 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Large-Scale Retrieval: Binary or n-ary Coding?
Sep 20, 2015



The growing amount of data available in modern-day datasets makes the need to efficiently search and retrieve information. To make large-scale search feasible, Distance Estimation and Subset Indexing are the main approaches. Although binary coding has been popular for implementing both techniques, n-ary coding (known as Product Quantization) is also very effective for Distance Estimation. However, their relative performance has not been studied for Subset Indexing. We investigate whether binary or n-ary coding works better under different retrieval strategies. This leads to the design of a new n-ary coding method, "Linear Subspace Quantization (LSQ)" which, unlike other n-ary encoders, can be used as a similarity-preserving embedding. Experiments on image retrieval show that when Distance Estimation is used, n-ary LSQ outperforms other methods. However, when Subset Indexing is applied, interestingly, binary codings are more effective and binary LSQ achieves the best accuracy.
Multi-Directional Multi-Level Dual-Cross Patterns for Robust Face Recognition
Aug 06, 2015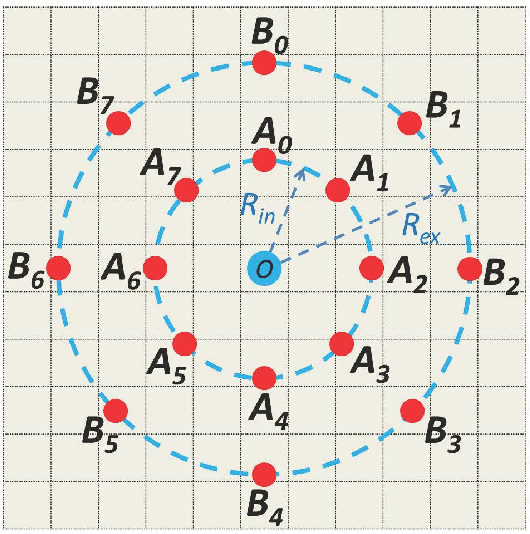
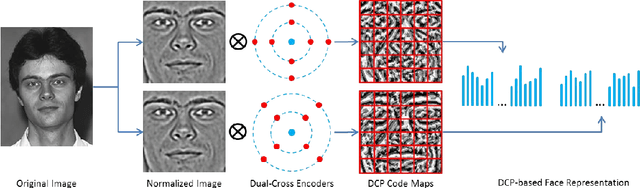
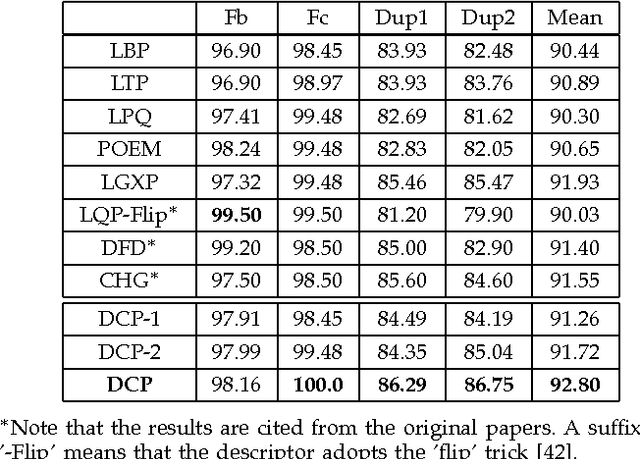
To perform unconstrained face recognition robust to variations in illumination, pose and expression, this paper presents a new scheme to extract "Multi-Directional Multi-Level Dual-Cross Patterns" (MDML-DCPs) from face images. Specifically, the MDMLDCPs scheme exploits the first derivative of Gaussian operator to reduce the impact of differences in illumination and then computes the DCP feature at both the holistic and component levels. DCP is a novel face image descriptor inspired by the unique textural structure of human faces. It is computationally efficient and only doubles the cost of computing local binary patterns, yet is extremely robust to pose and expression variations. MDML-DCPs comprehensively yet efficiently encodes the invariant characteristics of a face image from multiple levels into patterns that are highly discriminative of inter-personal differences but robust to intra-personal variations. Experimental results on the FERET, CAS-PERL-R1, FRGC 2.0, and LFW databases indicate that DCP outperforms the state-of-the-art local descriptors (e.g. LBP, LTP, LPQ, POEM, tLBP, and LGXP) for both face identification and face verification tasks. More impressively, the best performance is achieved on the challenging LFW and FRGC 2.0 databases by deploying MDML-DCPs in a simple recognition scheme.
Exploiting Local Features from Deep Networks for Image Retrieval
Apr 30, 2015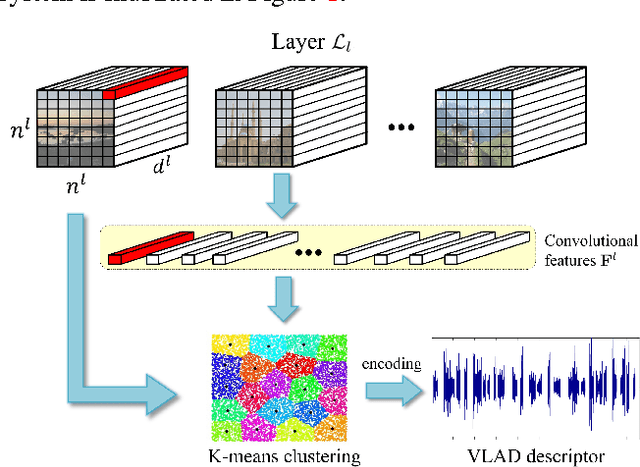
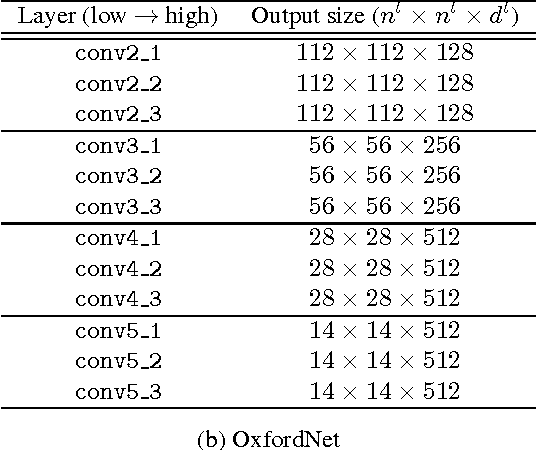
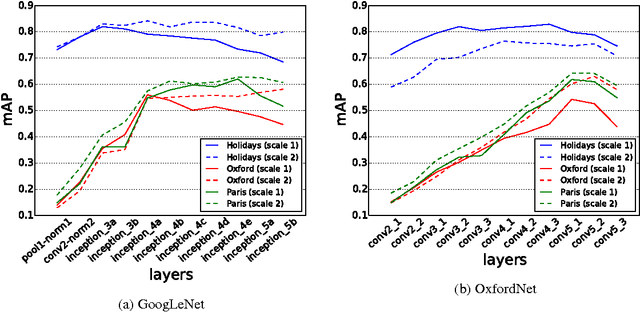
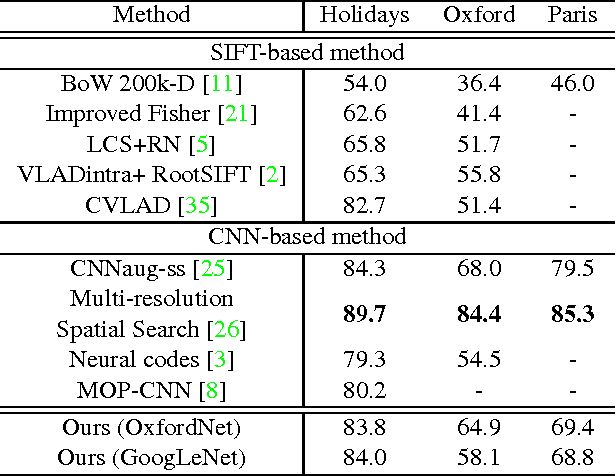
Deep convolutional neural networks have been successfully applied to image classification tasks. When these same networks have been applied to image retrieval, the assumption has been made that the last layers would give the best performance, as they do in classification. We show that for instance-level image retrieval, lower layers often perform better than the last layers in convolutional neural networks. We present an approach for extracting convolutional features from different layers of the networks, and adopt VLAD encoding to encode features into a single vector for each image. We investigate the effect of different layers and scales of input images on the performance of convolutional features using the recent deep networks OxfordNet and GoogLeNet. Experiments demonstrate that intermediate layers or higher layers with finer scales produce better results for image retrieval, compared to the last layer. When using compressed 128-D VLAD descriptors, our method obtains state-of-the-art results and outperforms other VLAD and CNN based approaches on two out of three test datasets. Our work provides guidance for transferring deep networks trained on image classification to image retrieval tasks.
SHOE: Supervised Hashing with Output Embeddings
Jan 30, 2015
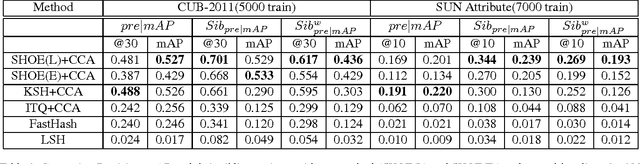

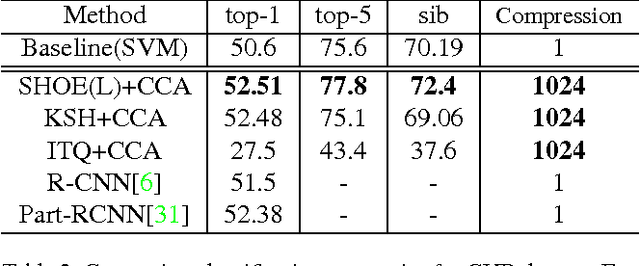
We present a supervised binary encoding scheme for image retrieval that learns projections by taking into account similarity between classes obtained from output embeddings. Our motivation is that binary hash codes learned in this way improve both the visual quality of retrieval results and existing supervised hashing schemes. We employ a sequential greedy optimization that learns relationship aware projections by minimizing the difference between inner products of binary codes and output embedding vectors. We develop a joint optimization framework to learn projections which improve the accuracy of supervised hashing over the current state of the art with respect to standard and sibling evaluation metrics. We further boost performance by applying the supervised dimensionality reduction technique on kernelized input CNN features. Experiments are performed on three datasets: CUB-2011, SUN-Attribute and ImageNet ILSVRC 2010. As a by-product of our method, we show that using a simple k-nn pooling classifier with our discriminative codes improves over the complex classification models on fine grained datasets like CUB and offer an impressive compression ratio of 1024 on CNN features.
Comparing apples to apples in the evaluation of binary coding methods
Sep 27, 2014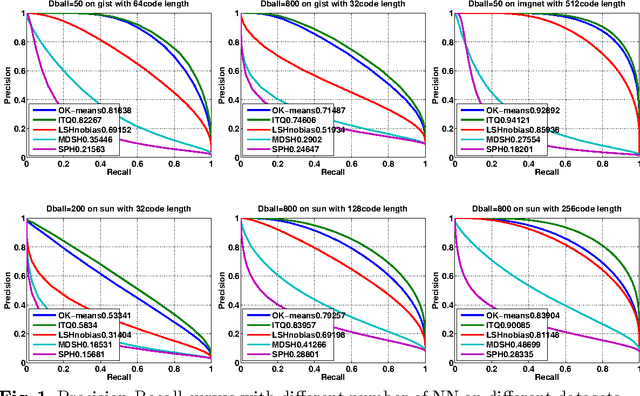
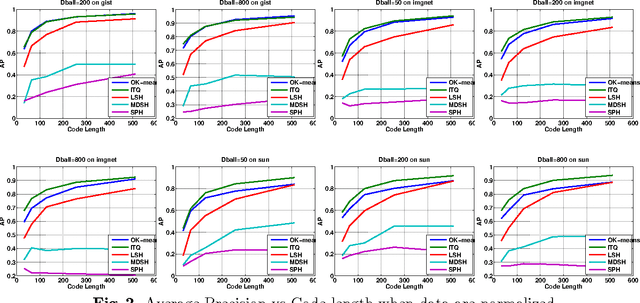
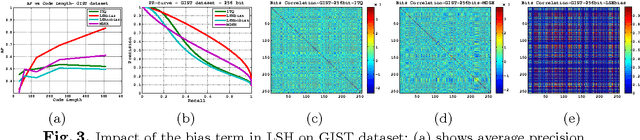
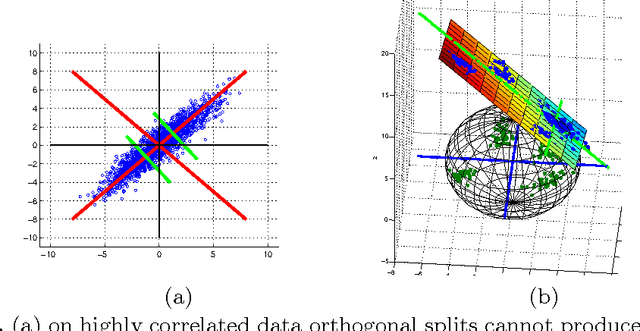
We discuss methodological issues related to the evaluation of unsupervised binary code construction methods for nearest neighbor search. These issues have been widely ignored in literature. These coding methods attempt to preserve either Euclidean distance or angular (cosine) distance in the binary embedding space. We explain why when comparing a method whose goal is preserving cosine similarity to one designed for preserving Euclidean distance, the original features should be normalized by mapping them to the unit hypersphere before learning the binary mapping functions. To compare a method whose goal is to preserves Euclidean distance to one that preserves cosine similarity, the original feature data must be mapped to a higher dimension by including a bias term in binary mapping functions. These conditions ensure the fair comparison between different binary code methods for the task of nearest neighbor search. Our experiments show under these conditions the very simple methods (e.g. LSH and ITQ) often outperform recent state-of-the-art methods (e.g. MDSH and OK-means).