 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Audio Signal Preprocessing Methods for Deep Neural Networks on Music Tagging
Jun 03, 2018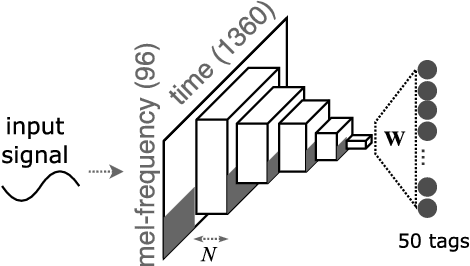
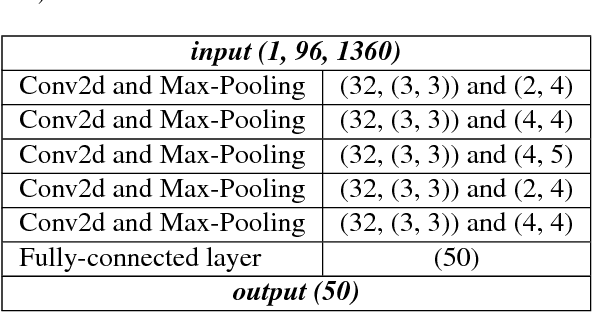
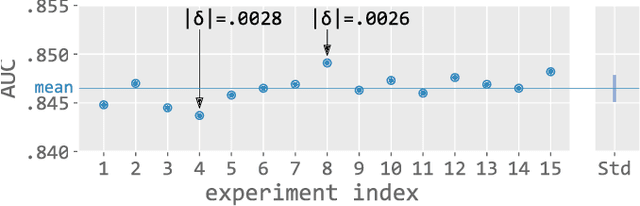
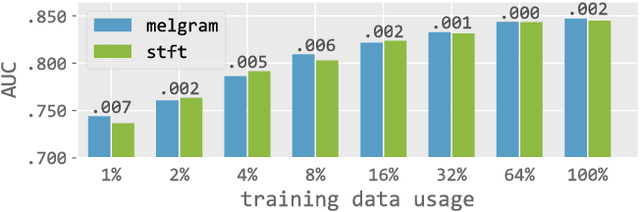
In this paper, we empirically investigate the effect of audio preprocessing on music tagging with deep neural networks. We perform comprehensive experiments involving audio preprocessing using different time-frequency representations, logarithmic magnitude compression, frequency weighting, and scaling. We show that many commonly used input preprocessing techniques are redundant except magnitude compression.
DialogWAE: Multimodal Response Generation with Conditional Wasserstein Auto-Encoder
May 31, 2018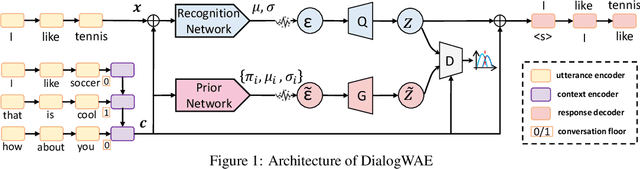
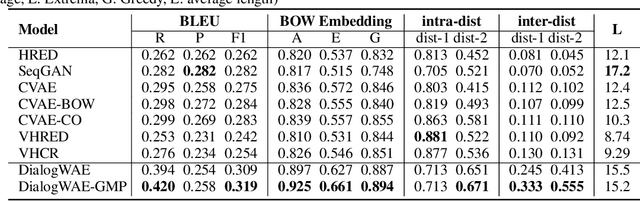
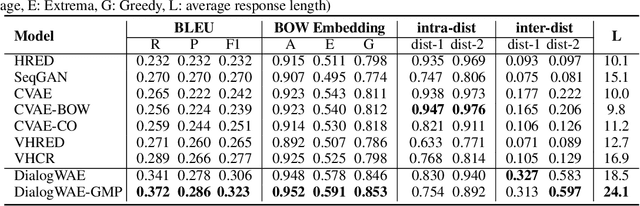
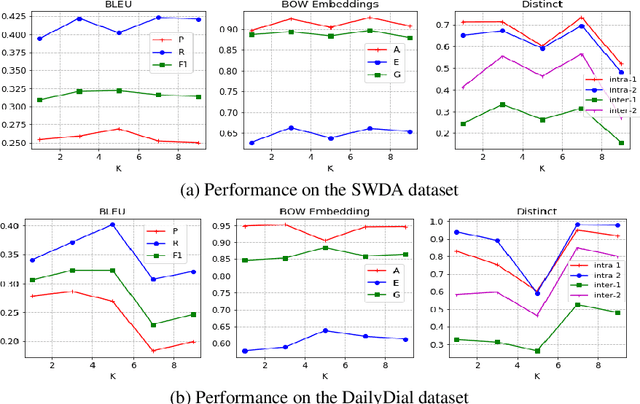
Variational autoencoders (VAEs) have shown a promise in data-driven conversation modeling. However, most VAE conversation models match the approximate posterior distribution over the latent variables to a simple prior such as standard normal distribution, thereby restricting the generated responses to a relatively simple (e.g., single-modal) scope. In this paper, we propose DialogWAE, a conditional Wasserstein autoencoder (WAE) specially designed for dialogue modeling. Unlike VAEs that impose a simple distribution over the latent variables, DialogWAE models the distribution of data by training a GAN within the latent variable space. Specifically, our model samples from the prior and posterior distributions over the latent variables by transforming context-dependent random noise using neural networks and minimizes the Wasserstein distance between the two distributions. We further develop a Gaussian mixture prior network to enrich the latent space. Experiments on two widely-used datasets show that DialogWAE outperforms the state-of-the-art approaches in generating more coherent, informative and diverse responses.
A Tutorial on Deep Learning for Music Information Retrieval
May 03, 2018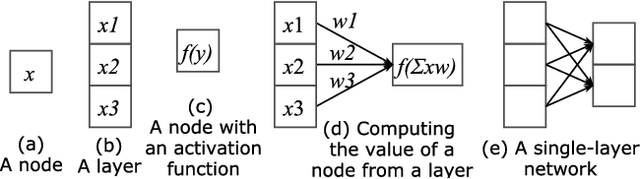

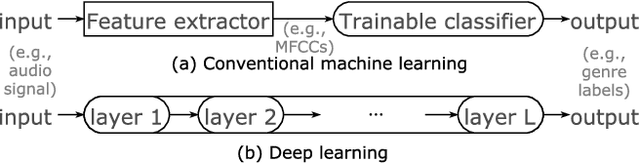

Following their success in Computer Vision and other areas, deep learning techniques have recently become widely adopted in Music Information Retrieval (MIR) research. However, the majority of works aim to adopt and assess methods that have been shown to be effective in other domains, while there is still a great need for more original research focusing on music primarily and utilising musical knowledge and insight. The goal of this paper is to boost the interest of beginners by providing a comprehensive tutorial and reducing the barriers to entry into deep learning for MIR. We lay out the basic principles and review prominent works in this hard to navigate the field. We then outline the network structures that have been successful in MIR problems and facilitate the selection of building blocks for the problems at hand. Finally, guidelines for new tasks and some advanced topics in deep learning are discussed to stimulate new research in this fascinating field.
Multi-lingual Common Semantic Space Construction via Cluster-consistent Word Embedding
Apr 21, 2018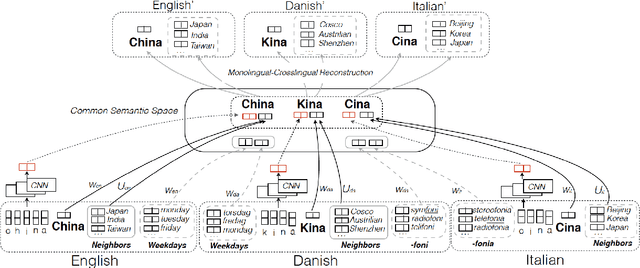
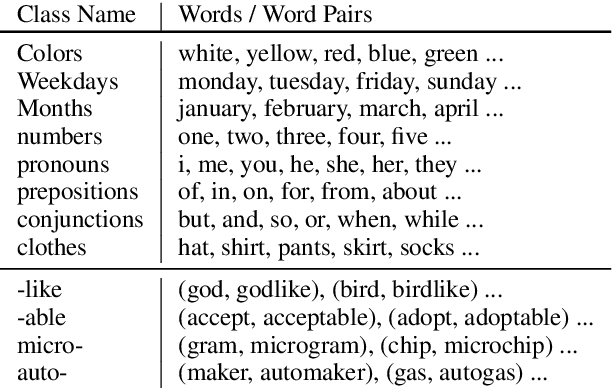

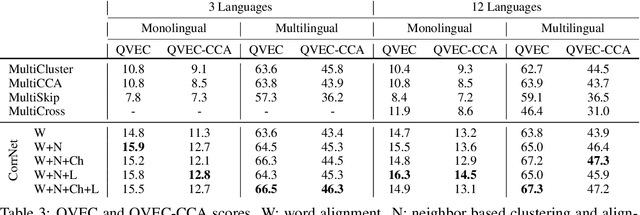
We construct a multilingual common semantic space based on distributional semantics, where words from multiple languages are projected into a shared space to enable knowledge and resource transfer across languages. Beyond word alignment, we introduce multiple cluster-level alignments and enforce the word clusters to be consistently distributed across multiple languages. We exploit three signals for clustering: (1) neighbor words in the monolingual word embedding space; (2) character-level information; and (3) linguistic properties (e.g., apposition, locative suffix) derived from linguistic structure knowledge bases available for thousands of languages. We introduce a new cluster-consistent correlational neural network to construct the common semantic space by aligning words as well as clusters. Intrinsic evaluation on monolingual and multilingual QVEC tasks shows our approach achieves significantly higher correlation with linguistic features than state-of-the-art multi-lingual embedding learning methods do. Using low-resource language name tagging as a case study for extrinsic evaluation, our approach achieves up to 24.5\% absolute F-score gain over the state of the art.
Emergent Communication in a Multi-Modal, Multi-Step Referential Game
Apr 16, 2018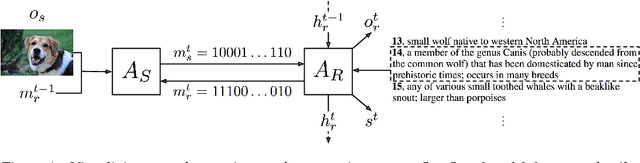

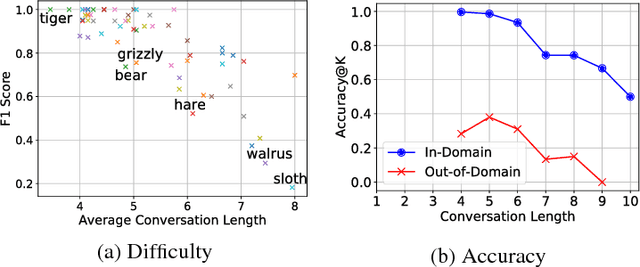
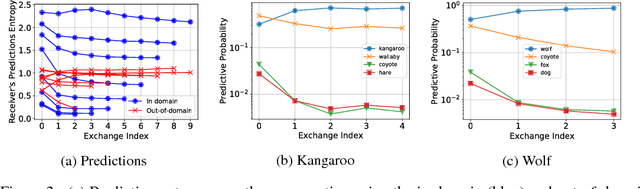
Inspired by previous work on emergent communication in referential games, we propose a novel multi-modal, multi-step referential game, where the sender and receiver have access to distinct modalities of an object, and their information exchange is bidirectional and of arbitrary duration. The multi-modal multi-step setting allows agents to develop an internal communication significantly closer to natural language, in that they share a single set of messages, and that the length of the conversation may vary according to the difficulty of the task. We examine these properties empirically using a dataset consisting of images and textual descriptions of mammals, where the agents are tasked with identifying the correct object. Our experiments indicate that a robust and efficient communication protocol emerges, where gradual information exchange informs better predictions and higher communication bandwidth improves generalization.
Training a Ranking Function for Open-Domain Question Answering
Apr 12, 2018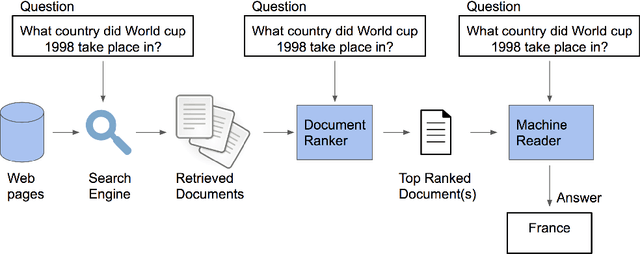

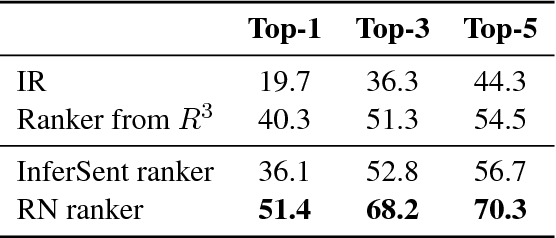
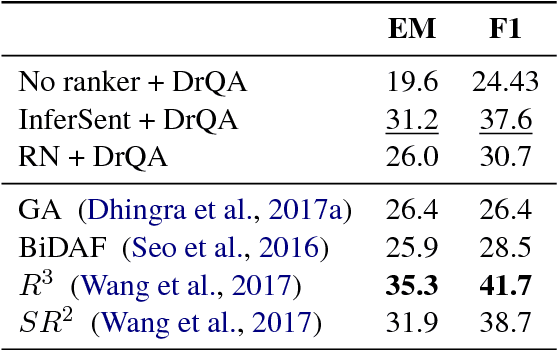
In recent years, there have been amazing advances in deep learning methods for machine reading. In machine reading, the machine reader has to extract the answer from the given ground truth paragraph. Recently, the state-of-the-art machine reading models achieve human level performance in SQuAD which is a reading comprehension-style question answering (QA) task. The success of machine reading has inspired researchers to combine information retrieval with machine reading to tackle open-domain QA. However, these systems perform poorly compared to reading comprehension-style QA because it is difficult to retrieve the pieces of paragraphs that contain the answer to the question. In this study, we propose two neural network rankers that assign scores to different passages based on their likelihood of containing the answer to a given question. Additionally, we analyze the relative importance of semantic similarity and word level relevance matching in open-domain QA.
Emergent Translation in Multi-Agent Communication
Apr 11, 2018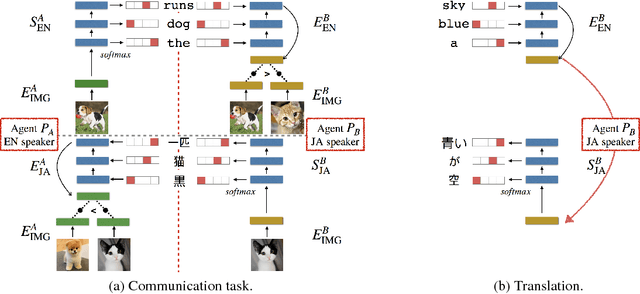
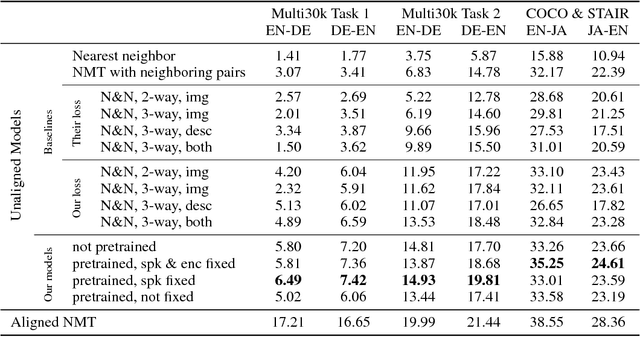
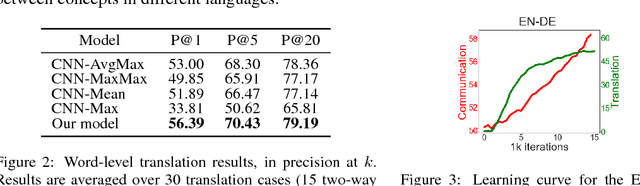

While most machine translation systems to date are trained on large parallel corpora, humans learn language in a different way: by being grounded in an environment and interacting with other humans. In this work, we propose a communication game where two agents, native speakers of their own respective languages, jointly learn to solve a visual referential task. We find that the ability to understand and translate a foreign language emerges as a means to achieve shared goals. The emergent translation is interactive and multimodal, and crucially does not require parallel corpora, but only monolingual, independent text and corresponding images. Our proposed translation model achieves this by grounding the source and target languages into a shared visual modality, and outperforms several baselines on both word-level and sentence-level translation tasks. Furthermore, we show that agents in a multilingual community learn to translate better and faster than in a bilingual communication setting.
Fine-Grained Attention Mechanism for Neural Machine Translation
Apr 03, 2018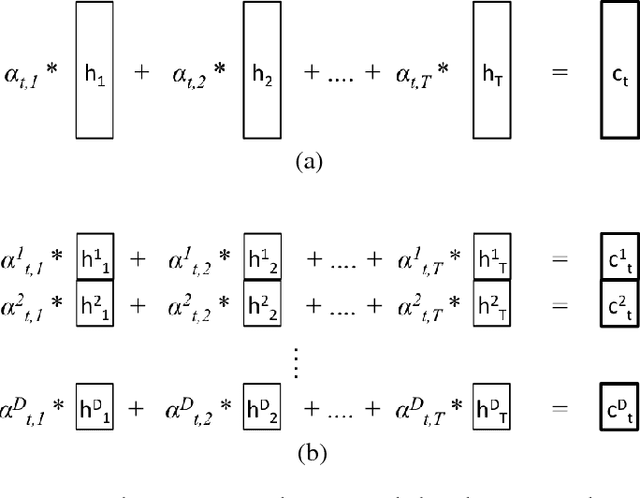
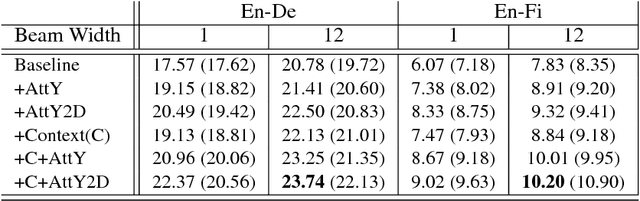
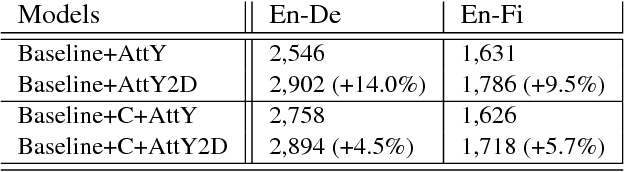
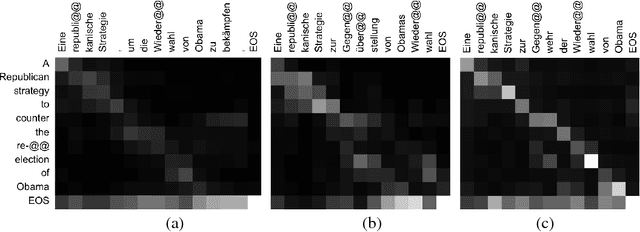
Neural machine translation (NMT) has been a new paradigm in machine translation, and the attention mechanism has become the dominant approach with the state-of-the-art records in many language pairs. While there are variants of the attention mechanism, all of them use only temporal attention where one scalar value is assigned to one context vector corresponding to a source word. In this paper, we propose a fine-grained (or 2D) attention mechanism where each dimension of a context vector will receive a separate attention score. In experiments with the task of En-De and En-Fi translation, the fine-grained attention method improves the translation quality in terms of BLEU score. In addition, our alignment analysis reveals how the fine-grained attention mechanism exploits the internal structure of context vectors.
* 9 pages, 4 figures
Segmentation of the Proximal Femur from MR Images using Deep Convolutional Neural Networks
Mar 20, 2018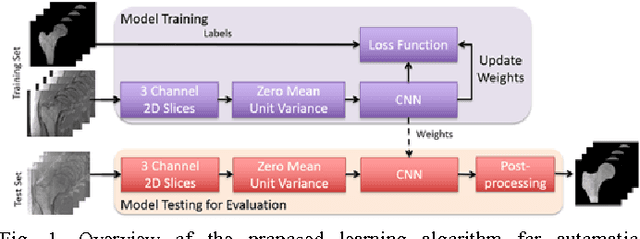
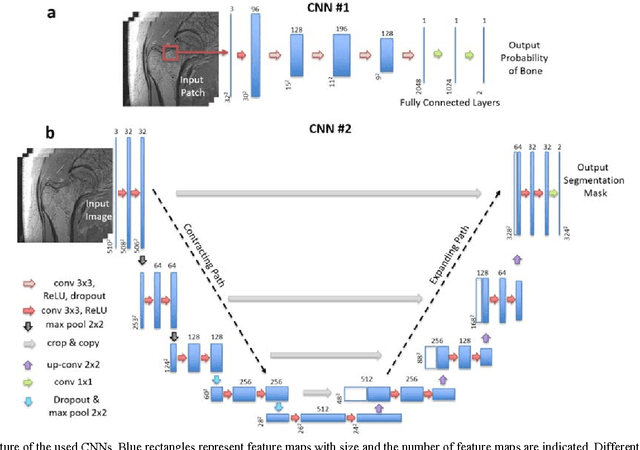
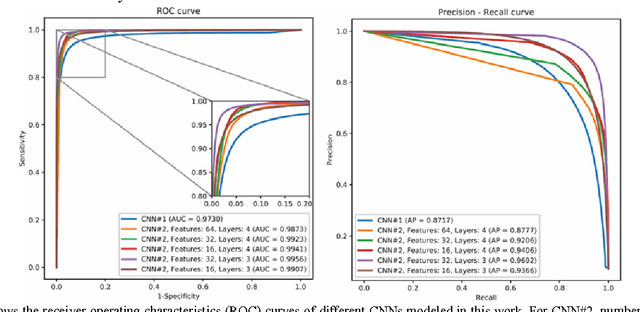
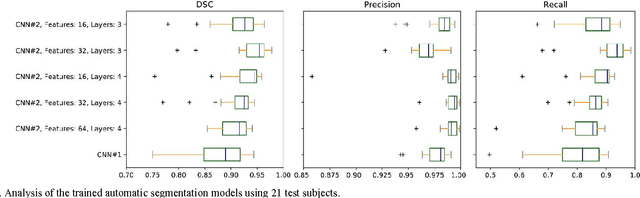
Magnetic resonance imaging (MRI) has been proposed as a complimentary method to measure bone quality and assess fracture risk. However, manual segmentation of MR images of bone is time-consuming, limiting the use of MRI measurements in the clinical practice. The purpose of this paper is to present an automatic proximal femur segmentation method that is based on deep convolutional neural networks (CNNs). This study had institutional review board approval and written informed consent was obtained from all subjects. A dataset of volumetric structural MR images of the proximal femur from 86 subject were manually-segmented by an expert. We performed experiments by training two different CNN architectures with multiple number of initial feature maps and layers, and tested their segmentation performance against the gold standard of manual segmentations using four-fold cross-validation. Automatic segmentation of the proximal femur achieved a high dice similarity score of 0.94$\pm$0.05 with precision = 0.95$\pm$0.02, and recall = 0.94$\pm$0.08 using a CNN architecture based on 3D convolution exceeding the performance of 2D CNNs. The high segmentation accuracy provided by CNNs has the potential to help bring the use of structural MRI measurements of bone quality into clinical practice for management of osteoporosis.
Controlling Decoding for More Abstractive Summaries with Copy-Based Networks
Mar 20, 2018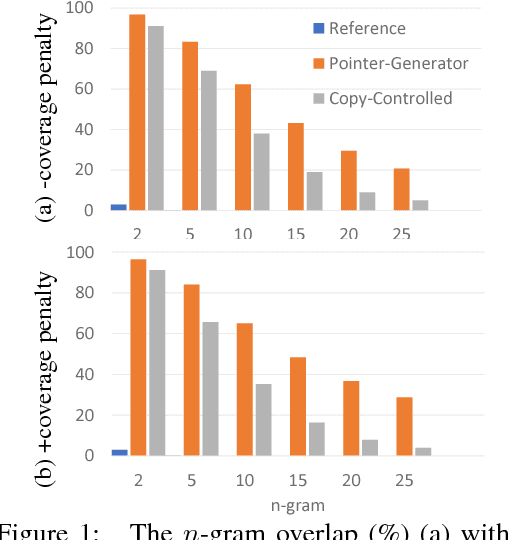
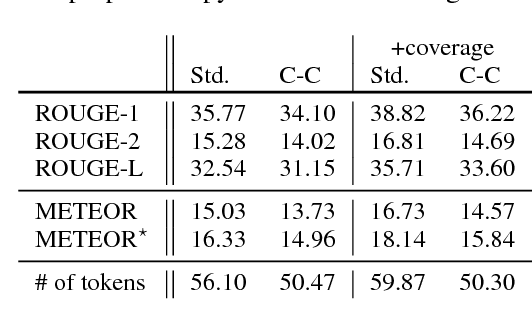
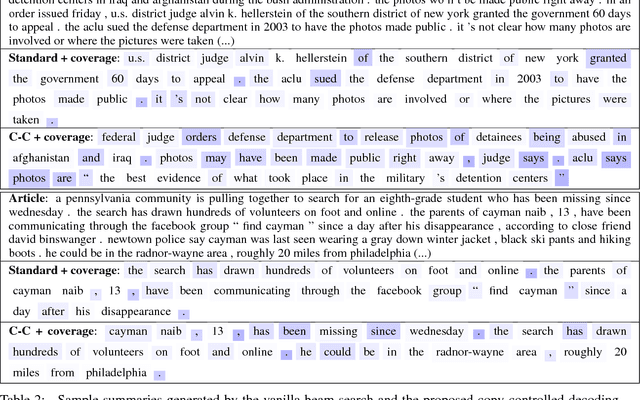
Attention-based neural abstractive summarization systems equipped with copy mechanisms have shown promising results. Despite this success, it has been noticed that such a system generates a summary by mostly, if not entirely, copying over phrases, sentences, and sometimes multiple consecutive sentences from an input paragraph, effectively performing extractive summarization. In this paper, we verify this behavior using the latest neural abstractive summarization system - a pointer-generator network. We propose a simple baseline method that allows us to control the amount of copying without retraining. Experiments indicate that the method provides a strong baseline for abstractive systems looking to obtain high ROUGE scores while minimizing overlap with the source article, substantially reducing the n-gram overlap with the original article while keeping within 2 points of the original model's ROUGE score.