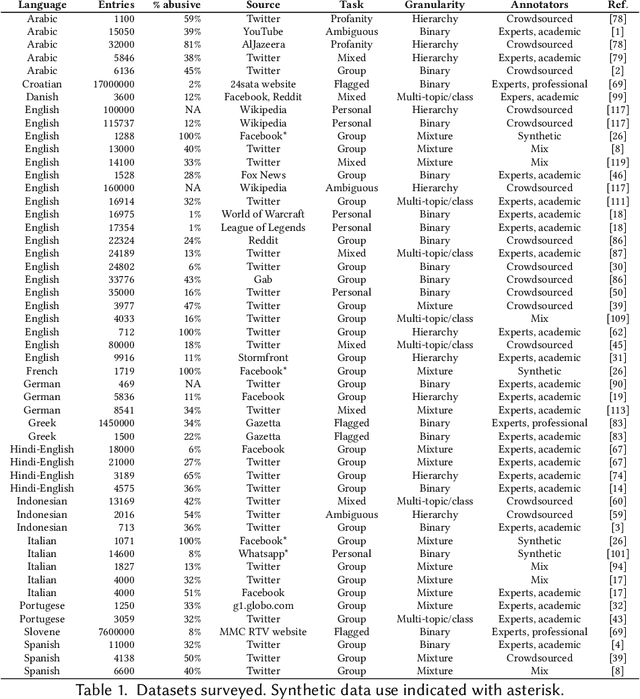
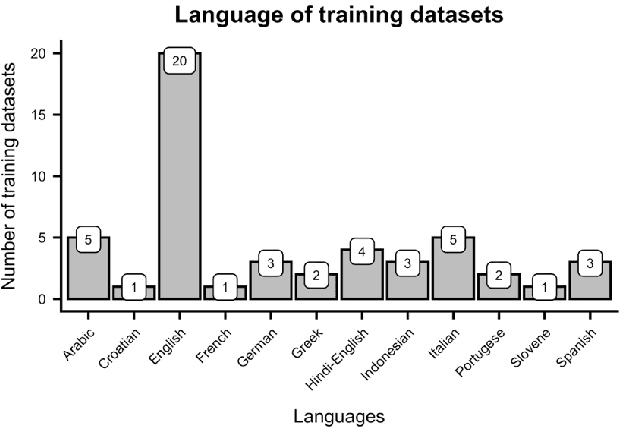
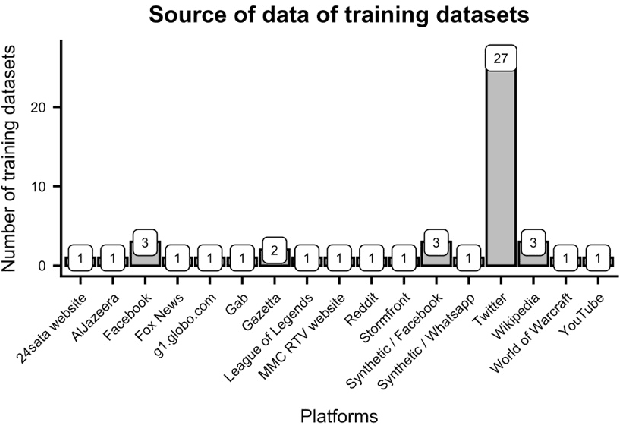
Data-driven analysis and detection of abusive online content covers many different tasks, phenomena, contexts, and methodologies. This paper systematically reviews abusive language dataset creation and content in conjunction with an open website for cataloguing abusive language data. This collection of knowledge leads to a synthesis providing evidence-based recommendations for practitioners working with this complex and highly diverse data.
The Rumour Mill: Making the Spread of Misinformation Explicit and Tangible
Feb 16, 2020
Misinformation spread presents a technological and social threat to society. With the advance of AI-based language models, automatically generated texts have become difficult to identify and easy to create at scale. We present "The Rumour Mill", a playful art piece, designed as a commentary on the spread of rumours and automatically-generated misinformation. The mill is a tabletop interactive machine, which invites a user to experience the process of creating believable text by interacting with different tangible controls on the mill. The user manipulates visible parameters to adjust the genre and type of an automatically generated text rumour. The Rumour Mill is a physical demonstration of the state of current technology and its ability to generate and manipulate natural language text, and of the act of starting and spreading rumours.
Offensive Language and Hate Speech Detection for Danish
Aug 13, 2019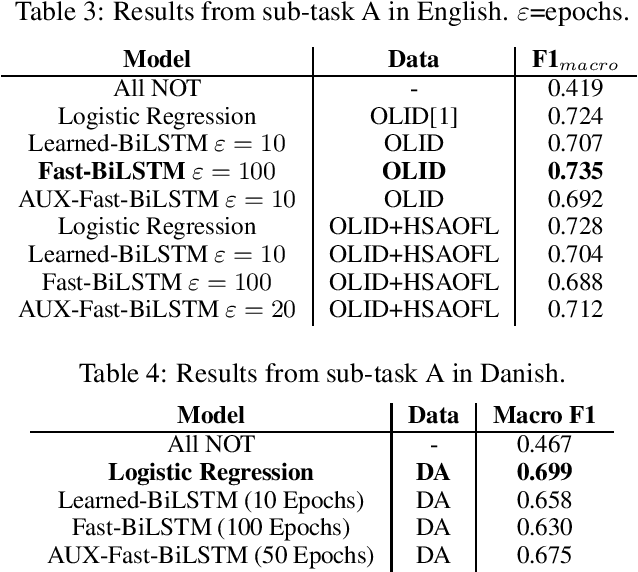
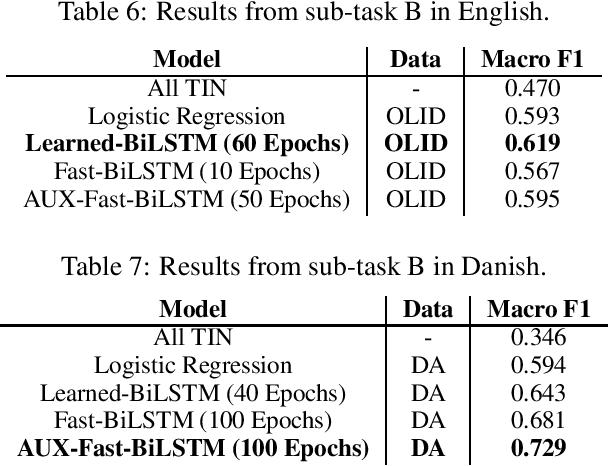
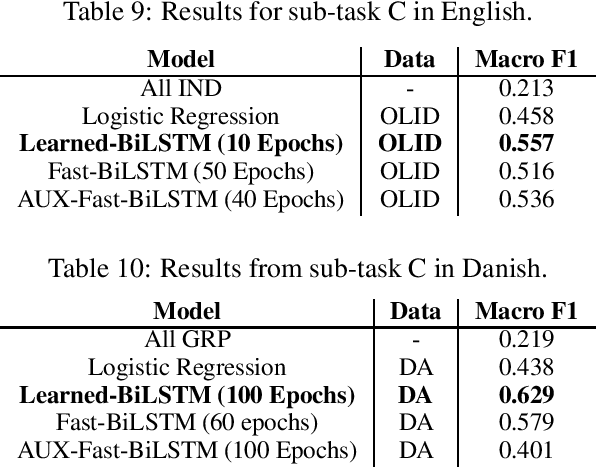
The presence of offensive language on social media platforms and the implications this poses is becoming a major concern in modern society. Given the enormous amount of content created every day, automatic methods are required to detect and deal with this type of content. Until now, most of the research has focused on solving the problem for the English language, while the problem is multilingual. We construct a Danish dataset containing user-generated comments from \textit{Reddit} and \textit{Facebook}. It contains user generated comments from various social media platforms, and to our knowledge, it is the first of its kind. Our dataset is annotated to capture various types and target of offensive language. We develop four automatic classification systems, each designed to work for both the English and the Danish language. In the detection of offensive language in English, the best performing system achieves a macro averaged F1-score of $0.74$, and the best performing system for Danish achieves a macro averaged F1-score of $0.70$. In the detection of whether or not an offensive post is targeted, the best performing system for English achieves a macro averaged F1-score of $0.62$, while the best performing system for Danish achieves a macro averaged F1-score of $0.73$. Finally, in the detection of the target type in a targeted offensive post, the best performing system for English achieves a macro averaged F1-score of $0.56$, and the best performing system for Danish achieves a macro averaged F1-score of $0.63$. Our work for both the English and the Danish language captures the type and targets of offensive language, and present automatic methods for detecting different kinds of offensive language such as hate speech and cyberbullying.
Simple Natural Language Processing Tools for Danish
Jul 26, 2019This technical note describes a set of baseline tools for automatic processing of Danish text. The tools are machine-learning based, using natural language processing models trained over previously annotated documents. They are maintained at ITU Copenhagen and will always be freely available.
Stance Prediction for Russian: Data and Analysis
Oct 03, 2018

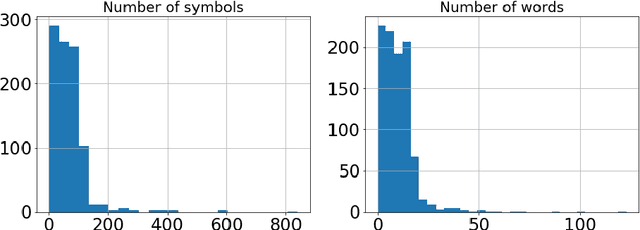
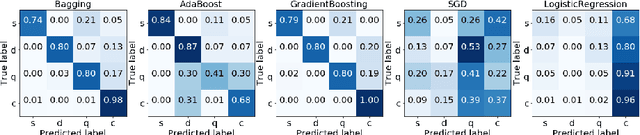
Stance detection is a critical component of rumour and fake news identification. It involves the extraction of the stance a particular author takes related to a given claim, both expressed in text. This paper investigates stance classification for Russian. It introduces a new dataset, RuStance, of Russian tweets and news comments from multiple sources, covering multiple stories, as well as text classification approaches to stance detection as benchmarks over this data in this language. As well as presenting this openly-available dataset, the first of its kind for Russian, the paper presents a baseline for stance prediction in the language.
RumourEval 2019: Determining Rumour Veracity and Support for Rumours
Sep 18, 2018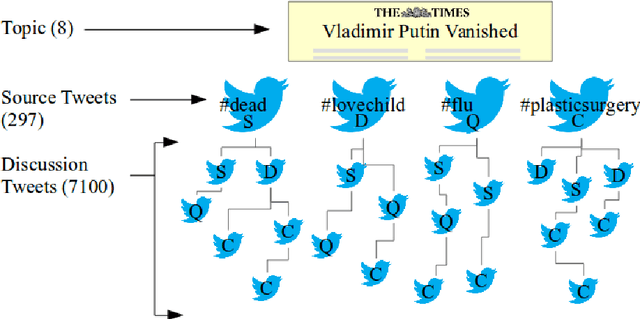
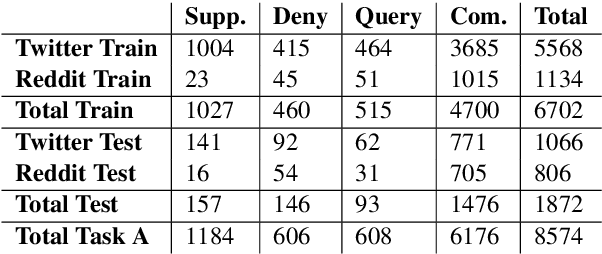
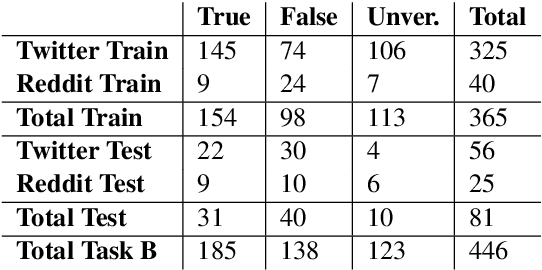
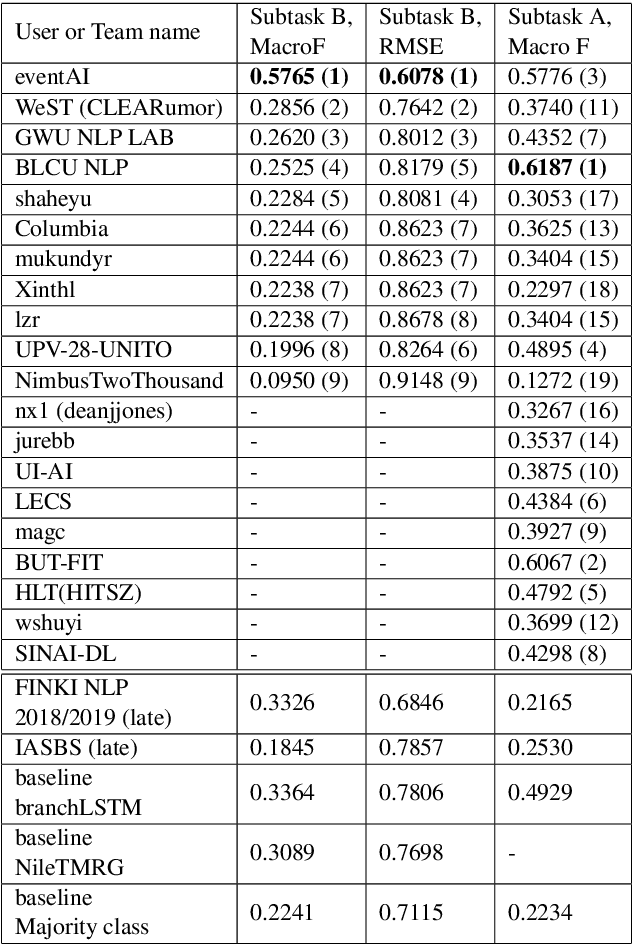
This is the proposal for RumourEval-2019, which will run in early 2019 as part of that year's SemEval event. Since the first RumourEval shared task in 2017, interest in automated claim validation has greatly increased, as the dangers of "fake news" have become a mainstream concern. Yet automated support for rumour checking remains in its infancy. For this reason, it is important that a shared task in this area continues to provide a focus for effort, which is likely to increase. We therefore propose a continuation in which the veracity of further rumours is determined, and as previously, supportive of this goal, tweets discussing them are classified according to the stance they take regarding the rumour. Scope is extended compared with the first RumourEval, in that the dataset is substantially expanded to include Reddit as well as Twitter data, and additional languages are also included.