 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Still Need Automatic Speech Recognition for Spoken Language Understanding?
Nov 29, 2021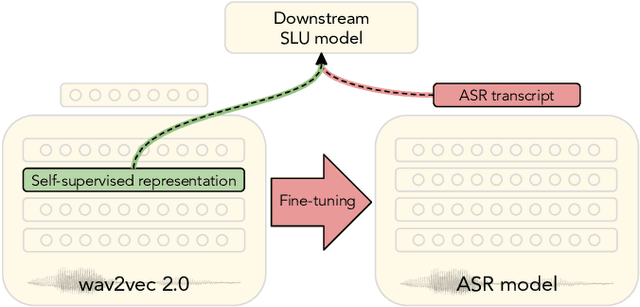

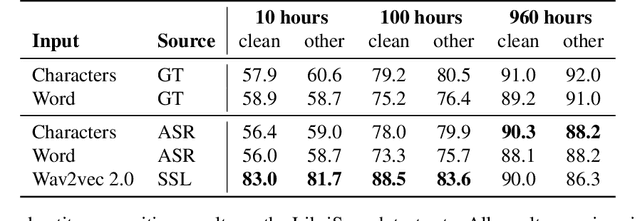

Spoken language understanding (SLU) tasks are usually solved by first transcribing an utterance with automatic speech recognition (ASR) and then feeding the output to a text-based model. Recent advances in self-supervised representation learning for speech data have focused on improving the ASR component. We investigate whether representation learning for speech has matured enough to replace ASR in SLU. We compare learned speech features from wav2vec 2.0, state-of-the-art ASR transcripts, and the ground truth text as input for a novel speech-based named entity recognition task, a cardiac arrest detection task on real-world emergency calls and two existing SLU benchmarks. We show that learned speech features are superior to ASR transcripts on three classification tasks. For machine translation, ASR transcripts are still the better choice. We highlight the intrinsic robustness of wav2vec 2.0 representations to out-of-vocabulary words as key to better performance.
Hierarchical VAEs Know What They Don't Know
Mar 01, 2021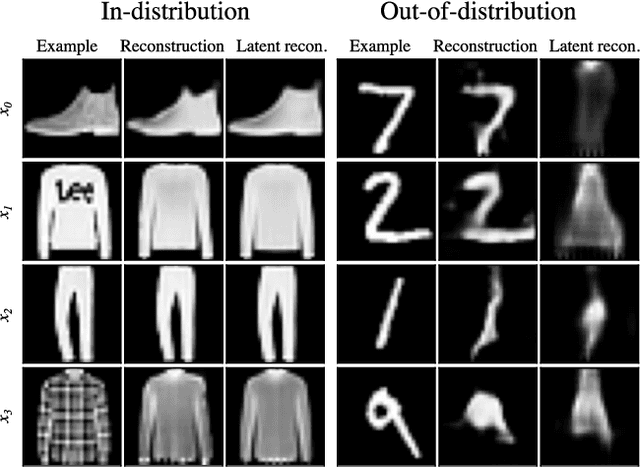
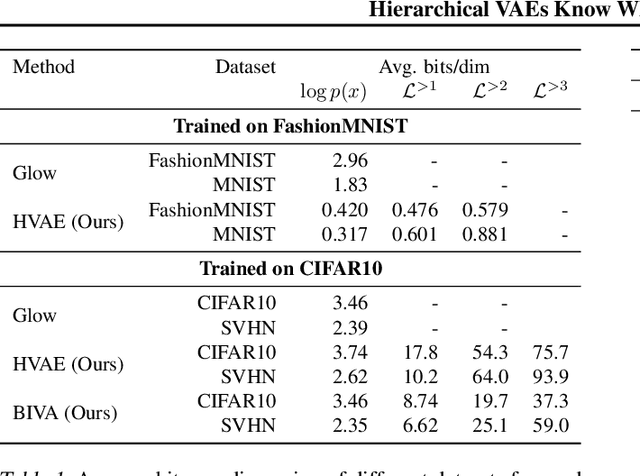
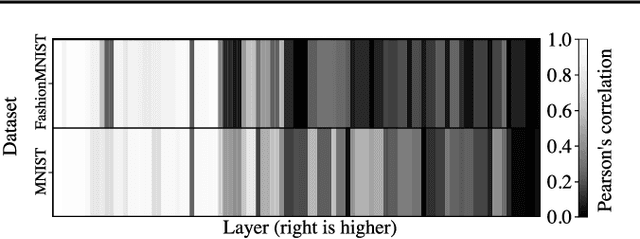
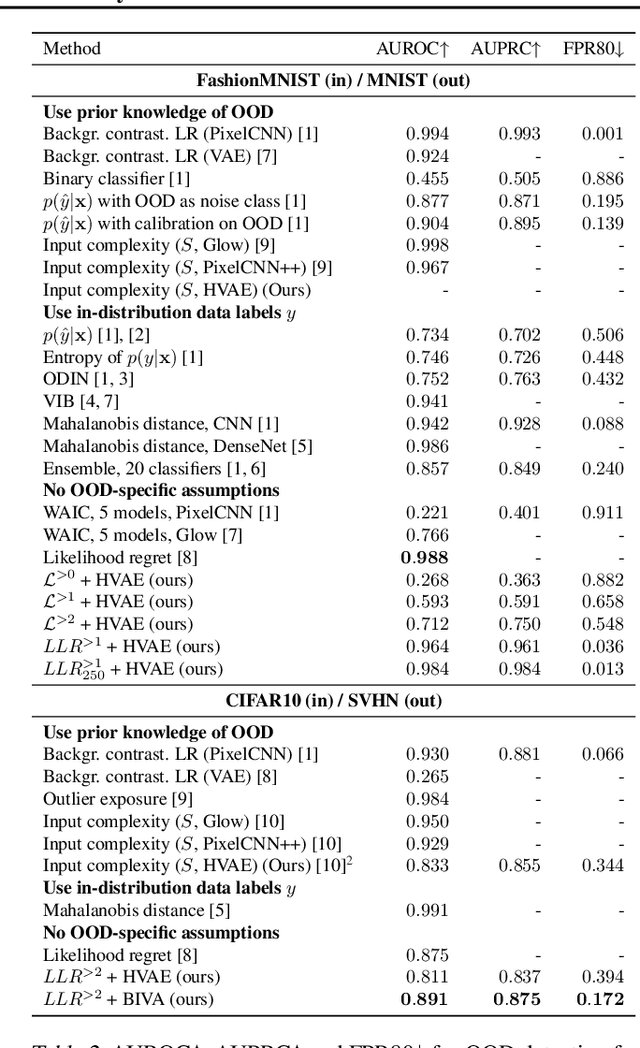
Deep generative models have shown themselves to be state-of-the-art density estimators. Yet, recent work has found that they often assign a higher likelihood to data from outside the training distribution. This seemingly paradoxical behavior has caused concerns over the quality of the attained density estimates. In the context of hierarchical variational autoencoders, we provide evidence to explain this behavior by out-of-distribution data having in-distribution low-level features. We argue that this is both expected and desirable behavior. With this insight in hand, we develop a fast, scalable and fully unsupervised likelihood-ratio score for OOD detection that requires data to be in-distribution across all feature-levels. We benchmark the method on a vast set of data and model combinations and achieve state-of-the-art results on out-of-distribution detection.
Do End-to-End Speech Recognition Models Care About Context?
Feb 17, 2021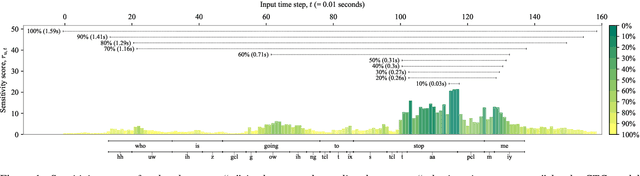
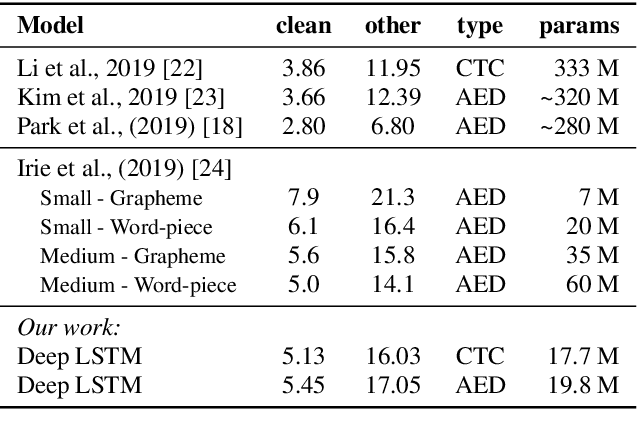
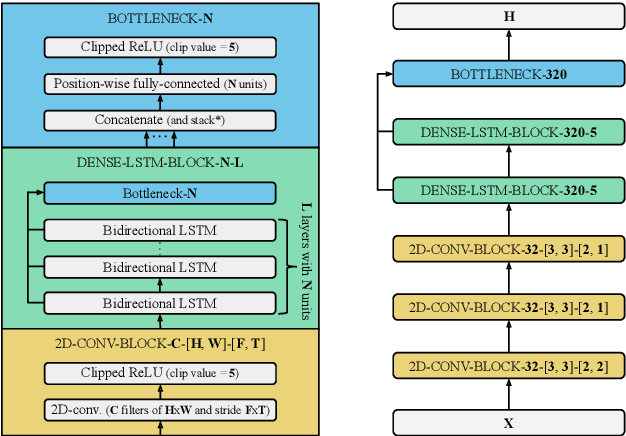
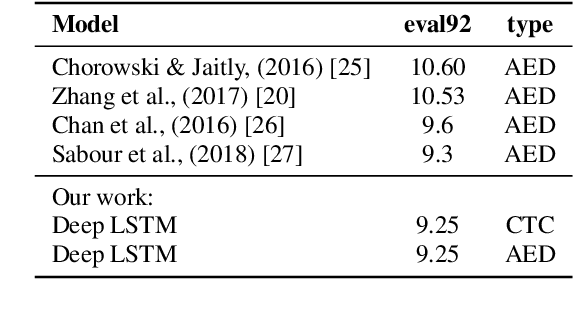
The two most common paradigms for end-to-end speech recognition are connectionist temporal classification (CTC) and attention-based encoder-decoder (AED) models. It has been argued that the latter is better suited for learning an implicit language model. We test this hypothesis by measuring temporal context sensitivity and evaluate how the models perform when we constrain the amount of contextual information in the audio input. We find that the AED model is indeed more context sensitive, but that the gap can be closed by adding self-attention to the CTC model. Furthermore, the two models perform similarly when contextual information is constrained. Finally, in contrast to previous research, our results show that the CTC model is highly competitive on WSJ and LibriSpeech without the help of an external language model.
On Scaling Contrastive Representations for Low-Resource Speech Recognition
Feb 01, 2021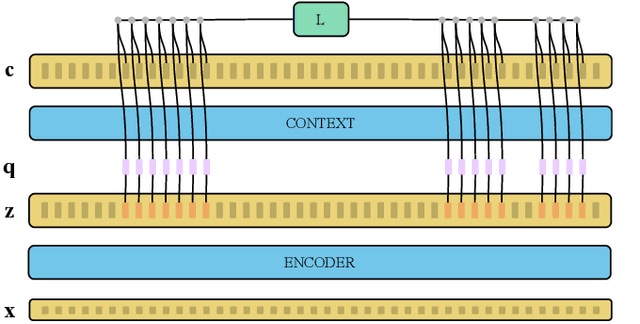
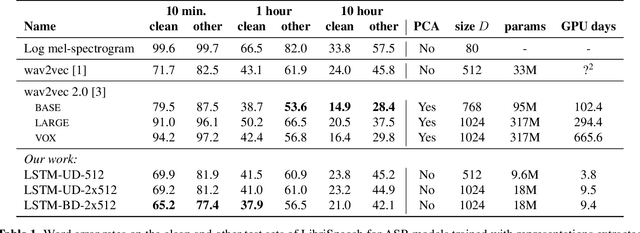
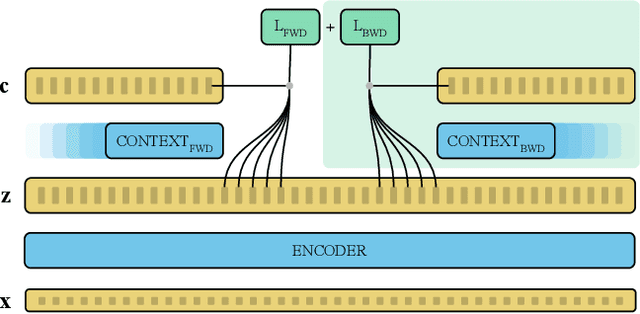
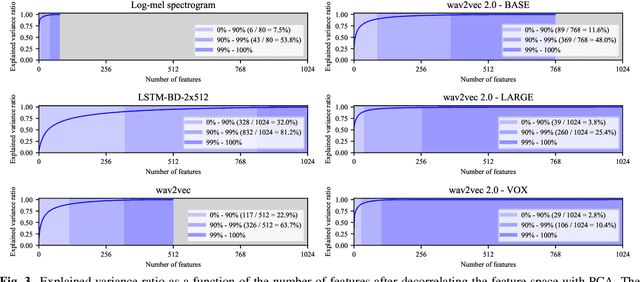
Recent advances in self-supervised learning through contrastive training have shown that it is possible to learn a competitive speech recognition system with as little as 10 minutes of labeled data. However, these systems are computationally expensive since they require pre-training followed by fine-tuning in a large parameter space. We explore the performance of such systems without fine-tuning by training a state-of-the-art speech recognizer on the fixed representations from the computationally demanding wav2vec 2.0 framework. We find performance to decrease without fine-tuning and, in the extreme low-resource setting, wav2vec 2.0 is inferior to its predecessor. In addition, we find that wav2vec 2.0 representations live in a low dimensional subspace and that decorrelating the features of the representations can stabilize training of the automatic speech recognizer. Finally, we propose a bidirectional extension to the original wav2vec framework that consistently improves performance.
MultiQT: Multimodal Learning for Real-Time Question Tracking in Speech
May 12, 2020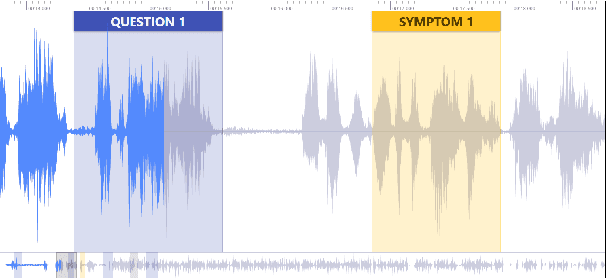

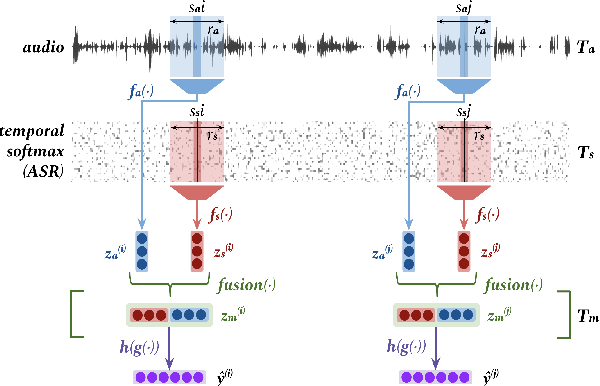

We address a challenging and practical task of labeling questions in speech in real time during telephone calls to emergency medical services in English, which embeds within a broader decision support system for emergency call-takers. We propose a novel multimodal approach to real-time sequence labeling in speech. Our model treats speech and its own textual representation as two separate modalities or views, as it jointly learns from streamed audio and its noisy transcription into text via automatic speech recognition. Our results show significant gains of jointly learning from the two modalities when compared to text or audio only, under adverse noise and limited volume of training data. The results generalize to medical symptoms detection where we observe a similar pattern of improvements with multimodal learning.
BIVA: A Very Deep Hierarchy of Latent Variables for Generative Modeling
Feb 06, 2019

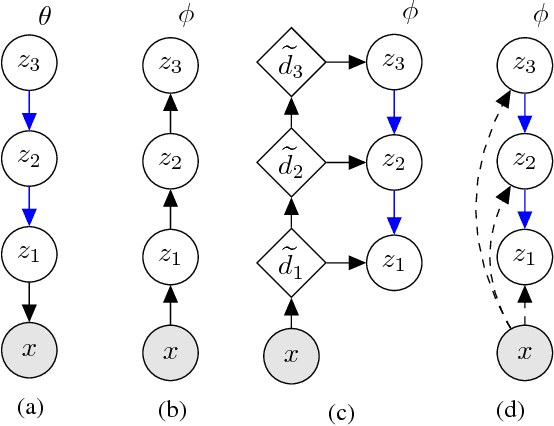

With the introduction of the variational autoencoder (VAE), probabilistic latent variable models have received renewed attention as powerful generative models. However, their performance in terms of test likelihood and quality of generated samples has been surpassed by autoregressive models without stochastic units. Furthermore, flow-based models have recently been shown to be an attractive alternative that scales well to high-dimensional data. In this paper we close the performance gap by constructing VAE models that can effectively utilize a deep hierarchy of stochastic variables and model complex covariance structures. We introduce the Bidirectional-Inference Variational Autoencoder (BIVA), characterized by a skip-connected generative model and an inference network formed by a bidirectional stochastic inference path. We show that BIVA reaches state-of-the-art test likelihoods, generates sharp and coherent natural images, and uses the hierarchy of latent variables to capture different aspects of the data distribution. We observe that BIVA, in contrast to recent results, can be used for anomaly detection. We attribute this to the hierarchy of latent variables which is able to extract high-level semantic features. Finally, we extend BIVA to semi-supervised classification tasks and show that it performs comparably to state-of-the-art results by generative adversarial networks.
On the Inductive Bias of Word-Character-Level Multi-Task Learning for Speech Recognition
Nov 28, 2018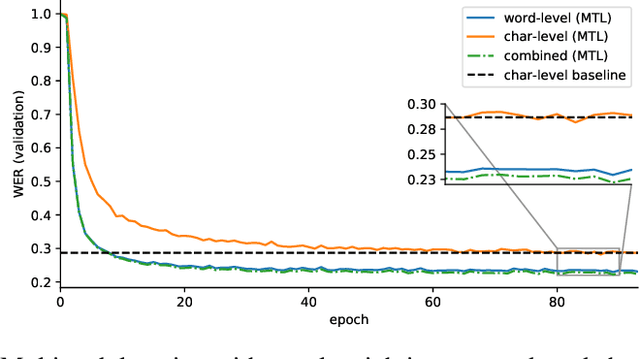
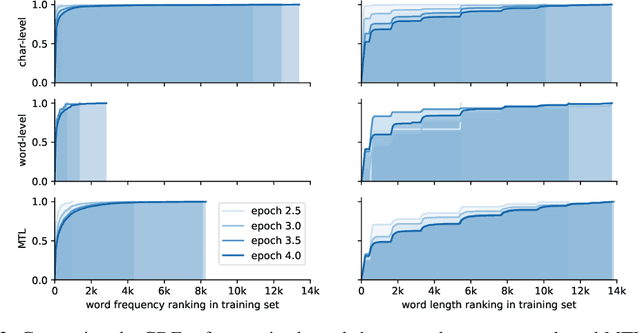
End-to-end automatic speech recognition (ASR) commonly transcribes audio signals into sequences of characters while its performance is evaluated by measuring the word-error rate (WER). This suggests that predicting sequences of words directly may be helpful instead. However, training with word-level supervision can be more difficult due to the sparsity of examples per label class. In this paper we analyze an end-to-end ASR model that combines a word-and-character representation in a multi-task learning (MTL) framework. We show that it improves on the WER and study how the word-level model can benefit from character-level supervision by analyzing the learned inductive preference bias of each model component empirically. We find that by adding character-level supervision, the MTL model interpolates between recognizing more frequent words (preferred by the word-level model) and shorter words (preferred by the character-level model).
Utilizing Domain Knowledge in End-to-End Audio Processing
Dec 01, 2017
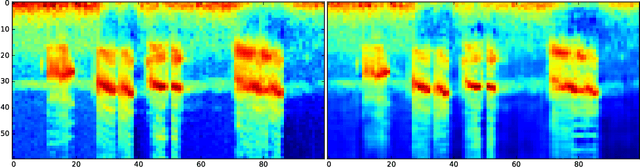
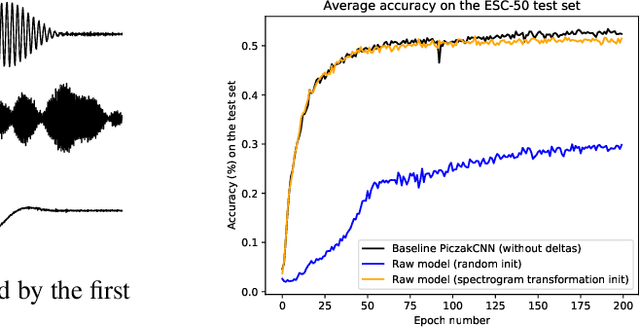
End-to-end neural network based approaches to audio modelling are generally outperformed by models trained on high-level data representations. In this paper we present preliminary work that shows the feasibility of training the first layers of a deep convolutional neural network (CNN) model to learn the commonly-used log-scaled mel-spectrogram transformation. Secondly, we demonstrate that upon initializing the first layers of an end-to-end CNN classifier with the learned transformation, convergence and performance on the ESC-50 environmental sound classification dataset are similar to a CNN-based model trained on the highly pre-processed log-scaled mel-spectrogram features.
Exploiting Nontrivial Connectivity for Automatic Speech Recognition
Nov 28, 2017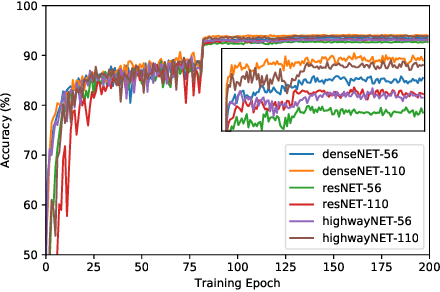
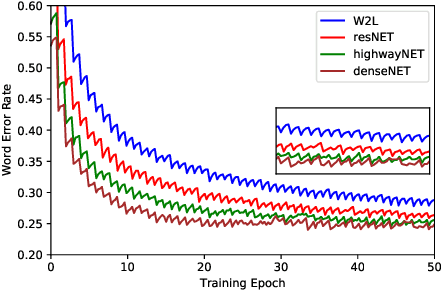

Nontrivial connectivity has allowed the training of very deep networks by addressing the problem of vanishing gradients and offering a more efficient method of reusing parameters. In this paper we make a comparison between residual networks, densely-connected networks and highway networks on an image classification task. Next, we show that these methodologies can easily be deployed into automatic speech recognition and provide significant improvements to existing models.
Semi-Supervised Generation with Cluster-aware Generative Models
Apr 03, 2017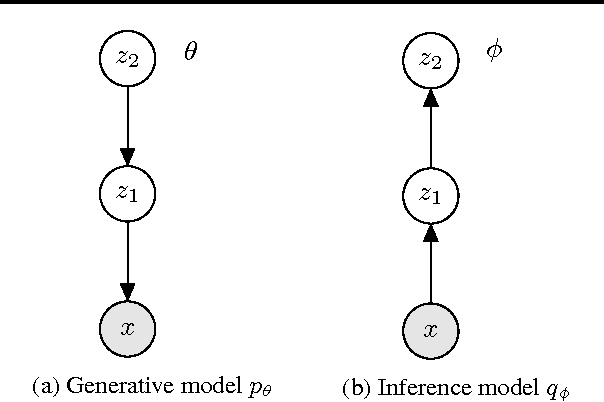
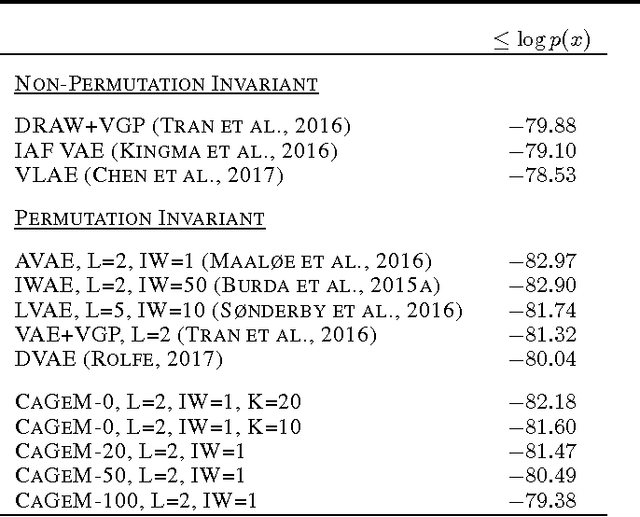
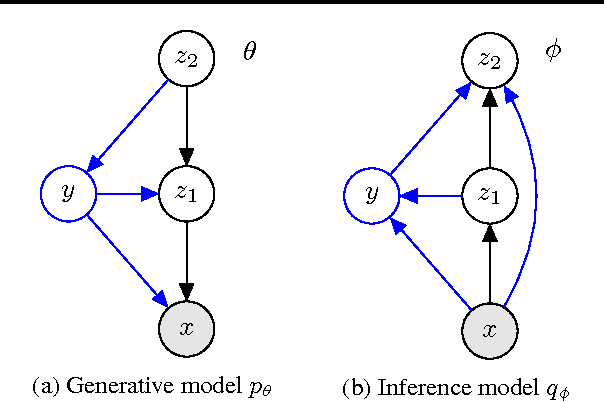

Deep generative models trained with large amounts of unlabelled data have proven to be powerful within the domain of unsupervised learning. Many real life data sets contain a small amount of labelled data points, that are typically disregarded when training generative models. We propose the Cluster-aware Generative Model, that uses unlabelled information to infer a latent representation that models the natural clustering of the data, and additional labelled data points to refine this clustering. The generative performances of the model significantly improve when labelled information is exploited, obtaining a log-likelihood of -79.38 nats on permutation invariant MNIST, while also achieving competitive semi-supervised classification accuracies. The model can also be trained fully unsupervised, and still improve the log-likelihood performance with respect to related methods.