 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Linguistic Phenomena in Multi-Agent Communication Games
Jan 25, 2019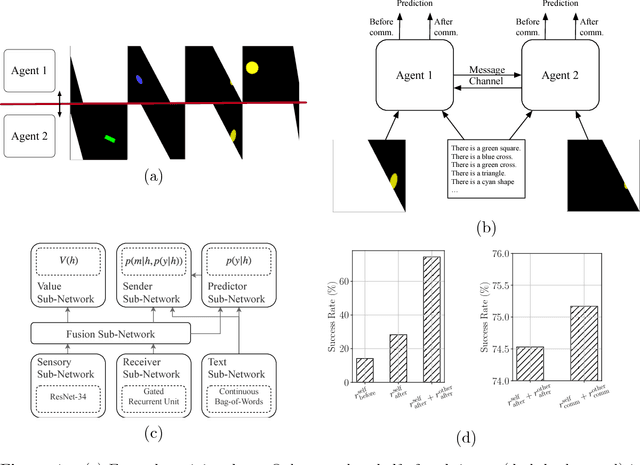
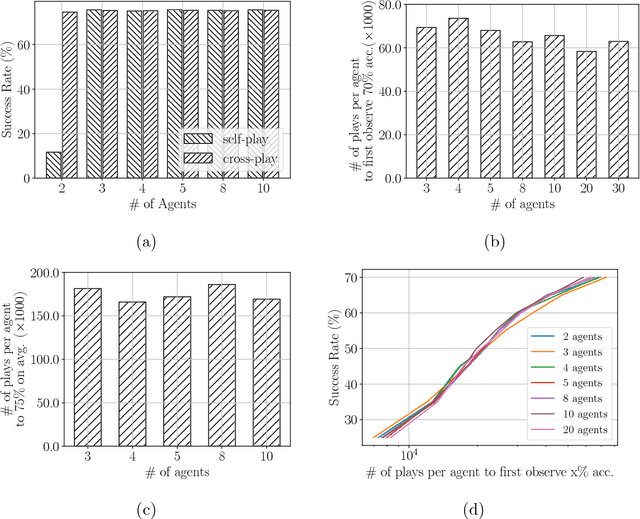
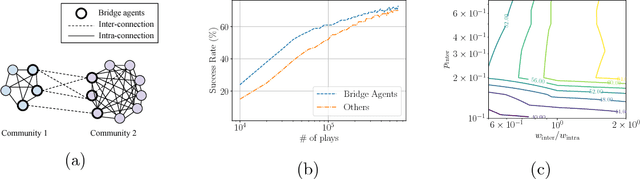
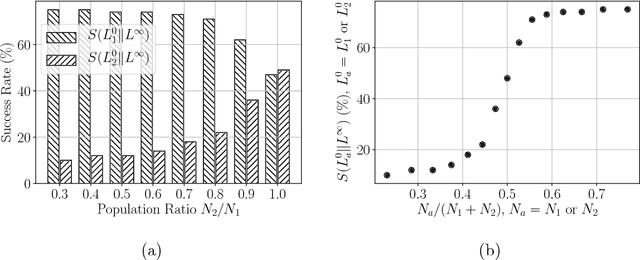
In this work, we propose a computational framework in which agents equipped with communication capabilities simultaneously play a series of referential games, where agents are trained using deep reinforcement learning. We demonstrate that the framework mirrors linguistic phenomena observed in natural language: i) the outcome of contact between communities is a function of inter- and intra-group connectivity; ii) linguistic contact either converges to the majority protocol, or in balanced cases leads to novel creole languages of lower complexity; and iii) a linguistic continuum emerges where neighboring languages are more mutually intelligible than farther removed languages. We conclude that intricate properties of language evolution need not depend on complex evolved linguistic capabilities, but can emerge from simple social exchanges between perceptually-enabled agents playing communication games.
Passage Re-ranking with BERT
Jan 15, 2019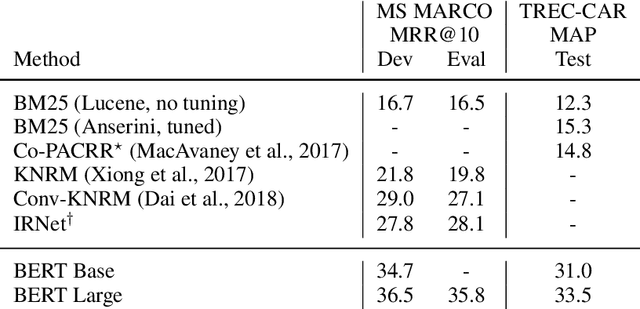
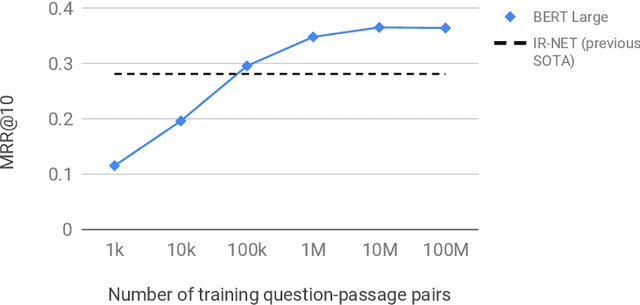
Recently, neural models pretrained on a language modeling task, such as ELMo (Peters et al., 2017), OpenAI GPT (Radford et al., 2018), and BERT (Devlin et al., 2018), have achieved impressive results on various natural language processing tasks such as question-answering and natural language inference. In this paper, we describe a simple re-implementation of BERT for query-based passage re-ranking. Our system is the state of the art on the TREC-CAR dataset and the top entry in the leaderboard of the MS MARCO passage retrieval task, outperforming the previous state of the art by 27% (relative) in MRR@10. The code to reproduce our submission is available at https://github.com/nyu-dl/dl4marco-bert
Importance of a Search Strategy in Neural Dialogue Modelling
Nov 02, 2018

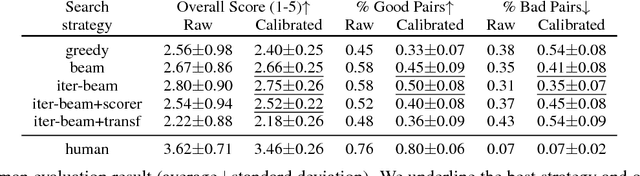
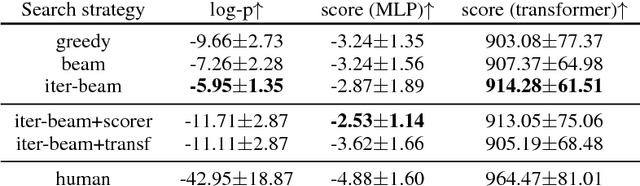
Search strategies for generating a response from a neural dialogue model have received relatively little attention compared to improving network architectures and learning algorithms in recent years. In this paper, we consider a standard neural dialogue model based on recurrent networks with an attention mechanism, and focus on evaluating the impact of the search strategy. We compare four search strategies: greedy search, beam search, iterative beam search and iterative beam search followed by selection scoring. We evaluate these strategies using human evaluation of full conversations and compare them using automatic metrics including log-probabilities, scores and diversity metrics. We observe a significant gap between greedy search and the proposed iterative beam search augmented with selection scoring, demonstrating the importance of the search algorithm in neural dialogue generation.
Dialogue Natural Language Inference
Nov 01, 2018
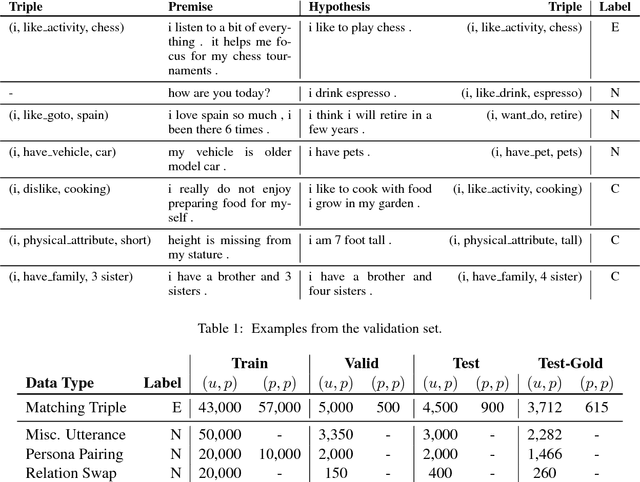
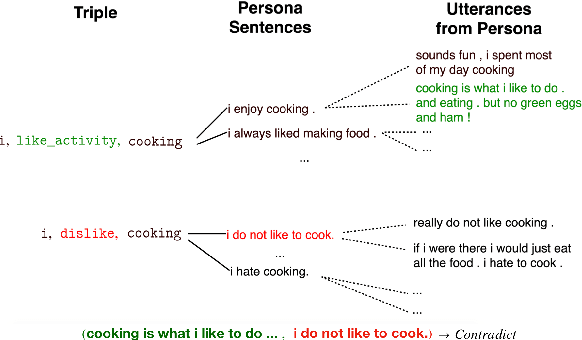
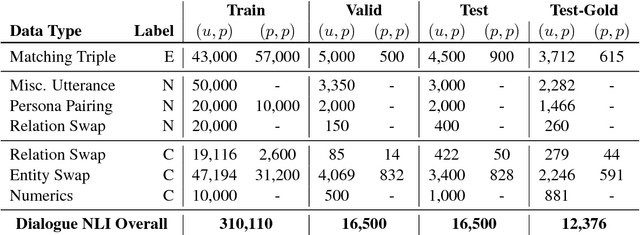
Consistency is a long standing issue faced by dialogue models. In this paper, we frame the consistency of dialogue agents as natural language inference (NLI) and create a new natural language inference dataset called Dialogue NLI. We propose a method which demonstrates that a model trained on Dialogue NLI can be used to improve the consistency of a dialogue model, and evaluate the method with human evaluation and with automatic metrics on a suite of evaluation sets designed to measure a dialogue model's consistency.
Loss Functions for Multiset Prediction
Oct 25, 2018
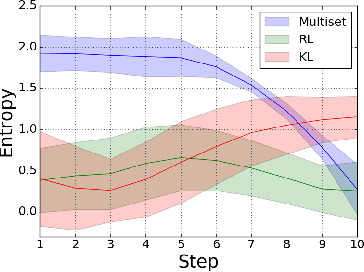
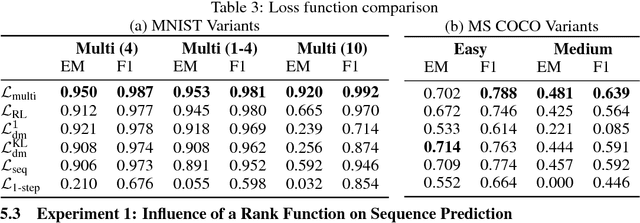
We study the problem of multiset prediction. The goal of multiset prediction is to train a predictor that maps an input to a multiset consisting of multiple items. Unlike existing problems in supervised learning, such as classification, ranking and sequence generation, there is no known order among items in a target multiset, and each item in the multiset may appear more than once, making this problem extremely challenging. In this paper, we propose a novel multiset loss function by viewing this problem from the perspective of sequential decision making. The proposed multiset loss function is empirically evaluated on two families of datasets, one synthetic and the other real, with varying levels of difficulty, against various baseline loss functions including reinforcement learning, sequence, and aggregated distribution matching loss functions. The experiments reveal the effectiveness of the proposed loss function over the others.
Classifier-agnostic saliency map extraction
Oct 02, 2018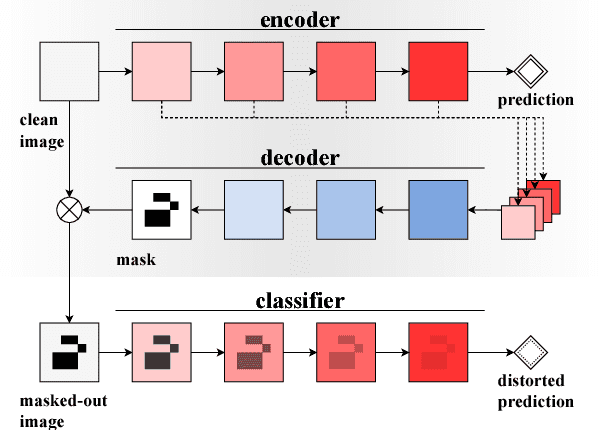
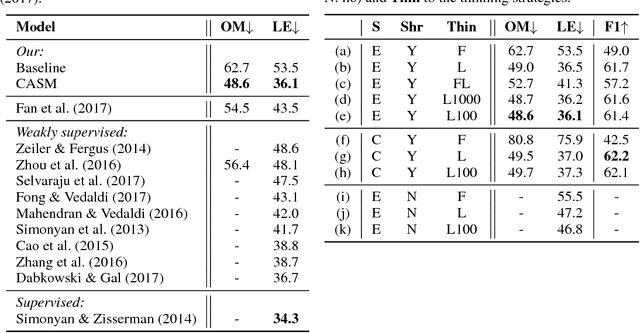

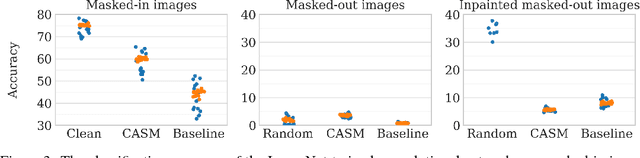
Extracting saliency maps, which indicate parts of the image important to classification, requires many tricks to achieve satisfactory performance when using classifier-dependent methods. Instead, we propose classifier-agnostic saliency map extraction, which finds all parts of the image that any classifier could use, not just one given in advance. We observe that the proposed approach extracts higher quality saliency maps and outperforms existing weakly-supervised localization techniques, setting the new state of the art result on the ImageNet dataset. We made our code publicly available at https://github.com/kondiz/casme .
Directional Analysis of Stochastic Gradient Descent via von Mises-Fisher Distributions in Deep learning
Sep 29, 2018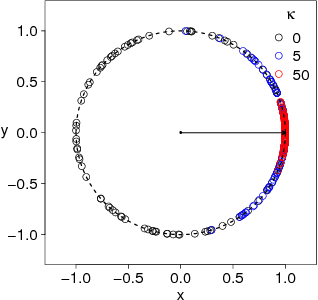

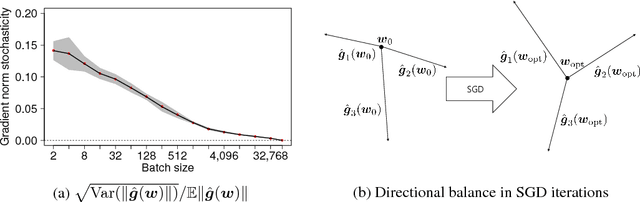
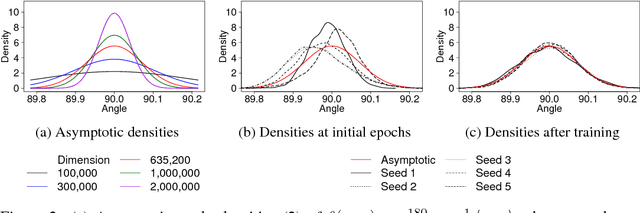
Although stochastic gradient descent (SGD) is a driving force behind the recent success of deep learning, our understanding of its dynamics in a high-dimensional parameter space is limited. In recent years, some researchers have used the stochasticity of minibatch gradients, or the signal-to-noise ratio, to better characterize the learning dynamics of SGD. Inspired from these work, we here analyze SGD from a geometrical perspective by inspecting the stochasticity of the norms and directions of minibatch gradients. We propose a model of the directional concentration for minibatch gradients through von Mises-Fisher (VMF) distribution, and show that the directional uniformity of minibatch gradients increases over the course of SGD. We empirically verify our result using deep convolutional networks and observe a higher correlation between the gradient stochasticity and the proposed directional uniformity than that against the gradient norm stochasticity, suggesting that the directional statistics of minibatch gradients is a major factor behind SGD.
Backplay: "Man muss immer umkehren"
Sep 28, 2018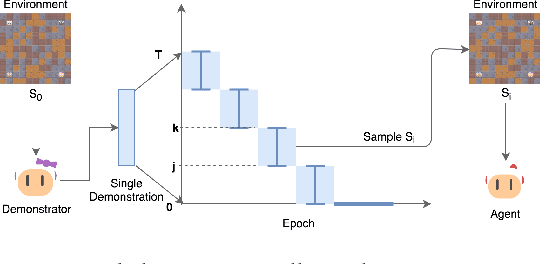
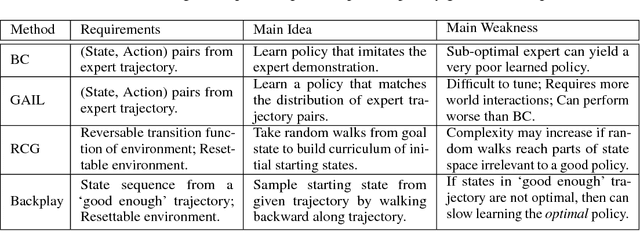
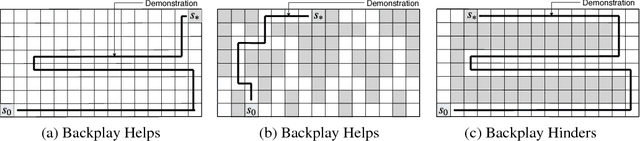
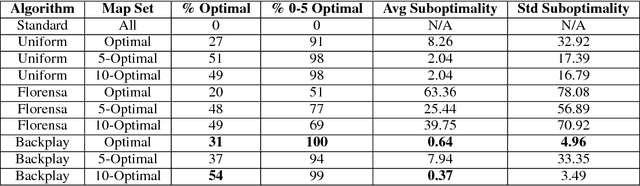
A long-standing problem in model-free reinforcement learning (RL) is that it requires a large number of trials to learn a good policy, especially in environments with sparse rewards. We explore a method to increase the sample efficiency of RL when we have access to demonstrations. Our approach, Backplay, uses a single demonstration to construct a curriculum for a given task. Rather than starting each training episode in the environment's fixed initial state, we start the agent near the end of the demonstration and move the starting point backwards during the course of training until we reach the initial state. We perform experiments in a competitive four-player game (Pommerman) and a path-finding maze game. We find that Backplay provides significant gains in sample complexity with a stark advantage in sparse reward settings. In some cases, it reached success rates greater than 50 and generalized to unseen initial conditions, while standard RL did not yield any improvement.
Jump to better conclusions: SCAN both left and right
Sep 12, 2018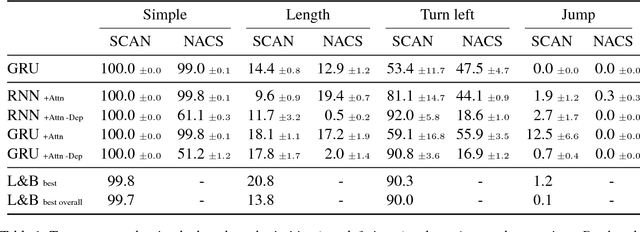
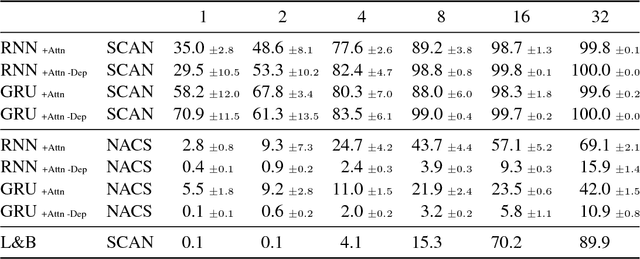

Lake and Baroni (2018) recently introduced the SCAN data set, which consists of simple commands paired with action sequences and is intended to test the strong generalization abilities of recurrent sequence-to-sequence models. Their initial experiments suggested that such models may fail because they lack the ability to extract systematic rules. Here, we take a closer look at SCAN and show that it does not always capture the kind of generalization that it was designed for. To mitigate this we propose a complementary dataset, which requires mapping actions back to the original commands, called NACS. We show that models that do well on SCAN do not necessarily do well on NACS, and that NACS exhibits properties more closely aligned with realistic use-cases for sequence-to-sequence models.
Dynamic Meta-Embeddings for Improved Sentence Representations
Sep 05, 2018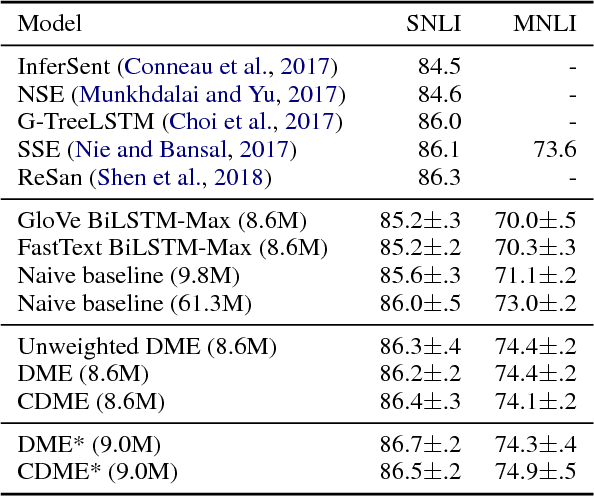

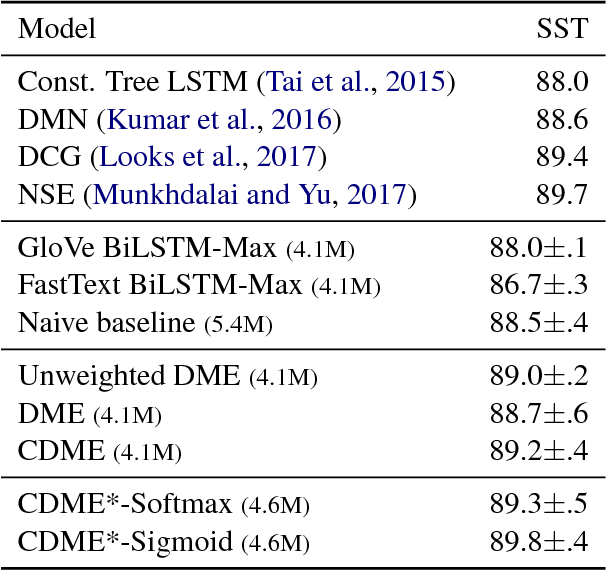
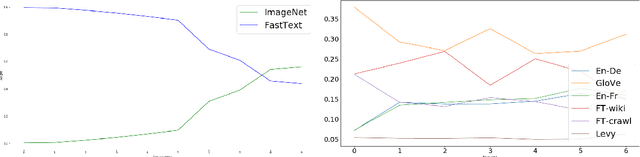
While one of the first steps in many NLP systems is selecting what pre-trained word embeddings to use, we argue that such a step is better left for neural networks to figure out by themselves. To that end, we introduce dynamic meta-embeddings, a simple yet effective method for the supervised learning of embedding ensembles, which leads to state-of-the-art performance within the same model class on a variety of tasks. We subsequently show how the technique can be used to shed new light on the usage of word embeddings in NLP systems.