 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuTa-VC: A Duration-aware Typical-to-atypical Voice Conversion Approach with Diffusion Probabilistic Model
Jun 18, 2023



We present a novel typical-to-atypical voice conversion approach (DuTa-VC), which (i) can be trained with nonparallel data (ii) first introduces diffusion probabilistic model (iii) preserves the target speaker identity (iv) is aware of the phoneme duration of the target speaker. DuTa-VC consists of three parts: an encoder transforms the source mel-spectrogram into a duration-modified speaker-independent mel-spectrogram, a decoder performs the reverse diffusion to generate the target mel-spectrogram, and a vocoder is applied to reconstruct the waveform. Objective evaluations conducted on the UASpeech show that DuTa-VC is able to capture severity characteristics of dysarthric speech, reserves speaker identity, and significantly improves dysarthric speech recognition as a data augmentation. Subjective evaluations by two expert speech pathologists validate that DuTa-VC can preserve the severity and type of dysarthria of the target speakers in the synthesized speech.
Regularizing Contrastive Predictive Coding for Speech Applications
Apr 26, 2023



Self-supervised methods such as Contrastive predictive Coding (CPC) have greatly improved the quality of the unsupervised representations. These representations significantly reduce the amount of labeled data needed for downstream task performance, such as automatic speech recognition. CPC learns representations by learning to predict future frames given current frames. Based on the observation that the acoustic information, e.g., phones, changes slower than the feature extraction rate in CPC, we propose regularization techniques that impose slowness constraints on the features. Here we propose two regularization techniques: Self-expressing constraint and Left-or-Right regularization. We evaluate the proposed model on ABX and linear phone classification tasks, acoustic unit discovery, and automatic speech recognition. The regularized CPC trained on 100 hours of unlabeled data matches the performance of the baseline CPC trained on 360 hours of unlabeled data. We also show that our regularization techniques are complementary to data augmentation and can further boost the system's performance. In monolingual, cross-lingual, or multilingual settings, with/without data augmentation, regardless of the amount of data used for training, our regularized models outperformed the baseline CPC models on the ABX task.
Stabilized training of joint energy-based models and their practical applications
Mar 07, 2023



The recently proposed Joint Energy-based Model (JEM) interprets discriminatively trained classifier $p(y|x)$ as an energy model, which is also trained as a generative model describing the distribution of the input observations $p(x)$. The JEM training relies on "positive examples" (i.e. examples from the training data set) as well as on "negative examples", which are samples from the modeled distribution $p(x)$ generated by means of Stochastic Gradient Langevin Dynamics (SGLD). Unfortunately, SGLD often fails to deliver negative samples of sufficient quality during the standard JEM training, which causes a very unbalanced contribution from the positive and negative examples when calculating gradients for JEM updates. As a consequence, the standard JEM training is quite unstable requiring careful tuning of hyper-parameters and frequent restarts when the training starts diverging. This makes it difficult to apply JEM to different neural network architectures, modalities, and tasks. In this work, we propose a training procedure that stabilizes SGLD-based JEM training (ST-JEM) by balancing the contribution from the positive and negative examples. We also propose to add an additional "regularization" term to the training objective -- MI between the input observations $x$ and output labels $y$ -- which encourages the JEM classifier to make more certain decisions about output labels. We demonstrate the effectiveness of our approach on the CIFAR10 and CIFAR100 tasks. We also consider the task of classifying phonemes in a speech signal, for which we were not able to train JEM without the proposed stabilization. We show that a convincing speech can be generated from the trained model. Alternatively, corrupted speech can be de-noised by bringing it closer to the modeled speech distribution using a few SGLD iterations. We also propose and discuss additional applications of the trained model.
Non-Contrastive Self-supervised Learning for Utterance-Level Information Extraction from Speech
Aug 10, 2022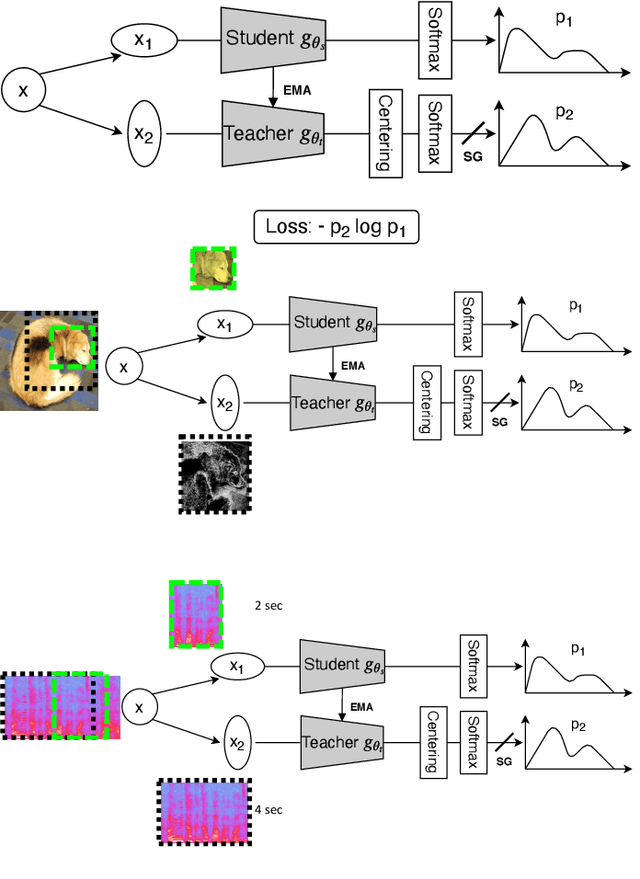
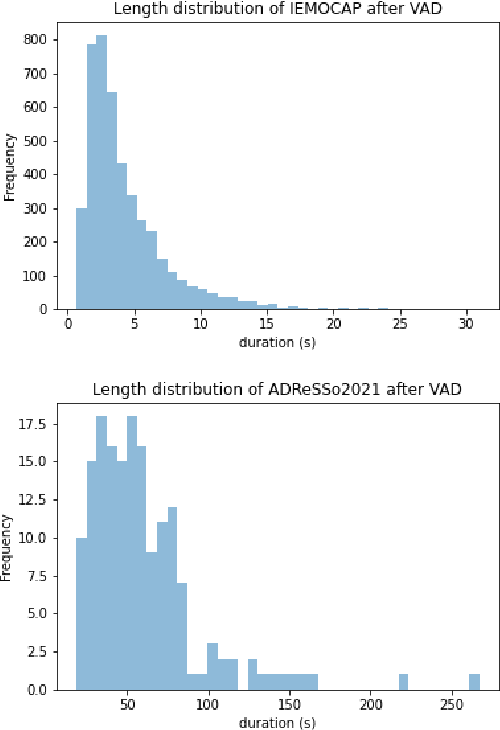
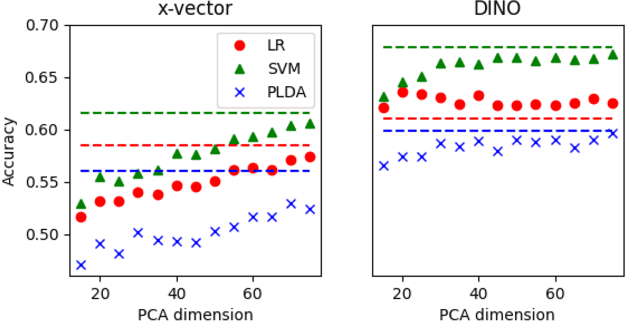
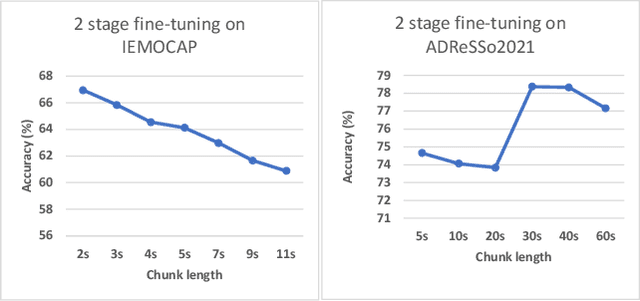
In recent studies, self-supervised pre-trained models tend to outperform supervised pre-trained models in transfer learning. In particular, self-supervised learning (SSL) of utterance-level speech representation can be used in speech applications that require discriminative representation of consistent attributes within an utterance: speaker, language, emotion, and age. Existing frame-level self-supervised speech representation, e.g., wav2vec, can be used as utterance-level representation with pooling, but the models are usually large. There are also SSL techniques to learn utterance-level representation. One of the most successful is a contrastive method, which requires negative sampling: selecting alternative samples to contrast with the current sample (anchor). However, this does not ensure that all the negative samples belong to classes different from the anchor class without labels. This paper applies a non-contrastive self-supervised method to learn utterance-level embeddings. We adapted DIstillation with NO labels (DINO) from computer vision to speech. Unlike contrastive methods, DINO does not require negative sampling. We compared DINO to x-vector trained in a supervised manner. When transferred to down-stream tasks (speaker verification, speech emotion recognition (SER), and Alzheimer's disease detection), DINO outperformed x-vector. We studied the influence of several aspects during transfer learning such as dividing the fine-tuning process into steps, chunk lengths, or augmentation. During fine-tuning, tuning the last affine layers first and then the whole network surpassed fine-tuning all at once. Using shorter chunk lengths, although they generate more diverse inputs, did not necessarily improve performance, implying speech segments at least with a specific length are required for better performance per application. Augmentation was helpful in SER.
Non-Contrastive Self-Supervised Learning of Utterance-Level Speech Representations
Aug 10, 2022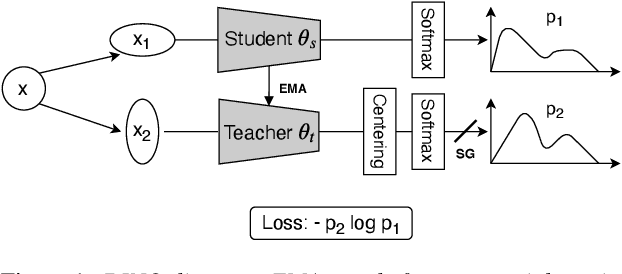
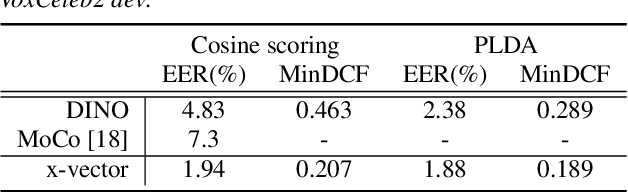
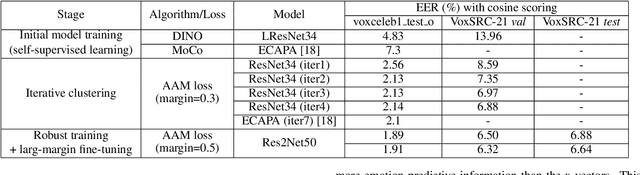
Considering the abundance of unlabeled speech data and the high labeling costs, unsupervised learning methods can be essential for better system development. One of the most successful methods is contrastive self-supervised methods, which require negative sampling: sampling alternative samples to contrast with the current sample (anchor). However, it is hard to ensure if all the negative samples belong to classes different from the anchor class without labels. This paper applies a non-contrastive self-supervised learning method on an unlabeled speech corpus to learn utterance-level embeddings. We used DIstillation with NO labels (DINO), proposed in computer vision, and adapted it to the speech domain. Unlike the contrastive methods, DINO does not require negative sampling. These embeddings were evaluated on speaker verification and emotion recognition. In speaker verification, the unsupervised DINO embedding with cosine scoring provided 4.38% EER on the VoxCeleb1 test trial. This outperforms the best contrastive self-supervised method by 40% relative in EER. An iterative pseudo-labeling training pipeline, not requiring speaker labels, further improved the EER to 1.89%. In emotion recognition, the DINO embedding performed 60.87, 79.21, and 56.98% in micro-f1 score on IEMOCAP, Crema-D, and MSP-Podcast, respectively. The results imply the generality of the DINO embedding to different speech applications.
Unsupervised Speech Segmentation and Variable Rate Representation Learning using Segmental Contrastive Predictive Coding
Oct 08, 2021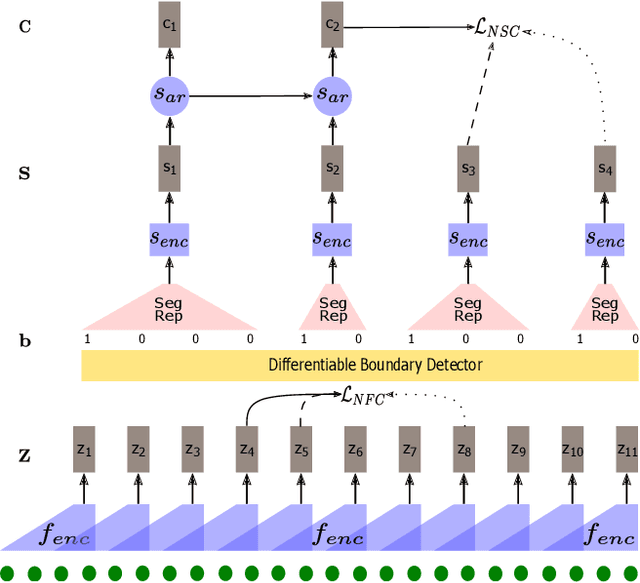
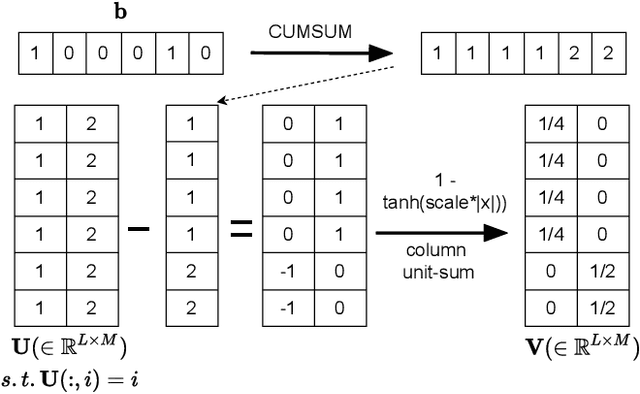
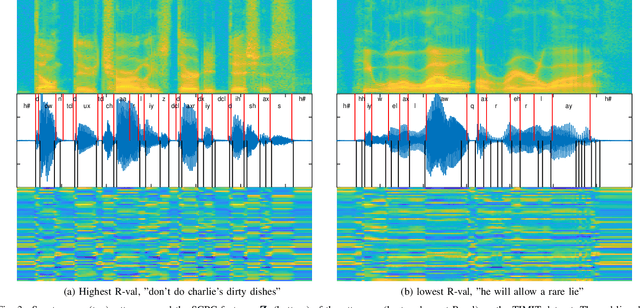
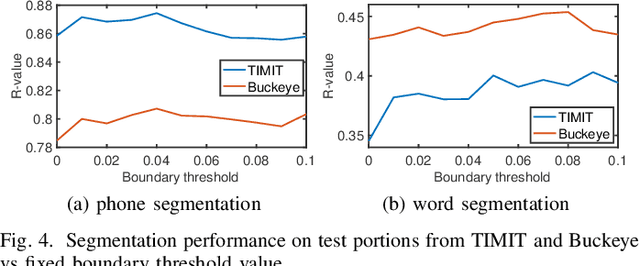
Typically, unsupervised segmentation of speech into the phone and word-like units are treated as separate tasks and are often done via different methods which do not fully leverage the inter-dependence of the two tasks. Here, we unify them and propose a technique that can jointly perform both, showing that these two tasks indeed benefit from each other. Recent attempts employ self-supervised learning, such as contrastive predictive coding (CPC), where the next frame is predicted given past context. However, CPC only looks at the audio signal's frame-level structure. We overcome this limitation with a segmental contrastive predictive coding (SCPC) framework to model the signal structure at a higher level, e.g., phone level. A convolutional neural network learns frame-level representation from the raw waveform via noise-contrastive estimation (NCE). A differentiable boundary detector finds variable-length segments, which are then used to optimize a segment encoder via NCE to learn segment representations. The differentiable boundary detector allows us to train frame-level and segment-level encoders jointly. Experiments show that our single model outperforms existing phone and word segmentation methods on TIMIT and Buckeye datasets. We discover that phone class impacts the boundary detection performance, and the boundaries between successive vowels or semivowels are the most difficult to identify. Finally, we use SCPC to extract speech features at the segment level rather than at uniformly spaced frame level (e.g., 10 ms) and produce variable rate representations that change according to the contents of the utterance. We can lower the feature extraction rate from the typical 100 Hz to as low as 14.5 Hz on average while still outperforming the MFCC features on the linear phone classification task.
Beyond Isolated Utterances: Conversational Emotion Recognition
Sep 13, 2021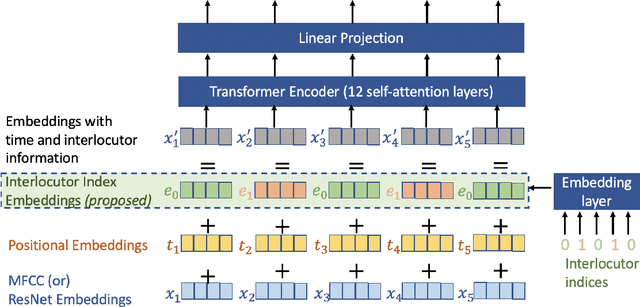

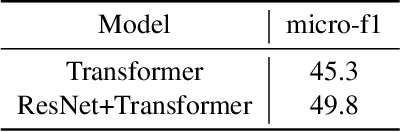
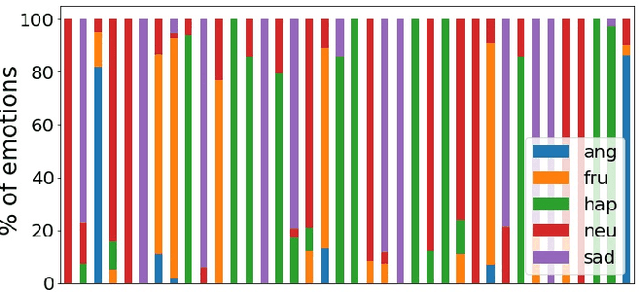
Speech emotion recognition is the task of recognizing the speaker's emotional state given a recording of their utterance. While most of the current approaches focus on inferring emotion from isolated utterances, we argue that this is not sufficient to achieve conversational emotion recognition (CER) which deals with recognizing emotions in conversations. In this work, we propose several approaches for CER by treating it as a sequence labeling task. We investigated transformer architecture for CER and, compared it with ResNet-34 and BiLSTM architectures in both contextual and context-less scenarios using IEMOCAP corpus. Based on the inner workings of the self-attention mechanism, we proposed DiverseCatAugment (DCA), an augmentation scheme, which improved the transformer model performance by an absolute 3.3% micro-f1 on conversations and 3.6% on isolated utterances. We further enhanced the performance by introducing an interlocutor-aware transformer model where we learn a dictionary of interlocutor index embeddings to exploit diarized conversations.
Pathological voice adaptation with autoencoder-based voice conversion
Jun 15, 2021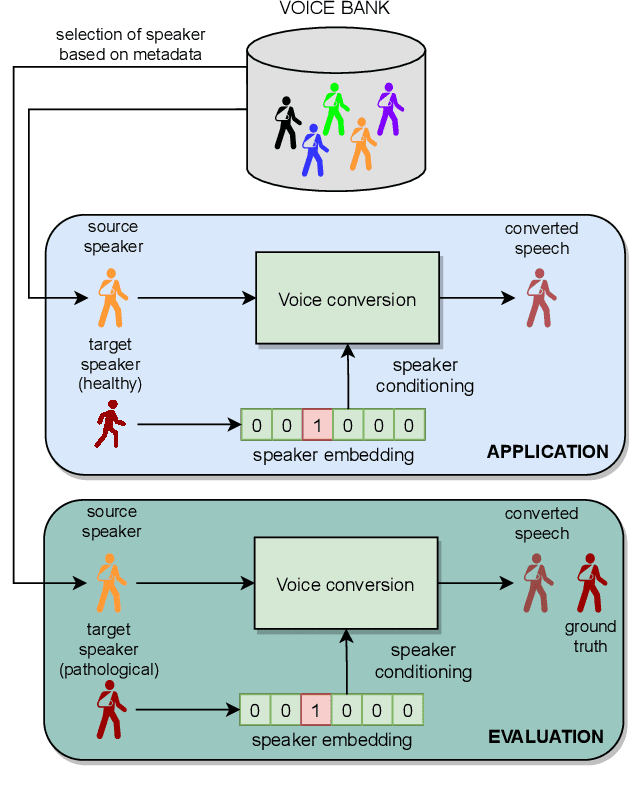

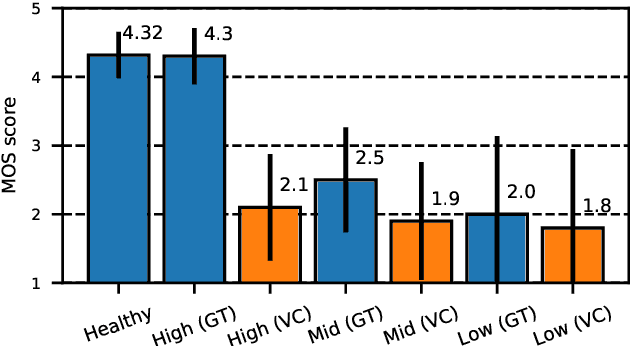
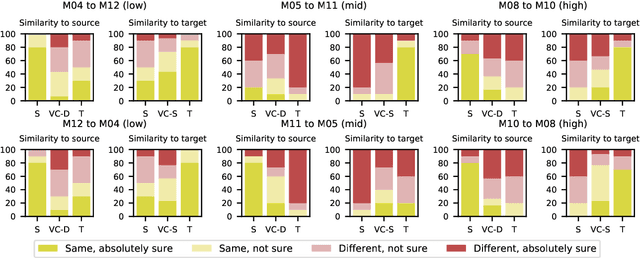
In this paper, we propose a new approach to pathological speech synthesis. Instead of using healthy speech as a source, we customise an existing pathological speech sample to a new speaker's voice characteristics. This approach alleviates the evaluation problem one normally has when converting typical speech to pathological speech, as in our approach, the voice conversion (VC) model does not need to be optimised for speech degradation but only for the speaker change. This change in the optimisation ensures that any degradation found in naturalness is due to the conversion process and not due to the model exaggerating characteristics of a speech pathology. To show a proof of concept of this method, we convert dysarthric speech using the UASpeech database and an autoencoder-based VC technique. Subjective evaluation results show reasonable naturalness for high intelligibility dysarthric speakers, though lower intelligibility seems to introduce a marginal degradation in naturalness scores for mid and low intelligibility speakers compared to ground truth. Conversion of speaker characteristics for low and high intelligibility speakers is successful, but not for mid. Whether the differences in the results for the different intelligibility levels is due to the intelligibility levels or due to the speakers needs to be further investigated.
Segmental Contrastive Predictive Coding for Unsupervised Word Segmentation
Jun 03, 2021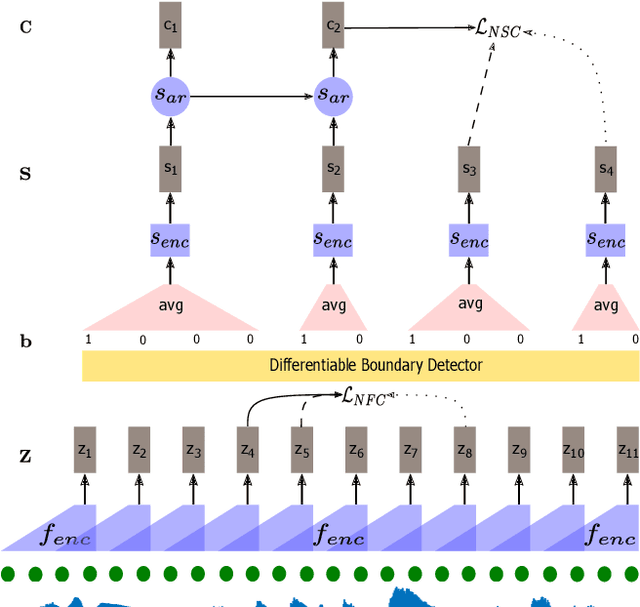
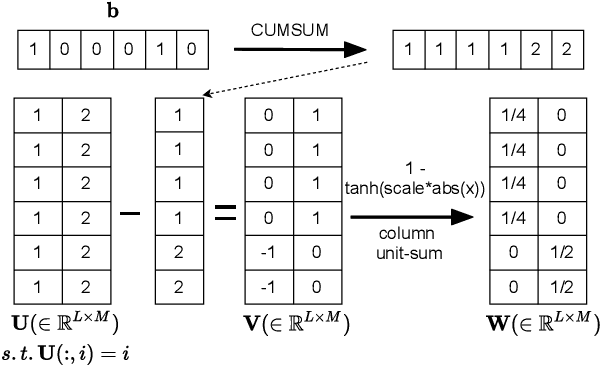
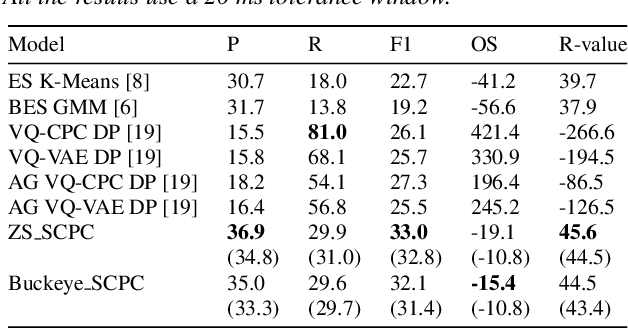
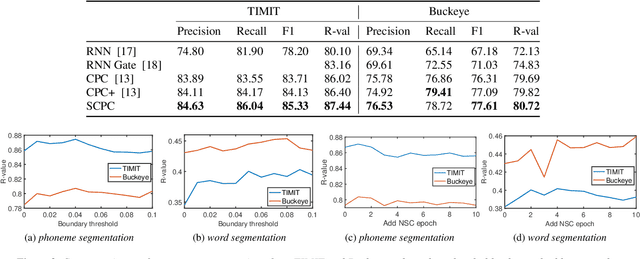
Automatic detection of phoneme or word-like units is one of the core objectives in zero-resource speech processing. Recent attempts employ self-supervised training methods, such as contrastive predictive coding (CPC), where the next frame is predicted given past context. However, CPC only looks at the audio signal's frame-level structure. We overcome this limitation with a segmental contrastive predictive coding (SCPC) framework that can model the signal structure at a higher level e.g. at the phoneme level. In this framework, a convolutional neural network learns frame-level representation from the raw waveform via noise-contrastive estimation (NCE). A differentiable boundary detector finds variable-length segments, which are then used to optimize a segment encoder via NCE to learn segment representations. The differentiable boundary detector allows us to train frame-level and segment-level encoders jointly. Typically, phoneme and word segmentation are treated as separate tasks. We unify them and experimentally show that our single model outperforms existing phoneme and word segmentation methods on TIMIT and Buckeye datasets. We analyze the impact of boundary threshold and when is the right time to include the segmental loss in the learning process.
Artificial Intelligence applied to chest X-Ray images for the automatic detection of COVID-19. A thoughtful evaluation approach
Nov 29, 2020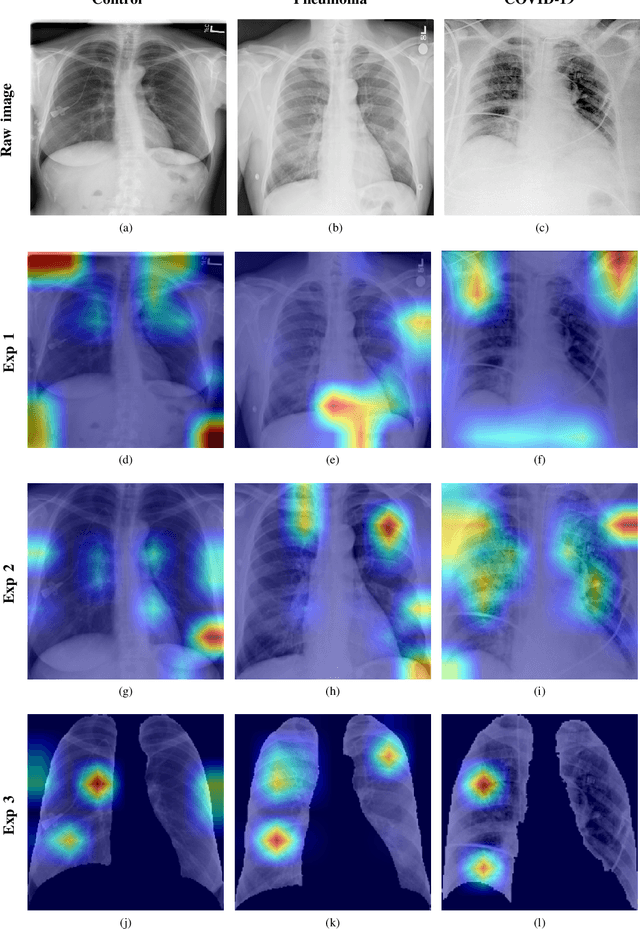
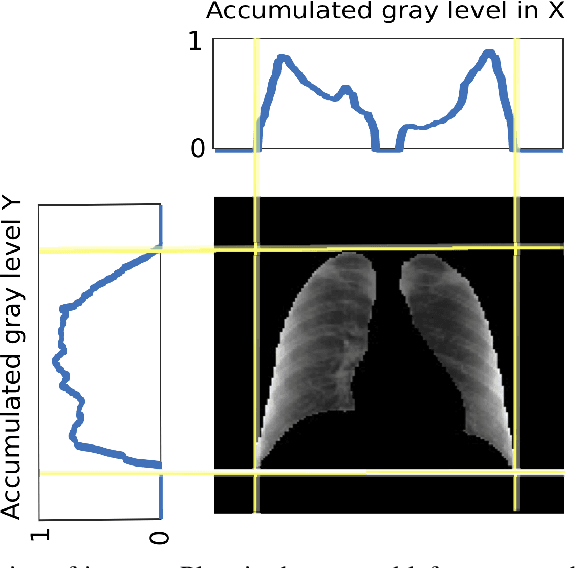
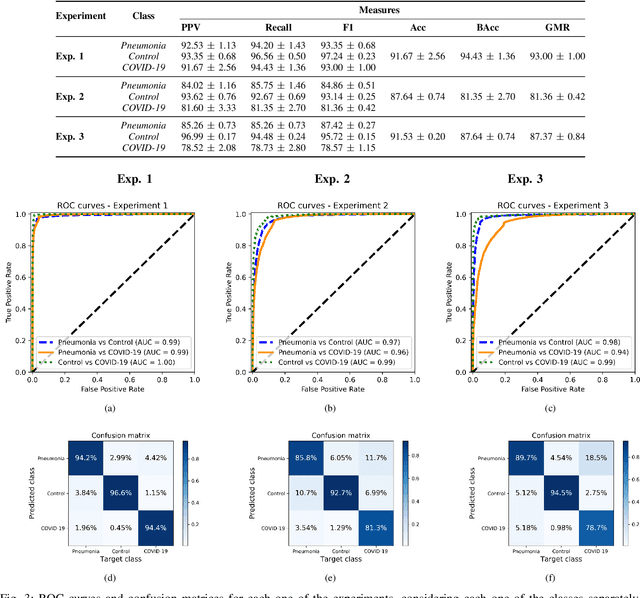
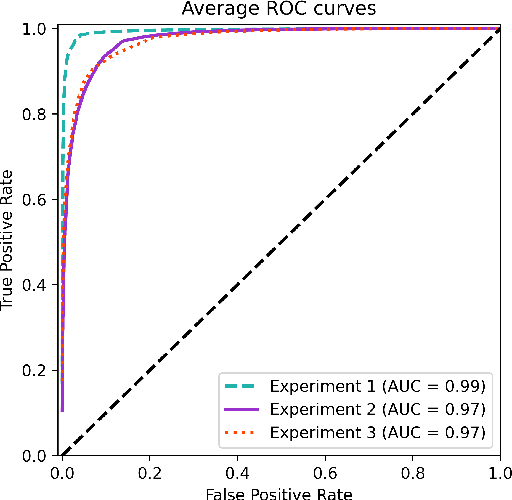
Current standard protocols used in the clinic for diagnosing COVID-19 include molecular or antigen tests, generally complemented by a plain chest X-Ray. The combined analysis aims to reduce the significant number of false negatives of these tests, but also to provide complementary evidence about the presence and severity of the disease. However, the procedure is not free of errors, and the interpretation of the chest X-Ray is only restricted to radiologists due to its complexity. With the long term goal to provide new evidence for the diagnosis, this paper presents an evaluation of different methods based on a deep neural network. These are the first steps to develop an automatic COVID-19 diagnosis tool using chest X-Ray images, that would additionally differentiate between controls, pneumonia or COVID-19 groups. The paper describes the process followed to train a Convolutional Neural Network with a dataset of more than 79,500 X-Ray images compiled from different sources, including more than 8,500 COVID-19 examples. For the sake of evaluation and comparison of the models developed, three different experiments were carried out following three preprocessing schemes. The aim is to evaluate how preprocessing the data affects the results and improves its explainability. Likewise, a critical analysis is carried out about different variability issues that might compromise the system and the effects on the performance. With the employed methodology, a 91.5% classification accuracy is obtained, with a 87.4% average recall for the worst but most explainable experiment, which requires a previous automatic segmentation of the lungs region.