 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterization of Overlap in Observational Studies
Jul 09, 2019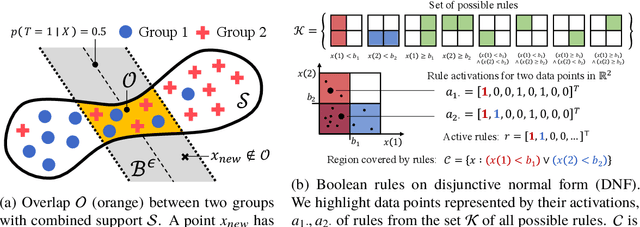
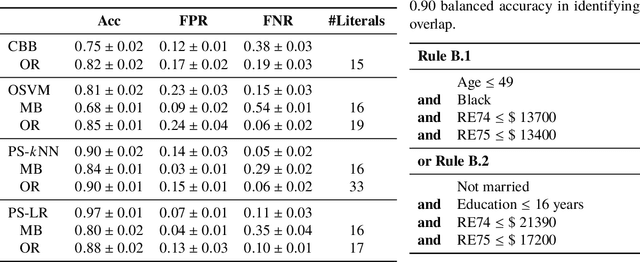
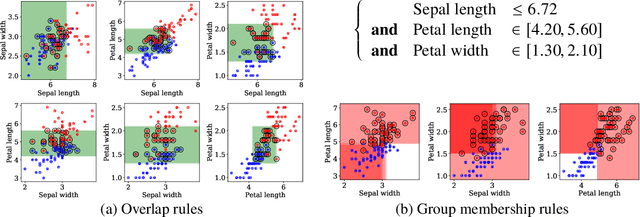

Overlap between treatment groups is required for nonparametric estimation of causal effects. If a subgroup of subjects always receives (or never receives) a given intervention, we cannot estimate the effect of intervention changes on that subgroup without further assumptions. When overlap does not hold globally, characterizing local regions of overlap can inform the relevance of any causal conclusions for new subjects, and can help guide additional data collection. To have impact, these descriptions must be interpretable for downstream users who are not machine learning experts, such as clinicians. We formalize overlap estimation as a problem of finding minimum volume sets and give a method to solve it by reduction to binary classification with Boolean rules. We also generalize our method to estimate overlap in off-policy policy evaluation. Using data from real-world applications, we demonstrate that these rules have comparable accuracy to black-box estimators while maintaining a simple description. In one case study, we perform a user study with clinicians to evaluate rules learned to describe treatment group overlap in post-surgical opioid prescriptions. In another, we estimate overlap in policy evaluation of antibiotic prescription for urinary tract infections.
Teaching AI to Explain its Decisions Using Embeddings and Multi-Task Learning
Jun 05, 2019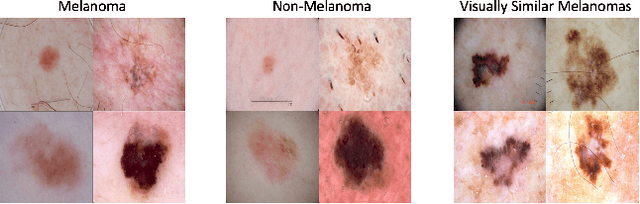
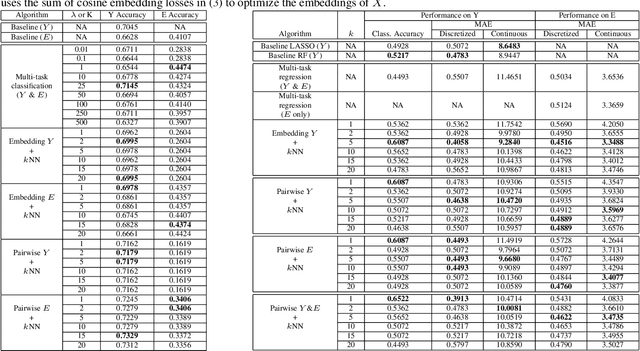
Using machine learning in high-stakes applications often requires predictions to be accompanied by explanations comprehensible to the domain user, who has ultimate responsibility for decisions and outcomes. Recently, a new framework for providing explanations, called TED, has been proposed to provide meaningful explanations for predictions. This framework augments training data to include explanations elicited from domain users, in addition to features and labels. This approach ensures that explanations for predictions are tailored to the complexity expectations and domain knowledge of the consumer. In this paper, we build on this foundational work, by exploring more sophisticated instantiations of the TED framework and empirically evaluate their effectiveness in two diverse domains, chemical odor and skin cancer prediction. Results demonstrate that meaningful explanations can be reliably taught to machine learning algorithms, and in some cases, improving modeling accuracy.
Interpretable Subgroup Discovery in Treatment Effect Estimation with Application to Opioid Prescribing Guidelines
May 08, 2019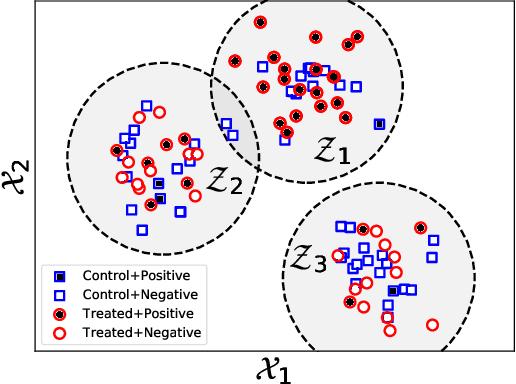
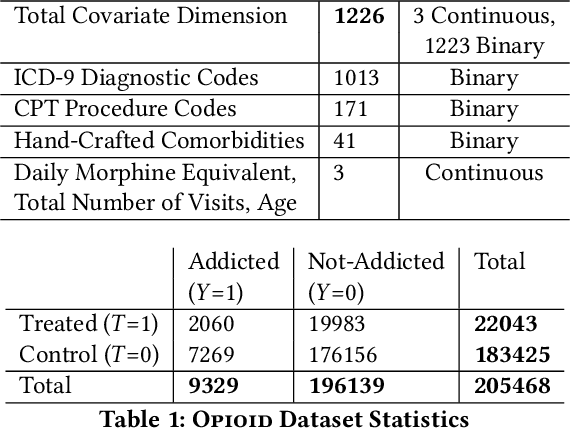
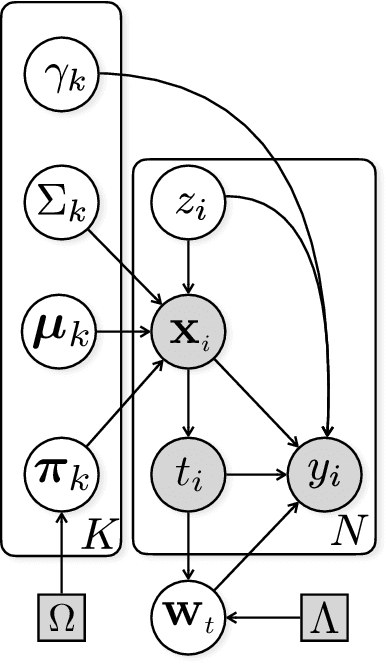
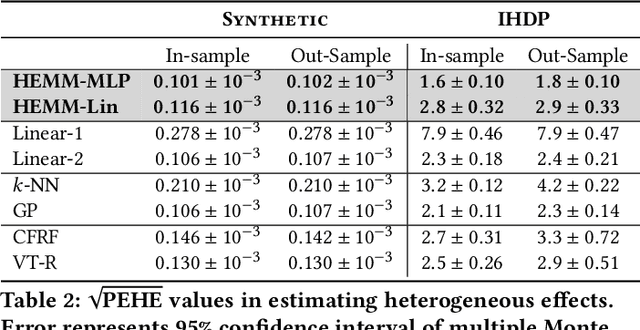
The dearth of prescribing guidelines for physicians is one key driver of the current opioid epidemic in the United States. In this work, we analyze medical and pharmaceutical claims data to draw insights on characteristics of patients who are more prone to adverse outcomes after an initial synthetic opioid prescription. Toward this end, we propose a generative model that allows discovery from observational data of subgroups that demonstrate an enhanced or diminished causal effect due to treatment. Our approach models these sub-populations as a mixture distribution, using sparsity to enhance interpretability, while jointly learning nonlinear predictors of the potential outcomes to better adjust for confounding. The approach leads to human-interpretable insights on discovered subgroups, improving the practical utility for decision support
Bias Mitigation Post-processing for Individual and Group Fairness
Dec 14, 2018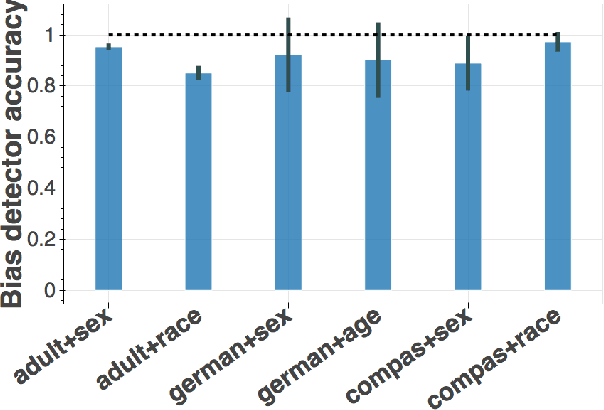
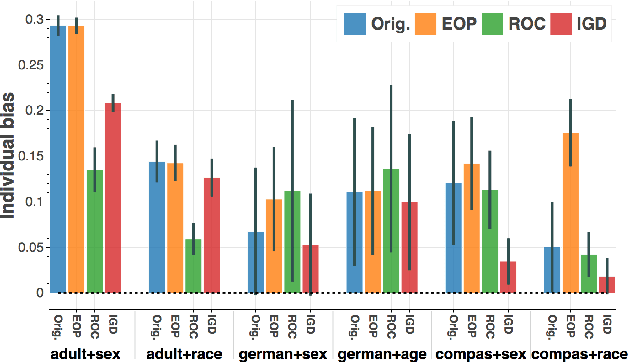
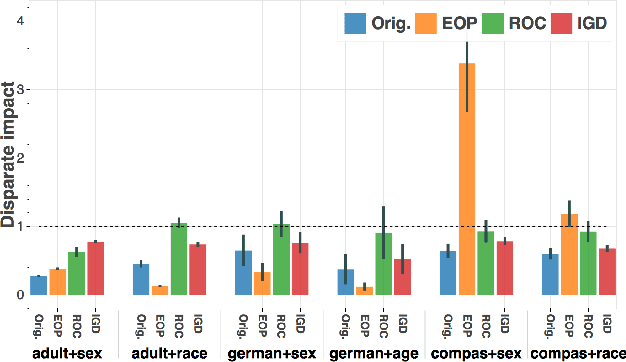
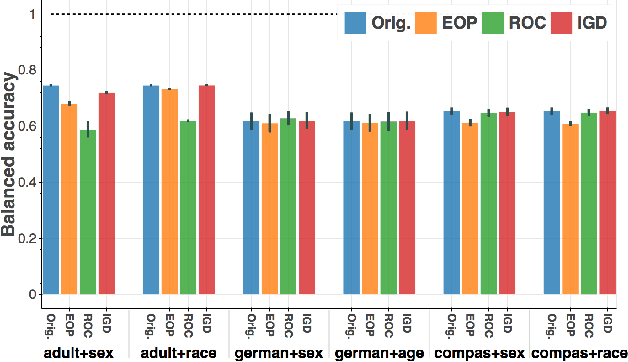
Whereas previous post-processing approaches for increasing the fairness of predictions of biased classifiers address only group fairness, we propose a method for increasing both individual and group fairness. Our novel framework includes an individual bias detector used to prioritize data samples in a bias mitigation algorithm aiming to improve the group fairness measure of disparate impact. We show superior performance to previous work in the combination of classification accuracy, individual fairness and group fairness on several real-world datasets in applications such as credit, employment, and criminal justice.
Understanding Unequal Gender Classification Accuracy from Face Images
Nov 30, 2018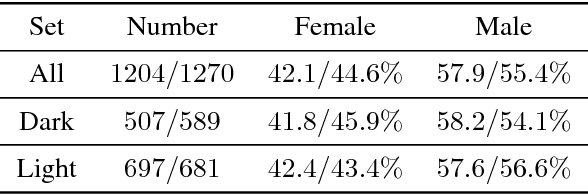
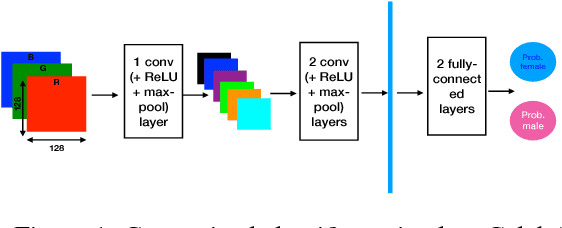
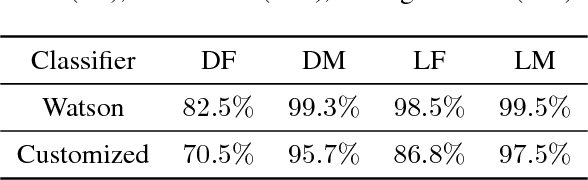
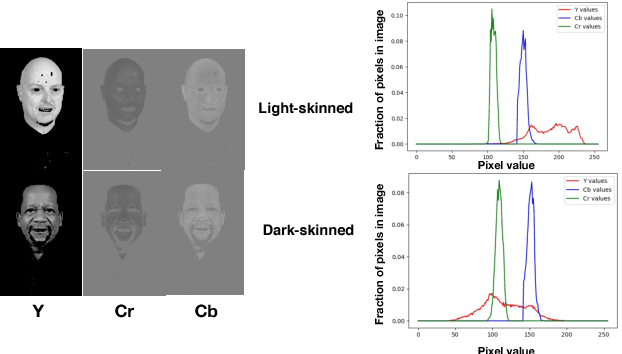
Recent work shows unequal performance of commercial face classification services in the gender classification task across intersectional groups defined by skin type and gender. Accuracy on dark-skinned females is significantly worse than on any other group. In this paper, we conduct several analyses to try to uncover the reason for this gap. The main finding, perhaps surprisingly, is that skin type is not the driver. This conclusion is reached via stability experiments that vary an image's skin type via color-theoretic methods, namely luminance mode-shift and optimal transport. A second suspect, hair length, is also shown not to be the driver via experiments on face images cropped to exclude the hair. Finally, using contrastive post-hoc explanation techniques for neural networks, we bring forth evidence suggesting that differences in lip, eye and cheek structure across ethnicity lead to the differences. Further, lip and eye makeup are seen as strong predictors for a female face, which is a troubling propagation of a gender stereotype.
TED: Teaching AI to Explain its Decisions
Nov 12, 2018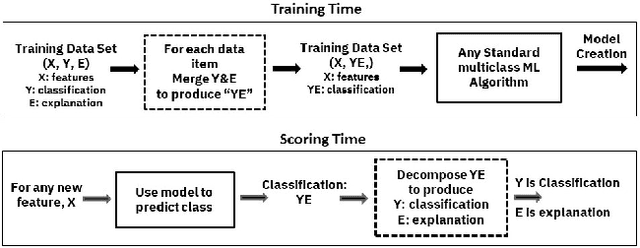
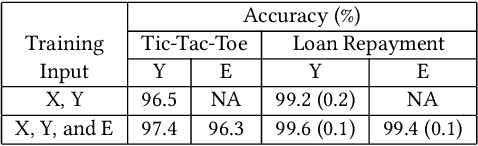

Artificial intelligence systems are being increasingly deployed due to their potential to increase the efficiency, scale, consistency, fairness, and accuracy of decisions. However, as many of these systems are opaque in their operation, there is a growing demand for such systems to provide explanations for their decisions. Conventional approaches to this problem attempt to expose or discover the inner workings of a machine learning model with the hope that the resulting explanations will be meaningful to the consumer. In contrast, this paper suggests a new approach to this problem. It introduces a simple, practical framework, called Teaching Explanations for Decisions (TED), that provides meaningful explanations that match the mental model of the consumer. We illustrate the generality and effectiveness of this approach with two different examples, resulting in highly accurate explanations with no loss of prediction accuracy for these two examples.
SimplerVoice: A Key Message & Visual Description Generator System for Illiteracy
Nov 03, 2018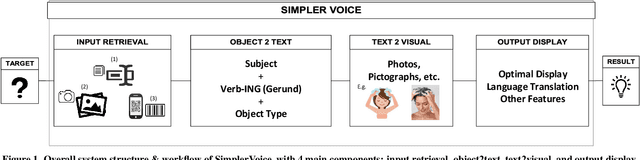

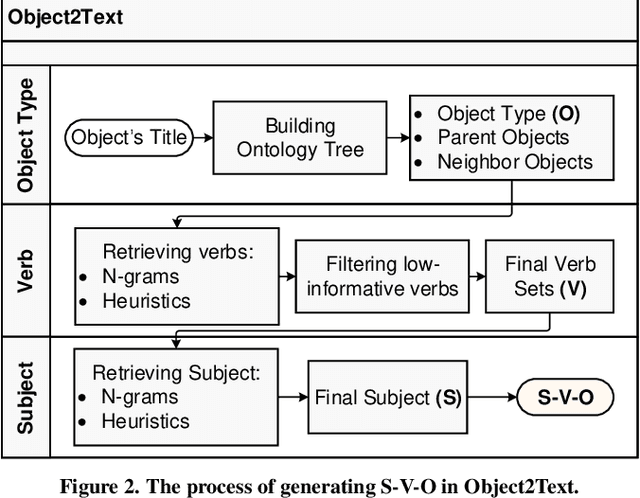

We introduce SimplerVoice: a key message and visual description generator system to help low-literate adults navigate the information-dense world with confidence, on their own. SimplerVoice can automatically generate sensible sentences describing an unknown object, extract semantic meanings of the object usage in the form of a query string, then, represent the string as multiple types of visual guidance (pictures, pictographs, etc.). We demonstrate SimplerVoice system in a case study of generating grocery products' manuals through a mobile application. To evaluate, we conducted a user study on SimplerVoice's generated description in comparison to the information interpreted by users from other methods: the original product package and search engines' top result, in which SimplerVoice achieved the highest performance score: 4.82 on 5-point mean opinion score scale. Our result shows that SimplerVoice is able to provide low-literate end-users with simple yet informative components to help them understand how to use the grocery products, and that the system may potentially provide benefits in other real-world use cases
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Oct 03, 2018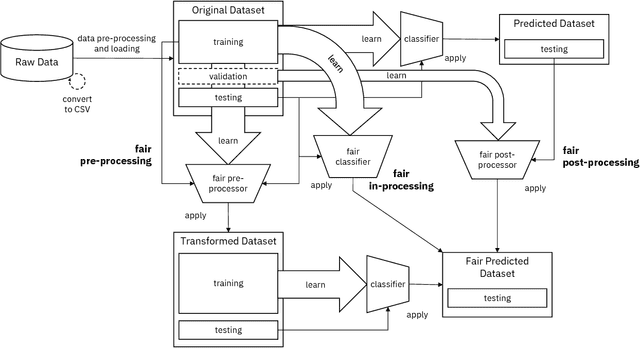
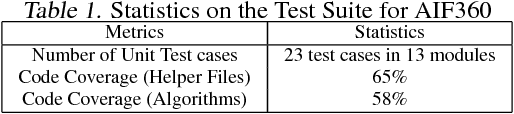
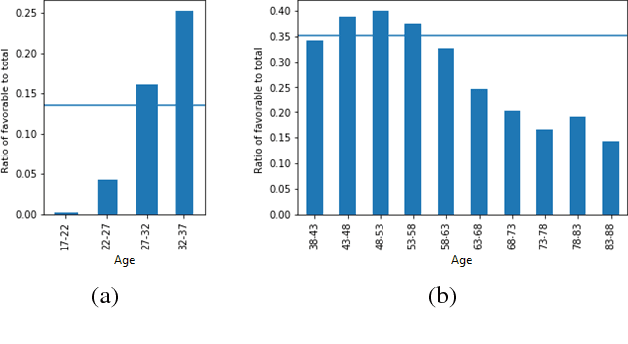
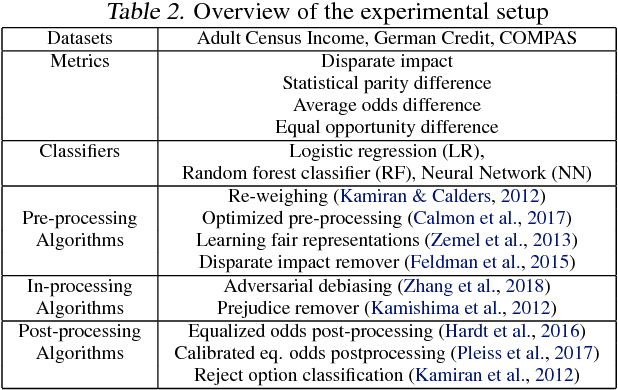
Fairness is an increasingly important concern as machine learning models are used to support decision making in high-stakes applications such as mortgage lending, hiring, and prison sentencing. This paper introduces a new open source Python toolkit for algorithmic fairness, AI Fairness 360 (AIF360), released under an Apache v2.0 license {https://github.com/ibm/aif360). The main objectives of this toolkit are to help facilitate the transition of fairness research algorithms to use in an industrial setting and to provide a common framework for fairness researchers to share and evaluate algorithms. The package includes a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to mitigate bias in datasets and models. It also includes an interactive Web experience (https://aif360.mybluemix.net) that provides a gentle introduction to the concepts and capabilities for line-of-business users, as well as extensive documentation, usage guidance, and industry-specific tutorials to enable data scientists and practitioners to incorporate the most appropriate tool for their problem into their work products. The architecture of the package has been engineered to conform to a standard paradigm used in data science, thereby further improving usability for practitioners. Such architectural design and abstractions enable researchers and developers to extend the toolkit with their new algorithms and improvements, and to use it for performance benchmarking. A built-in testing infrastructure maintains code quality.
Trusted Multi-Party Computation and Verifiable Simulations: A Scalable Blockchain Approach
Sep 22, 2018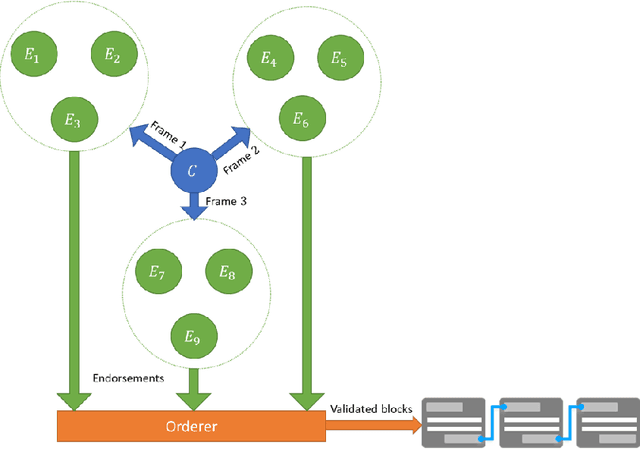

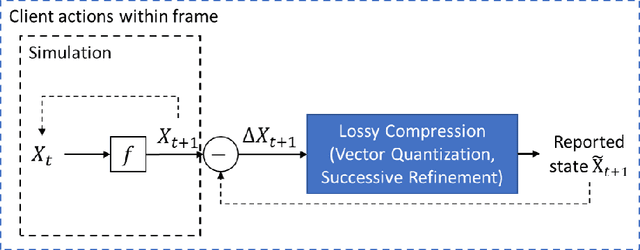
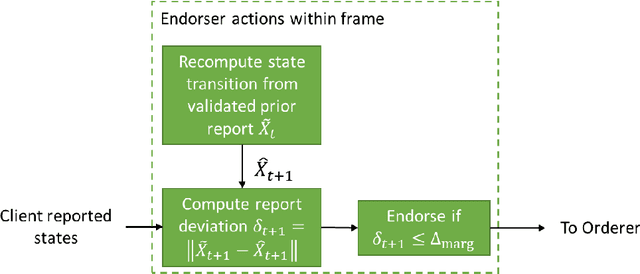
Large-scale computational experiments, often running over weeks and over large datasets, are used extensively in fields such as epidemiology, meteorology, computational biology, and healthcare to understand phenomena, and design high-stakes policies affecting everyday health and economy. For instance, the OpenMalaria framework is a computationally-intensive simulation used by various non-governmental and governmental agencies to understand malarial disease spread and effectiveness of intervention strategies, and subsequently design healthcare policies. Given that such shared results form the basis of inferences drawn, technological solutions designed, and day-to-day policies drafted, it is essential that the computations are validated and trusted. In particular, in a multi-agent environment involving several independent computing agents, a notion of trust in results generated by peers is critical in facilitating transparency, accountability, and collaboration. Using a novel combination of distributed validation of atomic computation blocks and a blockchain-based immutable audits mechanism, this work proposes a universal framework for distributed trust in computations. In particular we address the scalaibility problem by reducing the storage and communication costs using a lossy compression scheme. This framework guarantees not only verifiability of final results, but also the validity of local computations, and its cost-benefit tradeoffs are studied using a synthetic example of training a neural network.
Teaching Meaningful Explanations
Sep 11, 2018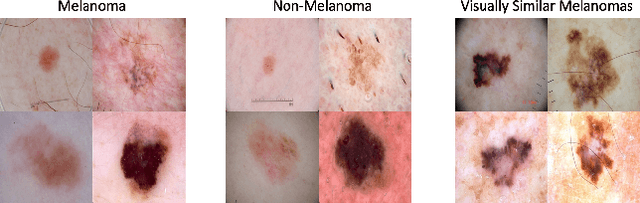
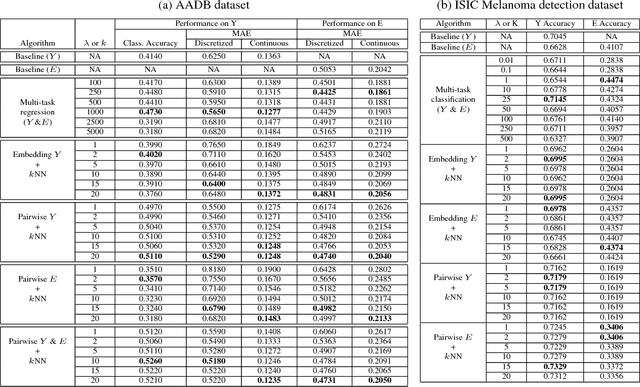
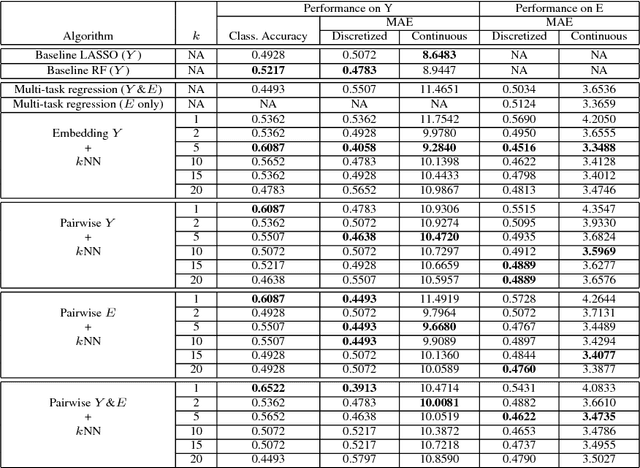
The adoption of machine learning in high-stakes applications such as healthcare and law has lagged in part because predictions are not accompanied by explanations comprehensible to the domain user, who often holds the ultimate responsibility for decisions and outcomes. In this paper, we propose an approach to generate such explanations in which training data is augmented to include, in addition to features and labels, explanations elicited from domain users. A joint model is then learned to produce both labels and explanations from the input features. This simple idea ensures that explanations are tailored to the complexity expectations and domain knowledge of the consumer. Evaluation spans multiple modeling techniques on a game dataset, a (visual) aesthetics dataset, a chemical odor dataset and a Melanoma dataset showing that our approach is generalizable across domains and algorithms. Results demonstrate that meaningful explanations can be reliably taught to machine learning algorithms, and in some cases, also improve modeling accuracy.