 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Sim-to-Real Gap in Semiconductor Visual Program Synthesis via Input Binarization
Jun 01, 2026Precise parametric control over circuit geometry is essential for semiconductor inspection, yet obtaining sufficient real training data remains costly. Although generative models such as diffusion models and Generative Adversarial Networks (GANs) can augment training data, they cannot guarantee the nanometer-scale geometric accuracy required for metrology tasks. We propose a visual program synthesis framework in which a Vision-Language Model (VLM) converts inspection images into editable Domain-Specific Language (DSL) code describing circuit geometries, enabling controlled generation of training data with exact parameter manipulation. Because the VLM is trained solely on synthetic DSL-rendered data, a domain gap arises when processing real Scanning Electron Microscope (SEM) images. We bridge this gap with an input binarization strategy that strips SEM-specific texture and noise, letting the model focus on geometric structure. On the MIIC dataset, binarized inputs improve the mean Dice coefficient from 0.4393 to 0.5256 over the raw-input baseline, demonstrating that simple texture abstraction substantially mitigates the sim-to-real gap.
LaSTR: Language-Driven Time-Series Segment Retrieval
Feb 28, 2026Effectively searching time-series data is essential for system analysis, but existing methods often require expert-designed similarity criteria or rely on global, series-level descriptions. We study language-driven segment retrieval: given a natural language query, the goal is to retrieve relevant local segments from large time-series repositories. We build large-scale segment--caption training data by applying TV2-based segmentation to LOTSA windows and generating segment descriptions with GPT-5.2, and then train a Conformer-based contrastive retriever in a shared text--time-series embedding space. On a held-out test split, we evaluate single-positive retrieval together with caption-side consistency (SBERT and VLM-as-a-judge) under multiple candidate pool sizes. Across all settings, LaSTR outperforms random and CLIP baselines, yielding improved ranking quality and stronger semantic agreement between retrieved segments and query intent.
Label or Message: A Large-Scale Experimental Survey of Texts and Objects Co-Occurrence
Jul 30, 2020
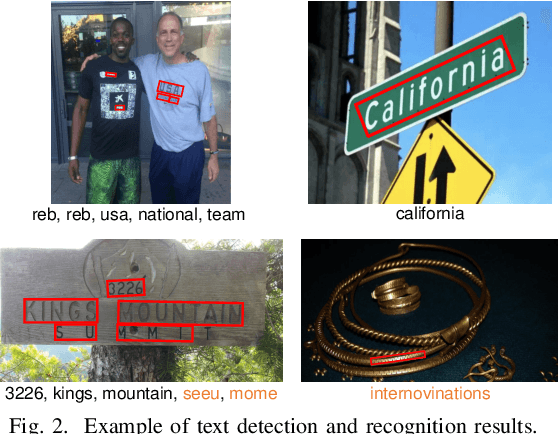
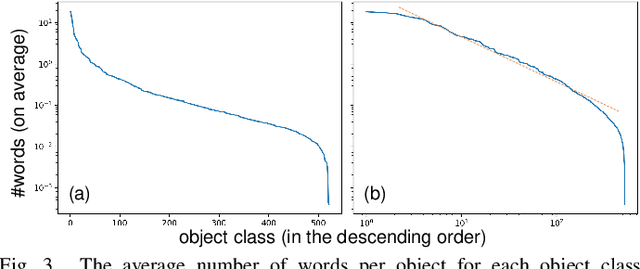
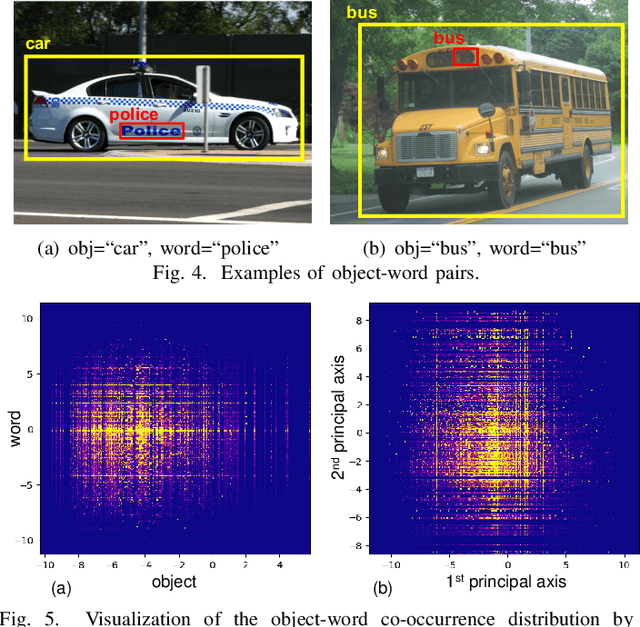
Our daily life is surrounded by textual information. Nowadays, the automatic collection of textual information becomes possible owing to the drastic improvement of scene text detectors and recognizer. The purpose of this paper is to conduct a large-scale survey of co-occurrence between visual objects (such as book and car) and scene texts with a large image dataset and a state-of-the-art scene text detector and recognizer. Especially, we focus on the function of "label" texts, which are attached to objects for detailing the objects. By analyzing co-occurrence between objects and scene texts, it is possible to observe the statistics about the label texts and understand how the scene texts will be useful for recognizing the objects and vice versa.