 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame Plan: What AI can do for Football, and What Football can do for AI
Nov 18, 2020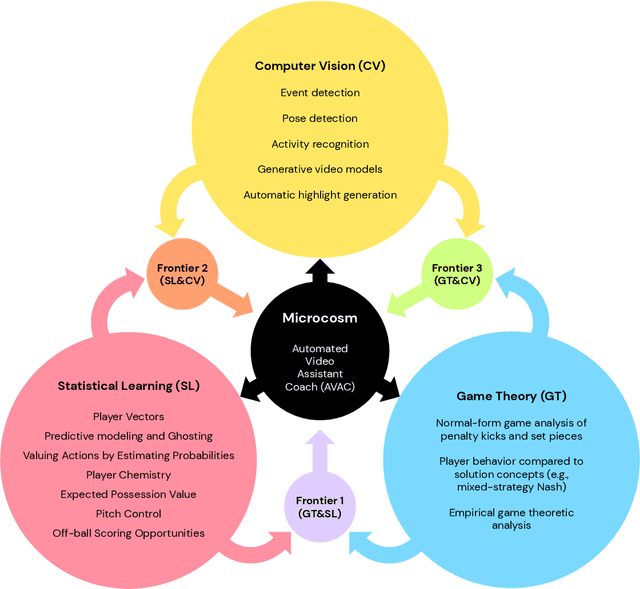



The rapid progress in artificial intelligence (AI) and machine learning has opened unprecedented analytics possibilities in various team and individual sports, including baseball, basketball, and tennis. More recently, AI techniques have been applied to football, due to a huge increase in data collection by professional teams, increased computational power, and advances in machine learning, with the goal of better addressing new scientific challenges involved in the analysis of both individual players' and coordinated teams' behaviors. The research challenges associated with predictive and prescriptive football analytics require new developments and progress at the intersection of statistical learning, game theory, and computer vision. In this paper, we provide an overarching perspective highlighting how the combination of these fields, in particular, forms a unique microcosm for AI research, while offering mutual benefits for professional teams, spectators, and broadcasters in the years to come. We illustrate that this duality makes football analytics a game changer of tremendous value, in terms of not only changing the game of football itself, but also in terms of what this domain can mean for the field of AI. We review the state-of-the-art and exemplify the types of analysis enabled by combining the aforementioned fields, including illustrative examples of counterfactual analysis using predictive models, and the combination of game-theoretic analysis of penalty kicks with statistical learning of player attributes. We conclude by highlighting envisioned downstream impacts, including possibilities for extensions to other sports (real and virtual).
Modelling Latent Skills for Multitask Language Generation
Feb 21, 2020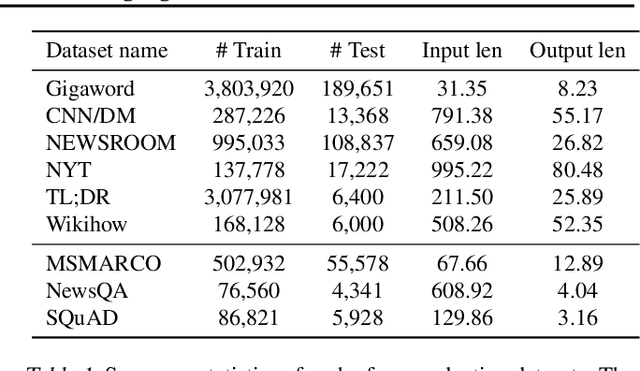

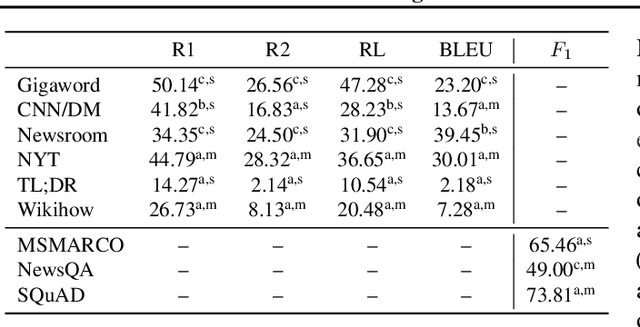
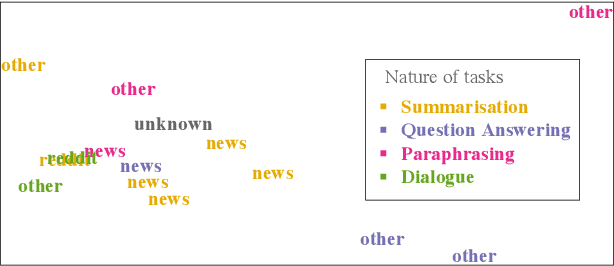
We present a generative model for multitask conditional language generation. Our guiding hypothesis is that a shared set of latent skills underlies many disparate language generation tasks, and that explicitly modelling these skills in a task embedding space can help with both positive transfer across tasks and with efficient adaptation to new tasks. We instantiate this task embedding space as a latent variable in a latent variable sequence-to-sequence model. We evaluate this hypothesis by curating a series of monolingual text-to-text language generation datasets - covering a broad range of tasks and domains - and comparing the performance of models both in the multitask and few-shot regimes. We show that our latent task variable model outperforms other sequence-to-sequence baselines on average across tasks in the multitask setting. In the few-shot learning setting on an unseen test dataset (i.e., a new task), we demonstrate that model adaptation based on inference in the latent task space is more robust than standard fine-tuning based parameter adaptation and performs comparably in terms of overall performance. Finally, we examine the latent task representations learnt by our model and show that they cluster tasks in a natural way.
Generating syntactically varied realisations from AMR graphs
Apr 20, 2018
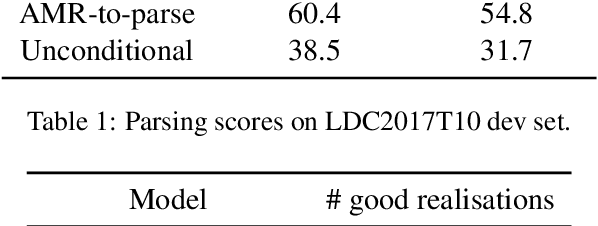

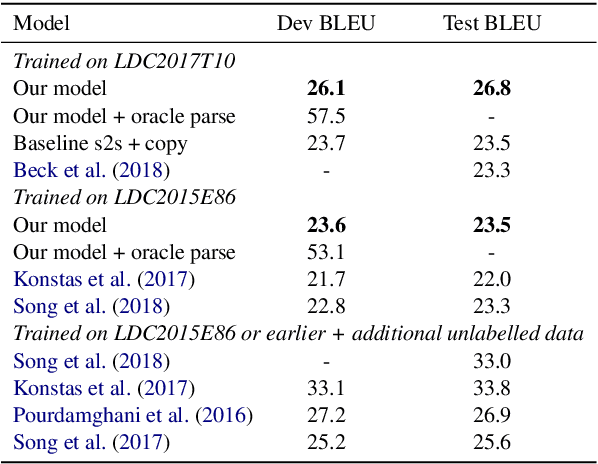
Generating from Abstract Meaning Representation (AMR) is an underspecified problem, as many syntactic decisions are not specified by the semantic graph. We learn a sequence-to-sequence model that generates possible constituency trees for an AMR graph, and then train another model to generate text realisations conditioned on both an AMR graph and a constituency tree. We show that factorising the model this way lets us effectively use parse information, obtaining competitive BLEU scores on self-generated parses and impressive BLEU scores with oracle parses. We also demonstrate that we can generate meaning-preserving syntactic paraphrases of the same AMR graph.
Emergent Communication through Negotiation
Apr 11, 2018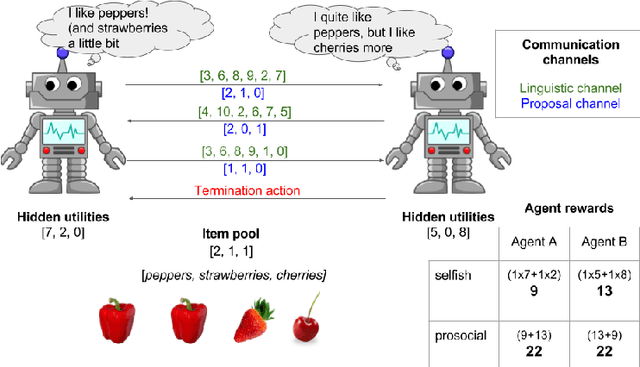
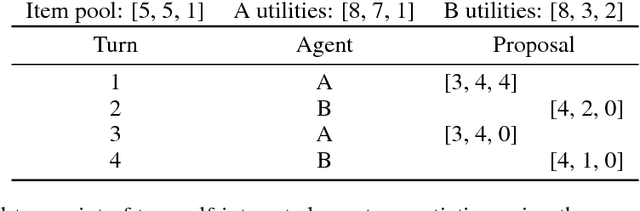
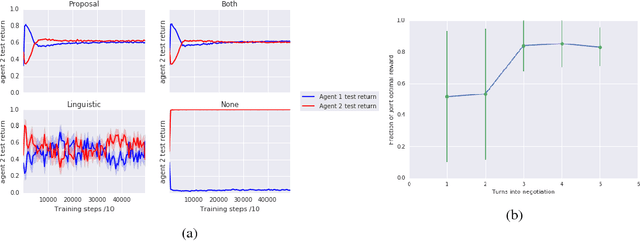
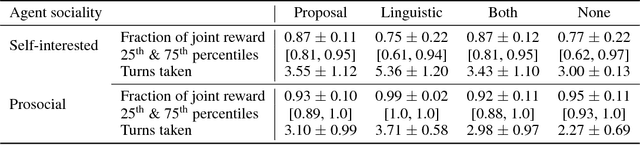
Multi-agent reinforcement learning offers a way to study how communication could emerge in communities of agents needing to solve specific problems. In this paper, we study the emergence of communication in the negotiation environment, a semi-cooperative model of agent interaction. We introduce two communication protocols -- one grounded in the semantics of the game, and one which is \textit{a priori} ungrounded and is a form of cheap talk. We show that self-interested agents can use the pre-grounded communication channel to negotiate fairly, but are unable to effectively use the ungrounded channel. However, prosocial agents do learn to use cheap talk to find an optimal negotiating strategy, suggesting that cooperation is necessary for language to emerge. We also study communication behaviour in a setting where one agent interacts with agents in a community with different levels of prosociality and show how agent identifiability can aid negotiation.
Latent Variable Dialogue Models and their Diversity
Feb 20, 2017
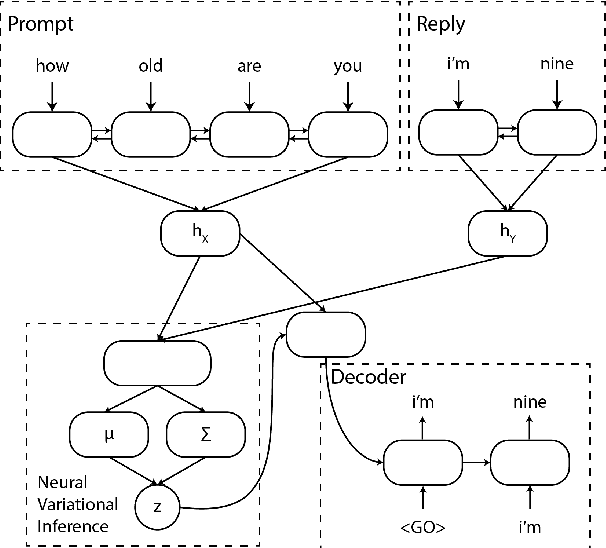
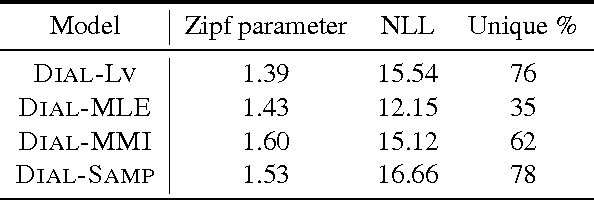

We present a dialogue generation model that directly captures the variability in possible responses to a given input, which reduces the `boring output' issue of deterministic dialogue models. Experiments show that our model generates more diverse outputs than baseline models, and also generates more consistently acceptable output than sampling from a deterministic encoder-decoder model.
A Joint Model for Word Embedding and Word Morphology
Jun 08, 2016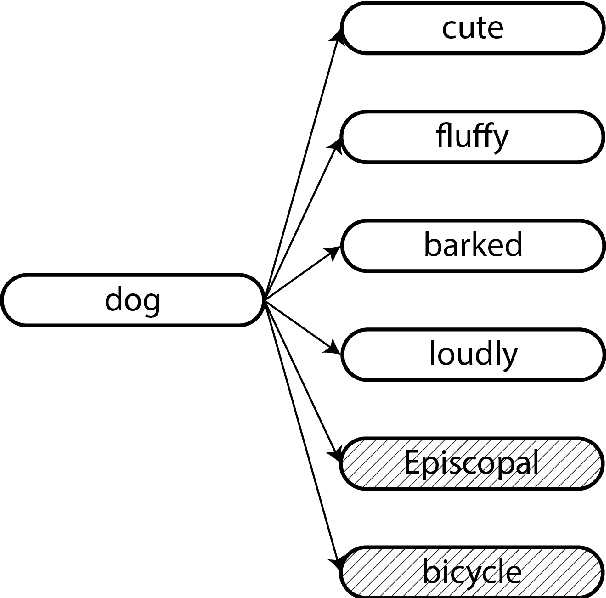
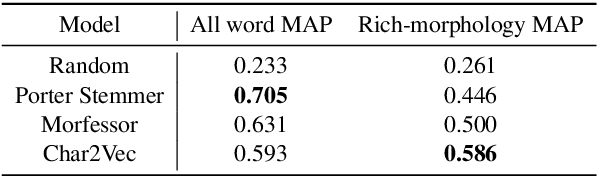
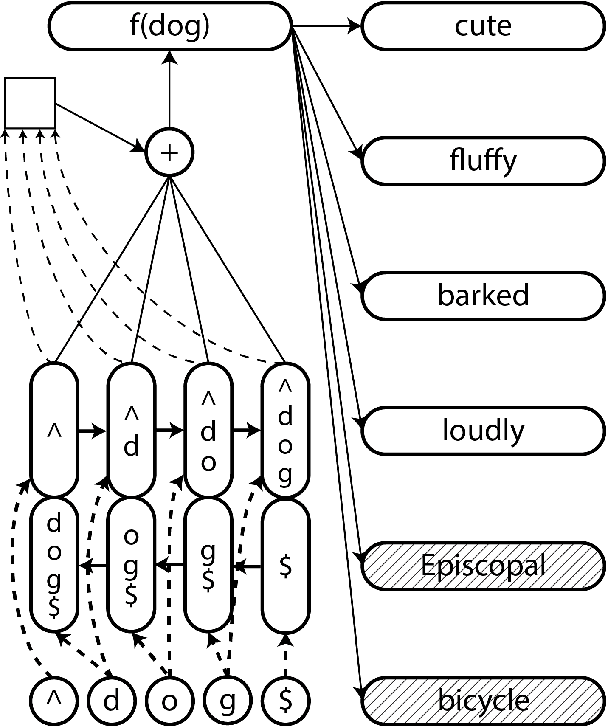
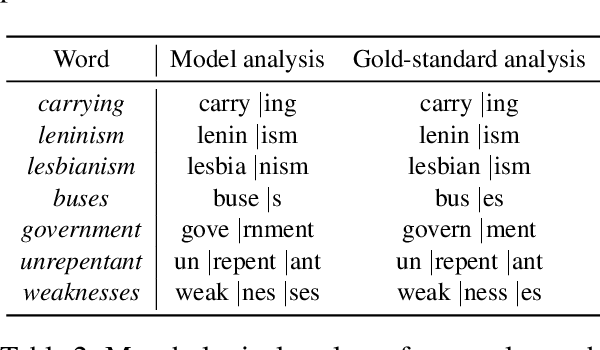
This paper presents a joint model for performing unsupervised morphological analysis on words, and learning a character-level composition function from morphemes to word embeddings. Our model splits individual words into segments, and weights each segment according to its ability to predict context words. Our morphological analysis is comparable to dedicated morphological analyzers at the task of morpheme boundary recovery, and also performs better than word-based embedding models at the task of syntactic analogy answering. Finally, we show that incorporating morphology explicitly into character-level models help them produce embeddings for unseen words which correlate better with human judgments.