 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Content, Different Answers: Cross-Modal Inconsistency in MLLMs
Dec 09, 2025We introduce two new benchmarks REST and REST+(Render-Equivalence Stress Tests) to enable systematic evaluation of cross-modal inconsistency in multimodal large language models (MLLMs). MLLMs are trained to represent vision and language in the same embedding space, yet they cannot perform the same tasks in both modalities. Our benchmarks contain samples with the same semantic information in three modalities (image, text, mixed) and we show that state-of-the-art MLLMs cannot consistently reason over these different modalities. We evaluate 15 MLLMs and find that the degree of modality inconsistency varies substantially, even when accounting for problems with text recognition (OCR). Neither rendering text as image nor rendering an image as text solves the inconsistency. Even if OCR is correct, we find that visual characteristics (text colour and resolution, but not font) and the number of vision tokens have an impact on model performance. Finally, we find that our consistency score correlates with the modality gap between text and images, highlighting a mechanistic interpretation of cross-modal inconsistent MLLMs.
Privacy-Aware Visual Language Models
May 27, 2024This paper aims to advance our understanding of how Visual Language Models (VLMs) handle privacy-sensitive information, a crucial concern as these technologies become integral to everyday life. To this end, we introduce a new benchmark PrivBench, which contains images from 8 sensitive categories such as passports, or fingerprints. We evaluate 10 state-of-the-art VLMs on this benchmark and observe a generally limited understanding of privacy, highlighting a significant area for model improvement. Based on this we introduce PrivTune, a new instruction-tuning dataset aimed at equipping VLMs with knowledge about visual privacy. By tuning two pretrained VLMs, TinyLLaVa and MiniGPT-v2, on this small dataset, we achieve strong gains in their ability to recognize sensitive content, outperforming even GPT4-V. At the same time, we show that privacy-tuning only minimally affects the VLMs performance on standard benchmarks such as VQA. Overall, this paper lays out a crucial challenge for making VLMs effective in handling real-world data safely and provides a simple recipe that takes the first step towards building privacy-aware VLMs.
Back to Basics: Deep Reinforcement Learning in Traffic Signal Control
Sep 15, 2021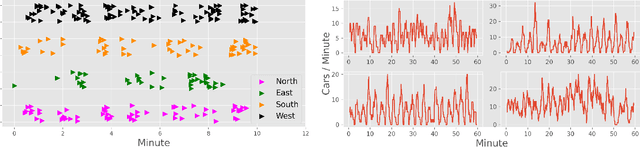
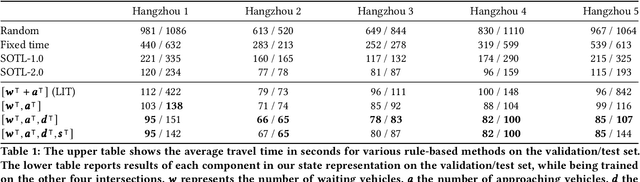
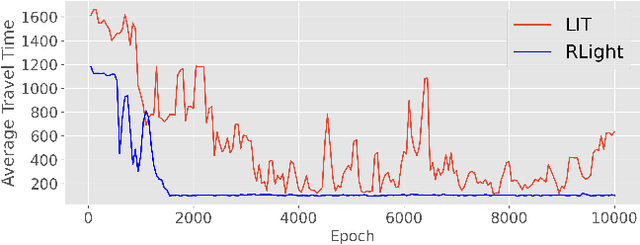
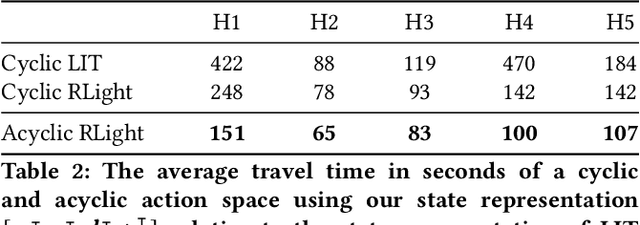
In this paper we revisit some of the fundamental premises for a reinforcement learning (RL) approach to self-learning traffic lights. We propose RLight, a combination of choices that offers robust performance and good generalization to unseen traffic flows. In particular, our main contributions are threefold: our lightweight and cluster-aware state representation leads to improved performance; we reformulate the MDP such that it skips redundant timesteps of yellow light, speeding up learning by 30%; and we investigate the action space and provide insight into the difference in performance between acyclic and cyclic phase transitions. Additionally, we provide insights into the generalisation of the methods to unseen traffic. Evaluations using the real-world Hangzhou traffic dataset show that RLight outperforms state-of-the-art rule-based and deep reinforcement learning algorithms, demonstrating the potential of RL-based methods to improve urban traffic flows.
I Bet You Are Wrong: Gambling Adversarial Networks for Structured Semantic Segmentation
Aug 07, 2019

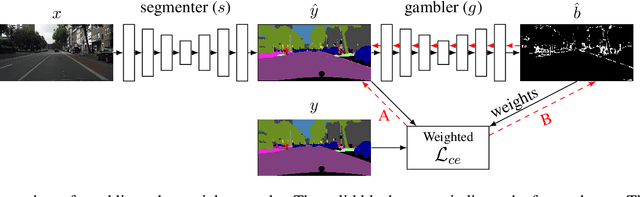
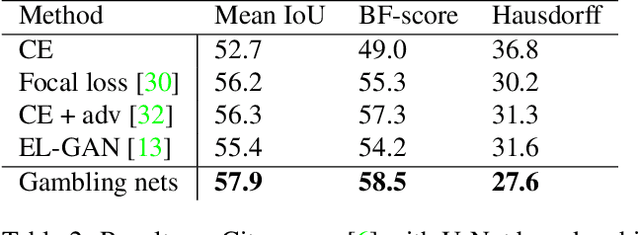
Adversarial training has been recently employed for realizing structured semantic segmentation, in which the aim is to preserve higher-level scene structural consistencies in dense predictions. However, as we show, value-based discrimination between the predictions from the segmentation network and ground-truth annotations can hinder the training process from learning to improve structural qualities as well as disabling the network from properly expressing uncertainties. In this paper, we rethink adversarial training for semantic segmentation and propose to formulate the fake/real discrimination framework with a correct/incorrect training objective. More specifically, we replace the discriminator with a "gambler" network that learns to spot and distribute its budget in areas where the predictions are clearly wrong, while the segmenter network tries to leave no clear clues for the gambler where to bet. Empirical evaluation on two road-scene semantic segmentation tasks shows that not only does the proposed method re-enable expressing uncertainties, it also improves pixel-wise and structure-based metrics.