 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntuitive and Efficient Human-robot Collaboration via Real-time Approximate Bayesian Inference
May 17, 2022
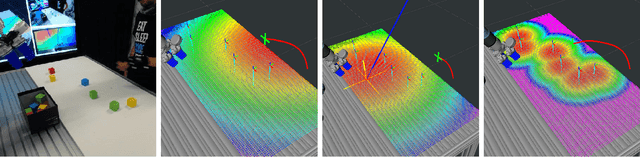
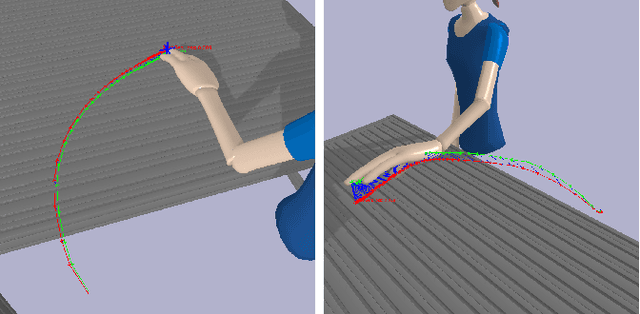
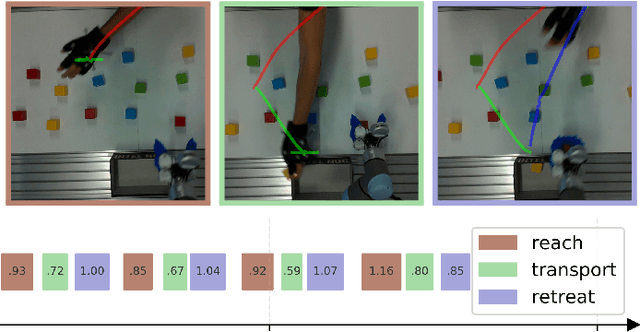
The combination of collaborative robots and end-to-end AI, promises flexible automation of human tasks in factories and warehouses. However, such promise seems a few breakthroughs away. In the meantime, humans and cobots will collaborate helping each other. For these collaborations to be effective and safe, robots need to model, predict and exploit human's intents for responsive decision making processes. Approximate Bayesian Computation (ABC) is an analysis-by-synthesis approach to perform probabilistic predictions upon uncertain quantities. ABC includes priors conveniently, leverages sampling algorithms for inference and is flexible to benefit from complex models, e.g. via simulators. However, ABC is known to be computationally too intensive to run at interactive frame rates required for effective human-robot collaboration tasks. In this paper, we formulate human reaching intent prediction as an ABC problem and describe two key performance innovations which allow computations at interactive rates. Our real-world experiments with a collaborative robot set-up, demonstrate the viability of our proposed approach. Experimental evaluations convey the advantages and value of human intent prediction for packing cooperative tasks. Qualitative results show how anticipating human's reaching intent improves human-robot collaboration without compromising safety. Quantitative task fluency metrics confirm the qualitative claims.
Data Augmentation with Paraphrase Generation and Entity Extraction for Multimodal Dialogue System
May 09, 2022
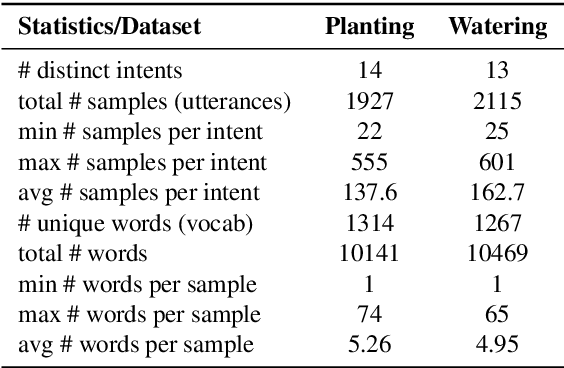
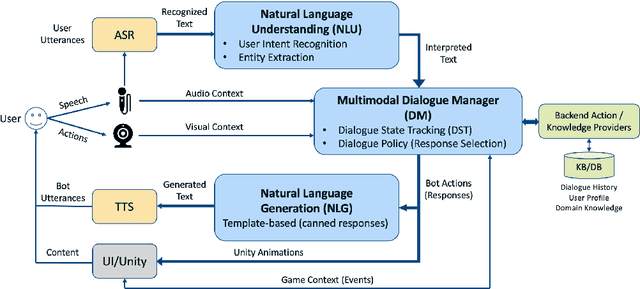
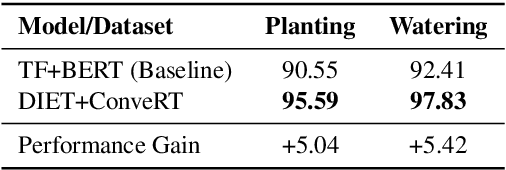
Contextually aware intelligent agents are often required to understand the users and their surroundings in real-time. Our goal is to build Artificial Intelligence (AI) systems that can assist children in their learning process. Within such complex frameworks, Spoken Dialogue Systems (SDS) are crucial building blocks to handle efficient task-oriented communication with children in game-based learning settings. We are working towards a multimodal dialogue system for younger kids learning basic math concepts. Our focus is on improving the Natural Language Understanding (NLU) module of the task-oriented SDS pipeline with limited datasets. This work explores the potential benefits of data augmentation with paraphrase generation for the NLU models trained on small task-specific datasets. We also investigate the effects of extracting entities for conceivably further data expansion. We have shown that paraphrasing with model-in-the-loop (MITL) strategies using small seed data is a promising approach yielding improved performance results for the Intent Recognition task.
Controllable Response Generation for Assistive Use-cases
Dec 04, 2021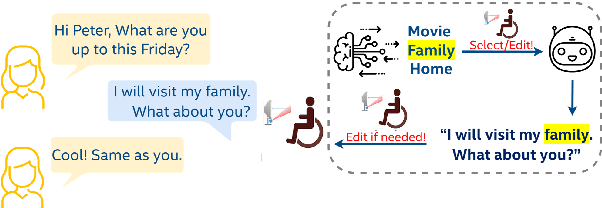
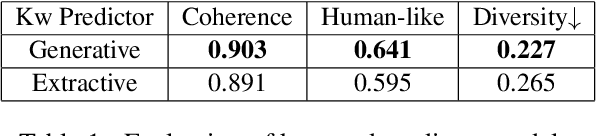
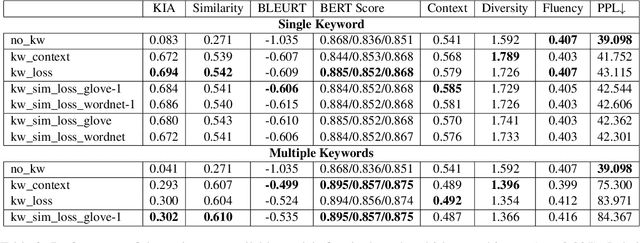
Conversational agents have become an integral part of the general population for simple task enabling situations. However, these systems are yet to have any social impact on the diverse and minority population, for example, helping people with neurological disorders, for example ALS, and people with speech, language and social communication disorders. Language model technology can play a huge role to help these users carry out daily communication and social interactions. To enable this population, we build a dialog system that can be controlled by users using cues or keywords. We build models that can suggest relevant cues in the dialog response context which is used to control response generation and can speed up communication. We also introduce a keyword loss to lexically constrain the model output. We show both qualitatively and quantitatively that our models can effectively induce the keyword into the model response without degrading the quality of response. In the context of usage of such systems for people with degenerative disorders, we present human evaluation of our cue or keyword predictor and the controllable dialog system and show that our models perform significantly better than models without control. Our study shows that keyword control on end to end response generation models is powerful and can enable and empower users with degenerative disorders to carry out their day to day communication.
Semi-supervised Interactive Intent Labeling
May 12, 2021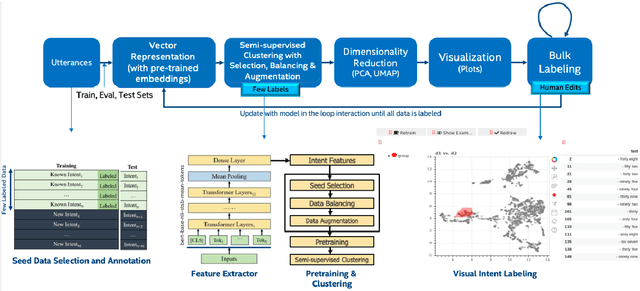

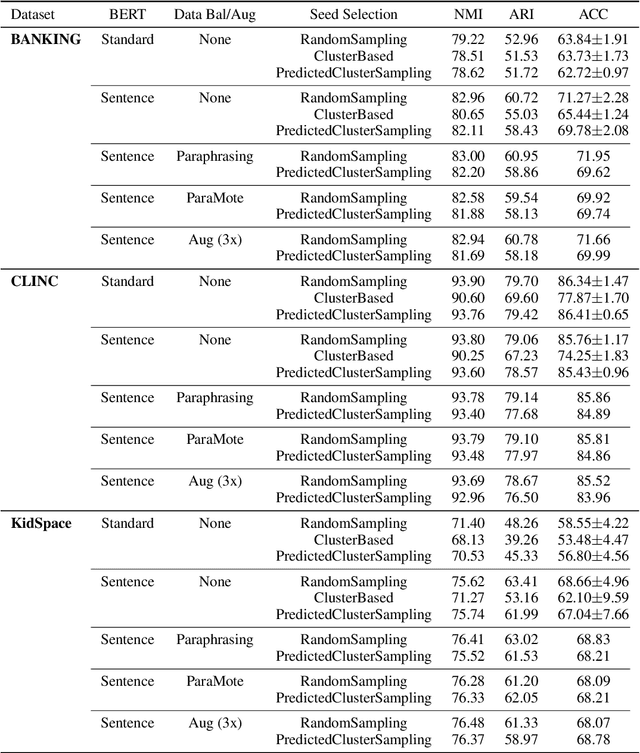
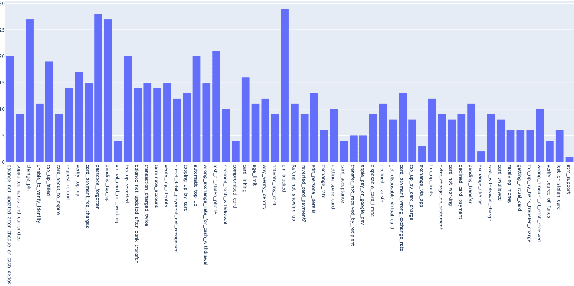
Building the Natural Language Understanding (NLU) modules of task-oriented Spoken Dialogue Systems (SDS) involves a definition of intents and entities, collection of task-relevant data, annotating the data with intents and entities, and then repeating the same process over and over again for adding any functionality/enhancement to the SDS. In this work, we showcase an Intent Bulk Labeling system where SDS developers can interactively label and augment training data from unlabeled utterance corpora using advanced clustering and visual labeling methods. We extend the Deep Aligned Clustering work with a better backbone BERT model, explore techniques to select the seed data for labeling, and develop a data balancing method using an oversampling technique that utilizes paraphrasing models. We also look at the effect of data augmentation on the clustering process. Our results show that we can achieve over 10% gain in clustering accuracy on some datasets using the combination of the above techniques. Finally, we extract utterance embeddings from the clustering model and plot the data to interactively bulk label the samples, reducing the time and effort for data labeling of the whole dataset significantly.
Uncertainty as a Form of Transparency: Measuring, Communicating, and Using Uncertainty
Nov 15, 2020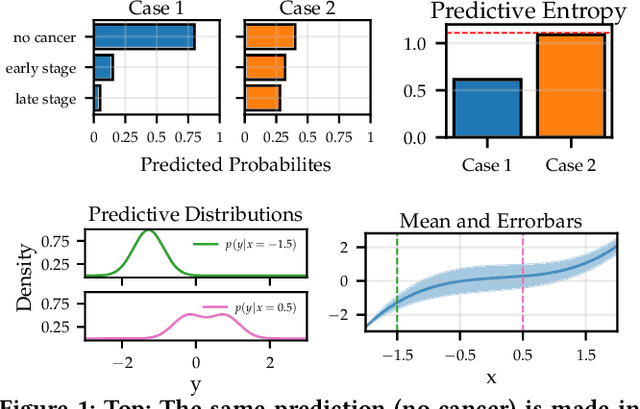

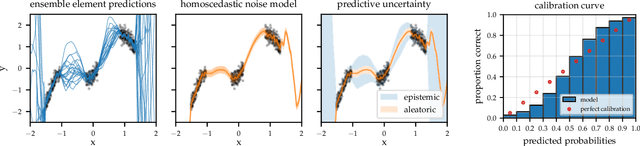
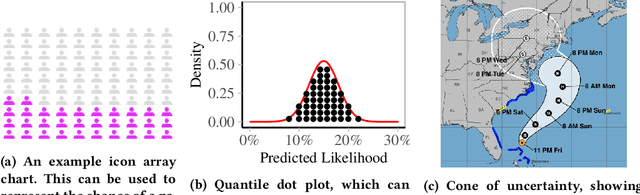
Transparency of algorithmic systems entails exposing system properties to various stakeholders for purposes that include understanding, improving, and/or contesting predictions. The machine learning (ML) community has mostly considered explainability as a proxy for transparency. With this work, we seek to encourage researchers to study uncertainty as a form of transparency and practitioners to communicate uncertainty estimates to stakeholders. First, we discuss methods for assessing uncertainty. Then, we describe the utility of uncertainty for mitigating model unfairness, augmenting decision-making, and building trustworthy systems. We also review methods for displaying uncertainty to stakeholders and discuss how to collect information required for incorporating uncertainty into existing ML pipelines. Our contribution is an interdisciplinary review to inform how to measure, communicate, and use uncertainty as a form of transparency.
Audio-Visual Understanding of Passenger Intents for In-Cabin Conversational Agents
Jul 08, 2020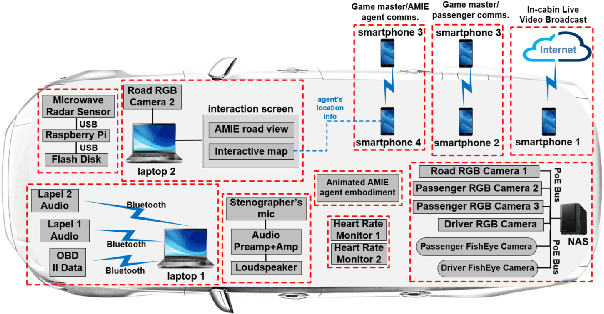
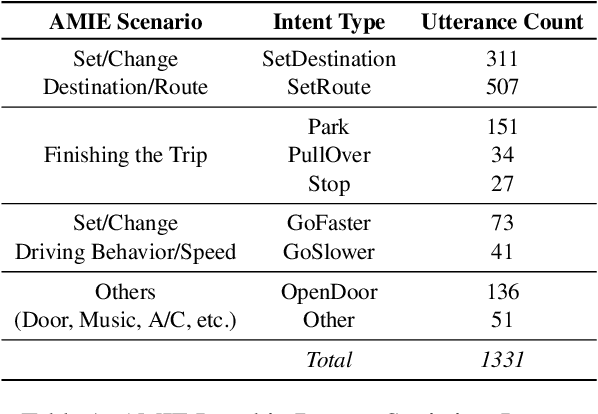
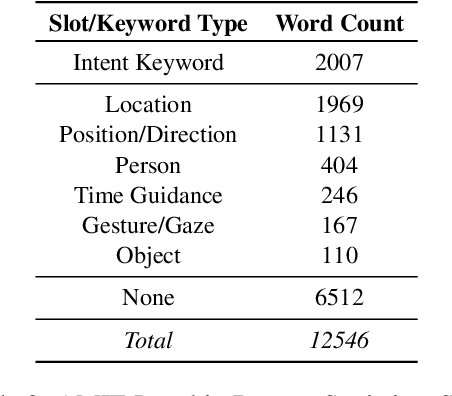

Building multimodal dialogue understanding capabilities situated in the in-cabin context is crucial to enhance passenger comfort in autonomous vehicle (AV) interaction systems. To this end, understanding passenger intents from spoken interactions and vehicle vision systems is a crucial component for developing contextual and visually grounded conversational agents for AV. Towards this goal, we explore AMIE (Automated-vehicle Multimodal In-cabin Experience), the in-cabin agent responsible for handling multimodal passenger-vehicle interactions. In this work, we discuss the benefits of a multimodal understanding of in-cabin utterances by incorporating verbal/language input together with the non-verbal/acoustic and visual clues from inside and outside the vehicle. Our experimental results outperformed text-only baselines as we achieved improved performances for intent detection with a multimodal approach.
Low Rank Fusion based Transformers for Multimodal Sequences
Jul 04, 2020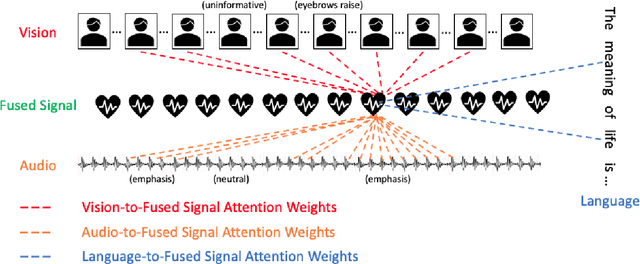
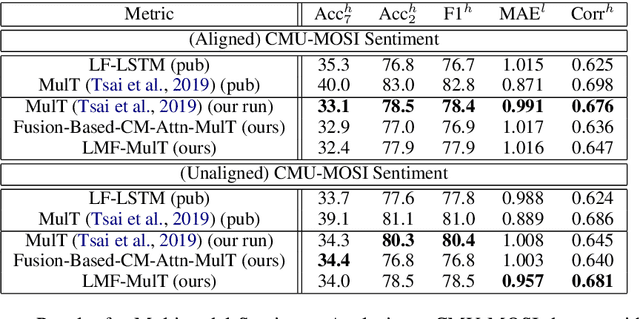
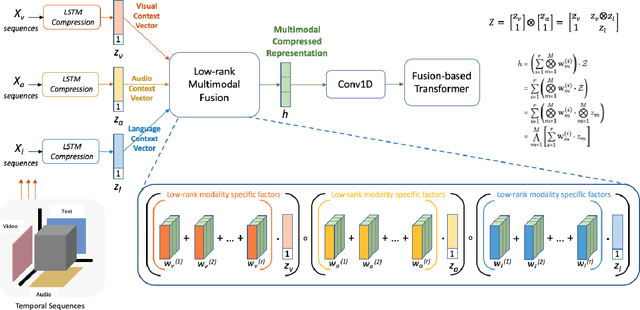
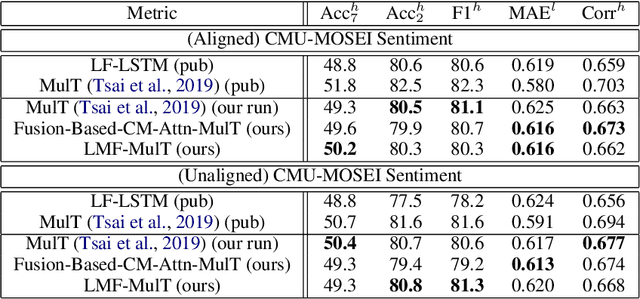
Our senses individually work in a coordinated fashion to express our emotional intentions. In this work, we experiment with modeling modality-specific sensory signals to attend to our latent multimodal emotional intentions and vice versa expressed via low-rank multimodal fusion and multimodal transformers. The low-rank factorization of multimodal fusion amongst the modalities helps represent approximate multiplicative latent signal interactions. Motivated by the work of~\cite{tsai2019MULT} and~\cite{Liu_2018}, we present our transformer-based cross-fusion architecture without any over-parameterization of the model. The low-rank fusion helps represent the latent signal interactions while the modality-specific attention helps focus on relevant parts of the signal. We present two methods for the Multimodal Sentiment and Emotion Recognition results on CMU-MOSEI, CMU-MOSI, and IEMOCAP datasets and show that our models have lesser parameters, train faster and perform comparably to many larger fusion-based architectures.
Exploring Context, Attention and Audio Features for Audio Visual Scene-Aware Dialog
Dec 20, 2019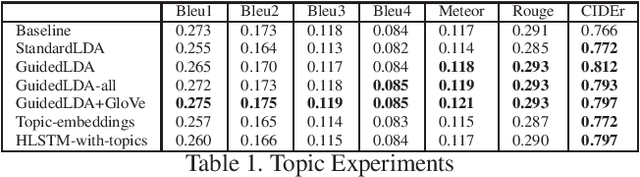
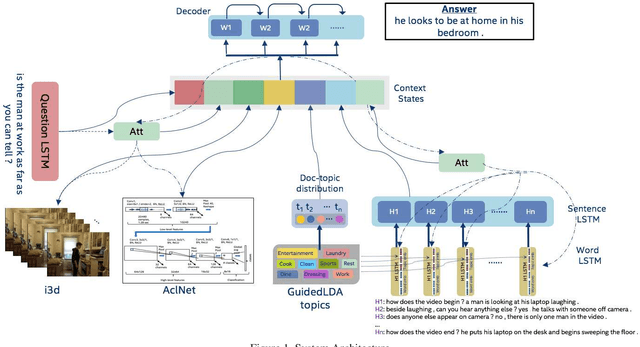
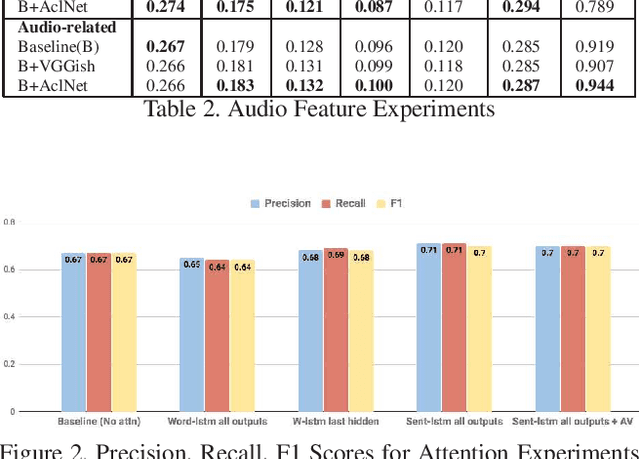
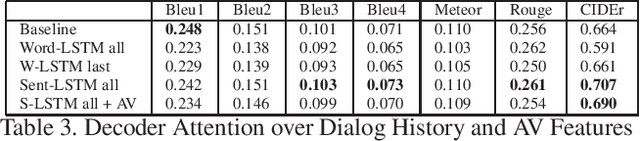
We are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances and have conversations with users about the objects, activities and events surrounding them. Recent progress in visual grounding techniques and Audio Understanding are enabling machines to understand shared semantic concepts and listen to the various sensory events in the environment. With audio and visual grounding methods, end-to-end multimodal SDS are trained to meaningfully communicate with us in natural language about the real dynamic audio-visual sensory world around us. In this work, we explore the role of `topics' as the context of the conversation along with multimodal attention into such an end-to-end audio-visual scene-aware dialog system architecture. We also incorporate an end-to-end audio classification ConvNet, AclNet, into our models. We develop and test our approaches on the Audio Visual Scene-Aware Dialog (AVSD) dataset released as a part of the DSTC7. We present the analysis of our experiments and show that some of our model variations outperform the baseline system released for AVSD.
Leveraging Topics and Audio Features with Multimodal Attention for Audio Visual Scene-Aware Dialog
Dec 20, 2019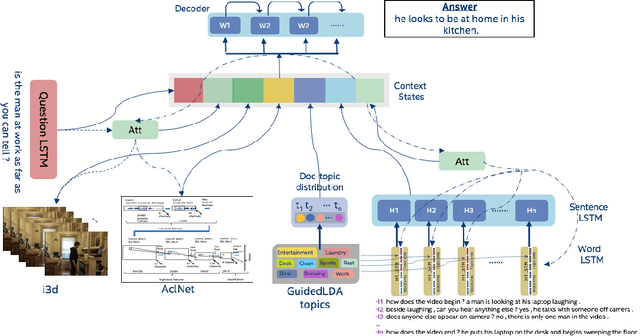

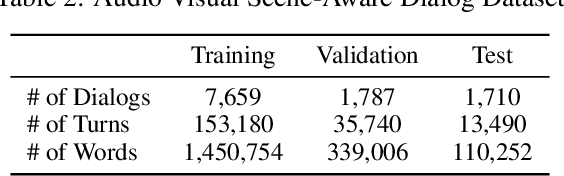
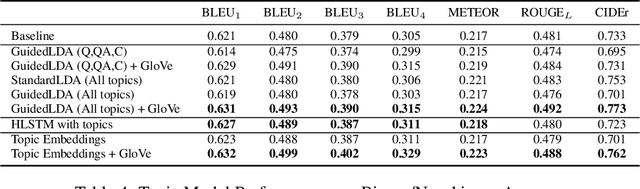
With the recent advancements in Artificial Intelligence (AI), Intelligent Virtual Assistants (IVA) such as Alexa, Google Home, etc., have become a ubiquitous part of many homes. Currently, such IVAs are mostly audio-based, but going forward, we are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances. This will enable agents to have conversations with users about the objects, activities and events surrounding them. In this work, we present three main architectural explorations for the Audio Visual Scene-Aware Dialog (AVSD): 1) investigating `topics' of the dialog as an important contextual feature for the conversation, 2) exploring several multimodal attention mechanisms during response generation, 3) incorporating an end-to-end audio classification ConvNet, AclNet, into our architecture. We discuss detailed analysis of the experimental results and show that our model variations outperform the baseline system presented for the AVSD task.
Modeling Intent, Dialog Policies and Response Adaptation for Goal-Oriented Interactions
Dec 20, 2019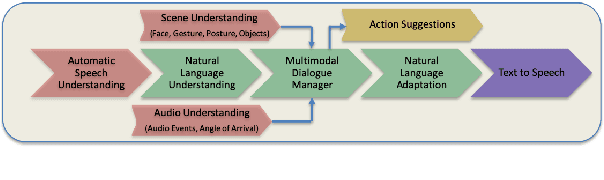
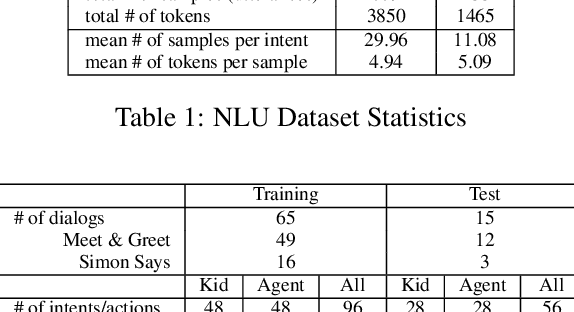
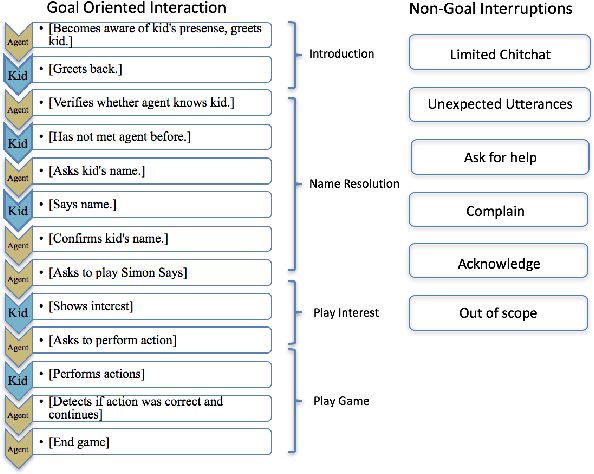
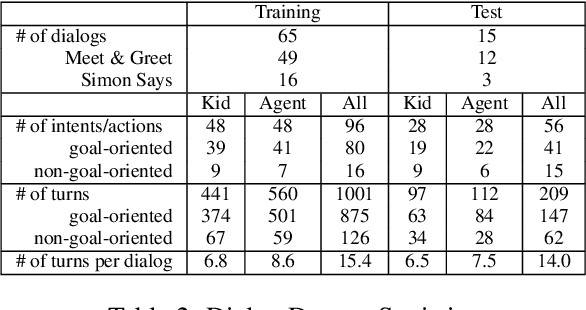
Building a machine learning driven spoken dialog system for goal-oriented interactions involves careful design of intents and data collection along with development of intent recognition models and dialog policy learning algorithms. The models should be robust enough to handle various user distractions during the interaction flow and should steer the user back into an engaging interaction for successful completion of the interaction. In this work, we have designed a goal-oriented interaction system where children can engage with agents for a series of interactions involving `Meet \& Greet' and `Simon Says' game play. We have explored various feature extractors and models for improved intent recognition and looked at leveraging previous user and system interactions in novel ways with attention models. We have also looked at dialog adaptation methods for entrained response selection. Our bootstrapped models from limited training data perform better than many baseline approaches we have looked at for intent recognition and dialog action prediction.
* Presented as a full-paper at the 23rd Workshop on the Semantics and Pragmatics of Dialogue (SemDial 2019 - LondonLogue), Sep 4-6, 2019, London, UK