 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fair Recommendation in Two-Sided Platforms
Dec 26, 2021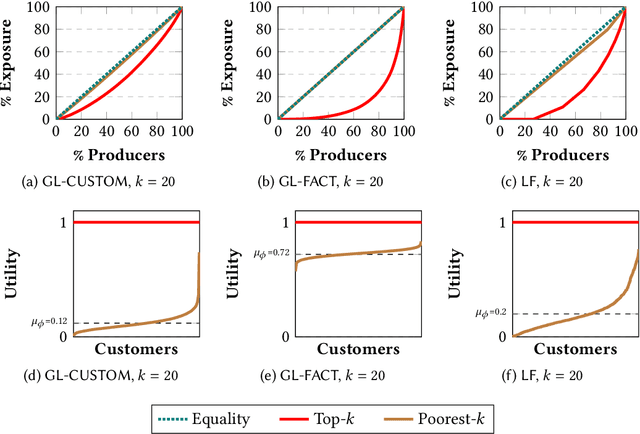
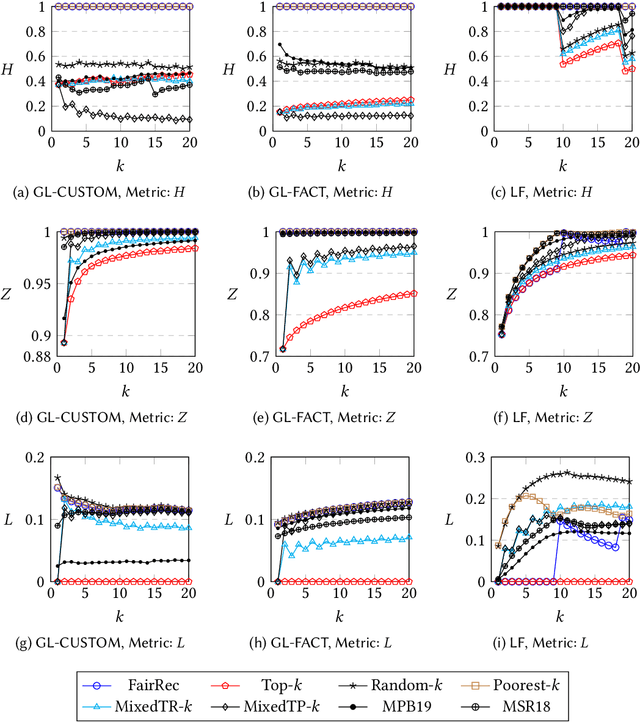
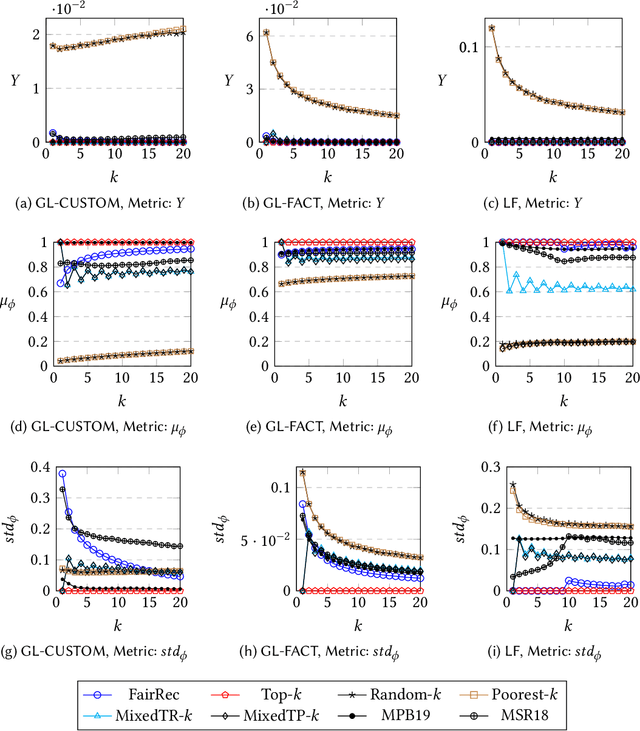
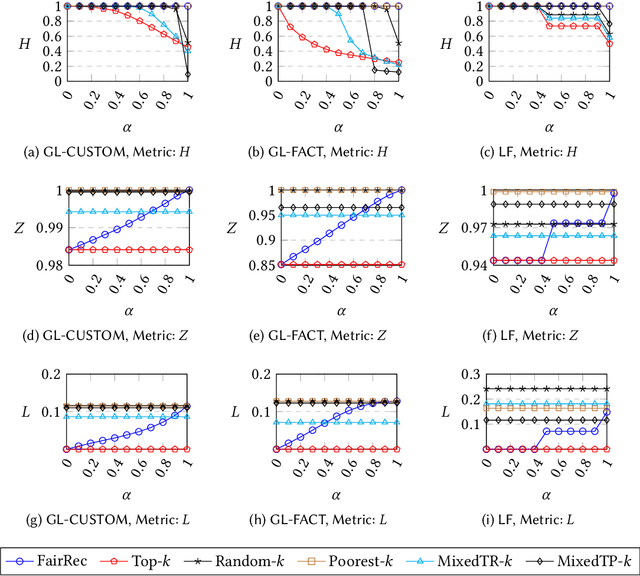
Many online platforms today (such as Amazon, Netflix, Spotify, LinkedIn, and AirBnB) can be thought of as two-sided markets with producers and customers of goods and services. Traditionally, recommendation services in these platforms have focused on maximizing customer satisfaction by tailoring the results according to the personalized preferences of individual customers. However, our investigation reinforces the fact that such customer-centric design of these services may lead to unfair distribution of exposure to the producers, which may adversely impact their well-being. On the other hand, a pure producer-centric design might become unfair to the customers. As more and more people are depending on such platforms to earn a living, it is important to ensure fairness to both producers and customers. In this work, by mapping a fair personalized recommendation problem to a constrained version of the problem of fairly allocating indivisible goods, we propose to provide fairness guarantees for both sides. Formally, our proposed {\em FairRec} algorithm guarantees Maxi-Min Share ($\alpha$-MMS) of exposure for the producers, and Envy-Free up to One Item (EF1) fairness for the customers. Extensive evaluations over multiple real-world datasets show the effectiveness of {\em FairRec} in ensuring two-sided fairness while incurring a marginal loss in overall recommendation quality. Finally, we present a modification of FairRec (named as FairRecPlus) that at the cost of additional computation time, improves the recommendation performance for the customers, while maintaining the same fairness guarantees.
On Fair Selection in the Presence of Implicit and Differential Variance
Dec 10, 2021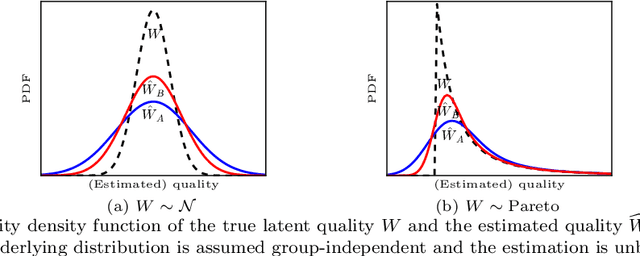

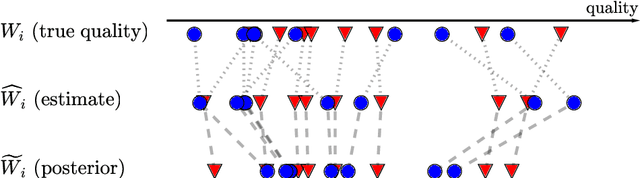
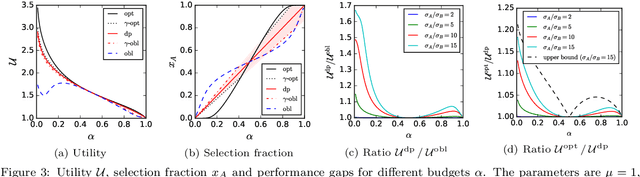
Discrimination in selection problems such as hiring or college admission is often explained by implicit bias from the decision maker against disadvantaged demographic groups. In this paper, we consider a model where the decision maker receives a noisy estimate of each candidate's quality, whose variance depends on the candidate's group -- we argue that such differential variance is a key feature of many selection problems. We analyze two notable settings: in the first, the noise variances are unknown to the decision maker who simply picks the candidates with the highest estimated quality independently of their group; in the second, the variances are known and the decision maker picks candidates having the highest expected quality given the noisy estimate. We show that both baseline decision makers yield discrimination, although in opposite directions: the first leads to underrepresentation of the low-variance group while the second leads to underrepresentation of the high-variance group. We study the effect on the selection utility of imposing a fairness mechanism that we term the $\gamma$-rule (it is an extension of the classical four-fifths rule and it also includes demographic parity). In the first setting (with unknown variances), we prove that under mild conditions, imposing the $\gamma$-rule increases the selection utility -- here there is no trade-off between fairness and utility. In the second setting (with known variances), imposing the $\gamma$-rule decreases the utility but we prove a bound on the utility loss due to the fairness mechanism.
Exploring Alignment of Representations with Human Perception
Nov 29, 2021
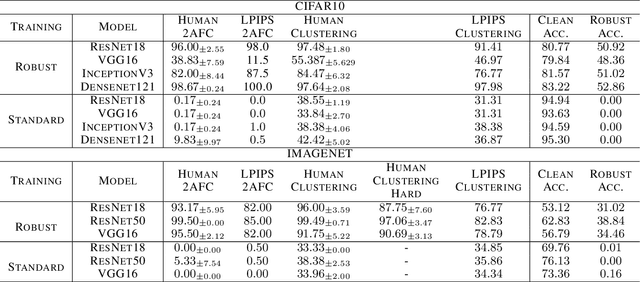


We argue that a valuable perspective on when a model learns \textit{good} representations is that inputs that are mapped to similar representations by the model should be perceived similarly by humans. We use \textit{representation inversion} to generate multiple inputs that map to the same model representation, then quantify the perceptual similarity of these inputs via human surveys. Our approach yields a measure of the extent to which a model is aligned with human perception. Using this measure of alignment, we evaluate models trained with various learning paradigms (\eg~supervised and self-supervised learning) and different training losses (standard and robust training). Our results suggest that the alignment of representations with human perception provides useful additional insights into the qualities of a model. For example, we find that alignment with human perception can be used as a measure of trust in a model's prediction on inputs where different models have conflicting outputs. We also find that various properties of a model like its architecture, training paradigm, training loss, and data augmentation play a significant role in learning representations that are aligned with human perception.
Detecting and Mitigating Test-time Failure Risks via Model-agnostic Uncertainty Learning
Sep 09, 2021
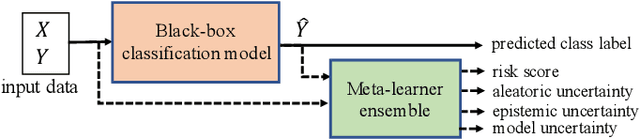

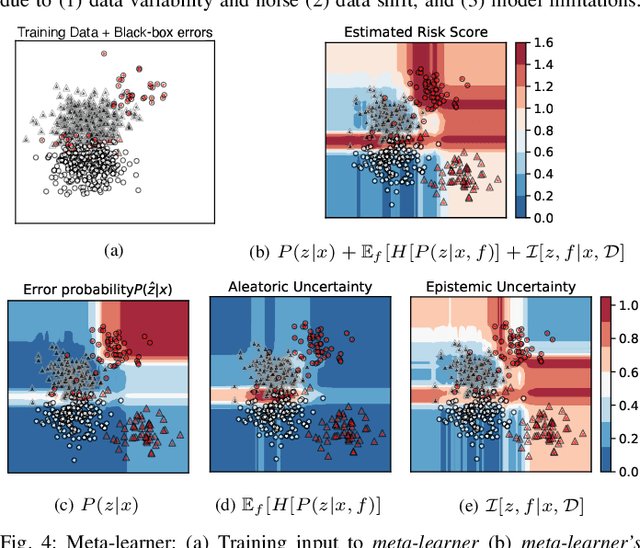
Reliably predicting potential failure risks of machine learning (ML) systems when deployed with production data is a crucial aspect of trustworthy AI. This paper introduces Risk Advisor, a novel post-hoc meta-learner for estimating failure risks and predictive uncertainties of any already-trained black-box classification model. In addition to providing a risk score, the Risk Advisor decomposes the uncertainty estimates into aleatoric and epistemic uncertainty components, thus giving informative insights into the sources of uncertainty inducing the failures. Consequently, Risk Advisor can distinguish between failures caused by data variability, data shifts and model limitations and advise on mitigation actions (e.g., collecting more data to counter data shift). Extensive experiments on various families of black-box classification models and on real-world and synthetic datasets covering common ML failure scenarios show that the Risk Advisor reliably predicts deployment-time failure risks in all the scenarios, and outperforms strong baselines.
Loss-Aversively Fair Classification
May 10, 2021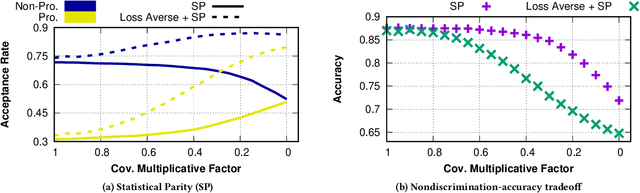
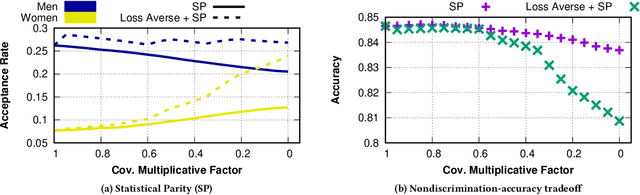
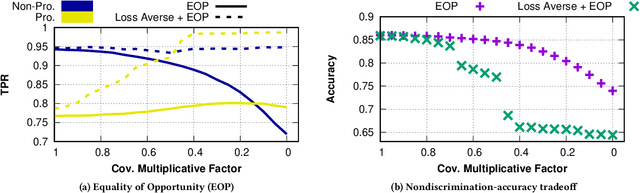
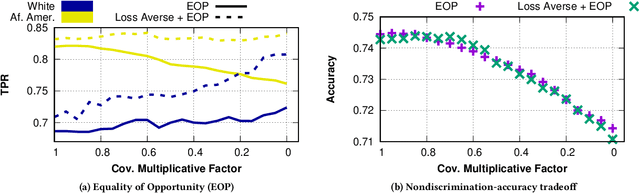
The use of algorithmic (learning-based) decision making in scenarios that affect human lives has motivated a number of recent studies to investigate such decision making systems for potential unfairness, such as discrimination against subjects based on their sensitive features like gender or race. However, when judging the fairness of a newly designed decision making system, these studies have overlooked an important influence on people's perceptions of fairness, which is how the new algorithm changes the status quo, i.e., decisions of the existing decision making system. Motivated by extensive literature in behavioral economics and behavioral psychology (prospect theory), we propose a notion of fair updates that we refer to as loss-averse updates. Loss-averse updates constrain the updates to yield improved (more beneficial) outcomes to subjects compared to the status quo. We propose tractable proxy measures that would allow this notion to be incorporated in the training of a variety of linear and non-linear classifiers. We show how our proxy measures can be combined with existing measures for training nondiscriminatory classifiers. Our evaluation using synthetic and real-world datasets demonstrates that the proposed proxy measures are effective for their desired tasks.
* 8 pages, Accepted at AIES 2019
Accounting for Model Uncertainty in Algorithmic Discrimination
May 10, 2021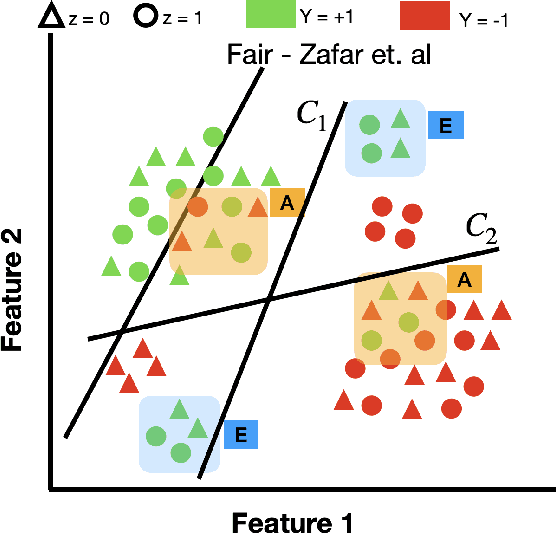
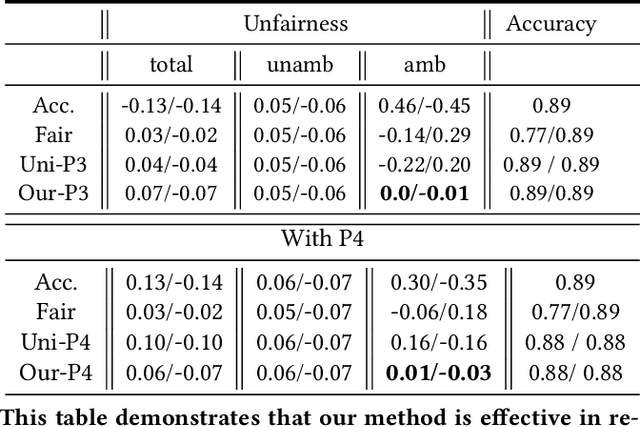

Traditional approaches to ensure group fairness in algorithmic decision making aim to equalize ``total'' error rates for different subgroups in the population. In contrast, we argue that the fairness approaches should instead focus only on equalizing errors arising due to model uncertainty (a.k.a epistemic uncertainty), caused due to lack of knowledge about the best model or due to lack of data. In other words, our proposal calls for ignoring the errors that occur due to uncertainty inherent in the data, i.e., aleatoric uncertainty. We draw a connection between predictive multiplicity and model uncertainty and argue that the techniques from predictive multiplicity could be used to identify errors made due to model uncertainty. We propose scalable convex proxies to come up with classifiers that exhibit predictive multiplicity and empirically show that our methods are comparable in performance and up to four orders of magnitude faster than the current state-of-the-art. We further propose methods to achieve our goal of equalizing group error rates arising due to model uncertainty in algorithmic decision making and demonstrate the effectiveness of these methods using synthetic and real-world datasets.
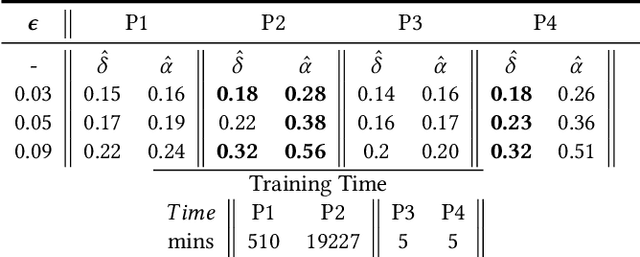
CrossWalk: Fairness-enhanced Node Representation Learning
May 06, 2021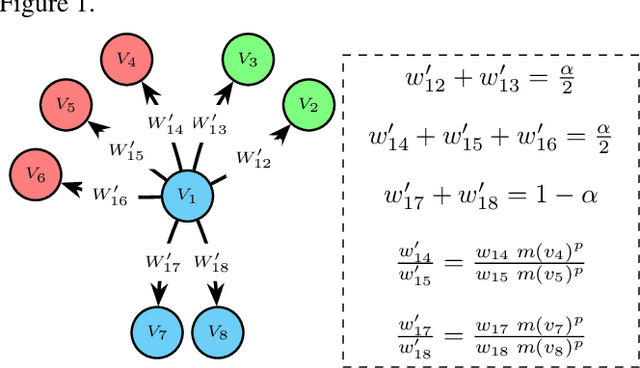
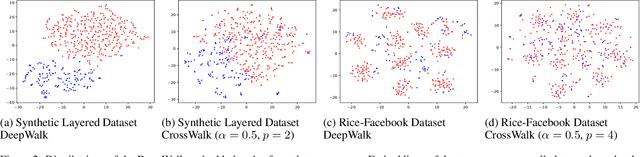
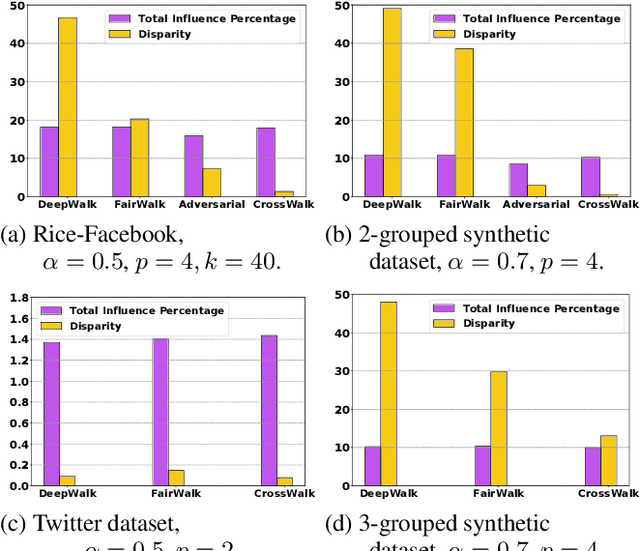
The potential for machine learning systems to amplify social inequities and unfairness is receiving increasing popular and academic attention. Much recent work has focused on developing algorithmic tools to assess and mitigate such unfairness. However, there is little work on enhancing fairness in graph algorithms. Here, we develop a simple, effective and general method, CrossWalk, that enhances fairness of various graph algorithms, including influence maximization, link prediction and node classification, applied to node embeddings. CrossWalk is applicable to any random walk based node representation learning algorithm, such as DeepWalk and Node2Vec. The key idea is to bias random walks to cross group boundaries, by upweighting edges which (1) are closer to the groups' peripheries or (2) connect different groups in the network. CrossWalk pulls nodes that are near groups' peripheries towards their neighbors from other groups in the embedding space, while preserving the necessary structural information from the graph. Extensive experiments show the effectiveness of our algorithm to enhance fairness in various graph algorithms, including influence maximization, link prediction and node classification in synthetic and real networks, with only a very small decrease in performance.
When the Umpire is also a Player: Bias in Private Label Product Recommendations on E-commerce Marketplaces
Feb 02, 2021
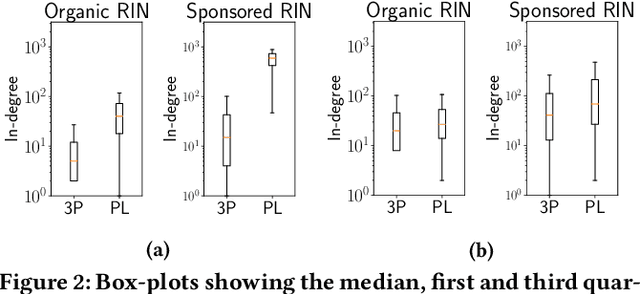
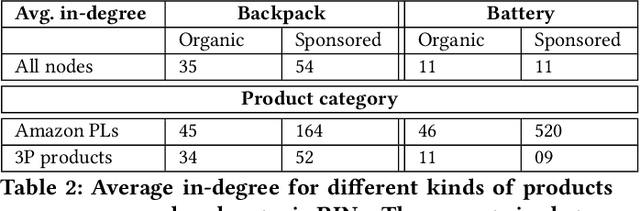
Algorithmic recommendations mediate interactions between millions of customers and products (in turn, their producers and sellers) on large e-commerce marketplaces like Amazon. In recent years, the producers and sellers have raised concerns about the fairness of black-box recommendation algorithms deployed on these marketplaces. Many complaints are centered around marketplaces biasing the algorithms to preferentially favor their own `private label' products over competitors. These concerns are exacerbated as marketplaces increasingly de-emphasize or replace `organic' recommendations with ad-driven `sponsored' recommendations, which include their own private labels. While these concerns have been covered in popular press and have spawned regulatory investigations, to our knowledge, there has not been any public audit of these marketplace algorithms. In this study, we bridge this gap by performing an end-to-end systematic audit of related item recommendations on Amazon. We propose a network-centric framework to quantify and compare the biases across organic and sponsored related item recommendations. Along a number of our proposed bias measures, we find that the sponsored recommendations are significantly more biased toward Amazon private label products compared to organic recommendations. While our findings are primarily interesting to producers and sellers on Amazon, our proposed bias measures are generally useful for measuring link formation bias in any social or content networks.
On Fair Virtual Conference Scheduling: Achieving Equitable Participant and Speaker Satisfaction
Oct 24, 2020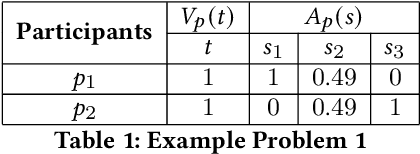
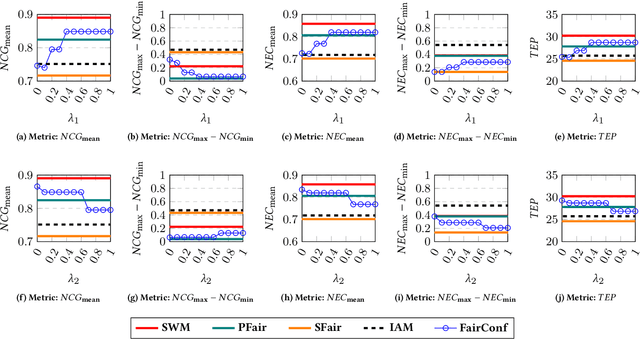
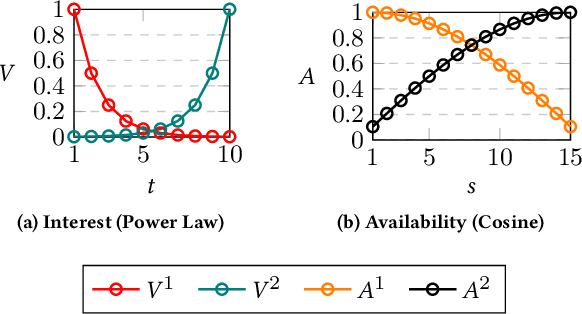
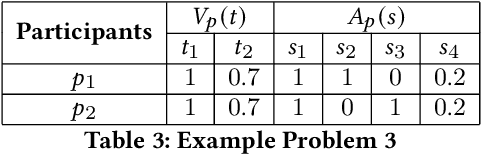
The (COVID-19) pandemic-induced restrictions on travel and social gatherings have prompted most conference organizers to move their events online. However, in contrast to physical conferences, virtual conferences face a challenge in efficiently scheduling talks, accounting for the availability of participants from different time-zones as well as their interests in attending different talks. In such settings, a natural objective for the conference organizers would be to maximize some global welfare measure, such as the total expected audience participation across all talks. However, we show that optimizing for global welfare could result in a schedule that is unfair to the stakeholders, i.e., the individual utilities for participants and speakers can be highly unequal. To address the fairness concerns, we formally define fairness notions for participants and speakers, and subsequently derive suitable fairness objectives for them. We show that the welfare and fairness objectives can be in conflict with each other, and there is a need to maintain a balance between these objective while caring for them simultaneously. Thus, we propose a joint optimization framework that allows conference organizers to design talk schedules that balance (i.e., allow trade-offs) between global welfare, participant fairness and the speaker fairness objectives. We show that the optimization problem can be solved using integer linear programming, and empirically evaluate the necessity and benefits of such joint optimization approach in virtual conference scheduling.
Unifying Model Explainability and Robustness via Machine-Checkable Concepts
Jul 02, 2020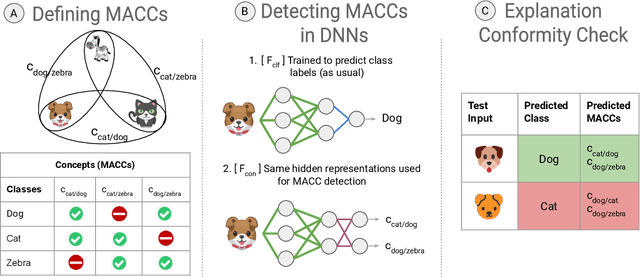



As deep neural networks (DNNs) get adopted in an ever-increasing number of applications, explainability has emerged as a crucial desideratum for these models. In many real-world tasks, one of the principal reasons for requiring explainability is to in turn assess prediction robustness, where predictions (i.e., class labels) that do not conform to their respective explanations (e.g., presence or absence of a concept in the input) are deemed to be unreliable. However, most, if not all, prior methods for checking explanation-conformity (e.g., LIME, TCAV, saliency maps) require significant manual intervention, which hinders their large-scale deployability. In this paper, we propose a robustness-assessment framework, at the core of which is the idea of using machine-checkable concepts. Our framework defines a large number of concepts that the DNN explanations could be based on and performs the explanation-conformity check at test time to assess prediction robustness. Both steps are executed in an automated manner without requiring any human intervention and are easily scaled to datasets with a very large number of classes. Experiments on real-world datasets and human surveys show that our framework is able to enhance prediction robustness significantly: the predictions marked to be robust by our framework have significantly higher accuracy and are more robust to adversarial perturbations.