 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing GraphSAGE with A Data-Driven Node Sampling
Apr 29, 2019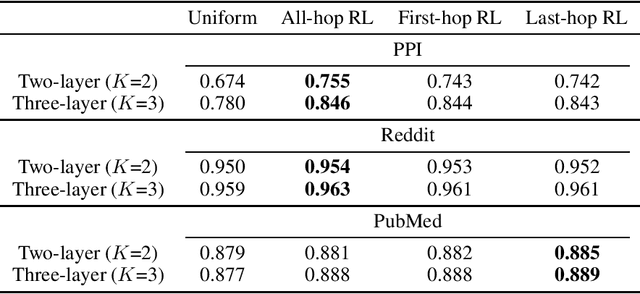
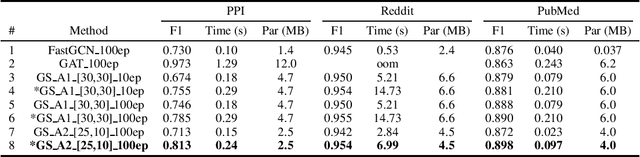
As an efficient and scalable graph neural network, GraphSAGE has enabled an inductive capability for inferring unseen nodes or graphs by aggregating subsampled local neighborhoods and by learning in a mini-batch gradient descent fashion. The neighborhood sampling used in GraphSAGE is effective in order to improve computing and memory efficiency when inferring a batch of target nodes with diverse degrees in parallel. Despite this advantage, the default uniform sampling suffers from high variance in training and inference, leading to sub-optimum accuracy. We propose a new data-driven sampling approach to reason about the real-valued importance of a neighborhood by a non-linear regressor, and to use the value as a criterion for subsampling neighborhoods. The regressor is learned using a value-based reinforcement learning. The implied importance for each combination of vertex and neighborhood is inductively extracted from the negative classification loss output of GraphSAGE. As a result, in an inductive node classification benchmark using three datasets, our method enhanced the baseline using the uniform sampling, outperforming recent variants of a graph neural network in accuracy.
Document Expansion by Query Prediction
Apr 17, 2019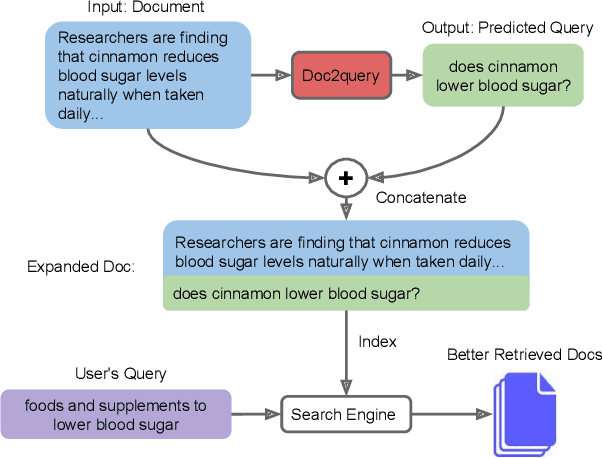
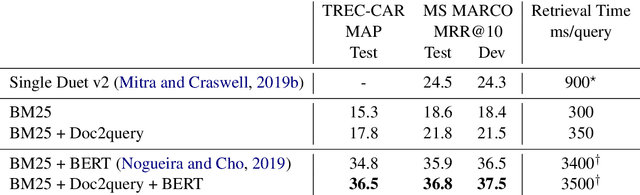

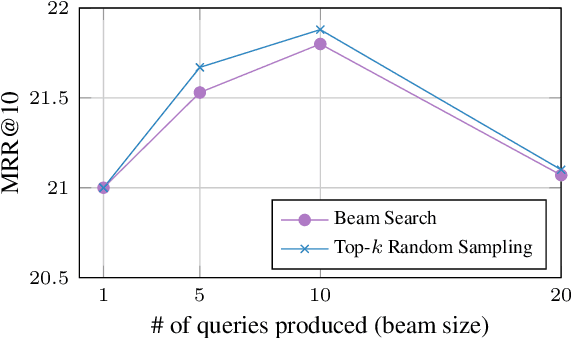
One technique to improve the retrieval effectiveness of a search engine is to expand documents with terms that are related or representative of the documents' content. From the perspective of a question answering system, a useful representation of a document might comprise the questions it can potentially answer. Following this observation, we propose a simple method that predicts which queries will be issued for a given document and then expands it with those predictions. Our predictions are made with a vanilla sequence-to-sequence model trained with supervised learning using a dataset of pairs of query and relevant documents. By combining our method with a highly-effective re-ranking component, we achieve the state of the art in two retrieval tasks. In a latency-critical regime, retrieval results alone (without the re-ranking component) approach the effectiveness of more computationally expensive neural re-rankers while taking only a fraction of the query latency.
BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
Apr 09, 2019
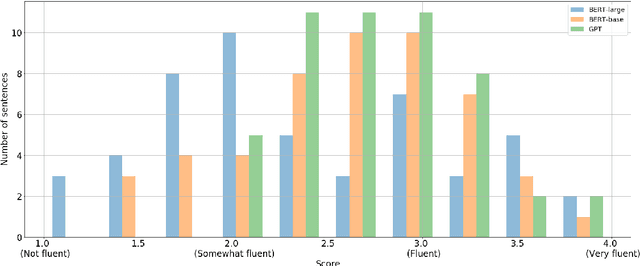
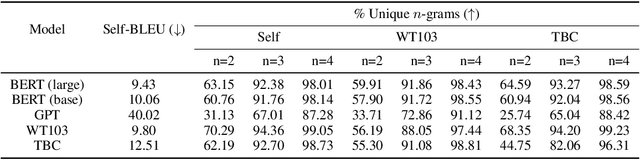
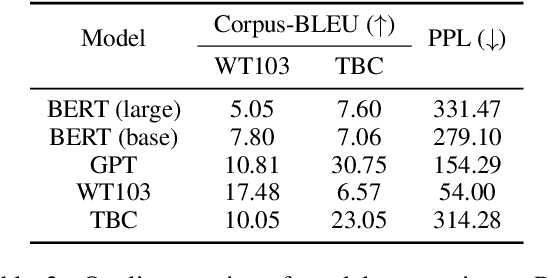
We show that BERT (Devlin et al., 2018) is a Markov random field language model. This formulation gives way to a natural procedure to sample sentences from BERT. We generate from BERT and find that it can produce high-quality, fluent generations. Compared to the generations of a traditional left-to-right language model, BERT generates sentences that are more diverse but of slightly worse quality.
Molecular geometry prediction using a deep generative graph neural network
Mar 31, 2019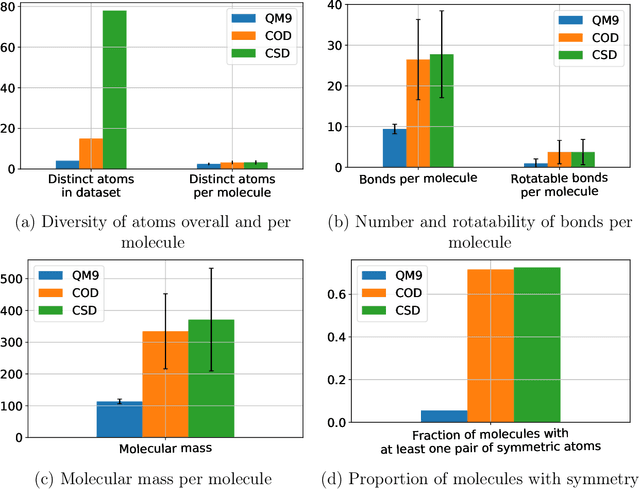
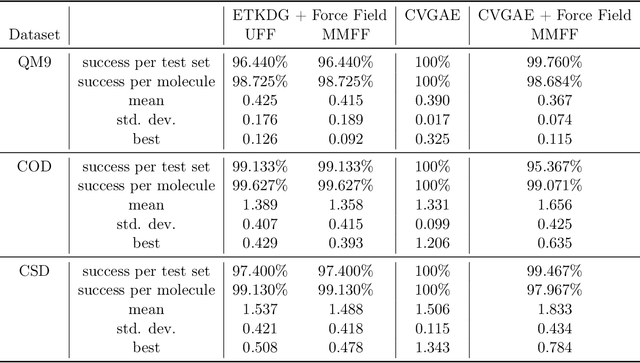
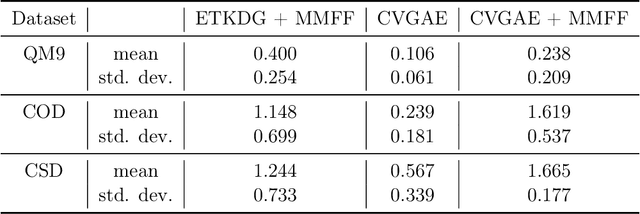
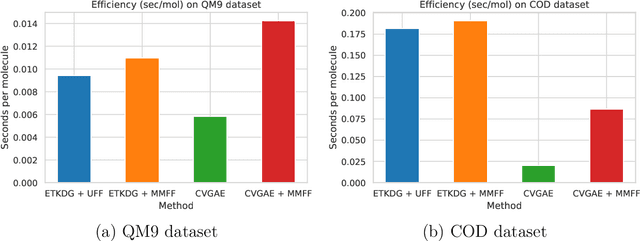
A molecule's geometry, also known as conformation, is one of a molecule's most important properties, determining the reactions it participates in, the bonds it forms, and the interactions it has with other molecules. Conventional conformation generation methods minimize hand-designed molecular force field energy functions that are not well correlated with the true energy function of a molecule observed in nature. They generate geometrically diverse sets of conformations, some of which are very similar to the ground-truth conformations and others of which are very different. In this paper we propose a conditional deep generative graph neural network that learns an energy function from data by directly learning to generate molecular conformations given a molecular graph. On three large scale small molecule datasets, we show that our method generates a set of conformations that on average is far more likely to be close to the corresponding reference conformations than are those obtained from conventional force field methods. Our method maintains geometrical diversity by generating conformations that are not too similar to each other, and is also computationally faster. We also show that our method can be used to provide initial coordinates for conventional force field methods. On one of the evaluated datasets we show that this combination allows us to combine the best of both methods, yielding generated conformations that are on average close to ground-truth conformations with some very similar to ground-truth conformations.
Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening
Mar 20, 2019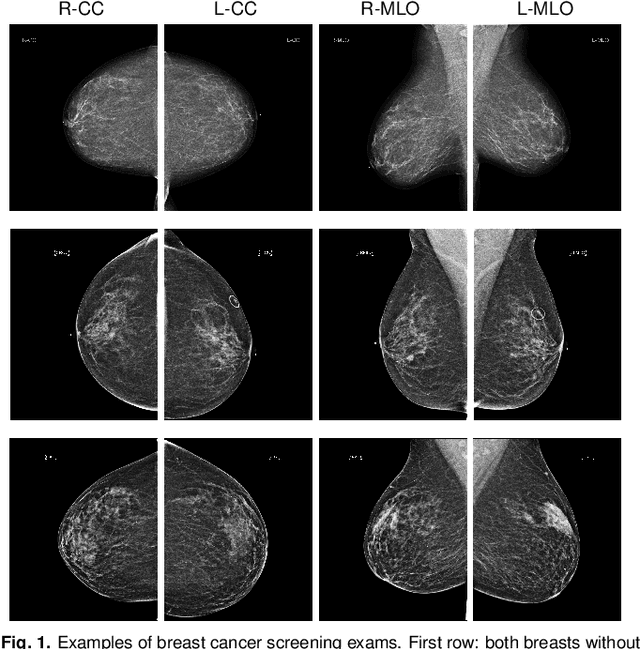
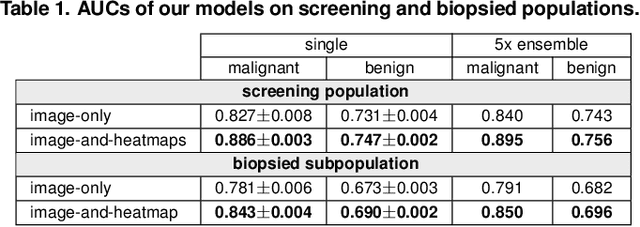
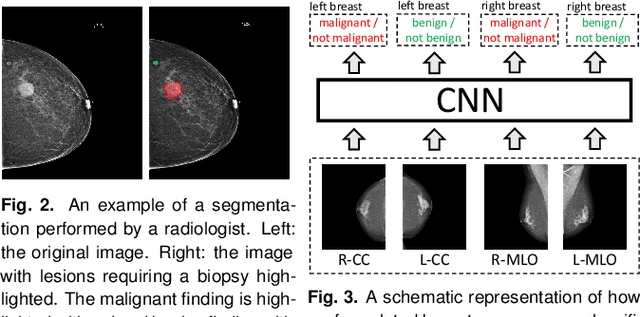
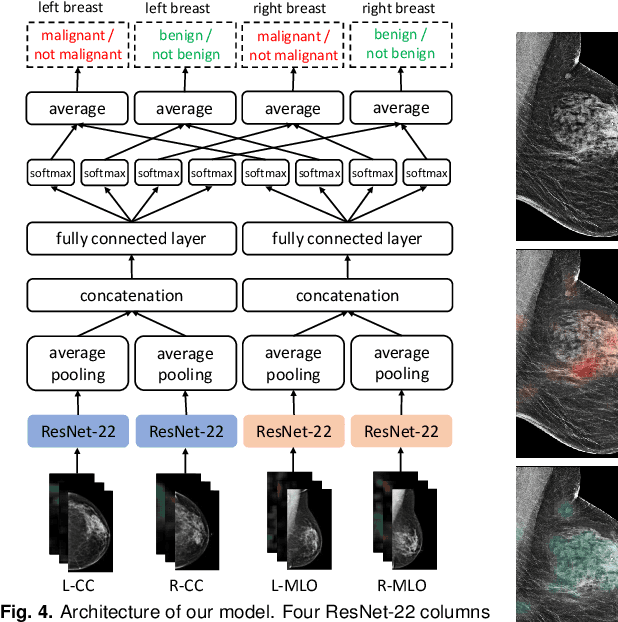
We present a deep convolutional neural network for breast cancer screening exam classification, trained and evaluated on over 200,000 exams (over 1,000,000 images). Our network achieves an AUC of 0.895 in predicting whether there is a cancer in the breast, when tested on the screening population. We attribute the high accuracy of our model to a two-stage training procedure, which allows us to use a very high-capacity patch-level network to learn from pixel-level labels alongside a network learning from macroscopic breast-level labels. To validate our model, we conducted a reader study with 14 readers, each reading 720 screening mammogram exams, and find our model to be as accurate as experienced radiologists when presented with the same data. Finally, we show that a hybrid model, averaging probability of malignancy predicted by a radiologist with a prediction of our neural network, is more accurate than either of the two separately. To better understand our results, we conduct a thorough analysis of our network's performance on different subpopulations of the screening population, model design, training procedure, errors, and properties of its internal representations.
Context-Aware Learning for Neural Machine Translation
Mar 12, 2019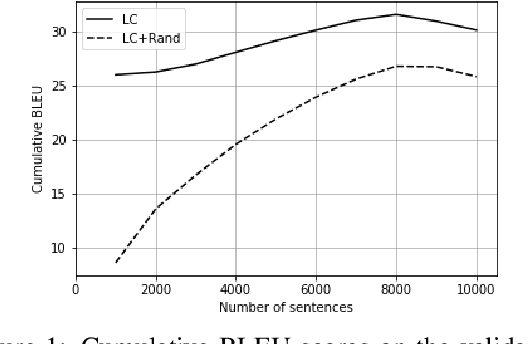
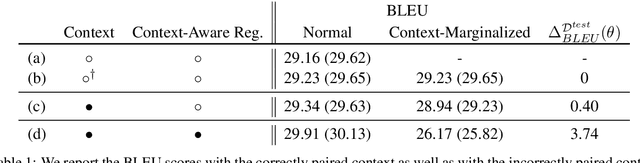
Interest in larger-context neural machine translation, including document-level and multi-modal translation, has been growing. Multiple works have proposed new network architectures or evaluation schemes, but potentially helpful context is still sometimes ignored by larger-context translation models. In this paper, we propose a novel learning algorithm that explicitly encourages a neural translation model to take into account additional context using a multilevel pair-wise ranking loss. We evaluate the proposed learning algorithm with a transformer-based larger-context translation system on document-level translation. By comparing performance using actual and random contexts, we show that a model trained with the proposed algorithm is more sensitive to the additional context.
Continual Learning via Neural Pruning
Mar 11, 2019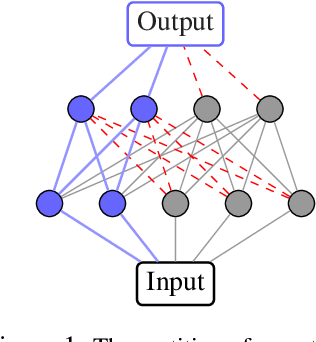
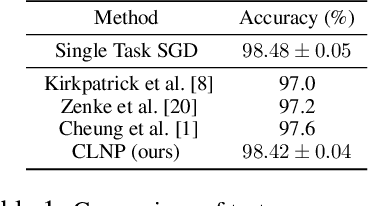
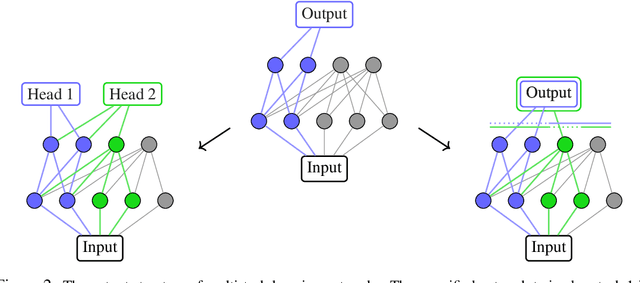
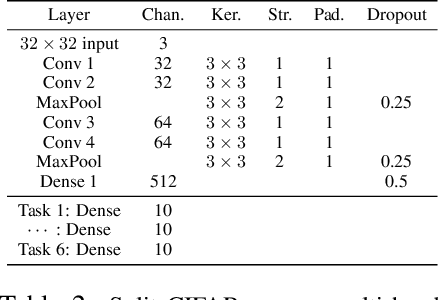
We introduce Continual Learning via Neural Pruning (CLNP), a new method aimed at lifelong learning in fixed capacity models based on neuronal model sparsification. In this method, subsequent tasks are trained using the inactive neurons and filters of the sparsified network and cause zero deterioration to the performance of previous tasks. In order to deal with the possible compromise between model sparsity and performance, we formalize and incorporate the concept of graceful forgetting: the idea that it is preferable to suffer a small amount of forgetting in a controlled manner if it helps regain network capacity and prevents uncontrolled loss of performance during the training of future tasks. CLNP also provides simple continual learning diagnostic tools in terms of the number of free neurons left for the training of future tasks as well as the number of neurons that are being reused. In particular, we see in experiments that CLNP verifies and automatically takes advantage of the fact that the features of earlier layers are more transferable. We show empirically that CLNP leads to significantly improved results over current weight elasticity based methods.
Insertion-based Decoding with automatically Inferred Generation Order
Feb 28, 2019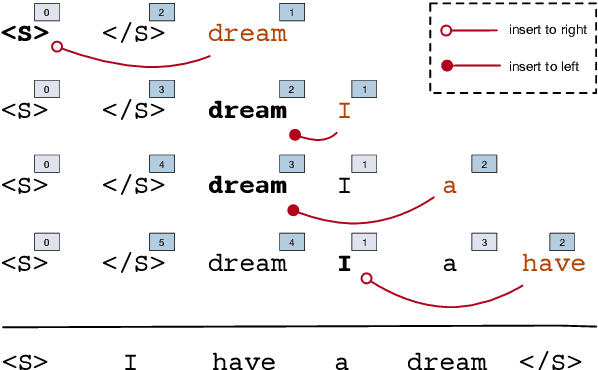

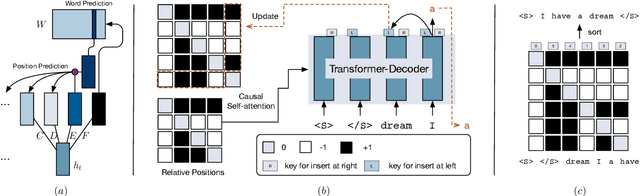
Conventional neural autoregressive decoding commonly assumes a fixed left-to-right generation order, which may be sub-optimal. In this work, we propose a novel decoding algorithm -- InDIGO -- which supports flexible sequence generation in arbitrary orders through insertion operations. We extend Transformer, a state-of-the-art sequence generation model, to efficiently implement the proposed approach, enabling it to be trained with either a pre-defined generation order or adaptive orders obtained from beam-search. Experiments on four real-world tasks, including word order recovery, machine translation, image caption and code generation, demonstrate that our algorithm can generate sequences following arbitrary orders, while achieving competitive or even better performance compared to the conventional left-to-right generation. The generated sequences show that InDIGO adopts adaptive generation orders based on input information.
Augmentation for small object detection
Feb 19, 2019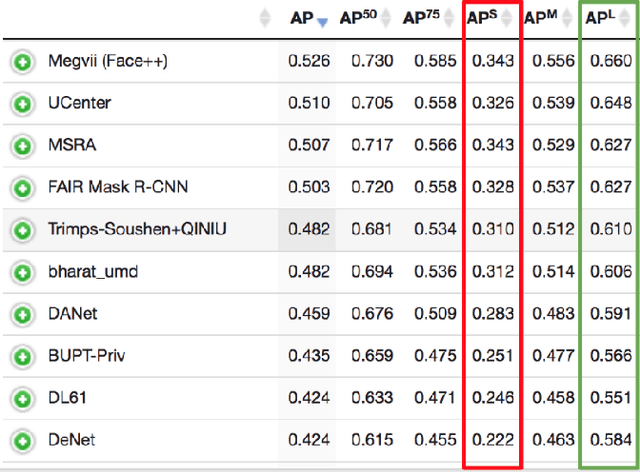
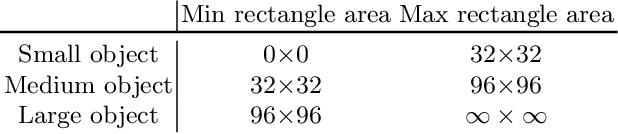

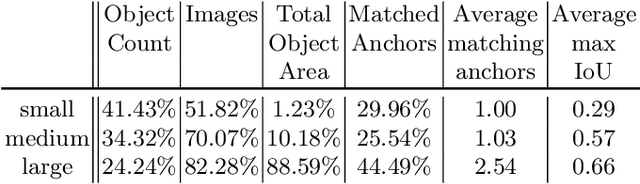
In recent years, object detection has experienced impressive progress. Despite these improvements, there is still a significant gap in the performance between the detection of small and large objects. We analyze the current state-of-the-art model, Mask-RCNN, on a challenging dataset, MS COCO. We show that the overlap between small ground-truth objects and the predicted anchors is much lower than the expected IoU threshold. We conjecture this is due to two factors; (1) only a few images are containing small objects, and (2) small objects do not appear enough even within each image containing them. We thus propose to oversample those images with small objects and augment each of those images by copy-pasting small objects many times. It allows us to trade off the quality of the detector on large objects with that on small objects. We evaluate different pasting augmentation strategies, and ultimately, we achieve 9.7\% relative improvement on the instance segmentation and 7.1\% on the object detection of small objects, compared to the current state of the art method on MS COCO.
Non-Monotonic Sequential Text Generation
Feb 05, 2019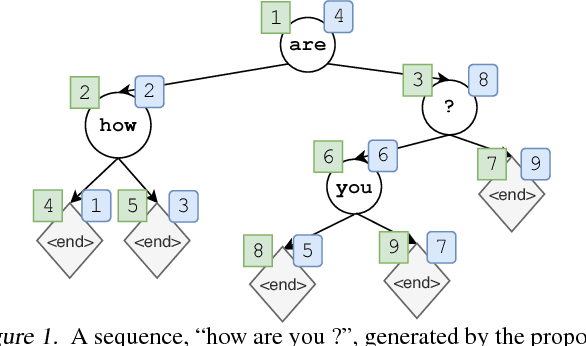
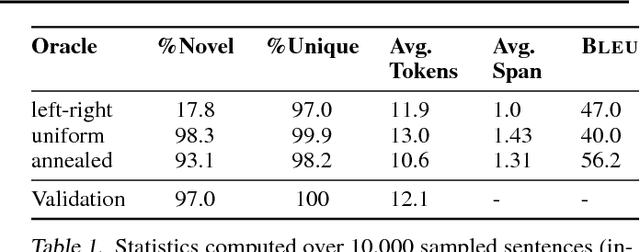
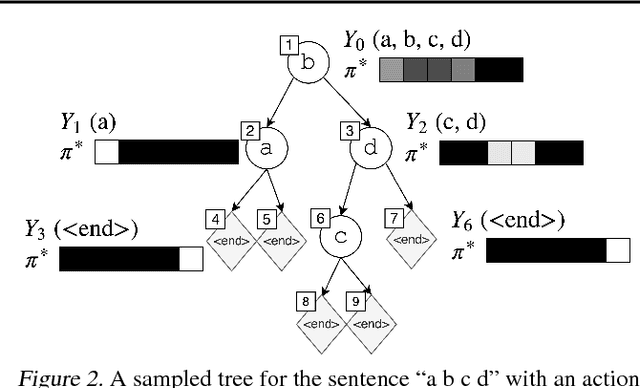

Standard sequential generation methods assume a pre-specified generation order, such as text generation methods which generate words from left to right. In this work, we propose a framework for training models of text generation that operate in non-monotonic orders; the model directly learns good orders, without any additional annotation. Our framework operates by generating a word at an arbitrary position, and then recursively generating words to its left and then words to its right, yielding a binary tree. Learning is framed as imitation learning, including a coaching method which moves from imitating an oracle to reinforcing the policy's own preferences. Experimental results demonstrate that using the proposed method, it is possible to learn policies which generate text without pre-specifying a generation order, while achieving competitive performance with conventional left-to-right generation.