 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Bound Consistency for the No-Overlap Constraint Using MDDs
Jan 21, 2026Achieving bound consistency for the no-overlap constraint is known to be NP-complete. Therefore, several polynomial-time tightening techniques, such as edge finding, not-first-not-last reasoning, and energetic reasoning, have been introduced for this constraint. In this work, we derive the first bound-consistent algorithm for the no-overlap constraint. By building on the no-overlap MDD defined by Ciré and van Hoeve, we extract bounds of the time window of the jobs, allowing us to tighten start and end times in time polynomial in the number of nodes of the MDD. Similarly, to bound the size and time-complexity, we limit the width of the MDD to a threshold, creating a relaxed MDD that can also be used to relax the bound-consistent filtering. Through experiments on a sequencing problem with time windows and a just-in-time objective ($1 \mid r_j, d_j, \bar{d}_j \mid \sum E_j + \sum T_j$), we observe that the proposed filtering, even with a threshold on the width, achieves a stronger reduction in the number of nodes visited in the search tree compared to the previously proposed precedence-detection algorithm of Ciré and van Hoeve. The new filtering also appears to be complementary to classical propagation methods for the no-overlap constraint, allowing a substantial reduction in both the number of nodes and the solving time on several instances.
Busting the Paper Ballot: Voting Meets Adversarial Machine Learning
Jun 17, 2025



We show the security risk associated with using machine learning classifiers in United States election tabulators. The central classification task in election tabulation is deciding whether a mark does or does not appear on a bubble associated to an alternative in a contest on the ballot. Barretto et al. (E-Vote-ID 2021) reported that convolutional neural networks are a viable option in this field, as they outperform simple feature-based classifiers. Our contributions to election security can be divided into four parts. To demonstrate and analyze the hypothetical vulnerability of machine learning models on election tabulators, we first introduce four new ballot datasets. Second, we train and test a variety of different models on our new datasets. These models include support vector machines, convolutional neural networks (a basic CNN, VGG and ResNet), and vision transformers (Twins and CaiT). Third, using our new datasets and trained models, we demonstrate that traditional white box attacks are ineffective in the voting domain due to gradient masking. Our analyses further reveal that gradient masking is a product of numerical instability. We use a modified difference of logits ratio loss to overcome this issue (Croce and Hein, ICML 2020). Fourth, in the physical world, we conduct attacks with the adversarial examples generated using our new methods. In traditional adversarial machine learning, a high (50% or greater) attack success rate is ideal. However, for certain elections, even a 5% attack success rate can flip the outcome of a race. We show such an impact is possible in the physical domain. We thoroughly discuss attack realism, and the challenges and practicality associated with printing and scanning ballot adversarial examples.
Bringing freedom in variable choice when searching counter-examples in floating point programs
Feb 27, 2020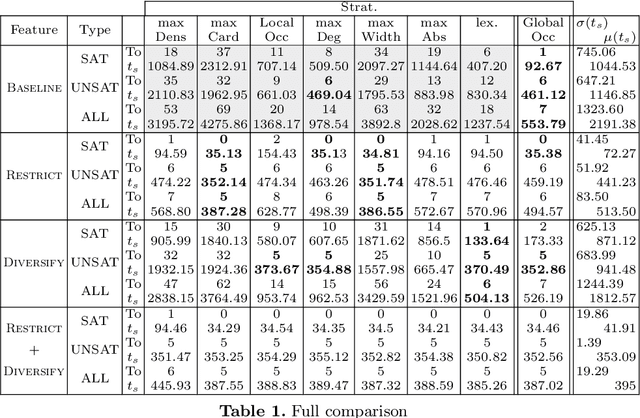

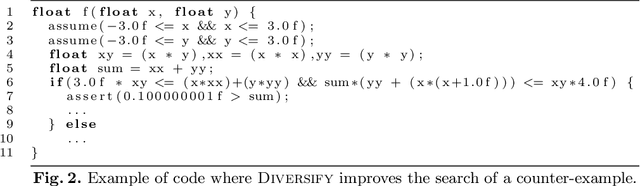

Program verification techniques typically focus on finding counter-examples that violate properties of a program. Constraint programming offers a convenient way to verify programs by modeling their state transformations and specifying searches that seek counter-examples. Floating-point computations present additional challenges for verification given the semantic subtleties of floating point arithmetic. % This paper focuses on search strategies for CSPs using floating point numbers constraint systems and dedicated to program verification. It introduces a new search heuristic based on the global number of occurrences that outperforms state-of-the-art strategies. More importantly, it demonstrates that a new technique that only branches on input variables of the verified program improve performance. It composes with a diversification technique that prevents the selection of the same variable within a fixed horizon further improving performances and reduces disparities between various variable choice heuristics. The result is a robust methodology that can tailor the search strategy according to the sought properties of the counter example.
An efficient constraint based framework forhandling floating point SMT problems
Feb 27, 2020


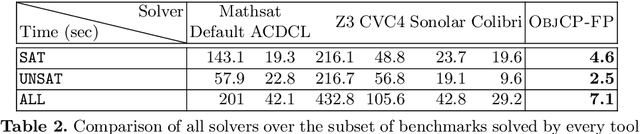
This paper introduces the 2019 version of \us{}, a novel Constraint Programming framework for floating point verification problems expressed with the SMT language of SMTLIB. SMT solvers decompose their task by delegating to specific theories (e.g., floating point, bit vectors, arrays, ...) the task to reason about combinatorial or otherwise complex constraints for which the SAT encoding would be cumbersome or ineffective. This decomposition and encoding processes lead to the obfuscation of the high-level constraints and a loss of information on the structure of the combinatorial model. In \us{}, constraints over the floats are first class objects, and the purpose is to expose and exploit structures of floating point domains to enhance the search process. A symbolic phase rewrites each SMTLIB instance to elementary constraints, and eliminates auxiliary variables whose presence is counterproductive. A diversification technique within the search steers it away from costly enumerations in unproductive areas of the search space. The empirical evaluation demonstrates that the 2019 version of \us{} is competitive on computationally challenging floating point benchmarks that induce significant search efforts even for other CP solvers. It highlights that the ability to harness both inference and search is critical. Indeed, it yields a factor 3 improvement over Colibri and is up to 10 times faster than SMT solvers. The evaluation was conducted over 214 benchmarks (The Griggio suite) which is a standard within SMTLIB.
Domain Views for Constraint Programming
Jan 21, 2014
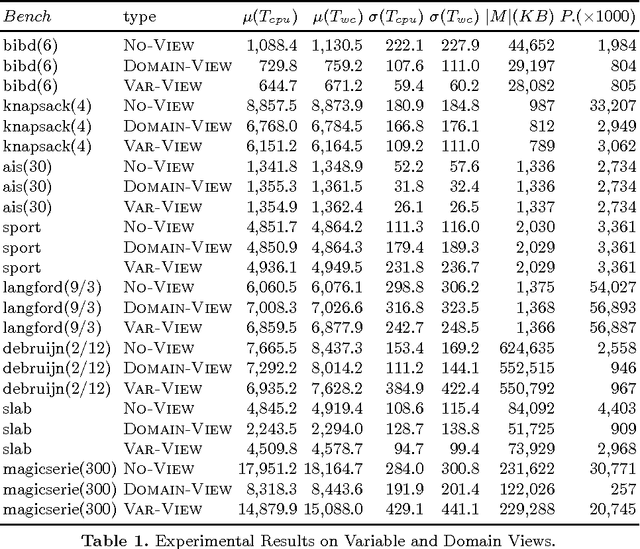


Views are a standard abstraction in constraint programming: They make it possible to implement a single version of each constraint, while avoiding to create new variables and constraints that would slow down propagation. Traditional constraint-programming systems provide the concept of {\em variable views} which implement a view of the type $y = f(x)$ by delegating all (domain and constraint) operations on variable $y$ to variable $x$. This paper proposes the alternative concept of {\em domain views} which only delegate domain operations. Domain views preserve the benefits of variable views but simplify the implementation of value-based propagation. Domain views also support non-injective views compositionally, expanding the scope of views significantly. Experimental results demonstrate the practical benefits of domain views.
A Microkernel Architecture for Constraint Programming
Jan 21, 2014



This paper presents a microkernel architecture for constraint programming organized around a number of small number of core functionalities and minimal interfaces. The architecture contrasts with the monolithic nature of many implementations. Experimental results indicate that the software engineering benefits are not incompatible with runtime efficiency.