 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Normalization Tells You Which Filter is Important
Dec 02, 2021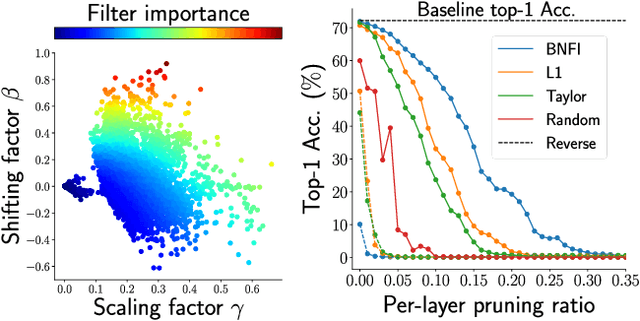
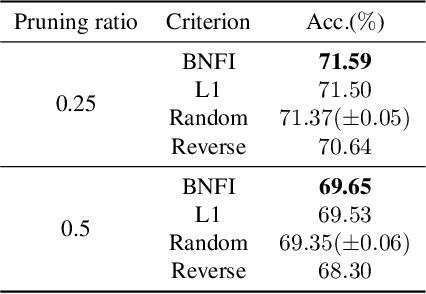
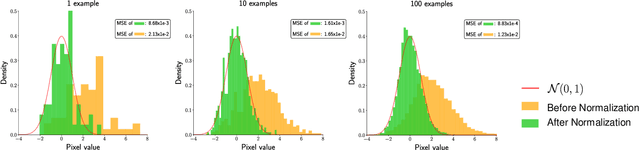
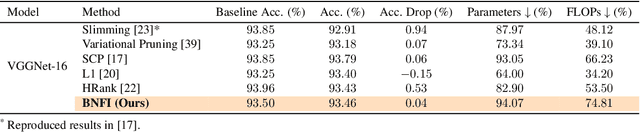
The goal of filter pruning is to search for unimportant filters to remove in order to make convolutional neural networks (CNNs) efficient without sacrificing the performance in the process. The challenge lies in finding information that can help determine how important or relevant each filter is with respect to the final output of neural networks. In this work, we share our observation that the batch normalization (BN) parameters of pre-trained CNNs can be used to estimate the feature distribution of activation outputs, without processing of training data. Upon observation, we propose a simple yet effective filter pruning method by evaluating the importance of each filter based on the BN parameters of pre-trained CNNs. The experimental results on CIFAR-10 and ImageNet demonstrate that the proposed method can achieve outstanding performance with and without fine-tuning in terms of the trade-off between the accuracy drop and the reduction in computational complexity and number of parameters of pruned networks.
Generative Residual Attention Network for Disease Detection
Oct 25, 2021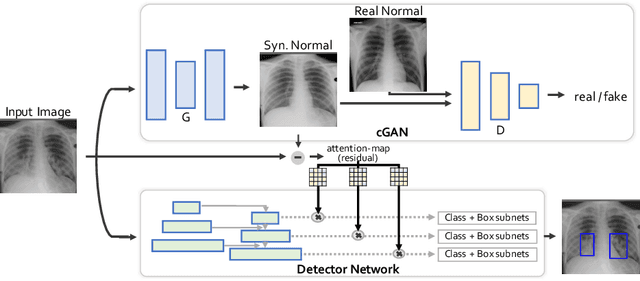
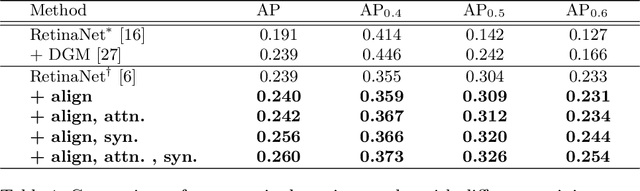
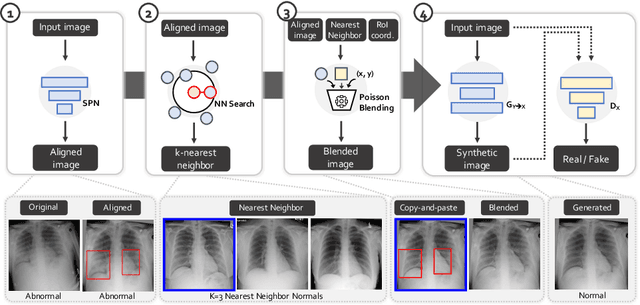
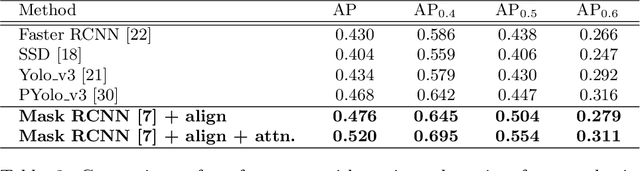
Accurate identification and localization of abnormalities from radiology images serve as a critical role in computer-aided diagnosis (CAD) systems. Building a highly generalizable system usually requires a large amount of data with high-quality annotations, including disease-specific global and localization information. However, in medical images, only a limited number of high-quality images and annotations are available due to annotation expenses. In this paper, we explore this problem by presenting a novel approach for disease generation in X-rays using a conditional generative adversarial learning. Specifically, given a chest X-ray image from a source domain, we generate a corresponding radiology image in a target domain while preserving the identity of the patient. We then use the generated X-ray image in the target domain to augment our training to improve the detection performance. We also present a unified framework that simultaneously performs disease generation and localization.We evaluate the proposed approach on the X-ray image dataset provided by the Radiological Society of North America (RSNA), surpassing the state-of-the-art baseline detection algorithms.
Meta-Learning with Task-Adaptive Loss Function for Few-Shot Learning
Oct 17, 2021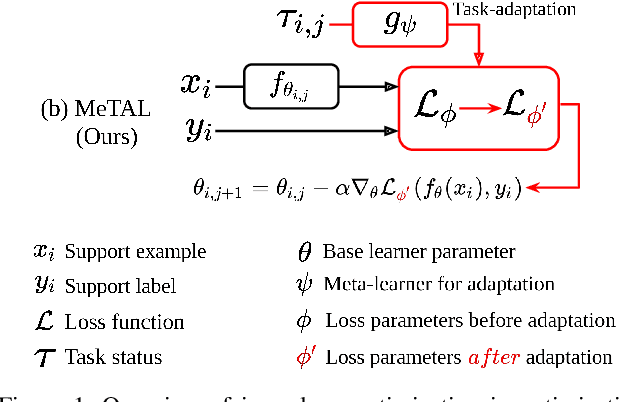
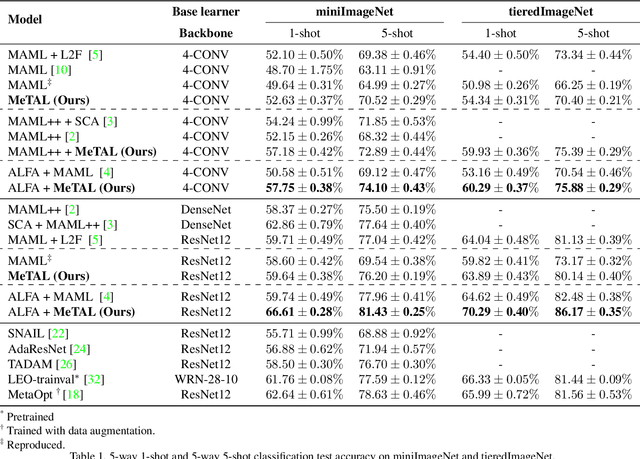
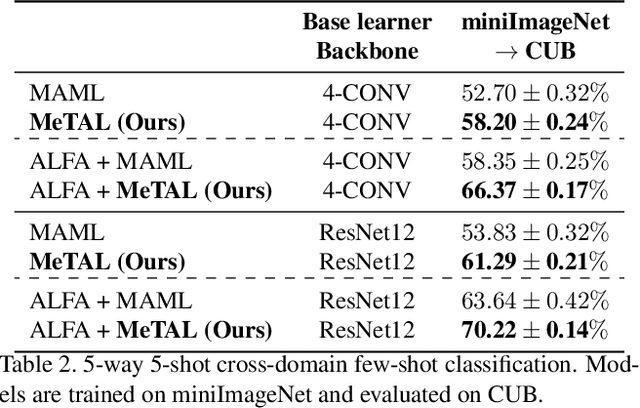
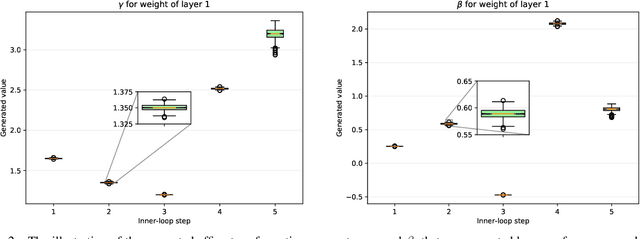
In few-shot learning scenarios, the challenge is to generalize and perform well on new unseen examples when only very few labeled examples are available for each task. Model-agnostic meta-learning (MAML) has gained the popularity as one of the representative few-shot learning methods for its flexibility and applicability to diverse problems. However, MAML and its variants often resort to a simple loss function without any auxiliary loss function or regularization terms that can help achieve better generalization. The problem lies in that each application and task may require different auxiliary loss function, especially when tasks are diverse and distinct. Instead of attempting to hand-design an auxiliary loss function for each application and task, we introduce a new meta-learning framework with a loss function that adapts to each task. Our proposed framework, named Meta-Learning with Task-Adaptive Loss Function (MeTAL), demonstrates the effectiveness and the flexibility across various domains, such as few-shot classification and few-shot regression.
PolyNet: Polynomial Neural Network for 3D Shape Recognition with PolyShape Representation
Oct 15, 2021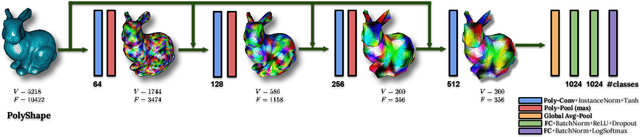
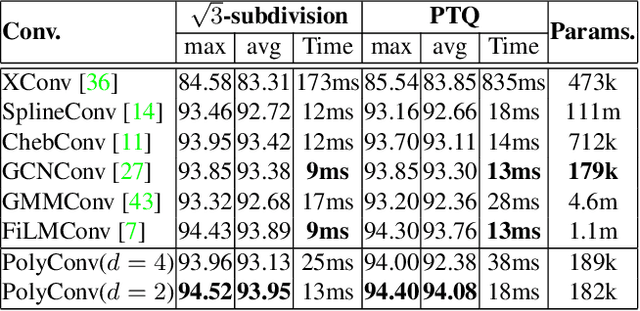
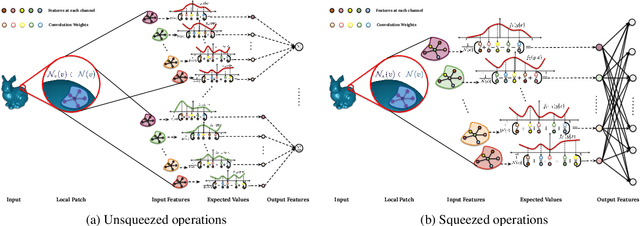
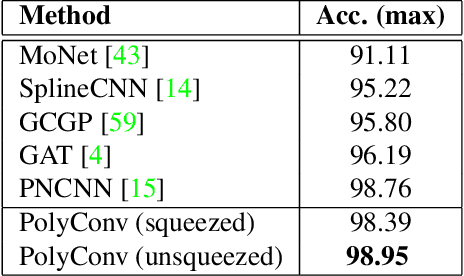
3D shape representation and its processing have substantial effects on 3D shape recognition. The polygon mesh as a 3D shape representation has many advantages in computer graphics and geometry processing. However, there are still some challenges for the existing deep neural network (DNN)-based methods on polygon mesh representation, such as handling the variations in the degree and permutations of the vertices and their pairwise distances. To overcome these challenges, we propose a DNN-based method (PolyNet) and a specific polygon mesh representation (PolyShape) with a multi-resolution structure. PolyNet contains two operations; (1) a polynomial convolution (PolyConv) operation with learnable coefficients, which learns continuous distributions as the convolutional filters to share the weights across different vertices, and (2) a polygonal pooling (PolyPool) procedure by utilizing the multi-resolution structure of PolyShape to aggregate the features in a much lower dimension. Our experiments demonstrate the strength and the advantages of PolyNet on both 3D shape classification and retrieval tasks compared to existing polygon mesh-based methods and its superiority in classifying graph representations of images. The code is publicly available from https://myavartanoo.github.io/polynet/.
Toward Real-World Super-Resolution via Adaptive Downsampling Models
Sep 08, 2021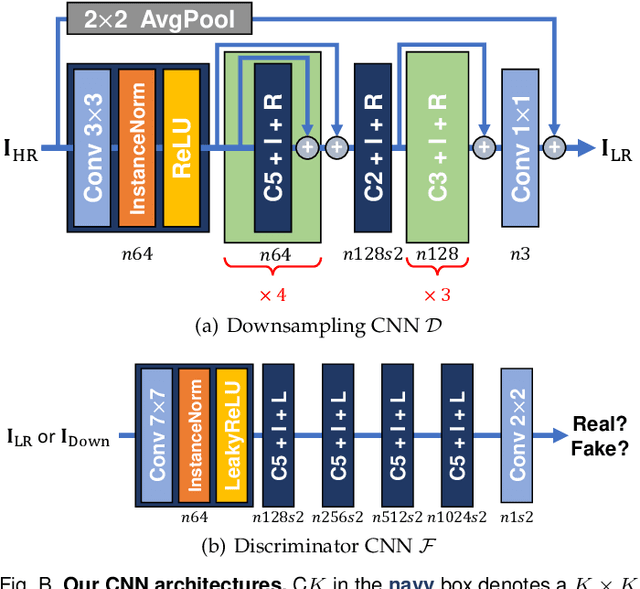

Most image super-resolution (SR) methods are developed on synthetic low-resolution (LR) and high-resolution (HR) image pairs that are constructed by a predetermined operation, e.g., bicubic downsampling. As existing methods typically learn an inverse mapping of the specific function, they produce blurry results when applied to real-world images whose exact formulation is different and unknown. Therefore, several methods attempt to synthesize much more diverse LR samples or learn a realistic downsampling model. However, due to restrictive assumptions on the downsampling process, they are still biased and less generalizable. This study proposes a novel method to simulate an unknown downsampling process without imposing restrictive prior knowledge. We propose a generalizable low-frequency loss (LFL) in the adversarial training framework to imitate the distribution of target LR images without using any paired examples. Furthermore, we design an adaptive data loss (ADL) for the downsampler, which can be adaptively learned and updated from the data during the training loops. Extensive experiments validate that our downsampling model can facilitate existing SR methods to perform more accurate reconstructions on various synthetic and real-world examples than the conventional approaches.
3DIAS: 3D Shape Reconstruction with Implicit Algebraic Surfaces
Aug 19, 2021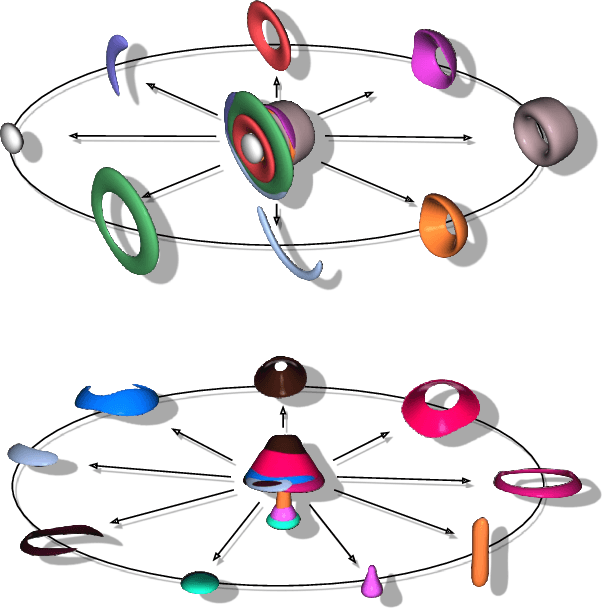
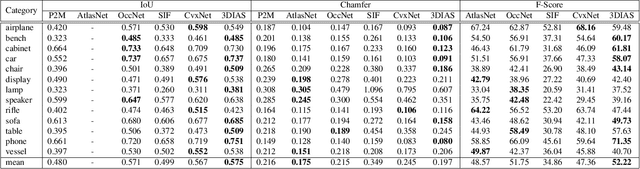
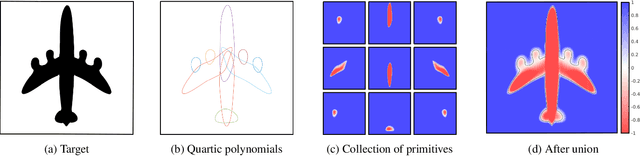

3D Shape representation has substantial effects on 3D shape reconstruction. Primitive-based representations approximate a 3D shape mainly by a set of simple implicit primitives, but the low geometrical complexity of the primitives limits the shape resolution. Moreover, setting a sufficient number of primitives for an arbitrary shape is challenging. To overcome these issues, we propose a constrained implicit algebraic surface as the primitive with few learnable coefficients and higher geometrical complexities and a deep neural network to produce these primitives. Our experiments demonstrate the superiorities of our method in terms of representation power compared to the state-of-the-art methods in single RGB image 3D shape reconstruction. Furthermore, we show that our method can semantically learn segments of 3D shapes in an unsupervised manner. The code is publicly available from https://myavartanoo.github.io/3dias/ .
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

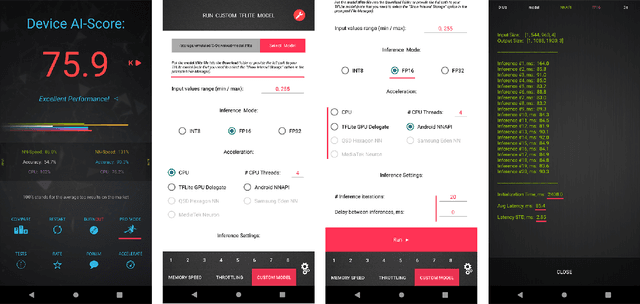
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
NTIRE 2021 Challenge on Video Super-Resolution
May 10, 2021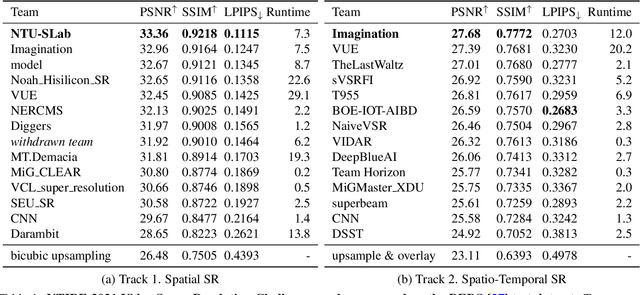


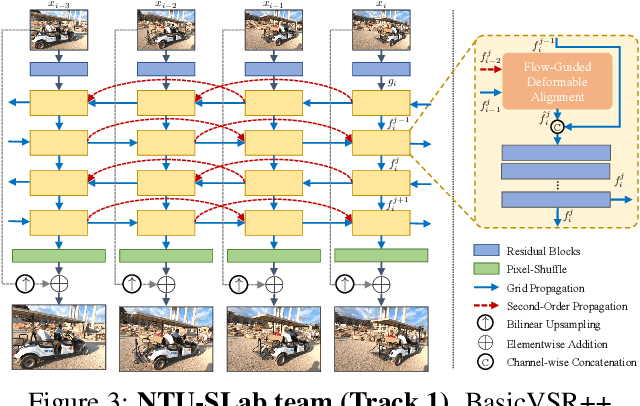
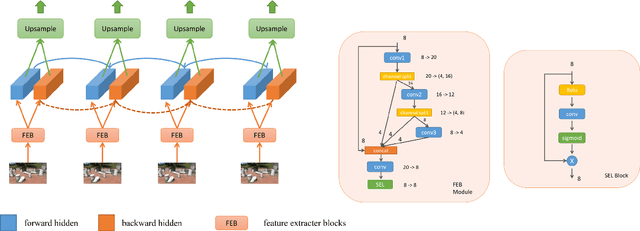
Super-Resolution (SR) is a fundamental computer vision task that aims to obtain a high-resolution clean image from the given low-resolution counterpart. This paper reviews the NTIRE 2021 Challenge on Video Super-Resolution. We present evaluation results from two competition tracks as well as the proposed solutions. Track 1 aims to develop conventional video SR methods focusing on the restoration quality. Track 2 assumes a more challenging environment with lower frame rates, casting spatio-temporal SR problem. In each competition, 247 and 223 participants have registered, respectively. During the final testing phase, 14 teams competed in each track to achieve state-of-the-art performance on video SR tasks.
NTIRE 2021 Challenge on Image Deblurring
Apr 30, 2021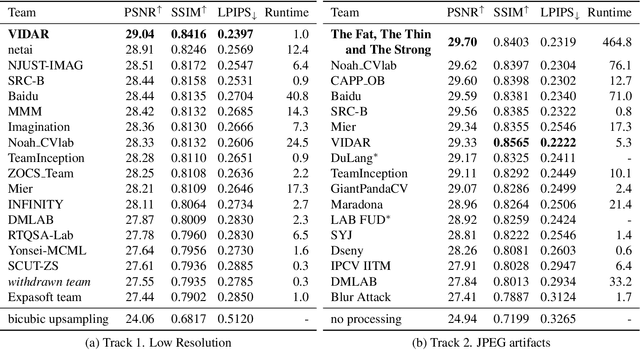


Motion blur is a common photography artifact in dynamic environments that typically comes jointly with the other types of degradation. This paper reviews the NTIRE 2021 Challenge on Image Deblurring. In this challenge report, we describe the challenge specifics and the evaluation results from the 2 competition tracks with the proposed solutions. While both the tracks aim to recover a high-quality clean image from a blurry image, different artifacts are jointly involved. In track 1, the blurry images are in a low resolution while track 2 images are compressed in JPEG format. In each competition, there were 338 and 238 registered participants and in the final testing phase, 18 and 17 teams competed. The winning methods demonstrate the state-of-the-art performance on the image deblurring task with the jointly combined artifacts.
Clean Images are Hard to Reblur: A New Clue for Deblurring
Apr 26, 2021
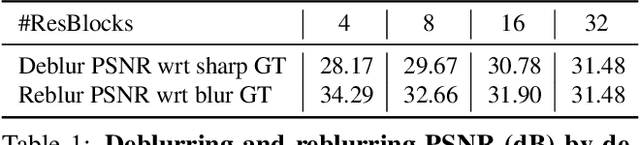

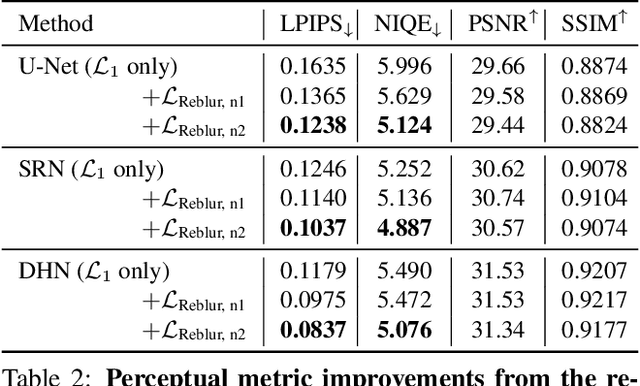
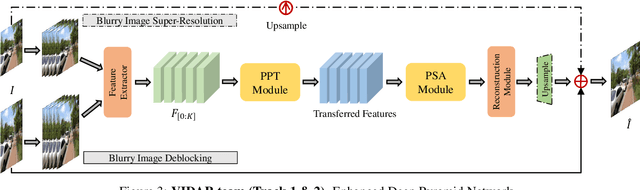
The goal of dynamic scene deblurring is to remove the motion blur present in a given image. Most learning-based approaches implement their solutions by minimizing the L1 or L2 distance between the output and reference sharp image. Recent attempts improve the perceptual quality of the deblurred image by using features learned from visual recognition tasks. However, those features are originally designed to capture the high-level contexts rather than the low-level structures of the given image, such as blurriness. We propose a novel low-level perceptual loss to make image sharper. To better focus on image blurriness, we train a reblurring module amplifying the unremoved motion blur. Motivated that a well-deblurred clean image should contain zero-magnitude motion blur that is hard to be amplified, we design two types of reblurring loss functions. The supervised reblurring loss at training stage compares the amplified blur between the deblurred image and the reference sharp image. The self-supervised reblurring loss at inference stage inspects if the deblurred image still contains noticeable blur to be amplified. Our experimental results demonstrate the proposed reblurring losses improve the perceptual quality of the deblurred images in terms of NIQE and LPIPS scores as well as visual sharpness.