 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRWarp: Generalized Image Super-Resolution under Arbitrary Transformation
Apr 21, 2021
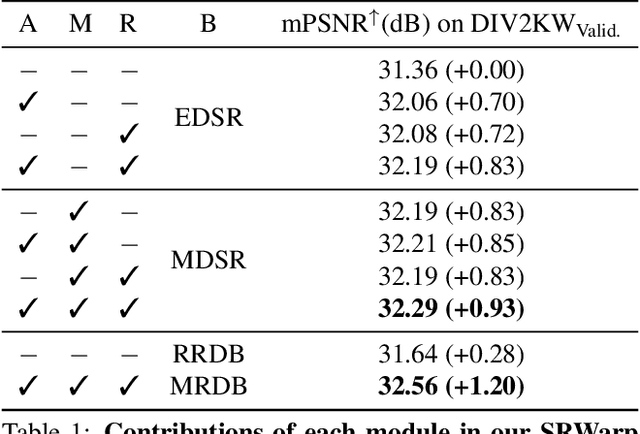

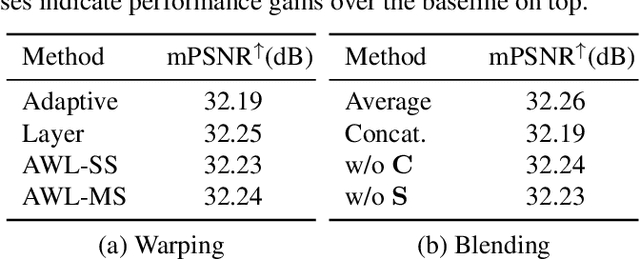
Deep CNNs have achieved significant successes in image processing and its applications, including single image super-resolution (SR). However, conventional methods still resort to some predetermined integer scaling factors, e.g., x2 or x4. Thus, they are difficult to be applied when arbitrary target resolutions are required. Recent approaches extend the scope to real-valued upsampling factors, even with varying aspect ratios to handle the limitation. In this paper, we propose the SRWarp framework to further generalize the SR tasks toward an arbitrary image transformation. We interpret the traditional image warping task, specifically when the input is enlarged, as a spatially-varying SR problem. We also propose several novel formulations, including the adaptive warping layer and multiscale blending, to reconstruct visually favorable results in the transformation process. Compared with previous methods, we do not constrain the SR model on a regular grid but allow numerous possible deformations for flexible and diverse image editing. Extensive experiments and ablation studies justify the necessity and demonstrate the advantage of the proposed SRWarp method under various transformations.
3DCrowdNet: 2D Human Pose-Guided3D Crowd Human Pose and Shape Estimation in the Wild
Apr 15, 2021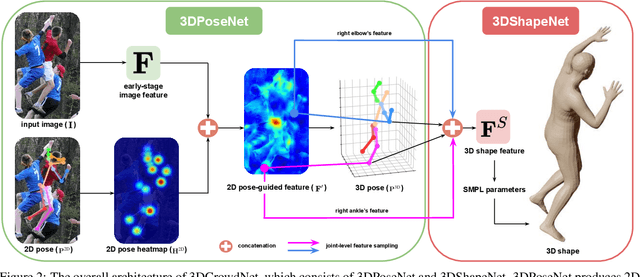

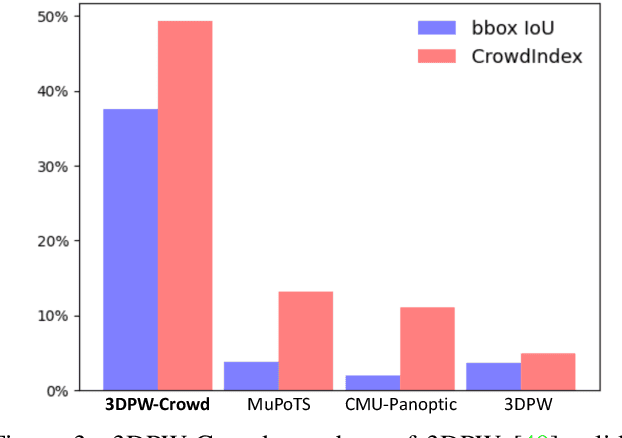
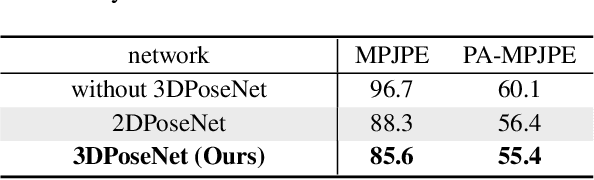
Recovering accurate 3D human pose and shape from in-the-wild crowd scenes is highly challenging and barely studied, despite their common presence. In this regard, we present 3DCrowdNet, a 2D human pose-guided 3D crowd pose and shape estimation system for in-the-wild scenes. 2D human pose estimation methods provide relatively robust outputs on crowd scenes than 3D human pose estimation methods, as they can exploit in-the-wild multi-person 2D datasets that include crowd scenes. On the other hand, the 3D methods leverage 3D datasets, of which images mostly contain a single actor without a crowd. The train data difference impedes the 3D methods' ability to focus on a target person in in-the-wild crowd scenes. Thus, we design our system to leverage the robust 2D pose outputs from off-the-shelf 2D pose estimators, which guide a network to focus on a target person and provide essential human articulation information. We show that our 3DCrowdNet outperforms previous methods on in-the-wild crowd scenes. We will release the codes.
DAQ: Distribution-Aware Quantization for Deep Image Super-Resolution Networks
Dec 21, 2020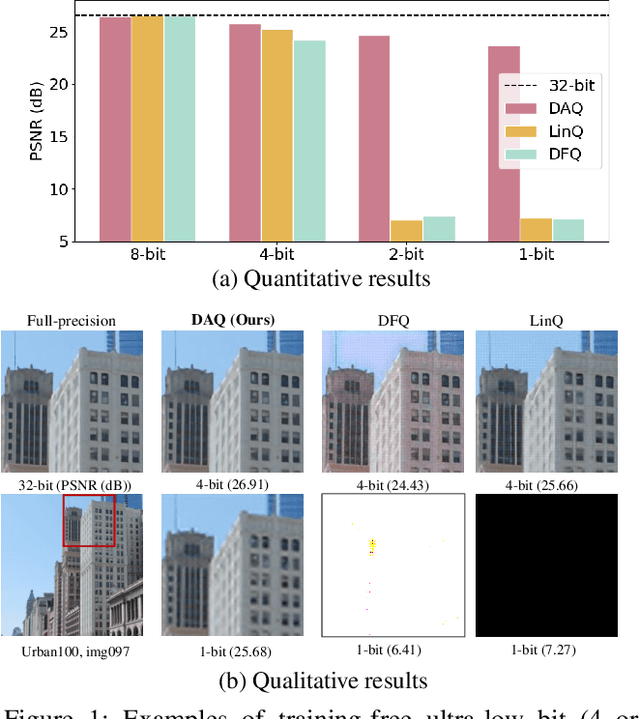

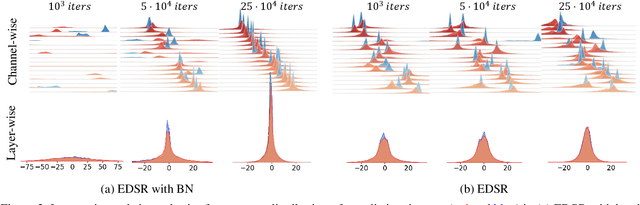
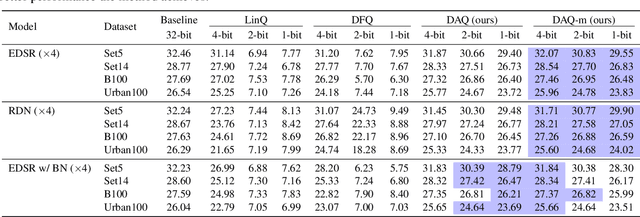
Quantizing deep convolutional neural networks for image super-resolution substantially reduces their computational costs. However, existing works either suffer from a severe performance drop in ultra-low precision of 4 or lower bit-widths, or require a heavy fine-tuning process to recover the performance. To our knowledge, this vulnerability to low precisions relies on two statistical observations of feature map values. First, distribution of feature map values varies significantly per channel and per input image. Second, feature maps have outliers that can dominate the quantization error. Based on these observations, we propose a novel distribution-aware quantization scheme (DAQ) which facilitates accurate training-free quantization in ultra-low precision. A simple function of DAQ determines dynamic range of feature maps and weights with low computational burden. Furthermore, our method enables mixed-precision quantization by calculating the relative sensitivity of each channel, without any training process involved. Nonetheless, quantization-aware training is also applicable for auxiliary performance gain. Our new method outperforms recent training-free and even training-based quantization methods to the state-of-the-art image super-resolution networks in ultra-low precision.
Searching for Controllable Image Restoration Networks
Dec 21, 2020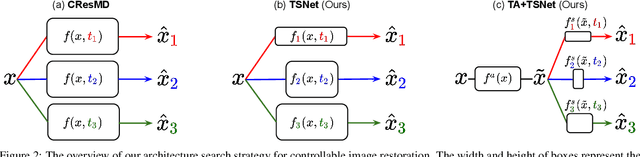
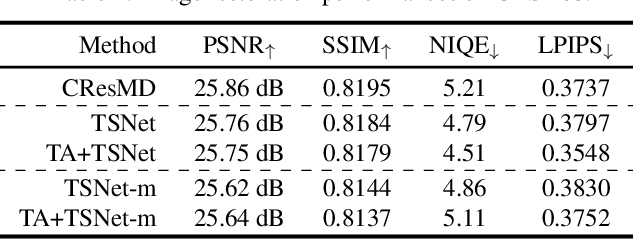
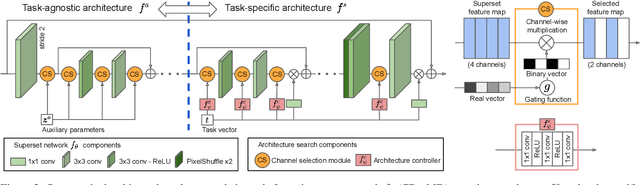
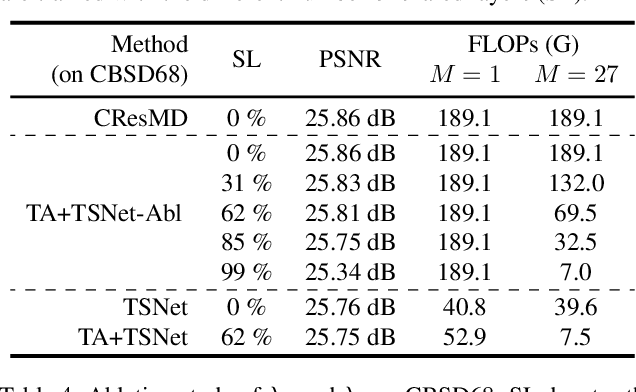
Diverse user preferences over images have recently led to a great amount of interest in controlling the imagery effects for image restoration tasks. However, existing methods require separate inference through the entire network per each output, which hinders users from readily comparing multiple imagery effects due to long latency. To this end, we propose a novel framework based on a neural architecture search technique that enables efficient generation of multiple imagery effects via two stages of pruning: task-agnostic and task-specific pruning. Specifically, task-specific pruning learns to adaptively remove the irrelevant network parameters for each task, while task-agnostic pruning learns to find an efficient architecture by sharing the early layers of the network across different tasks. Since the shared layers allow for feature reuse, only a single inference of the task-agnostic layers is needed to generate multiple imagery effects from the input image. Using the proposed task-agnostic and task-specific pruning schemes together significantly reduces the FLOPs and the actual latency of inference compared to the baseline. We reduce 95.7% of the FLOPs when generating 27 imagery effects, and make the GPU latency 73.0% faster on 4K-resolution images.
NeuralAnnot: Neural Annotator for in-the-wild Expressive 3D Human Pose and Mesh Training Sets
Nov 28, 2020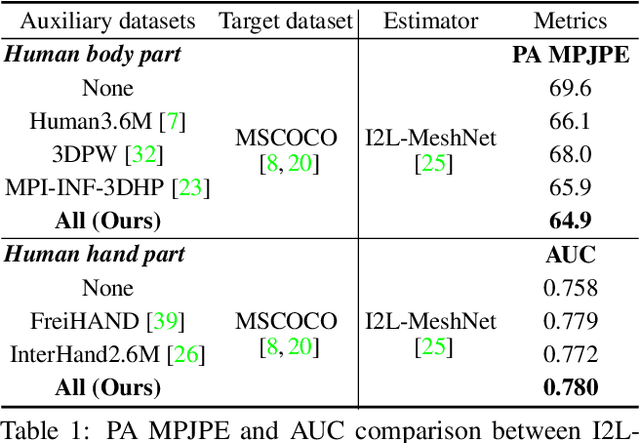
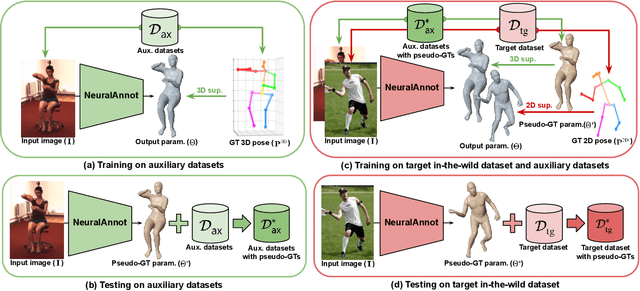

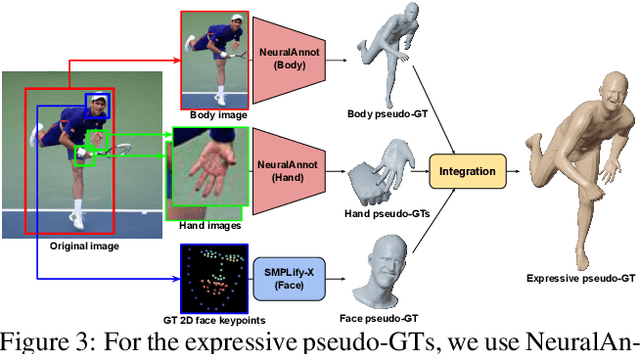
Recovering expressive 3D human pose and mesh from in-the-wild images is greatly challenging due to the absence of the training data. Several optimization-based methods have been used to obtain pseudo-groundtruth (GT) 3D poses and meshes from GT 2D poses. However, they often produce bad ones with long running time because their frameworks are optimized on each sample only using 2D supervisions in a sequential way. To overcome the limitations, we present NeuralAnnot, a neural annotator that learns to construct in-the-wild expressive 3D human pose and mesh training sets. Our NeuralAnnot is trained on a large number of samples by 2D supervisions from a target in-the-wild dataset and 3D supervisions from auxiliary datasets with GT 3D poses in a parallel way. We show that our NeuralAnnot produces far better 3D pseudo-GTs with much shorter running time than the optimization-based methods, and the newly obtained training set brings great performance gain. The newly obtained training sets and codes will be publicly available.
Pose2Pose: 3D Positional Pose-Guided 3D Rotational Pose Prediction for Expressive 3D Human Pose and Mesh Estimation
Nov 28, 2020
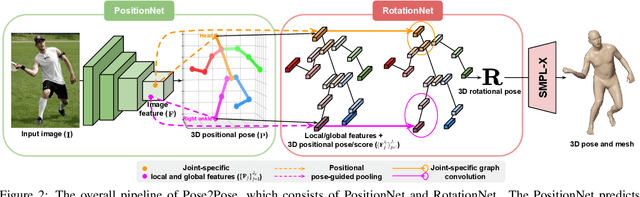

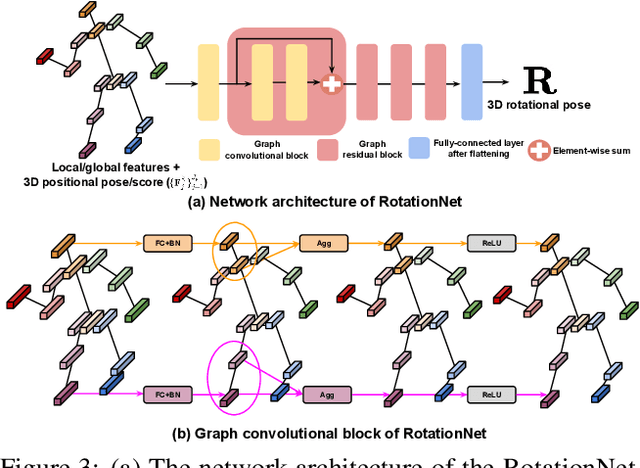
Previous 3D human pose and mesh estimation methods mostly rely on only global image feature to predict 3D rotations of human joints (i.e., 3D rotational pose) from an input image. However, local features on the position of human joints (i.e., positional pose) can provide joint-specific information, which is essential to understand human articulation. To effectively utilize both local and global features, we present Pose2Pose, a 3D positional pose-guided 3D rotational pose prediction network, along with a positional pose-guided pooling and joint-specific graph convolution. The positional pose-guided pooling extracts useful joint-specific local and global features. Also, the joint-specific graph convolution effectively processes the joint-specific features by learning joint-specific characteristics and different relationships between different joints. We use Pose2Pose for expressive 3D human pose and mesh estimation and show that it outperforms all previous part-specific and expressive methods by a large margin. The codes will be publicly available.
Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video
Nov 26, 2020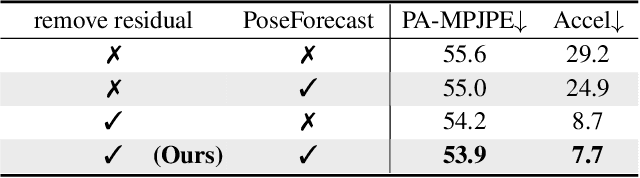
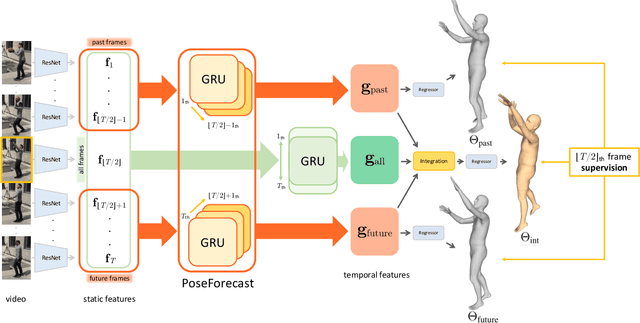

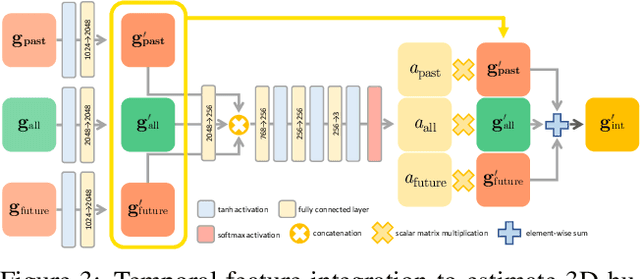
Despite the recent success of single image-based 3D human pose and shape estimation methods, recovering temporally consistent and smooth 3D human motion from a video is still challenging. Several video-based methods have been proposed; however, they fail to resolve the single image-based methods' temporal inconsistency issue due to a strong dependency on a static feature of the current frame. In this regard, we present a temporally consistent mesh recovery system (TCMR). It effectively focuses on the past and future frames' temporal information without being dominated by the current static feature. Our TCMR significantly outperforms previous video-based methods in temporal consistency with better per-frame 3D pose and shape accuracy. We will release the codes. Demo video: https://www.youtube.com/watch?v=WB3nTnSQDII&t=7s&ab_channel=%EC%B5%9C%ED%99%8D%EC%84%9D
DynaVSR: Dynamic Adaptive Blind Video Super-Resolution
Nov 09, 2020
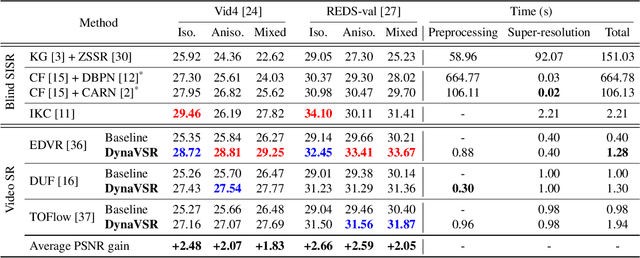
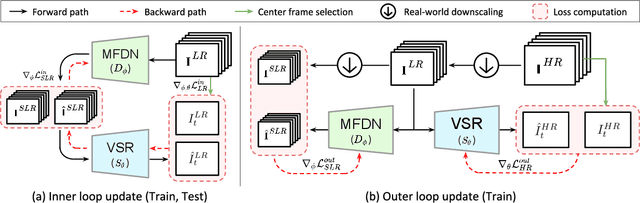
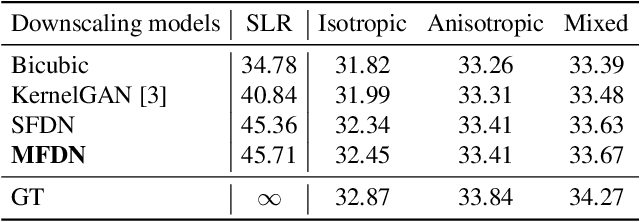
Most conventional supervised super-resolution (SR) algorithms assume that low-resolution (LR) data is obtained by downscaling high-resolution (HR) data with a fixed known kernel, but such an assumption often does not hold in real scenarios. Some recent blind SR algorithms have been proposed to estimate different downscaling kernels for each input LR image. However, they suffer from heavy computational overhead, making them infeasible for direct application to videos. In this work, we present DynaVSR, a novel meta-learning-based framework for real-world video SR that enables efficient downscaling model estimation and adaptation to the current input. Specifically, we train a multi-frame downscaling module with various types of synthetic blur kernels, which is seamlessly combined with a video SR network for input-aware adaptation. Experimental results show that DynaVSR consistently improves the performance of the state-of-the-art video SR models by a large margin, with an order of magnitude faster inference time compared to the existing blind SR approaches.
Meta-Learning with Adaptive Hyperparameters
Oct 31, 2020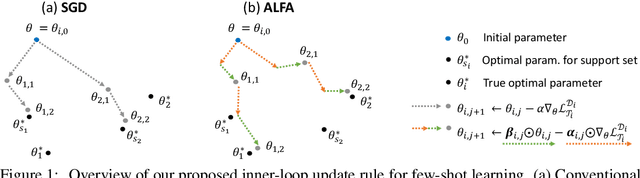
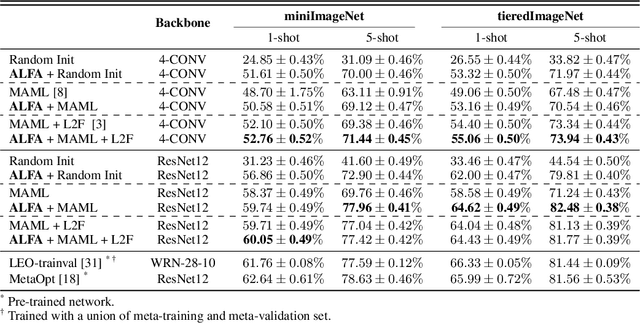
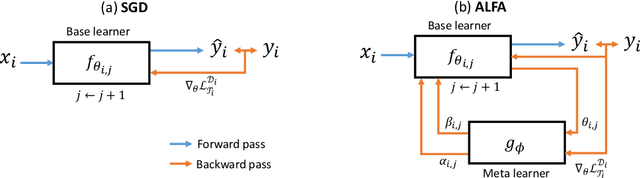
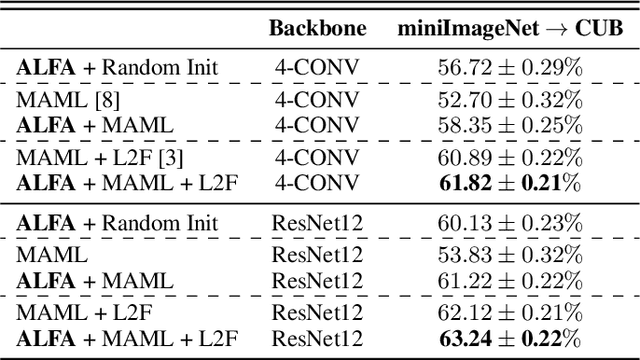
Despite its popularity, several recent works question the effectiveness of MAML when test tasks are different from training tasks, thus suggesting various task-conditioned methodology to improve the initialization. Instead of searching for better task-aware initialization, we focus on a complementary factor in MAML framework, inner-loop optimization (or fast adaptation). Consequently, we propose a new weight update rule that greatly enhances the fast adaptation process. Specifically, we introduce a small meta-network that can adaptively generate per-step hyperparameters: learning rate and weight decay coefficients. The experimental results validate that the Adaptive Learning of hyperparameters for Fast Adaptation (ALFA) is the equally important ingredient that was often neglected in the recent few-shot learning approaches. Surprisingly, fast adaptation from random initialization with ALFA can already outperform MAML.
AIM 2020 Challenge on Video Temporal Super-Resolution
Sep 28, 2020
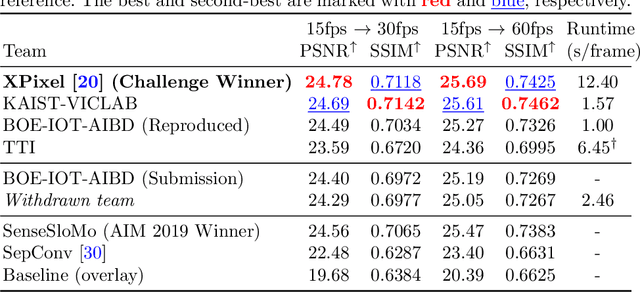

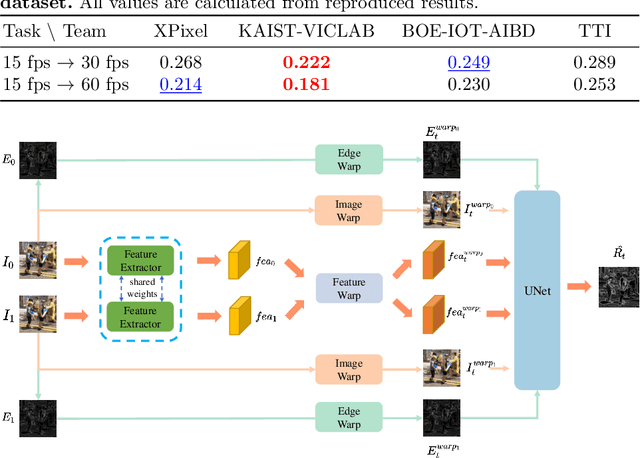
Videos in the real-world contain various dynamics and motions that may look unnaturally discontinuous in time when the recordedframe rate is low. This paper reports the second AIM challenge on Video Temporal Super-Resolution (VTSR), a.k.a. frame interpolation, with a focus on the proposed solutions, results, and analysis. From low-frame-rate (15 fps) videos, the challenge participants are required to submit higher-frame-rate (30 and 60 fps) sequences by estimating temporally intermediate frames. To simulate realistic and challenging dynamics in the real-world, we employ the REDS_VTSR dataset derived from diverse videos captured in a hand-held camera for training and evaluation purposes. There have been 68 registered participants in the competition, and 5 teams (one withdrawn) have competed in the final testing phase. The winning team proposes the enhanced quadratic video interpolation method and achieves state-of-the-art on the VTSR task.